LLM Anonymization Against Agentic Re-Identification
Pith reviewed 2026-06-28 22:22 UTC · model grok-4.3
The pith
AURA improves the privacy-utility frontier for text anonymization by using adaptive privacy scope against agentic web-search re-identification and mask-reconstruct reconstruction for utility retention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
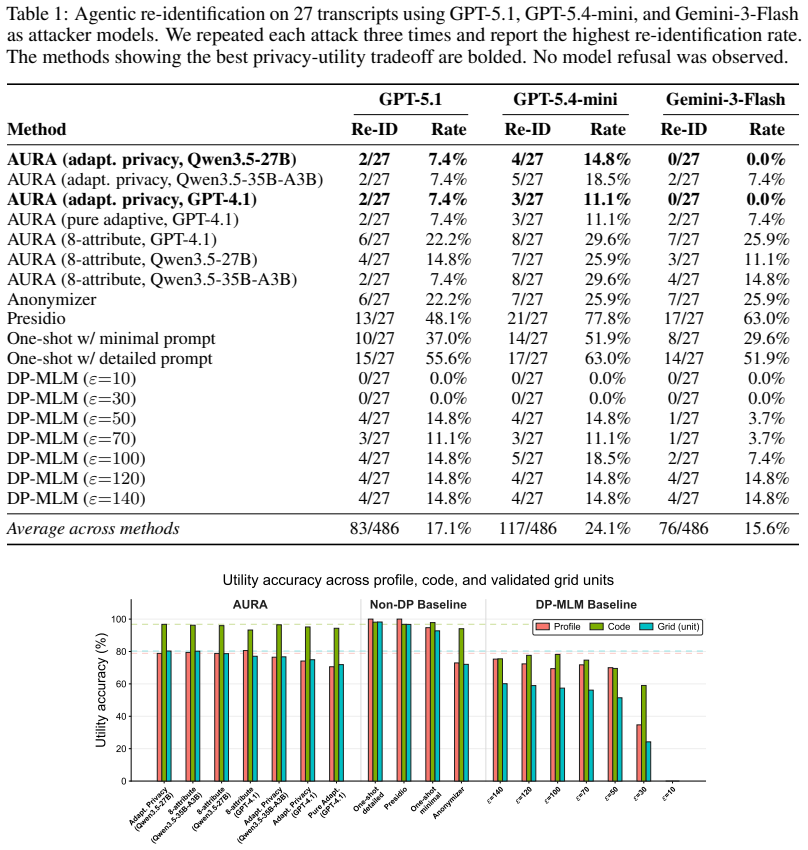
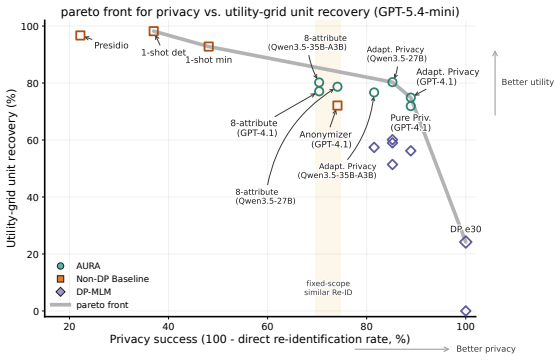
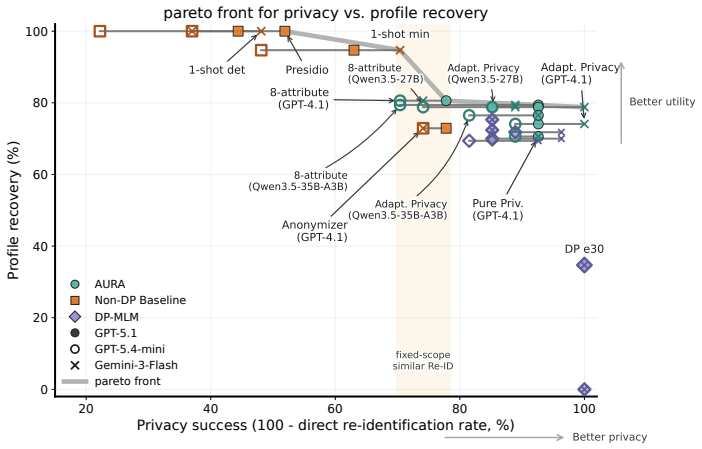
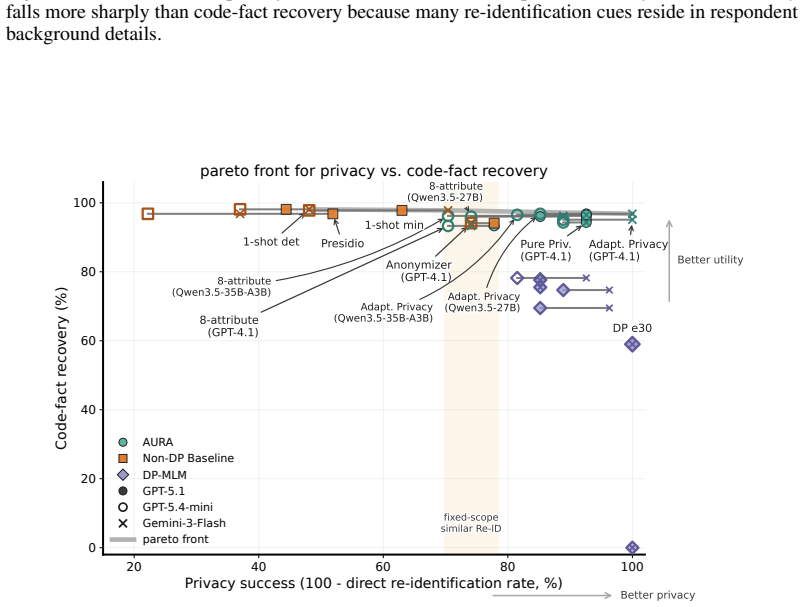
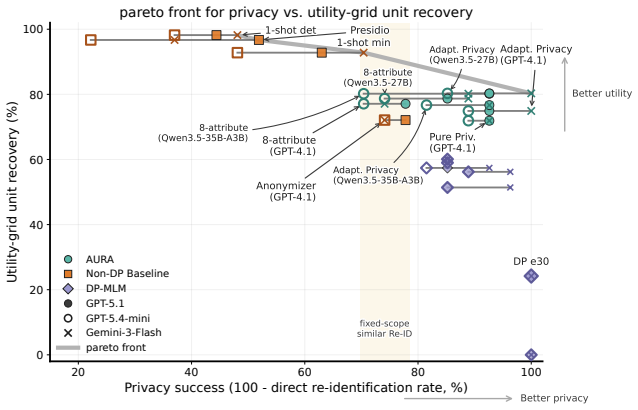
AURA, an LLM-powered mask-reconstruct framework that decouples privacy localization from utility-preserving reconstruction and selects candidates with adversarial privacy and utility-retention checks, improves the privacy-utility frontier by using adaptive privacy scope to strengthen resistance to agentic re-identification and using a mask-reconstruct anonymization method to better preserve contextual utility under fixed privacy scope, as shown on real-user interview transcripts with web-search agent attacks and the listed utility metrics.
What carries the argument
The AURA mask-reconstruct anonymization method, which separates privacy localization from subsequent utility-preserving reconstruction and applies adversarial checks to select output candidates.
If this is right
- Adaptive privacy scope selection increases resistance to re-identification by web-search agents.
- Mask-reconstruct reconstruction preserves more contextual utility than fixed-scope methods at the same privacy level.
- The combination yields an improved privacy-utility frontier on real interview transcripts.
- Utility can be quantified via extraction of interviewee-profile facts, codebook facts, and joint contextual utility.
Where Pith is reading between the lines
- The same decoupling of masking and reconstruction steps could be tested on other text types such as medical notes or customer logs where agentic analysis is a concern.
- Integration into data-release pipelines might allow organizations to tune the privacy scope dynamically based on the expected downstream analysis tasks.
- Future evaluations could examine whether the same gains hold when the attacking agents are allowed multiple rounds of search or when they combine web results with internal knowledge bases.
Load-bearing premise
The chosen utility metrics and the specific web-search agent attacks adequately represent real-world analytic value and threat models for anonymized text.
What would settle it
An experiment showing that a different anonymization technique or a wider range of web-search agents produces a strictly better privacy-utility trade-off on the same or comparable interview transcripts.
Figures


read the original abstract
Agentic LLMs with web search change the threat model for text anonymization: weak contextual cues can become cross-referenceable evidence for re-identification, yet those same details also carry downstream analytic value of the text. Existing defenses either remove explicit identifiers, perturb text for formal privacy, or test rewritten text against non-web inference models, leaving underexplored the operating region between resistance to agentic web-search re-identification and utility retention. We introduce AURA (\textbf{A}nonymization with \textbf{U}tility-\textbf{R}etention \textbf{A}daptation), an LLM-powered \textit{mask-reconstruct} framework that decouples privacy localization from utility-preserving reconstruction and selects candidates with adversarial privacy and utility-retention checks. We evaluate AURA on real-user interview transcripts using re-identification attacks carried out by web-search agents, along with a utility evaluation based on interviewee-profile facts, codebook facts, and the joint contextual utility grid. Our results show that AURA improves the privacy-utility frontier by using adaptive privacy scope to strengthen resistance to agentic re-identification and using a mask-reconstruct anonymization method to better preserve contextual utility under fixed privacy scope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AURA, an LLM-powered mask-reconstruct anonymization framework that uses adaptive privacy scope to resist agentic web-search re-identification attacks while preserving contextual utility via mask-reconstruct reconstruction and adversarial checks. It evaluates the approach on real-user interview transcripts against web-search agent attacks, using interviewee-profile facts, codebook facts, and a joint contextual utility grid, claiming an improved privacy-utility frontier over existing methods.
Significance. If the empirical claims hold under the stated threat model and metrics, the work is significant for addressing the gap between formal privacy perturbations and non-web inference testing in the presence of agentic LLMs with search capabilities. It provides a concrete, LLM-driven method that decouples localization from reconstruction and includes built-in adversarial validation, which could inform practical anonymization pipelines for sensitive textual data such as interviews.
major comments (2)
- [Abstract / Evaluation section] Abstract (and evaluation description): the central claim that AURA improves the privacy-utility frontier rests on the specific choice of utility metrics (interviewee-profile facts, codebook facts, joint contextual utility grid) and web-search agent attacks; these are presented without justification or ablation showing they adequately proxy real-world analytic value and threat models, which is load-bearing for the 'improves the frontier' result.
- [Abstract / Methods description] Abstract: the description of the mask-reconstruct method and adaptive privacy scope selection via 'adversarial privacy and utility-retention checks' provides no algorithmic details, pseudocode, or parameter definitions, preventing assessment of whether the reported gains are due to the proposed decoupling or to unstated implementation choices.
minor comments (2)
- [Abstract] The abstract uses the acronym AURA but expands it inline; ensure consistent expansion on first use in the full manuscript.
- [Abstract] No dataset size, number of transcripts, or statistical details (e.g., number of attacks, variance across runs) are mentioned in the provided abstract, which should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the review and the constructive comments on our manuscript. We address each major point below, proposing revisions to strengthen the presentation of our evaluation and method.
read point-by-point responses
-
Referee: [Abstract / Evaluation section] Abstract (and evaluation description): the central claim that AURA improves the privacy-utility frontier rests on the specific choice of utility metrics (interviewee-profile facts, codebook facts, joint contextual utility grid) and web-search agent attacks; these are presented without justification or ablation showing they adequately proxy real-world analytic value and threat models, which is load-bearing for the 'improves the frontier' result.
Authors: We agree that explicit justification and ablation are needed to support the central claim. The chosen metrics (interviewee-profile facts, codebook facts, and joint contextual utility grid) are motivated by their direct correspondence to the analytic tasks performed on interview data in social science research, and the web-search agent attacks reflect the stated threat model of agentic LLMs. However, the current manuscript does not include a dedicated justification subsection or ablation against alternative metrics. We will revise the evaluation section to add this justification, along with an ablation comparing our metrics to semantic similarity and downstream task performance measures. This revision will be made. revision: yes
-
Referee: [Abstract / Methods description] Abstract: the description of the mask-reconstruct method and adaptive privacy scope selection via 'adversarial privacy and utility-retention checks' provides no algorithmic details, pseudocode, or parameter definitions, preventing assessment of whether the reported gains are due to the proposed decoupling or to unstated implementation choices.
Authors: The abstract is intentionally concise, but we acknowledge that the high-level description alone does not allow full assessment of the decoupling and checks. The full methods section details the mask-reconstruct procedure, adaptive scope selection, and adversarial validation steps with parameter settings. To address the concern directly, we will expand the abstract with a brief algorithmic outline and add explicit pseudocode plus parameter definitions to the methods section. This revision will be made. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces an empirical LLM-based anonymization framework AURA and evaluates it on interview transcripts against external web-search agent re-identification attacks plus utility metrics (interviewee-profile facts, codebook facts, joint contextual grid). No equations, parameter fits, derivations, or self-citations appear in the provided text that would reduce any central claim to its own inputs by construction. The privacy-utility frontier improvement is asserted via direct comparison to external attacks and grids rather than self-referential definitions or renamings, making the evaluation self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[2]
Ruth Appel, Peter McCrory, Alex Tamkin, Miles McCain, Tyler Neylon, and Michael Stern. Anthropic economic index report: Uneven geographic and enterprise ai adoption.arXiv preprint arXiv:2511.15080, 2025
arXiv 2025
-
[3]
CluSanT: Differentially private and semantically coherent text sanitization
Ahmed Musa Awon, Yun Lu, Shera Potka, and Alex Thomo. CluSanT: Differentially private and semantically coherent text sanitization. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Paper...
-
[4]
Swe-chat: Coding agent interactions from real users in the wild, 2026
Joachim Baumann, Vishakh Padmakumar, Xiang Li, John Yang, Diyi Yang, and Sanmi Koyejo. Swe-chat: Coding agent interactions from real users in the wild, 2026. URL https://arxiv. org/abs/2604.20779
Pith/arXiv arXiv 2026
-
[5]
Ethical sharing and reuse of qualitative data.Australian Journal of Social Issues, 44(3):255–272, 2009
Libby Bishop. Ethical sharing and reuse of qualitative data.Australian Journal of Social Issues, 44(3):255–272, 2009
2009
-
[6]
How people use chatgpt
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use chatgpt. Technical report, National Bureau of Economic Research, 2025
2025
-
[7]
A customized text sanitization mechanism with differential privacy
Sai Chen, Fengran Mo, Yanhao Wang, Cen Chen, Jian-Yun Nie, Chengyu Wang, and Jamie Cui. A customized text sanitization mechanism with differential privacy. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: ACL 2023, pages 5747–5758, Toronto, Canada, July 2023. As- sociation for Compu...
-
[8]
De-identification of patient notes with recurrent neural networks.Journal of the American Medical Informatics Association, 24(3):596–606, 2017
Franck Dernoncourt, Ji Young Lee, Ozlem Uzuner, and Peter Szolovits. De-identification of patient notes with recurrent neural networks.Journal of the American Medical Informatics Association, 24(3):596–606, 2017
2017
-
[9]
The algorithmic foundations of differential privacy.Found
Cynthia Dwork and Aaron Roth. The algorithmic foundations of differential privacy.Found. Trends Theor. Comput. Sci., 9(3–4):211–407, August 2014. ISSN 1551-305X. doi: 10.1561/ 0400000042. URLhttps://doi.org/10.1561/0400000042
-
[10]
Private hyperparameter tuning with ex-post guarantee
Badih Ghazi, Pritish Kamath, Alexander Knop, Ravi Kumar, Pasin Manurangsi, and Chiyuan Zhang. Private hyperparameter tuning with ex-post guarantee. InNeurIPS, 2025. URL https://openreview.net/forum?id=zjMd3yfyWv
2025
-
[11]
Introducing anthropic interviewer: What 1,250 professionals told us about working with ai,
Kunal Handa, Michael Stern, Saffron Huang, Jerry Hong, Esin Durmus, Miles McCain, Grace Yun, AJ Alt, Thomas Millar, Alex Tamkin, Jane Leibrock, Stuart Ritchie, and Deep Ganguli. Introducing anthropic interviewer: What 1,250 professionals told us about working with ai,
-
[12]
URLhttps://anthropic.com/research/anthropic-interviewer
-
[13]
Secondary analysis of qualitative data: An overview.Historical Social Re- search/Historische Sozialforschung, pages 33–45, 2008
Janet Heaton. Secondary analysis of qualitative data: An overview.Historical Social Re- search/Historische Sozialforschung, pages 33–45, 2008
2008
-
[14]
Empirical privacy variance
Yuzheng Hu, Fan Wu, Ruicheng Xian, Yuhang Liu, Lydia Zakynthinou, Pritish Kamath, Chiyuan Zhang, and David Forsyth. Empirical privacy variance. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volume 2...
2025
-
[15]
What 81,000 people want from AI.https://www.anthropic.com/features/81k-interviews, 2026
Saffron Huang, Shan Carter, Jake Eaton, Sarah Pollack, Dexter Callender III, et al. What 81,000 people want from AI.https://www.anthropic.com/features/81k-interviews, 2026
2026
-
[16]
Dp-bart for privatized text rewriting under local differential privacy
Timour Igamberdiev and Ivan Habernal. Dp-bart for privatized text rewriting under local differential privacy. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13914–13934, 2023
2023
-
[17]
From weak cues to real identities: Evaluating inference-driven de-anonymization in llm agents, 2026
Myeongseob Ko, Jihyun Jeong, Sumiran Singh Thakur, Gyuhak Kim, and Ruoxi Jia. From weak cues to real identities: Evaluating inference-driven de-anonymization in llm agents, 2026. URLhttps://arxiv.org/abs/2603.18382
Pith/arXiv arXiv 2026
-
[18]
Practical differentially private hyperparameter tuning with subsampling
Antti Koskela and Tejas D Kulkarni. Practical differentially private hyperparameter tuning with subsampling. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 28201–28225. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/ paper/20...
2023
-
[19]
Large-scale online deanonymization with llms, 2026
Simon Lermen, Daniel Paleka, Joshua Swanson, Michael Aerni, Nicholas Carlini, and Florian Tramèr. Large-scale online deanonymization with llms, 2026. URL https://arxiv.org/ abs/2602.16800
arXiv 2026
-
[20]
Tianshi Li. Agentic llms as powerful deanonymizers: Re-identification of participants in the anthropic interviewer dataset.arXiv preprint arXiv:2601.05918, 2026
arXiv 2026
-
[21]
Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation
Zi Lin, Zihan Wang, Yongqi Tong, Yangkun Wang, Yuxin Guo, Yujia Wang, and Jingbo Shang. Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 4694–4702, 2023
2023
-
[22]
Lincoln and Egon G
Yvonna .S. Lincoln and Egon G. Guba.Naturalistic inquiry. Sage Publications, 1985
1985
-
[23]
Anonymisation models for text data: State of the art, challenges and future directions
Pierre Lison, Ildikó Pilán, David Sanchez, Montserrat Batet, and Lilja Øvrelid. Anonymisation models for text data: State of the art, challenges and future directions. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers),...
2021
-
[24]
The limits of word level differential privacy
Justus Mattern, Benjamin Weggenmann, and Florian Kerschbaum. The limits of word level differential privacy. InFindings of the Association for Computational Linguistics: NAACL 2022, pages 867–881, 2022
2022
-
[25]
Dp-mlm: Differen- tially private text rewriting using masked language models
Stephen Meisenbacher, Maulik Chevli, Juraj Vladika, and Florian Matthes. Dp-mlm: Differen- tially private text rewriting using masked language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 9314–9328, 2024
2024
-
[26]
Automatic de-identification of textual documents in the electronic health record: a review of recent research.BMC medical research methodology, 10(1):70, 2010
Stephane M Meystre, F Jeffrey Friedlin, Brett R South, Shuying Shen, and Matthew H Samore. Automatic de-identification of textual documents in the electronic health record: a review of recent research.BMC medical research methodology, 10(1):70, 2010
2010
-
[27]
Presidio: Data protection and de-identification SDK
Microsoft. Presidio: Data protection and de-identification SDK. https://github.com/ microsoft/presidio, 2021
2021
-
[28]
Position: Privacy is not just memorization!arXiv preprint arXiv:2510.01645, 2025
Niloofar Mireshghallah and Tianshi Li. Position: Privacy is not just memorization!arXiv preprint arXiv:2510.01645, 2025
arXiv 2025
-
[29]
Robust de-anonymization of large sparse datasets
Arvind Narayanan and Vitaly Shmatikov. Robust de-anonymization of large sparse datasets. In 2008 IEEE Symposium on Security and Privacy (sp 2008), pages 111–125. IEEE, 2008
2008
-
[30]
Automatic anonymization of swiss federal supreme court rulings
Joel Niklaus, Robin Mamié, Matthias Stürmer, Daniel Brunner, and Marcel Gygli. Automatic anonymization of swiss federal supreme court rulings. InProceedings of the Natural Legal Language Processing Workshop 2023, pages 159–165, 2023
2023
-
[31]
Hyperparameter tuning with renyi differential privacy
Nicolas Papernot and Thomas Steinke. Hyperparameter tuning with renyi differential privacy. InInternational Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=-70L8lpp9DF. 11
2022
-
[32]
The text anonymization benchmark (tab): A dedicated corpus and evaluation framework for text anonymization.Computational Linguistics, 48(4):1053–1101, 2022
Ildikó Pilán, Pierre Lison, Lilja Øvrelid, Anthi Papadopoulou, David Sánchez, and Montserrat Batet. The text anonymization benchmark (tab): A dedicated corpus and evaluation framework for text anonymization.Computational Linguistics, 48(4):1053–1101, 2022
2022
-
[33]
Anonymising interview data: Chal- lenges and compromise in practice.Qualitative research, 15(5):616–632, 2015
Benjamin Saunders, Jenny Kitzinger, and Celia Kitzinger. Anonymising interview data: Chal- lenges and compromise in practice.Qualitative research, 15(5):616–632, 2015
2015
-
[34]
PAPILLON: Privacy preservation from Internet-based and local language model ensembles
Li Siyan, Vethavikashini Chithrra Raghuram, Omar Khattab, Julia Hirschberg, and Zhou Yu. PAPILLON: Privacy preservation from Internet-based and local language model ensembles. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human...
-
[35]
Beyond memorization: Violating privacy via inference with large language models
Robin Staab, Mark Vero, Mislav Balunovic, and Martin Vechev. Beyond memorization: Violating privacy via inference with large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=kmn0BhQk7p
2024
-
[36]
Language models are advanced anonymizers
Robin Staab, Mark Vero, Mislav Balunovic, and Martin Vechev. Language models are advanced anonymizers. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[37]
Annotating longitudinal clinical narratives for de- identification: The 2014 i2b2/uthealth corpus.Journal of biomedical informatics, 58:S20–S29, 2015
Amber Stubbs and Özlem Uzuner. Annotating longitudinal clinical narratives for de- identification: The 2014 i2b2/uthealth corpus.Journal of biomedical informatics, 58:S20–S29, 2015
2014
-
[38]
Adrianna Danuta Surmiak. Confidentiality in qualitative research involving vulnerable partic- ipants: Researchers’ perspectives.Forum Qualitative Sozialforschung / Forum: Qualitative Social Research, 19(3), 2018. ISSN 1438-5627. doi: https://doi.org/10.17169/fqs-19.3.3099
-
[39]
Clio: Privacy-preserving insights into real-world ai use.arXiv preprint arXiv:2412.13678, 2024
Alex Tamkin, Miles McCain, Kunal Handa, Esin Durmus, Liane Lovitt, Ankur Rathi, Saffron Huang, Alfred Mountfield, Jerry Hong, Stuart Ritchie, et al. Clio: Privacy-preserving insights into real-world ai use.arXiv preprint arXiv:2412.13678, 2024
arXiv 2024
-
[40]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[41]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[42]
On the vulnerability of text sanitization
Meng Tong, Kejiang Chen, Xiaojian Yuan, Jiayang Liu, Weiming Zhang, Nenghai Yu, and Jie Zhang. On the vulnerability of text sanitization. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5150–5164, 2025
2025
-
[43]
Locally differentially private document genera- tion using zero shot prompting
Saiteja Utpala, Sara Hooker, and Pin-Yu Chen. Locally differentially private document genera- tion using zero shot prompting. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 8442–8457, 2023
2023
-
[44]
Syntf: Synthetic and differentially private term frequency vectors for privacy-preserving text mining
Benjamin Weggenmann and Florian Kerschbaum. Syntf: Synthetic and differentially private term frequency vectors for privacy-preserving text mining. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pages 305–314, 2018
2018
-
[45]
Robust utility-preserving text anonymization based on large language models
Tianyu Yang, Xiaodan Zhu, and Iryna Gurevych. Robust utility-preserving text anonymization based on large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 28922–28941, 2025
2025
-
[46]
Synthetic text generation with differential pri- vacy: A simple and practical recipe
Xiang Yue, Huseyin Inan, Xuechen Li, Girish Kumar, Julia McAnallen, Hoda Shajari, Huan Sun, David Levitan, and Robert Sim. Synthetic text generation with differential pri- vacy: A simple and practical recipe. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Compu- tational Lingui...
-
[47]
doi: 10.18653/v1/2023.acl-long.74
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.74. URL https://aclanthology.org/2023.acl-long.74/. 12
-
[48]
DYNTEXT: Semantic-aware dynamic text sanitization for privacy-preserving LLM inference
Juhua Zhang, Zhiliang Tian, Minghang Zhu, Yiping Song, Taishu Sheng, Siyi Yang, Qiunan Du, Xinwang Liu, Minlie Huang, and Dongsheng Li. DYNTEXT: Semantic-aware dynamic text sanitization for privacy-preserving LLM inference. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational...
-
[49]
Wildchat: 1m chatGPT interaction logs in the wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chatGPT interaction logs in the wild. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=Bl8u7ZRlbM
2024
-
[50]
Gonzalez, Ion Stoica, and Hao Zhang
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Tianle Li, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zhuohan Li, Zi Lin, Eric Xing, Joseph E. Gonzalez, Ion Stoica, and Hao Zhang. LMSYS-chat-1m: A large-scale real-world LLM conversation dataset. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=BOfDKxfwt0
2024
-
[51]
AGE": {
Jijie Zhou, Niloofar Mireshghallah, and Tianshi Li. Operationalizing data minimization for privacy-preserving LLM prompting. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=rpcnvW33EG. 13 A Pipeline Configuration Details Table 2 summarizes the key hyperparameters used in the reported 8-attrib...
2026
-
[52]
What key content existed in the original?
-
[53]
Was it preserved, distorted, or lost in the rewrite?
-
[54]
THEME": {
If lost, what specifically was lost and how severe is the loss? Be precise: cite exact spans from both texts to support your assessment. Output valid JSON only. Phase 2c — user === ORIGINAL TRANSCRIPT === {original_text} === END ORIGINAL === === REWRITTEN TRANSCRIPT === {rewritten_text} === END REWRITTEN === === MASK MAP (original -> replaced) === {mask_m...
-
[55]
Produce HIGH-LEVEL categories that group related quasi-identifiers. Good: RESEARCH_AREA (specific topics/methodologies/subfields) Good: TOOL_STACK (software/platform/framework mentions) Good: PUBLICATION_SIGNATURE (paper titles/venues/co-author patterns) Good: ORG_TYPE (employer or organization category) Good: CAREER_STAGE (early-career/mid-career/senior ...
-
[56]
Merge overlapping quasi-identifiers into a single broader attribute
-
[57]
Avoid micro-level singleton attributes tied to one exact proper noun
-
[58]
Ensure each attribute is actionable for a masker (generalizable, not just removable)
-
[59]
attributes
Return at most {max_attributes} attributes. Return STRICT JSON with this schema: { "attributes": [ { "key": "UPPERCASE_SHORT_KEY", "display_name": "Human-friendly name", "target_str": "what this attribute targets in text", "options": ["optional", "categorical", "values"], "note": "optional note" } ] } Rules: - All returned attributes must be different fro...
-
[60]
Presidio[ 26]: Microsoft’s open-source NER-based PII detection and replacement tool, applied to the full transcript
-
[61]
rewrite the transcript to remove sensitive information so the interviewee cannot be re-identified while maintaining the insight
Minimal one-shot rewriting: End-to-end LLM rewriting with a minimal instruction (“rewrite the transcript to remove sensitive information so the interviewee cannot be re-identified while maintaining the insight”) to simulate the day-to-day usage of an anonymizer
-
[62]
Detailed one-shot rewriting: End-to-end LLM rewriting with a detailed prompt that specifies what to change (names, organizations, job titles, numbers) and what to preserve (subjective content, dialogue structure, voice), emulating the goals of our pipeline in a single pass
-
[63]
Advanced Anonymizer[ 35]: Iterative adversarial LLM anonymization with feedback-guided rounds
-
[64]
ChatGPT” → “an AI tool
DP-MLM( ε∈ {10,30,50,70,100,120,140} ) [24]: Differentially private text rewriting using masked language models with per-token ε-DP guarantees. We evaluate at seven privacy budgets to characterize the full privacy–utility curve from aggressive perturbation to relatively loose privacy settings. Baseline behavior under stronger attackers.The non-DP baseline...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.