Active Timepoint Selection for Learning Measure-Valued Trajectories
Pith reviewed 2026-06-29 08:34 UTC · model grok-4.3
The pith
Linearized optimal transport embeds measures so Gaussian processes can select informative time points for trajectory inference
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
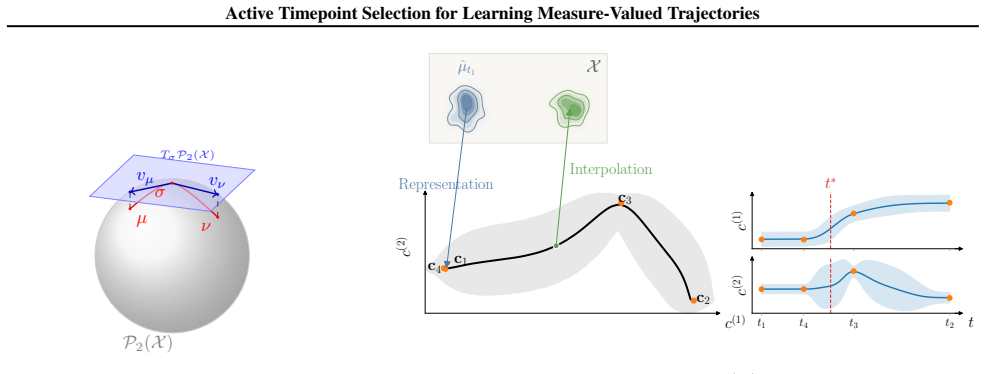
By mapping distributional snapshots into a tangent space via Linearized Optimal Transport, the authors construct a Gaussian process surrogate for the underlying probability path; this surrogate directly supplies the uncertainty estimates required to define an acquisition policy that iteratively chooses measurement times minimizing uncertainty in the inferred trajectory.
What carries the argument
The Linearized Optimal Transport embedding, which places probability measures in a Euclidean tangent space so that standard Gaussian process regression can quantify uncertainty over the full trajectory.
If this is right
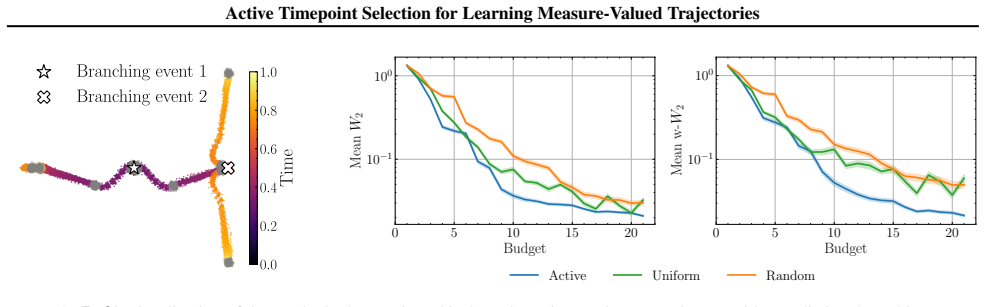
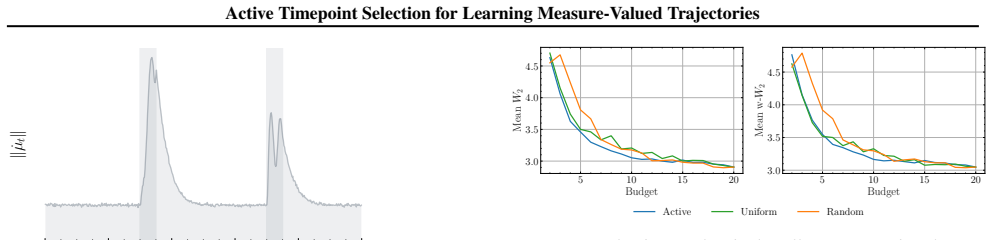
- An acquisition function can be written that selects the time minimizing predictive variance in the Gaussian process surrogate.
- Trajectory estimates improve over uncertainty-agnostic baselines on both synthetic and real datasets.
- Active experimentation becomes feasible on the infinite-dimensional space of probability measures.
Where Pith is reading between the lines
- Similar linearization tricks could bring uncertainty-aware experimental design to other non-Euclidean data spaces.
- The method may reduce the total number of snapshots needed in longitudinal studies of cell populations.
- One could check whether the selected times coincide with intervals of rapid change in the true underlying path.
Load-bearing premise
The Linearized Optimal Transport tangent space lets Gaussian process uncertainty estimates remain reliable when mapped back to the original Wasserstein geometry of probability measures.
What would settle it
On a synthetic trajectory where the full continuous path is known in advance, the times chosen by the uncertainty-driven policy produce no lower reconstruction error than times chosen by a non-adaptive baseline.
Figures

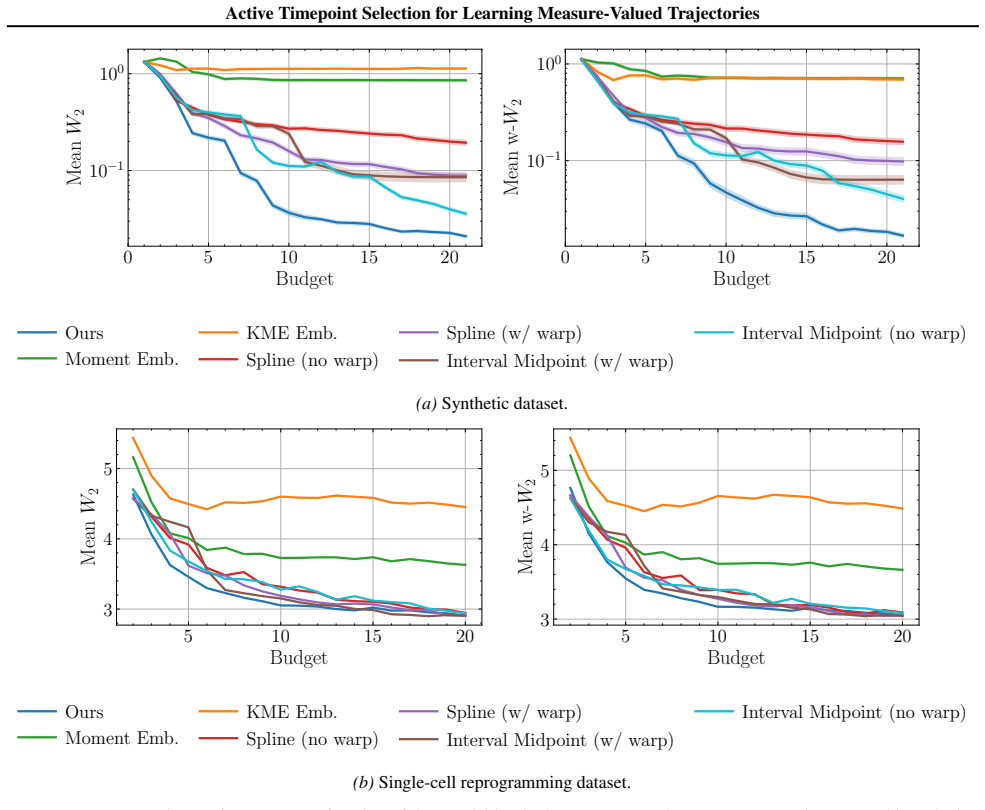


read the original abstract
Inferring continuous probability paths from sparse snapshots is a fundamental challenge in domains like single-cell biology, where high-fidelity data acquisition is often destructive and constrained by prohibitive sequencing costs. This motivates the need for active learning strategies to strategically select optimal measurement times. However, designing active learning policies for this setting remains an open problem: the target objects reside on the infinite dimensional Wasserstein space where standard Euclidean metrics are ill-defined, and current interpolation methods lack epistemic uncertainty quantification. We introduce a framework which extends active experimentation to the space of measures. By leveraging Linearized Optimal Transport (LOT), we map distributional snapshots into a tangent space amenable to Gaussian Process modeling, allowing us to construct a tractable probabilistic surrogate for the underlying probability path. This yields an acquisition policy that iteratively selects measurement times to minimize uncertainty. Empirical results demonstrate that our strategy outperforms uncertainty-agnostic baselines on both synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an active learning framework for inferring continuous measure-valued trajectories from sparse distributional snapshots. It maps snapshots into a Euclidean tangent space via Linearized Optimal Transport (LOT), fits a Gaussian Process surrogate in that space to obtain epistemic uncertainty, and uses the resulting posterior variance to define an acquisition function that iteratively selects measurement times minimizing uncertainty on the underlying probability path. The method is claimed to outperform uncertainty-agnostic baselines on both synthetic and real-world datasets, with motivation from single-cell biology applications.
Significance. If the LOT embedding supplies reliable epistemic uncertainty for Wasserstein trajectories, the work would provide a tractable extension of active learning to infinite-dimensional measure spaces, addressing a genuine gap where standard Euclidean GPs cannot be applied directly. The empirical outperformance on real datasets would constitute a concrete advance for costly data-acquisition settings. However, the local character of the linearization around a single reference measure constitutes a load-bearing assumption whose validity is not yet demonstrated for trajectories that move far from that reference.
major comments (2)
- [Methods section describing the LOT embedding and probabilistic surrogate] The central claim that the GP posterior variance in the LOT tangent space yields a reliable acquisition policy for the Wasserstein path rests on the unexamined assumption that first-order linearization errors remain negligible. Because LOT is constructed around one fixed reference measure μ₀, any segment of the trajectory whose support or mass distribution deviates substantially from μ₀ projects its variation through an approximation whose error grows with distance; the fitted GP length-scale and variance can therefore encode linearization artifacts rather than true Wasserstein variability. This directly affects the correctness of the uncertainty-minimizing acquisition rule. The manuscript should either (a) provide a quantitative bound on the linearization error along the learned trajectory or (b) demonstrate empirically that the selected time points remain optimal under a non-linearized
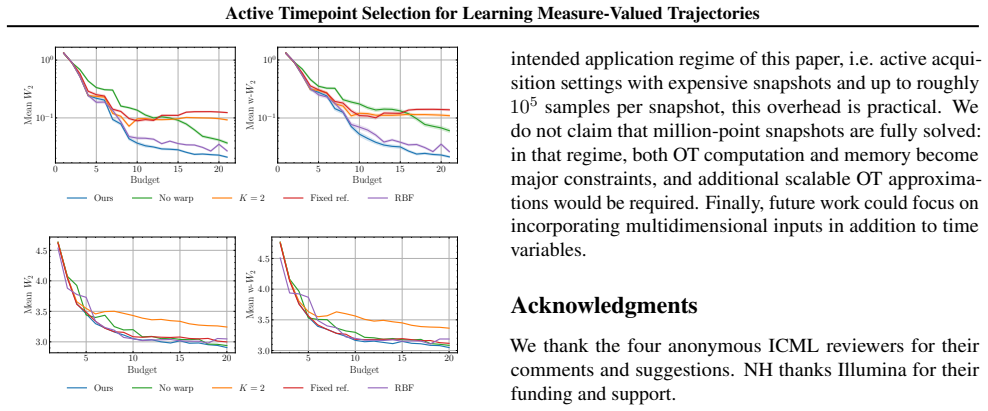
- [Experimental results and baseline comparisons] The empirical validation compares the proposed policy only against uncertainty-agnostic baselines. To substantiate that the LOT-GP uncertainty is the operative ingredient, an ablation that replaces the LOT-GP variance with a heuristic or random acquisition function while keeping the same embedding should be reported; without it, the performance gain could be attributable to the embedding alone rather than to the active selection mechanism.
minor comments (2)
- Notation for the reference measure and the tangent-space coordinates should be introduced once and used consistently; the current description occasionally switches between μ₀ and μ_ref without explicit cross-reference.
- The real-world dataset description should include the number of distributional snapshots, their temporal spacing, and the dimensionality of the underlying space so that readers can assess how far the trajectory travels from the chosen reference measure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of the LOT linearization assumption and the need to isolate the contribution of uncertainty quantification. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: The central claim that the GP posterior variance in the LOT tangent space yields a reliable acquisition policy for the Wasserstein path rests on the unexamined assumption that first-order linearization errors remain negligible. Because LOT is constructed around one fixed reference measure μ₀, any segment of the trajectory whose support or mass distribution deviates substantially from μ₀ projects its variation through an approximation whose error grows with distance; the fitted GP length-scale and variance can therefore encode linearization artifacts rather than true Wasserstein variability. This directly affects the correctness of the uncertainty-minimizing acquisition rule. The manuscript should either (a) provide a quantitative bound on the linearization error along the learned trajectory or (b) demonstrate empirically that the selected time points remain optimal under a non-linearized
Authors: We agree the linearization around a single reference is a central assumption whose validity requires further support, particularly for trajectories far from μ₀. Deriving a general quantitative error bound is technically demanding and outside the paper's scope. Instead, we will add empirical analysis in the revision: on synthetic data with known ground-truth paths, we will re-evaluate the timepoints selected by our policy using a non-linearized Wasserstein-based surrogate and report whether the selected times remain near-optimal. This addresses point (b) directly. revision: partial
-
Referee: The empirical validation compares the proposed policy only against uncertainty-agnostic baselines. To substantiate that the LOT-GP uncertainty is the operative ingredient, an ablation that replaces the LOT-GP variance with a heuristic or random acquisition function while keeping the same embedding should be reported; without it, the performance gain could be attributable to the embedding alone rather than to the active selection mechanism.
Authors: We accept that the current baselines do not fully isolate the role of the GP-derived uncertainty. In the revised manuscript we will add an ablation that retains the LOT embedding but replaces the variance-based acquisition with (i) uniform random selection and (ii) a simple heuristic (maximizing pairwise tangent-space distances), allowing direct comparison of performance gains attributable to the uncertainty-driven policy versus the embedding alone. revision: yes
Circularity Check
No circularity; derivation relies on external LOT embedding and GP without self-referential reduction
full rationale
The paper's core chain maps snapshots via LOT into a tangent space, fits a GP there, and derives an acquisition function from the resulting posterior variance. This structure is presented as a composition of standard tools (LOT linearization around a reference measure plus Euclidean GP regression) rather than any quantity being fitted on a subset and then renamed as a prediction, or any uniqueness theorem imported from the authors' own prior work. No equations are shown that equate the output acquisition policy to its inputs by construction, and the abstract explicitly frames LOT and GP as leveraged external components. The empirical outperformance claim is independent of the derivation. This is the normal case of a self-contained proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bayesian Active Learning for Classification and Preference Learning
URL https://api.semanticscholar. org/CorpusID:123428953. Flood, S., King, M., Rodgers, R., Ruggles, S., Warren, J. R., Backman, D., Chen, A., Cooper, G., Richards, S., Schouweiler, M., et al. Ipums cps: Version 12.0 [dataset]. Minneapolis, MN: IPUMS, 10:D030, 2024. Gal, Y ., Islam, R., and Ghahramani, Z. Deep bayesian active learning with image data. InIn...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1371/journal 2024
-
[2]
The full study contains multiple culture conditions
(mouse fibroblast reprogramming under OSKM induction). The full study contains multiple culture conditions. In our experiments we restrict to theserumsubset. Cells are annotated with a numeric day post-induction, and two experimental batches are provided. Representation and preprocessing.We treat each time point as an empirical measure over cell embedding...
2005
-
[3]
This shows that our method is a general tool for adaptive experimentation on measure-valued dynamical systems, and is not restricted to biology
During this period, the distribution of weekly earnings shifted quickly, because there were many fewer low-earning workers in the data. This shows that our method is a general tool for adaptive experimentation on measure-valued dynamical systems, and is not restricted to biology. 17 Active Timepoint Selection for Learning Measure-Valued Trajectories 0 2 4...
-
[4]
We report the results in Table 7 and Table 8, where MMFM underperforms our reconstruction framework
to reconstruct a probability path given our acquired snapshots. We report the results in Table 7 and Table 8, where MMFM underperforms our reconstruction framework. We believe this gap is largely due to the strong non-stationarity of the underlying dynamics. Furthermore, unlike in MMSB, our approach can be used to sample multiple plausible probability pat...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.