Feat2Go: Visual Feature-Grounded Value Estimation for Embodied Reinforcement Learning
Pith reviewed 2026-06-28 22:39 UTC · model grok-4.3
The pith
Feat2Go derives progress targets from visual patch similarities to reshape rewards for VLA reinforcement learning without manual engineering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
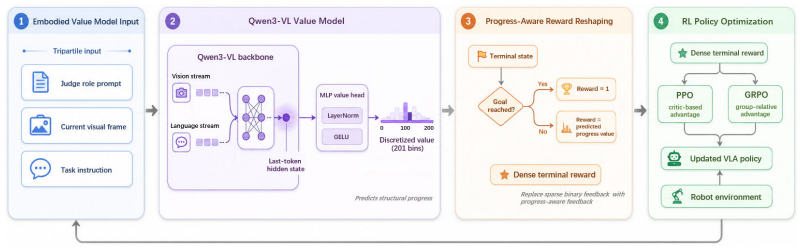
Feat2Go first derives a continuous progress target from a pretrained visual world model by measuring patch-level similarity to subgoal states and partitioning episodes into semantic stages with trend-based clustering. It then trains an embodied value model to predict this structural progress from the current observation and task instruction. The predicted value reshapes terminal rewards during policy optimization in compatible pipelines such as PPO and GRPO. This framework improves the performance of existing VLA models in both single-arm and bimanual manipulation without relying on manual reward engineering.
What carries the argument
The Feat2Go pipeline that grounds value estimation in patch-level visual similarities and trend-based stage clustering to generate dense progress signals for reward reshaping.
If this is right
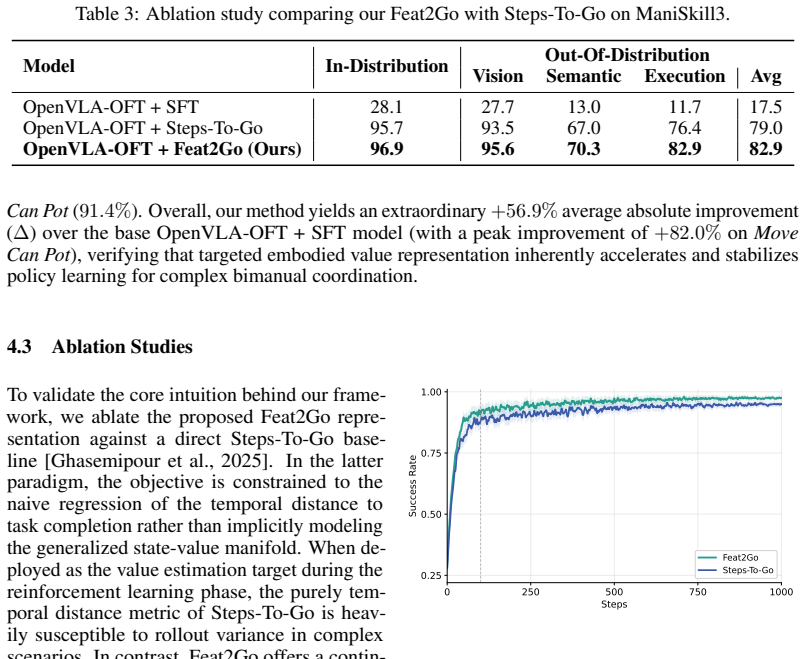
- Boosts average out-of-distribution success on ManiSkill3 from 17.5 percent to 82.9 percent while keeping 96.9 percent in-distribution performance.
- Achieves 88.8 percent average success rate on RoboTwin 2.0 in domain-randomized task settings.
- Outperforms prior reinforcement learning methods in bimanual and single-arm settings.
- Integrates directly with PPO and GRPO without changes to the policy architecture.
- Provides a general method for creating informative rewards from visual features in embodied tasks.
Where Pith is reading between the lines
- This suggests that visual world models can act as unsupervised sources of task structure for reward design in other robotic domains.
- Extensions could involve applying the same similarity and clustering process to non-manipulation tasks like navigation where visual progress is measurable.
- Testing the framework with different pretrained visual models would clarify how much the gains depend on the specific world model used.
Load-bearing premise
The patch-level similarities produced by the pretrained visual world model correspond to meaningful semantic stages of task progress that trend-based clustering can identify without supervision.
What would settle it
A controlled experiment where the visual similarities do not align with actual task progress stages, resulting in value predictions that do not improve or even harm policy learning outcomes compared to baseline rewards.
Figures

read the original abstract
Reinforcement learning is a promising approach for improving the capabilities of vision-language-action (VLA) models while avoiding the heavy data requirements of imitation learning. However, its effectiveness for VLA models is often constrained by sparse supervision and the difficulty of designing informative reward signals for long-horizon manipulation. In this work, we present Feat2Go, a fine-grained value estimation framework for embodied reinforcement learning. Specifically, Feat2Go first derives a continuous progress target from a pretrained visual world model by measuring patch-level similarity to subgoal states and partitioning episodes into semantic stages with trend-based clustering. We then train an embodied value model to predict this structural progress from the current observation and task instruction, and use the predicted value to reshape terminal rewards during policy optimization. The proposed framework is compatible with existing VLA policy reinforcement learning pipelines, including PPO and GRPO, and does not rely on manual reward engineering. Extensive experiments on ManiSkill3 and RoboTwin 2.0 demonstrate that Feat2Go consistently improves the performance of existing VLA models under both single-arm and bimanual manipulation settings. More specifically, on ManiSkill3, Feat2Go improves OpenVLAOFT from 17.5% to 82.9% average out-of-distribution success while retaining 96.9% in-distribution performance. On RoboTwin 2.0, Feat2Go achieves an average success rate of 88.8% in domain-randomized task settings, outperforming prior reinforcement learning methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Feat2Go, a framework for embodied RL that derives a continuous progress target from a pretrained visual world model via patch-level cosine similarity to subgoal states, followed by trend-based clustering to segment episodes into semantic stages. An embodied value model is trained to predict this progress from observations and task instructions; the predicted values reshape terminal rewards during PPO/GRPO optimization of VLA policies. Experiments claim large gains, including improving OpenVLAOFT from 17.5% to 82.9% average OOD success on ManiSkill3 (retaining 96.9% in-distribution) and 88.8% success on RoboTwin 2.0 in domain-randomized settings.
Significance. If the derived progress targets reliably track semantic task progress without per-task tuning or supervision, the method would provide a general, automatic mechanism for dense reward shaping in long-horizon manipulation, compatible with existing VLA RL pipelines. The reported performance jumps would represent a substantial advance over prior RL methods for VLA fine-tuning. However, the absence of validation for the core assumptions (patch similarities corresponding to progress, clustering yielding meaningful stages) prevents a firm assessment of whether the gains can be attributed to the proposed technique.
major comments (1)
- [Abstract] Abstract: the procedure for obtaining the progress target (patch-level similarity from a pretrained world model + trend-based clustering) is presented without any quantitative check that the resulting stages align with human-labeled milestones or that similarities remain monotonic and semantically meaningful under visual distractors, viewpoint changes, or non-monotonic feature trajectories. This validation is load-bearing for the claim that the value estimates and reward reshaping produce the reported gains.
minor comments (1)
- The abstract supplies no information on experimental controls, ablation studies, statistical significance testing, or the procedure for selecting clustering hyperparameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for validation of the core progress-target assumptions. We agree this is an important point and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the procedure for obtaining the progress target (patch-level similarity from a pretrained world model + trend-based clustering) is presented without any quantitative check that the resulting stages align with human-labeled milestones or that similarities remain monotonic and semantically meaningful under visual distractors, viewpoint changes, or non-monotonic feature trajectories. This validation is load-bearing for the claim that the value estimates and reward reshaping produce the reported gains.
Authors: We acknowledge that the current manuscript does not provide explicit quantitative validation (e.g., alignment with human-labeled milestones or robustness metrics under distractors/viewpoint changes). The reported performance improvements on ManiSkill3 and RoboTwin are empirical evidence that the targets are useful in practice, but we agree direct validation would make the attribution clearer. In the revision we will add (i) a quantitative comparison of clustered stages against human-annotated milestones on a held-out task subset and (ii) controlled robustness experiments measuring monotonicity and similarity stability under visual perturbations. These additions will be placed in a new subsection of the method or experiments. revision: yes
Circularity Check
No circularity: external world-model target supervises independent value model
full rationale
The derivation begins with an external pretrained visual world model that supplies patch-level cosine similarities to subgoal states; these are clustered via trend analysis to produce a continuous progress target. The embodied value model is then trained to regress this independently generated target from observations and instructions, after which the predicted values reshape terminal rewards inside PPO/GRPO. No equation equates the target to the value model output, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on a self-citation. The reported gains therefore rest on an external signal rather than a self-referential loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Patch-level similarity in a pretrained visual world model corresponds to semantic task progress
- domain assumption Trend-based clustering partitions episodes into semantically meaningful stages
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Senyu Fei, Siyin Wang, Li Ji, Ao Li, Shiduo Zhang, Liming Liu, Jinlong Hou, Jingjing Gong, Xianzhong Zhao, and Xipeng Qiu. Srpo: Self-referential policy optimization for vision-language- action models.arXiv preprint arXiv:2511.15605,
-
[6]
Self-improving embodied foundation models.CoRR, abs/2509.15155,
Seyed Kamyar Seyed Ghasemipour, Ayzaan Wahid, Jonathan Tompson, Pannag Sanketi, and Igor Mordatch. Self-improving embodied foundation models.arXiv preprint arXiv:2509.15155,
-
[7]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al. pi∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025a. Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789,
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789,
-
[11]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse-kai Chan, et al. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.arXiv preprint arXiv:2410.00425,
-
[15]
Rlinf-vla: A unified and efficient framework for vla+ rl training
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training. arXiv preprint arXiv:2510.06710,
-
[16]
Shaopeng Zhai, Qi Zhang, Tianyi Zhang, Fuxian Huang, Haoran Zhang, Ming Zhou, Shengzhe Zhang, Litao Liu, Sixu Lin, and Jiangmiao Pang. A vision-language-action-critic model for robotic real-world reinforcement learning.arXiv preprint arXiv:2509.15937,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.