Representation Collapse in Sequential Post-Training of Large Language Models
Pith reviewed 2026-06-29 08:08 UTC · model grok-4.3
The pith
Sequential post-training compresses LLM internal representations into low-rank spaces that limit later plasticity, generalization, and calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
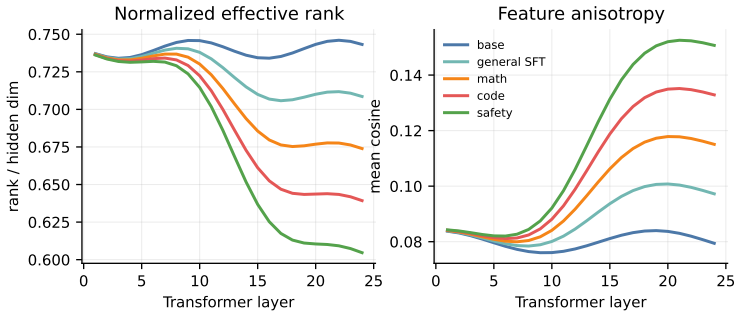
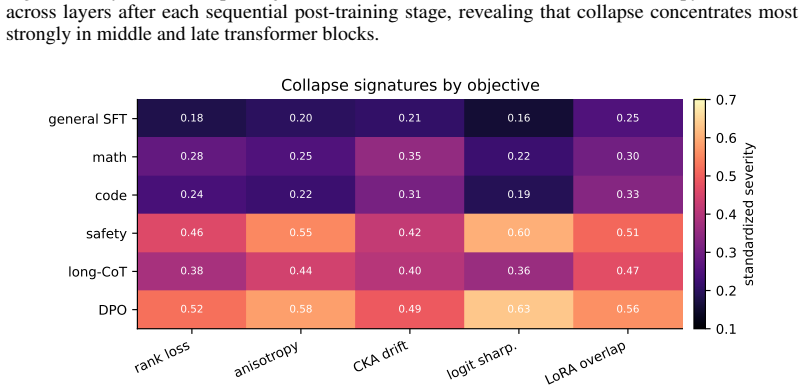
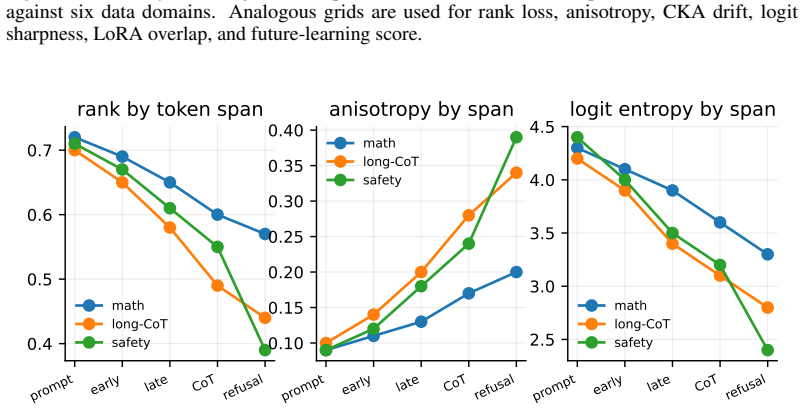
Sequential post-training causes representation collapse, measured as progressive reduction in rank, increase in anisotropy, and rise in homogeneity across hidden states, logits, token paths, and parameter updates. This collapse is not merely geometric but predicts measurable drops in plasticity during later adaptation stages, weaker performance on out-of-distribution tasks, and degraded probability calibration. Controlled experiments varying stage order show that certain sequences accelerate the collapse while others slow it, and lightweight interventions including replay buffers and regularization terms can reduce collapse without erasing the gains from each post-training step.
What carries the argument
The measurement suite tracking rank, anisotropy, and homogeneity of hidden states, logits, token trajectories, and LoRA updates, which quantifies representation collapse and its link to reduced future learnability.
If this is right
- Models that reach higher representation concentration after early post-training stages exhibit measurably lower plasticity when a new task is introduced.
- Out-of-domain generalization declines as hidden-state homogeneity increases across the sequence of training stages.
- Probability calibration worsens in proportion to the degree of representation collapse induced by prior stages.
- Certain orderings of fine-tuning, preference optimization, and specialization accelerate collapse more than others.
- Mixed-domain replay and diversity regularization preserve measurable future learnability while retaining stage-specific behavioral improvements.
Where Pith is reading between the lines
- Training pipelines could insert diversity checks after each major stage to decide whether to continue or reset.
- The same concentration pattern may appear in non-LLM sequential learning settings such as chained reinforcement learning agents.
- Routine monitoring of the measurement suite could guide when to apply corrective interventions during production post-training runs.
Load-bearing premise
The defined measurements of hidden states, logits, token trajectories, and LoRA updates isolate representation collapse and establish its causal connection to reduced plasticity and generalization under the tested stage sequences.
What would settle it
Running the same later adaptation stage on two models that differ only in measured representation concentration but show identical plasticity, out-of-domain accuracy, and calibration scores would falsify the claimed predictive link.
Figures











read the original abstract
Large language models are now adapted through chains of post-training stages rather than through a single instruction-tuning pass. This paper studies whether such sequential post-training gradually compresses internal representations into low-rank, anisotropic, and homogeneous feature spaces. We define a measurement suite for hidden states, logits, token trajectories, and LoRA updates, and we use it to analyze supervised fine-tuning, preference optimization, safety/refusal tuning, math and code specialization, and long chain-of-thought tuning under controlled stage orderings. The central hypothesis is that excessive representation concentration is not merely a geometric curiosity: it predicts reduced plasticity during later adaptation, weaker out-of-domain generalization, and poorer calibration. We further evaluate lightweight interventions, including mixed-domain replay, feature refresh, representation diversity regularization, and LoRA update decorrelation, as ways to preserve future learnability without giving up the behavioral gains of post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines whether sequential post-training stages in LLMs induce representation collapse, characterized by low-rank, anisotropic, and homogeneous feature spaces. It introduces a measurement suite spanning hidden-state anisotropy, logit concentration, token trajectories, and LoRA update norms, applies it across controlled orderings of SFT, preference optimization, safety tuning, math/code specialization, and long CoT, and hypothesizes that such collapse causally reduces later-stage plasticity, OOD generalization, and calibration. Lightweight interventions (mixed-domain replay, feature refresh, diversity regularization, LoRA decorrelation) are evaluated as mitigations that preserve behavioral gains.
Significance. If the measurement suite successfully isolates a causal geometric mechanism rather than stage-order confounders, the work would supply a concrete, testable account of why multi-stage post-training often degrades adaptability and would directly inform practical recipe design for preserving future learnability.
major comments (2)
- [Measurement suite section] Measurement suite section: the claim that the defined metrics (hidden-state anisotropy, logit concentration, token trajectories, LoRA norms) establish a causal link between representation collapse and reduced plasticity/OOD performance requires an explicit decoupling experiment. Because stage ordering simultaneously changes cumulative data exposure, optimization trajectory, and effective capacity, any observed correlation could be driven by those factors; the manuscript must show that the geometric signature predicts the downstream metrics even after controlling for the confounders.
- [Intervention evaluation section] Intervention evaluation section: the reported gains from replay, feature refresh, and diversity regularization must be accompanied by controls that verify the interventions act through the collapse metrics rather than through other mechanisms (e.g., simply increasing effective data diversity). Without such mediation analysis or matched ablations, it remains unclear whether the interventions succeed by mitigating the hypothesized geometric cause.
minor comments (2)
- Notation for the anisotropy and concentration metrics should be defined with explicit formulas and normalization details in the main text rather than deferred to an appendix.
- The abstract states the central hypothesis but supplies no quantitative outcomes; the introduction or results section should include a concise summary table of key effect sizes for the collapse–plasticity relationship.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments correctly identify gaps in establishing causality for the collapse-plasticity link and in validating the mechanism of the proposed interventions. We address each point below and commit to revisions that strengthen these aspects without altering the core claims or experimental scope.
read point-by-point responses
-
Referee: [Measurement suite section] Measurement suite section: the claim that the defined metrics (hidden-state anisotropy, logit concentration, token trajectories, LoRA norms) establish a causal link between representation collapse and reduced plasticity/OOD performance requires an explicit decoupling experiment. Because stage ordering simultaneously changes cumulative data exposure, optimization trajectory, and effective capacity, any observed correlation could be driven by those factors; the manuscript must show that the geometric signature predicts the downstream metrics even after controlling for the confounders.
Authors: We acknowledge that controlled stage orderings alone do not fully isolate the geometric signature from confounders such as cumulative data exposure and optimization trajectory. In the revision we will add a decoupling experiment that holds total tokens and optimization steps fixed while varying only the presence of collapse-inducing stages (via replay buffers that restore diversity without changing data volume). We will then report partial correlations and regression coefficients showing that collapse metrics remain predictive of plasticity and OOD metrics after these controls. revision: yes
-
Referee: [Intervention evaluation section] Intervention evaluation section: the reported gains from replay, feature refresh, and diversity regularization must be accompanied by controls that verify the interventions act through the collapse metrics rather than through other mechanisms (e.g., simply increasing effective data diversity). Without such mediation analysis or matched ablations, it remains unclear whether the interventions succeed by mitigating the hypothesized geometric cause.
Authors: The referee is right that the current intervention results lack explicit mediation or matched ablations. In the revision we will include (i) a mediation analysis regressing downstream gains on both intervention type and measured change in collapse metrics, and (ii) matched ablations that increase data diversity through non-geometric means (e.g., random token shuffling) and show they do not produce the same plasticity or calibration benefits. These additions will be reported alongside the existing tables. revision: yes
Circularity Check
No circularity: empirical measurements and hypotheses remain independent of inputs
full rationale
The paper presents an empirical study defining a measurement suite for hidden states, logits, token trajectories, and LoRA updates, then tests the hypothesis that representation concentration correlates with reduced plasticity, OOD generalization, and calibration under controlled stage orderings. No equations, fitted parameters, or derivations are described that reduce predictions to inputs by construction. The central claim is framed as a testable empirical prediction rather than a self-referential definition or self-citation load-bearing theorem. Interventions are evaluated separately, with no renaming of known results or ansatz smuggling. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
2022
-
[2]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
2024
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, 2023
2023
-
[6]
Model alignment as prospect theoretic optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Model alignment as prospect theoretic optimization. InProceedings of ICML, 2024
2024
-
[7]
SimPO: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference-free reward. InAdvances in Neural Information Processing Systems, 2024
2024
-
[8]
ORPO: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic preference optimization without reference model. InProceedings of EMNLP, 2024
2024
-
[9]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
AI@Meta. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Fine-tuning can distort pretrained features and underperform out-of-distribution
Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. InProceedings of ICLR, 2022
2022
-
[12]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In Proceedings of ICLR, 2022
2022
-
[13]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of ACL, 2021. 11
2021
-
[14]
How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of EMNLP-IJCNLP, 2019
2019
-
[15]
All-but-the-top: Simple and effective postprocessing for word representations
Jiaqi Mu and Pramod Viswanath. All-but-the-top: Simple and effective postprocessing for word representations. InProceedings of ICLR, 2018
2018
-
[16]
Isotropy in the contextual embedding space: Clusters and manifolds
Xingyu Cai, Jiaji Huang, Yuchen Bian, and Kenneth Church. Isotropy in the contextual embedding space: Clusters and manifolds. InProceedings of ICLR, 2021
2021
-
[17]
Representation degeneration problem in training natural language generation models
Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. Representation degeneration problem in training natural language generation models. InProceedings of ICLR, 2019
2019
-
[18]
Robert M. French. Catastrophic forgetting in connectionist networks.Trends in Cognitive Sciences, 1999
1999
-
[19]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. InProceedings of the National Academy of Sciences, 2017
2017
-
[20]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems, 2017
2017
-
[21]
Parisi, Ronald Kemker, Jose L
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 2019
2019
-
[22]
Vardan Papyan, X. Y . Han, and David L. Donoho. Prevalence of neural collapse during the terminal phase of deep learning training. InProceedings of the National Academy of Sciences, 2020
2020
- [23]
-
[24]
SimCSE: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sentence embeddings. InProceedings of EMNLP, 2021
2021
-
[25]
Learning without forgetting
Zhizhong Li and Derek Hoiem. Learning without forgetting. InIEEE Transactions on Pattern Analysis and Machine Intelligence, 2017
2017
-
[26]
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H. Lampert. iCaRL: Incremental classifier and representation learning. InProceedings of CVPR, 2017
2017
-
[27]
Dokania, Philip H
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K. Dokania, Philip H. S. Torr, and Marc’Aurelio Ranzato. Tiny episodic memories in continual learning. InProceedings of ICML Workshop on Multi-Task and Lifelong Reinforcement Learning, 2019
2019
-
[28]
Heming Zou, Yunliang Zang, and Xiangyang Ji. Structural features of the fly olfactory circuit mitigate the stability-plasticity dilemma in continual learning.arXiv preprint arXiv:2502.01427, 2025
-
[29]
Suchin Gururangan, Ana Marasovic, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of ACL, 2020
2020
-
[30]
Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M
Jason Wei, Maarten Bosma, Vincent Y . Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V . Le. Finetuned language models are zero-shot learners. In Proceedings of ICLR, 2022
2022
-
[31]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. InAdvances in Neural Information Processing Systems, 2017. 12
2017
-
[32]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F. Christiano. Learning to summarize with human feedback. InAdvances in Neural Information Processing Systems, 2020
2020
-
[33]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models. InProceedings of ICML, 2024
2024
-
[35]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[36]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems, 2022
2022
-
[37]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InProceedings of NeurIPS Datasets and Benchmarks, 2021
2021
-
[39]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
Program synthesis with large language models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models. InProceedings of the NeurIPS Workshop on Machine Learning for Programming, 2021
2021
-
[41]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
SVCCA: Singu- lar vector canonical correlation analysis for deep learning dynamics and interpretability
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singu- lar vector canonical correlation analysis for deep learning dynamics and interpretability. In Advances in Neural Information Processing Systems, 2017
2017
-
[43]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of ICML, 2019
2019
- [44]
-
[45]
Ruilin Li, Heming Zou, Xiufeng Yan, Zheming Liang, Jie Yang, Chenliang Li, and Xue Yang. Enhancing pretrained model-based continual representation learning via guided random projection.arXiv preprint arXiv:2603.19145, 2026. 13
- [46]
- [47]
- [48]
-
[49]
TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. TinyLlama: An open-source small language model.arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Ma...
2024
-
[51]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lelio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothee Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team. Gemma: Open models based on gemini research and technology.arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 technical re- port: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Yi: Open Foundation Models by 01.AI
01.AI. Yi: Open foundation models by 01.ai.arXiv preprint arXiv:2403.04652, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, et al. ChatGLM: A family of large language models from GLM-130B to GLM-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
FlyLoRA: Boosting task decoupling and parameter efficiency via implicit rank-wise mixture-of-experts
Heming Zou, Yunliang Zang, Wutong Xu, Yao Zhu, and Xiangyang Ji. FlyLoRA: Boosting task decoupling and parameter efficiency via implicit rank-wise mixture-of-experts. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. A Linearized theory of representation collapse This appendix gives a compact derivation for the theoretic...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.