Simple Token-Efficient Vision-Language Model for Case-level Pathology Synoptic Report Generation
Pith reviewed 2026-06-28 23:13 UTC · model grok-4.3
The pith
A simple vision-language model generates case-level pathology reports from multiple whole-slide images using low-magnification patches and half a GPU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
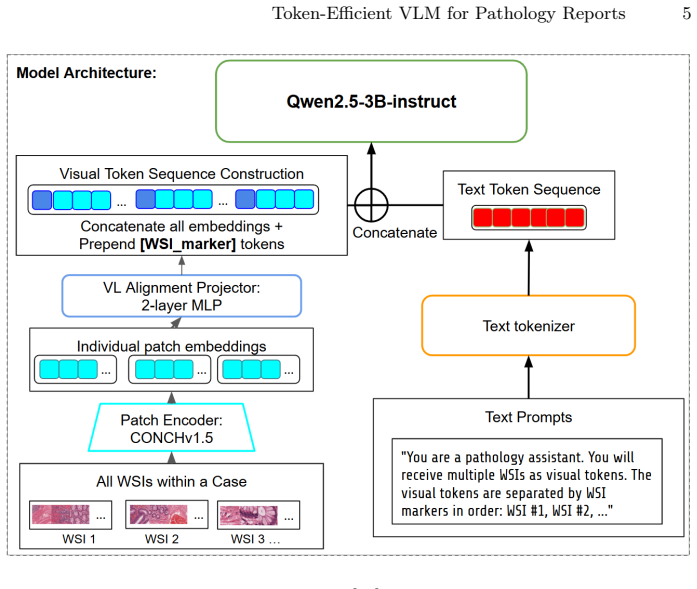
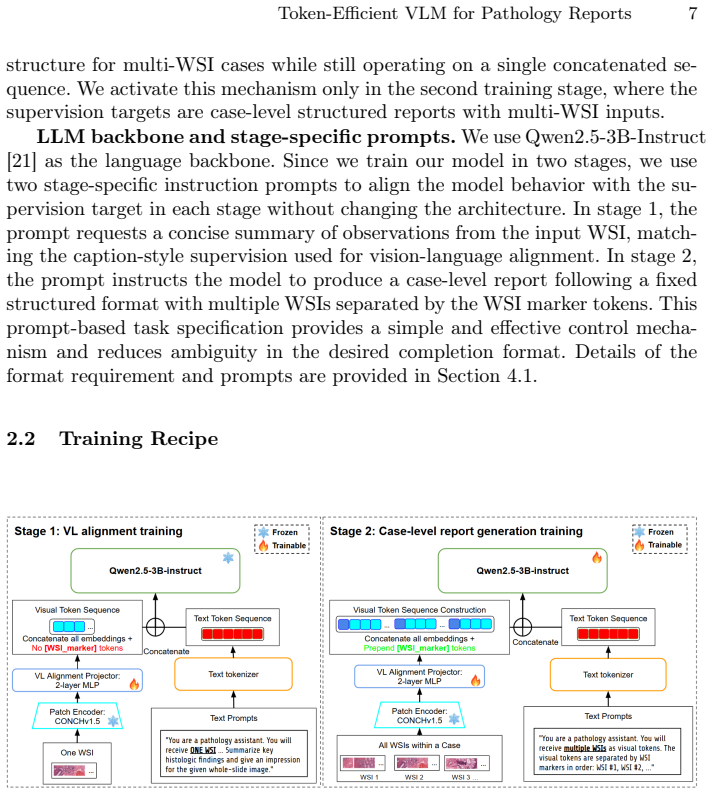
The model uses a frozen pathology patch encoder, a lightweight two-layer MLP vision-language aligner, and a large language model decoder together with an explicit WSI marker token to separate slides. Representing each slide with 512 by 512 patches at 5 times magnification reduces average sequence length by up to 64 times. Two-stage training first aligns the vision-language components on WSI captioning pairs and then performs case-level supervised fine-tuning on case-report pairs, yielding high ROUGE-L, METEOR, and BLEU-4 scores while training on only half an NVIDIA H100 GPU and producing outputs preferred over strong baselines in AI-based evaluations.
What carries the argument
The explicit WSI marker token that separates multiple slides within a single input sequence, allowing the decoder to perform case-level reasoning over heterogeneous multi-WSI inputs.
If this is right
- The two-stage training produces high ROUGE-L, METEOR, and BLEU-4 scores on case-level report generation.
- The model is consistently preferred over strong baselines in AI-based evaluations of report quality.
- Sequence-length reduction and efficient techniques make full training practical on only half a GPU.
- Ablation studies identify simple design choices that improve robustness when handling multiple WSIs per case.
- Performance-efficiency trade-offs are mapped across different patch resolutions and training configurations.
Where Pith is reading between the lines
- The same low-magnification patch strategy and marker token could be tested on other high-resolution medical imaging tasks such as radiology report generation to achieve similar token savings.
- The two-stage alignment-then-fine-tuning recipe may transfer to other vision-language settings that must process long sequences from multiple sources.
- If the generated reports match expert quality on human review, the approach could support draft report creation in pathology labs with modest hardware.
- Releasing the model and training code as a reproducible baseline would allow direct measurement of gains from future encoder or decoder improvements.
Load-bearing premise
That 512 by 512 patches extracted at 5 times magnification retain enough diagnostic detail for accurate case-level synoptic report generation across heterogeneous tissues and ambiguous findings.
What would settle it
A controlled comparison in which pathologists review the same cases at higher magnification and identify diagnostic details systematically absent from reports generated solely from the 5 times patches.
Figures






read the original abstract
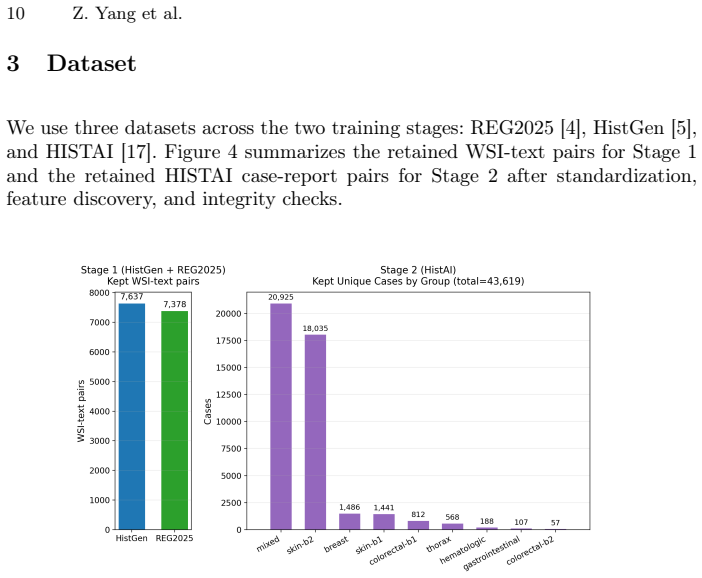
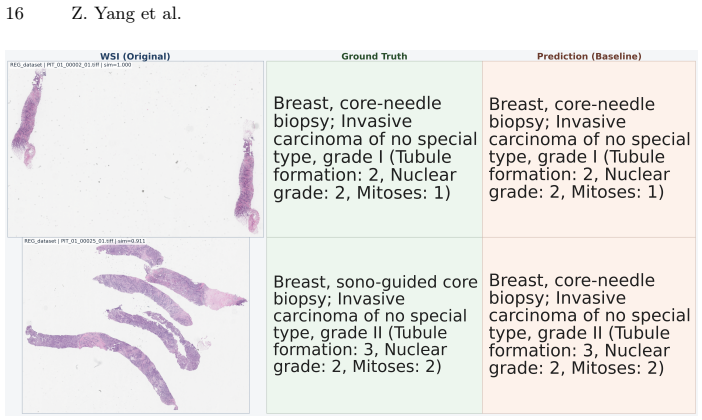
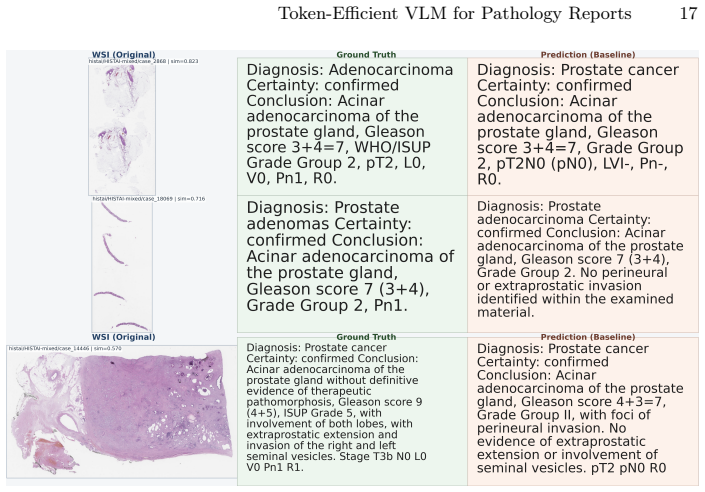
Generating clinically useful pathology reports for pathology cases from whole-slide images (WSIs) is challenging due to gigapixel resolution, long visual-token sequences, and the complexity of case-level reasoning, where a single case may contain multiple WSIs with heterogeneous tissues and ambiguous findings. We present a simple token-efficient vision--language model for case-level synoptic report generation that remains practical under constrained GPU memory. Our architecture follows a minimal three-component design: a frozen pathology patch encoder, a lightweight two-layer MLP vision-language aligner, and a large language model decoder, with an explicit WSI marker token to separate slides within a case. Training proceeds in two supervised stages: (1) aligner-only WSI captioning using heterogeneous WSI-text pairs, and (2) case-level supervised fine-tuning on case-report pairs for structured report generation. To reduce sequence length, we represent each slide using $512 \times 512$ patches at $5\times$ magnification, which reduces the average sequence length by up to $64\times$ times compared to the commonly used $20\times$ patches. Combined with efficient training techniques, we enable practical training with only half a NVIDIA H100 GPU. Across both training stages, our approach achieves high ROUGE-L/METEOR/BLEU-4 scores while being substantially more efficient in memory and runtime. In AI-based evaluations, our model is consistently preferred over strong baselines. Extensive ablations characterize performance-efficiency trade-offs and identify simple choices that improve robustness in multi-WSI settings. Overall, this work provides a strong, reproducible baseline for efficient pathology report generation, lowering the barrier to multi-WSI VLM research under limited compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a simple three-component VLM (frozen pathology patch encoder, two-layer MLP aligner, LLM decoder) with an explicit WSI marker token for case-level synoptic report generation from multi-WSI inputs. It uses two-stage supervised training (aligner-only WSI captioning followed by case-level SFT) and reduces token length by extracting 512×512 patches at 5× magnification (claimed 64× reduction vs. 20×), enabling training on half an H100 GPU. The central claims are high ROUGE-L/METEOR/BLEU-4 scores, consistent AI preference over baselines, and extensive ablations on performance-efficiency trade-offs in multi-WSI settings.
Significance. If the performance claims hold with proper validation, the work supplies a practical, reproducible baseline for token-efficient multi-WSI VLMs under constrained compute, directly addressing gigapixel resolution and heterogeneous tissue challenges in pathology report generation.
major comments (2)
- [Abstract] Abstract (efficiency paragraph): The central claim of accurate case-level reasoning over heterogeneous tissues and ambiguous findings rests on the unvalidated assumption that 512×512 patches at 5× magnification retain sufficient diagnostic detail (e.g., nuclear pleomorphism, mitoses). No ablation versus 20× patches, no pathologist review, and no quantitative comparison of report quality at different magnifications are supplied, making this load-bearing for the reported metric scores.
- [Abstract] Abstract: The assertions of 'high ROUGE-L/METEOR/BLEU-4 scores' and 'consistently preferred over strong baselines' are presented without dataset sizes, case counts, train/test splits, baseline model specifications, statistical significance tests, or ablation tables. This prevents independent verification of the performance and efficiency claims.
minor comments (1)
- The abstract mentions 'extensive ablations' but provides no section or table references for them in the summary text; ensure all ablation results are explicitly linked to tables or figures in the main body.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below, agreeing where the presentation can be strengthened and outlining targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (efficiency paragraph): The central claim of accurate case-level reasoning over heterogeneous tissues and ambiguous findings rests on the unvalidated assumption that 512×512 patches at 5× magnification retain sufficient diagnostic detail (e.g., nuclear pleomorphism, mitoses). No ablation versus 20× patches, no pathologist review, and no quantitative comparison of report quality at different magnifications are supplied, making this load-bearing for the reported metric scores.
Authors: We agree the abstract overstates the unvalidated assumption. The manuscript selects 5× for token reduction and validates via downstream report metrics and efficiency ablations, but contains no direct magnification ablation, no 20× comparison, and no pathologist review of patch diagnostic fidelity. We will revise the abstract to state the efficiency rationale explicitly, note that diagnostic sufficiency is inferred from report quality rather than direct visual validation, and add the absence of pathologist review as a limitation. revision: yes
-
Referee: [Abstract] Abstract: The assertions of 'high ROUGE-L/METEOR/BLEU-4 scores' and 'consistently preferred over strong baselines' are presented without dataset sizes, case counts, train/test splits, baseline model specifications, statistical significance tests, or ablation tables. This prevents independent verification of the performance and efficiency claims.
Authors: The abstract is a high-level summary; the full manuscript reports dataset sizes, case counts, splits, baseline details, and ablation tables in the Methods and Experiments sections. We will revise the abstract to include brief quantitative context (e.g., number of cases and WSIs) and add a pointer to the results tables. We will also incorporate statistical significance measures for the preference and metric comparisons in the revised results. revision: partial
Circularity Check
No circularity; empirical results from supervised training on held-out pairs
full rationale
The paper describes a standard supervised vision-language model trained in two stages on WSI-text and case-report pairs, with performance (ROUGE-L/METEOR/BLEU-4) measured on held-out data. No equations, derivations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear in the provided text. The architecture (frozen encoder + MLP aligner + LLM) and efficiency choices (512x512 patches at 5x) are presented as design decisions, not as outputs derived from prior results within the paper. Results are externally falsifiable via the reported benchmarks and ablations, making the work self-contained with no reduction of claims to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A frozen pathology patch encoder preserves sufficient visual features for downstream case-level report generation without further adaptation.
- domain assumption 512x512 patches at 5x magnification retain diagnostic information adequate for synoptic report generation despite reduced resolution.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2602.03998 (2026)
Alagha, A., Leclerc, C., Kotp, Y., Metwally, O., Moras, C., Rentopoulos, P., Ros- tami, G., Nguyen, B.N., Baig, J., Khellaf, A., Trinh, V.Q.H., Mizouni, R., Otrok, H., Bentahar, J., Hosseini, M.S.: Atlaspatch: Efficient tissue detection and high- throughput patch extraction for computational pathology at scale. arXiv preprint arXiv:2602.03998 (2026)
- [2]
-
[3]
Nature Medicine pp
Ding, T., Wagner, S.J., Song, A.H., Chen, R.J., Lu, M.Y., Zhang, A., Vaidya, A.J., Jaume,G.,Shaban,M.,Kim,A.,etal.:Amultimodalwhole-slidefoundationmodel for pathology. Nature Medicine pp. 1–13 (2025)
2025
-
[4]
https://reg2025.grand-challenge.org/ (2025), -MICCAI Registered Challenge
Grand Challenge: Report generation in pathology using pan-asia giga-pixel wsis (reg2025). https://reg2025.grand-challenge.org/ (2025), -MICCAI Registered Challenge. DOI: 10.5281/zenodo.15081613 (accessed 2026-02-24). 24 Z. Yang et al
-
[5]
In: proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024
Guo, Z., Ma, J., Xu, Y., Wang, Y., Wang, L., Chen, H.: HistGen: Histopathology Report Generation via Local-Global Feature Encoding and Cross-modal Context Interaction . In: proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024. vol. LNCS 15004. Springer Nature Switzerland (Oc- tober 2024)
2024
-
[6]
In: Oguz, I., Zhang, S., Metaxas, D.N
He, H., Hosseini, M.S., Wang, Y.: Pathttt: Test-time training with meta-auxiliary learning for pathology image classification. In: Oguz, I., Zhang, S., Metaxas, D.N. (eds.) Information Processing in Medical Imaging. pp. 33–46. Springer Nature Switzerland, Cham (2026)
2026
-
[7]
Gaussian Error Linear Units (GELUs)
Hendrycks, D., Gimpel, K.: Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Journal of Pathology Informat- ics15, 100357 (2024)
Hosseini, M.S., Bejnordi, B.E., Trinh, V.Q.H., Chan, L., Hasan, D., Li, X., Yang, S., Kim, T., Zhang, H., Wu, T., Chinniah, K., Maghsoud- lou, S., Zhang, R., Zhu, J., Khaki, S., Buin, A., Chaji, F., Salehi, A., Nguyen, B.N., Samaras, D., Plataniotis, K.N.: Computational pathology: A survey review and the way forward. Journal of Pathology Informat- ics15, ...
-
[9]
In: International Conference on Learning Representations (2022), https://openreview.net/forum?id=nZeVKeeFYf9
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language mod- els. In: International Conference on Learning Representations (2022), https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[10]
In: Callison-Burch, C., Koehn, P., Fordyce, C.S., Monz, C
Lavie, A., Agarwal, A.: METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments. In: Callison-Burch, C., Koehn, P., Fordyce, C.S., Monz, C. (eds.) Proceedings of the Second Workshop on Statisti- cal Machine Translation. pp. 228–231. Association for Computational Linguistics, Prague, Czech Republic (Jun 2007), htt...
2007
- [11]
-
[12]
In: ICML (2023)
Li, J., Li, D., Savarese, S., Hoi, S.: BLIP-2: bootstrapping language-image pre- training with frozen image encoders and large language models. In: ICML (2023)
2023
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Liang, Y., Lyu, X., Chen, W., Ding, M., Zhang, J., He, X., Wu, S., Xing, X., Yang, S., Wang, X., Shen, L.: Wsi-llava: A multimodal large language model for whole slide image. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22718–22727 (October 2025)
2025
-
[14]
In: Text Summarization Branches Out
Lin, C.Y.: ROUGE: A package for automatic evaluation of summaries. In: Text Summarization Branches Out. pp. 74–81. Association for Computational Linguis- tics, Barcelona, Spain (Jul 2004), https://aclanthology.org/W04-1013/
2004
-
[15]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning (2023)
2023
-
[16]
Nature Medicine30, 863—-874 (2024)
Lu, M.Y., Chen, B., Williamson, D.F., Chen, R.J., Liang, I., Ding, T., Jaume, G., Odintsov, I., Le, L.P., Gerber, G., et al.: A visual-language foundation model for computational pathology. Nature Medicine30, 863—-874 (2024)
2024
- [17]
-
[18]
https://openai.com/chatgpt/ (2026), aI chatbot
OpenAI: Chatgpt. https://openai.com/chatgpt/ (2026), aI chatbot
2026
-
[19]
Bleu: a method for automatic evaluation of machine translation
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Isabelle, P., Charniak, E., Lin, D. (eds.) Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics. pp. 311–318. Association for Computational Linguistics, Philadelphia, Pennsylvania, USA (Jul 2002). https://do...
-
[20]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Press, O., Smith, N.A., Lewis, M.: Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wa...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
arXiv preprint arXiv:2405.10254 (2024)
Shaikovski, G., Casson, A., Severson, K., Zimmermann, E., Wang, Y.K., Kunz, J.D., Retamero, J.A., Oakley, G., Klimstra, D., Kanan, C., et al.: Prism: A multi- modal generative foundation model for slide-level histopathology. arXiv preprint arXiv:2405.10254 (2024)
-
[23]
In: Hadjali, A., Maiorana, E., Gusikhin, O., Sansone, C
Sharma, V., Alagha, A., Khellaf, A., Trinh, V.Q.H., Hosseini, M.S.: Investigating zero-shot diagnostic pathology in vision-language models with efficient prompt de- sign. In: Hadjali, A., Maiorana, E., Gusikhin, O., Sansone, C. (eds.) Deep Learning Theory and Applications. pp. 263–279. Springer Nature Switzerland, Cham (2025)
2025
-
[24]
Contemporary Oncology19, A68 – A77 (2015), https://api.semanticscholar.org/CorpusID:12829250
Tomczak, K., Czerwińska, P., Wiznerowicz, M.: The cancer genome atlas (tcga): an immeasurable source of knowledge. Contemporary Oncology19, A68 – A77 (2015), https://api.semanticscholar.org/CorpusID:12829250
2015
-
[25]
Nature Communications16(1), 4886 (2025)
Tran, M., Schmidle, P., Guo, R.R., Wagner, S.J., Koch, V., Lupperger, V., Novotny, B., Murphree, D.H., Hardway, H.D., D’Amato, M., Lefkes, J., Geijs, D.J., Feuchtinger, A., Böhner, A., Kaczmarczyk, R., Biedermann, T., Amir, A.L., Mooyaart, A.L., Ciompi, F., Litjens, G., Wang, C., Comfere, N.I., Eyerich, K., Braun, S.A., Marr, C., Peng, T.: Generating derm...
-
[26]
Nature (2024)
Xu, H., Usuyama, N., Bagga, J., Zhang, S., Rao, R., Naumann, T., Wong, C., Gero, Z., González, J., Gu, Y., Xu, Y., Wei, M., Wang, W., Ma, S., Wei, F., Yang, J., Li, C., Gao, J., Rosemon, J., Bower, T., Lee, S., Weerasinghe, R., Wright, B.J., Robicsek, A., Piening, B.,Bifulco, C., Wang, S., Poon, H.: Awhole-slide foundation model for digital pathology from...
2024
-
[27]
In: International Conference on Learning Representa- tions (2020), https://openreview.net/forum?id=SkeHuCVFDr
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert. In: International Conference on Learning Representa- tions (2020), https://openreview.net/forum?id=SkeHuCVFDr
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.