PatchWorld: Gradient-Free Optimization of Executable World Models
Pith reviewed 2026-06-28 22:46 UTC · model grok-4.3
The pith
PatchWorld turns offline trajectories into executable Python belief-state programs that support planning under partial observability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
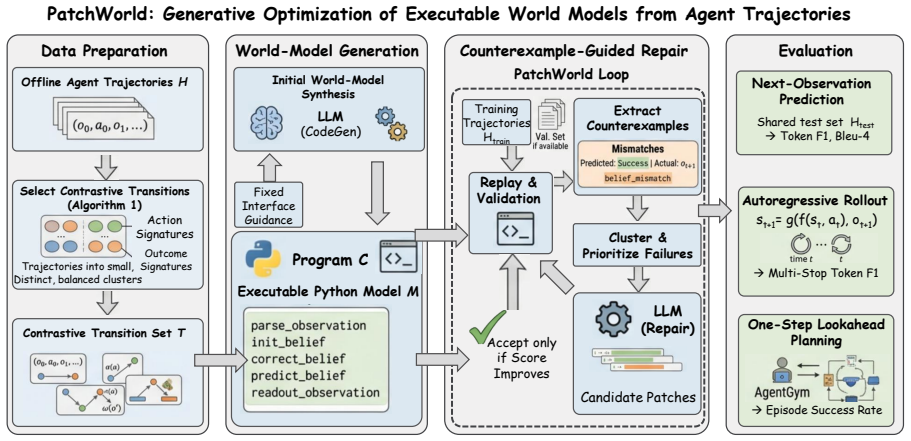
PatchWorld is a gradient-free framework that turns offline trajectories into executable Python world models through counterexample-guided code repair. It induces symbolic belief-state programs whose action updates can be inspected, replayed, and locally patched. Across seven AgentGym environments, PatchWorld-Simple achieves the highest code-based planning score among evaluated methods, reaching 76.4% macro success in live one-step lookahead while invoking no LLM calls inside the world-model prediction module itself. A human-specified residual-memory bias improves surface observation fidelity but weakens decision utility, exposing a tradeoff in executable world models.
What carries the argument
Counterexample-guided code repair that converts offline trajectories into executable belief-state programs whose dynamics are directly inspectable and patchable.
If this is right
- Code-based planning can reach higher macro success than other evaluated methods in the seven AgentGym environments.
- World-model prediction can run with no LLM calls inside the module itself.
- Symbolic programs allow direct inspection, replay, and local patching of action updates.
- Introducing a residual-memory bias trades higher observation fidelity for lower action-discriminative utility.
Where Pith is reading between the lines
- The same repair process could be applied to trajectory data from non-text domains such as grid-world navigation or simple robotics simulators.
- Eliminating internal LLM calls during prediction may reduce latency and cost for repeated lookahead steps in long-horizon tasks.
- Automated search over possible memory biases could replace the human-specified residual term to locate better fidelity-utility balances.
- Executable models of this form offer an alternative substrate for agent training loops that require verifiable dynamics.
Load-bearing premise
That counterexample-guided code repair applied to offline trajectories can reliably produce executable belief-state programs whose dynamics support effective planning under partial observability.
What would settle it
A controlled test showing that programs produced by the repair process yield planning success rates no higher than black-box baselines when trajectories contain higher noise or when environments exhibit stronger partial observability.
Figures


read the original abstract
Text-agent environments are typically modeled as partially observable Markov decision processes (POMDPs), assuming that the simulator's latent state and transition dynamics are hidden from the agent. Yet little work has examined whether executable code can be induced to serve as a world model for prediction and planning under partial observability. We introduce PatchWorld, a gradient-free framework that turns offline trajectories into executable Python world models through counterexample-guided code repair. Instead of predicting the next observation with a black-box model, PatchWorld induces symbolic belief-state programs whose action updates can be inspected, replayed, and locally patched. Across seven AgentGym environments, PatchWorld-Simple achieves the highest code-based planning score among evaluated methods, reaching 76.4\% macro success in live one-step lookahead while invoking no LLM calls inside the world-model prediction module itself. We further find that a human-specified residual-memory bias improves surface observation fidelity but weakens decision utility. This exposes a tradeoff in executable world models, since improving observation fidelity can come at the expense of action-discriminative dynamics, and vice versa. Code is available at https://github.com/HKBU-KnowComp/PatchWorld.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PatchWorld, a gradient-free framework that induces executable Python world models from offline trajectories via counterexample-guided code repair for POMDP-style text-agent environments. It claims that the resulting symbolic belief-state programs enable effective one-step lookahead planning without internal LLM calls during prediction, with PatchWorld-Simple achieving the highest code-based planning score (76.4% macro success) across seven AgentGym environments. The work also reports a fidelity-utility tradeoff, where a human-specified residual-memory bias improves observation replay fidelity at the cost of decision utility.
Significance. If the central empirical claims hold under scrutiny, the contribution would be notable for demonstrating an interpretable, patchable alternative to black-box neural world models in partially observable settings, with strengths in code availability and the identification of an explicit tradeoff between fidelity and planning utility.
major comments (2)
- [Abstract / Method] Abstract and method description: The headline result of 76.4% macro success in live one-step lookahead planning rests on the claim that counterexample-guided repair produces executable belief-state programs whose transition and observation functions support decision-making under partial observability. However, the repair process is described as operating on offline trajectories of (action, observation) pairs; no mechanism is specified to enforce maintenance and updating of latent beliefs across timesteps rather than surface-level fitting, which directly undermines the planning evaluation.
- [Abstract] Abstract: The reported fidelity-utility tradeoff (human-specified residual-memory bias improves surface fidelity but weakens decision utility) is presented as a key finding, yet the manuscript supplies no quantitative ablation, statistical tests, or controls showing that the bias is the causal factor rather than an artifact of the repair objective or environment selection.
minor comments (2)
- [Abstract] The abstract states performance numbers and a tradeoff finding but supplies no experimental details, baselines, statistical tests, or verification steps; these should be summarized even at high level.
- Notation for 'code-based planning score' and 'macro success' is used without an explicit definition or reference to how success is computed in the presence of partial observability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below, providing clarifications and indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: The headline result of 76.4% macro success in live one-step lookahead planning rests on the claim that counterexample-guided repair produces executable belief-state programs whose transition and observation functions support decision-making under partial observability. However, the repair process is described as operating on offline trajectories of (action, observation) pairs; no mechanism is specified to enforce maintenance and updating of latent beliefs across timesteps rather than surface-level fitting, which directly undermines the planning evaluation.
Authors: We agree that the current description requires greater precision on this point. The induced programs are executable Python functions that explicitly maintain internal state variables to represent latent beliefs (see Section 3), and the counterexample-guided repair operates on full trajectory rollouts that include sequential state updates. However, we acknowledge that the manuscript does not provide a sufficiently explicit account of how belief maintenance is enforced during repair rather than surface-level observation fitting. We will revise Section 3 to include a dedicated subsection and pseudocode detailing the belief-state representation, the update rule across timesteps, and how the repair objective penalizes inconsistent belief trajectories. revision: yes
-
Referee: [Abstract] Abstract: The reported fidelity-utility tradeoff (human-specified residual-memory bias improves surface fidelity but weakens decision utility) is presented as a key finding, yet the manuscript supplies no quantitative ablation, statistical tests, or controls showing that the bias is the causal factor rather than an artifact of the repair objective or environment selection.
Authors: We concur that the fidelity-utility tradeoff claim would be more robust with additional empirical controls. The manuscript reports the observed differences in replay fidelity and planning utility when the residual-memory bias is introduced, but does not include formal ablations isolating its causal effect or statistical significance testing. We will add a new subsection with quantitative ablations (varying the bias while holding the repair objective fixed), controls across environment subsets, and appropriate statistical tests. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper introduces PatchWorld as a gradient-free code-repair procedure evaluated via macro success rates on seven AgentGym environments. No equations, fitted parameters, or first-principles derivations appear in the provided text. The 76.4% planning score is presented as a comparative empirical outcome rather than a quantity derived from or equivalent to any input by construction. No self-citations are invoked as load-bearing uniqueness theorems. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Genie: Generative interactive environments. Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, and Yoshua Bengio. 2019. BabyAI: First steps towards grounded language learning with a hu- man in the loop. InInternational Conference on Learning Representations. Marc-Alexandre Côté, Ákos Kádár, Xingdi ...
-
[2]
In Proceedings of the 42nd acm sigplan international conference on programming language design and implementation, pages 835–850
Dreamcoder: Bootstrapping inductive pro- gram synthesis with wake-sleep library learning. In Proceedings of the 42nd acm sigplan international conference on programming language design and implementation, pages 835–850. Tianqing Fang, Hongming Zhang, Zhisong Zhang, Kaixin Ma, Wenhao Yu, Haitao Mi, and Dong Yu
-
[3]
InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 8959– 8975, Suzhou, China
WebEvolver: Enhancing web agent self- improvement with co-evolving world model. InPro- ceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pages 8959– 8975, Suzhou, China. Association for Computational Linguistics. Christopher Grimm, André Barreto, Satinder Singh, and David Silver. 2020. The value equivalence principle f...
2025
-
[4]
Program synthesis.Found. Trends Program. Lang., 4(1–2):1–119. David Ha and Jürgen Schmidhuber. 2018. World mod- els.CoRR, abs/1803.10122. Danijar Hafner, T. Lillicrap, Jimmy Ba, and Moham- mad Norouzi. 2019. Dream to control: Learning behaviors by latent imagination. Mengkang Hu, Tianxing Chen, Yude Zou, Yuheng Lei, Qiguang Chen, Ming Li, Yao Mu, Hongyuan...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Armando Solar-Lezama, Liviu Tancau, Rastislav Bodik, Sanjit Seshia, and Vijay Saraswat
OpenReview.net. Armando Solar-Lezama, Liviu Tancau, Rastislav Bodik, Sanjit Seshia, and Vijay Saraswat. 2006. Combinato- rial sketching for finite programs. InProceedings of the 12th International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS XII, page 404–415, New York, NY , USA. Association for Computing Mac...
-
[6]
arXiv preprint arXiv:2510.02387 , year =
LLMs as planning formalizers: A survey for leveraging large language models to construct auto- mated planning models. InFindings of the Asso- ciation for Computational Linguistics: ACL 2025, pages 25167–25188, Vienna, Austria. Association for Computational Linguistics. FAIR CodeGen team, Jade Copet, Quentin Carbon- neaux, Gal Cohen, Jonas Gehring, Jacob K...
-
[7]
For PatchWorld, this calls correct_belief; for WorldCoder/PoE- World, the program’s transition; for LLM- Direct, an ICL prompt that conditions on the lastk=3transitions
Belief update.On observation ot, the world model ingests (ot−1, at−1, ot) and updates its internal state. For PatchWorld, this calls correct_belief; for WorldCoder/PoE- World, the program’s transition; for LLM- Direct, an ICL prompt that conditions on the lastk=3transitions
-
[8]
Up to four ad- ditional diverse candidates are drawn from the environment’s exposed action API (dedu- plicated and capped at eight total candidates, including the default)
Candidate generation.A ReAct policy pro- poses a default action adefault. Up to four ad- ditional diverse candidates are drawn from the environment’s exposed action API (dedu- plicated and capped at eight total candidates, including the default)
-
[9]
No multi-step rollout is used in this study; the lookahead depth is exactly one
Lookahead rollout.For each candidate a(i), the world model predicts ˆo(i) t+1. No multi-step rollout is used in this study; the lookahead depth is exactly one
-
[10]
The gate falls back to adefault when (a) no candidate beats the default by a fixed mar- gin or (b) the world model returns an empty / parse-failed prediction
Reranking with a gate.A shared Qwen3- Coder-480B selector scores (ot, a(i),ˆo(i) t+1) tu- ples. The gate falls back to adefault when (a) no candidate beats the default by a fixed mar- gin or (b) the world model returns an empty / parse-failed prediction. This avoids penaliz- ing strong reactive baselines when the world model adds no signal
-
[11]
Identical
Termination.Episodes terminate on envi- ronment success, environment failure, or a 30-step cap, whichever comes first. Each en- vironment uses up to 200 held-out instances. The selector, candidate cap, and step cap are identical across all rows in Figure 3 and Table 11. I Per-Task Planning Results Table 11: Episode success rate (%) per environment under t...
2028
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.