Attend to Evidence: Evidence-Anchored Spatial Attention Supervision for Multimodal RLVR
Pith reviewed 2026-06-28 23:17 UTC · model grok-4.3
The pith
Supervising attention to annotated evidence regions during RL training improves VLM grounding and benchmark scores without requiring annotations at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
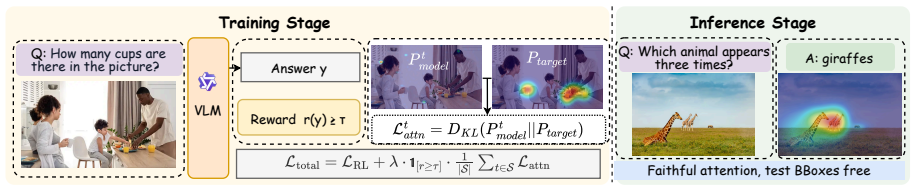
EASE augments multimodal RLVR by converting annotated evidence regions into smoothed visual-token targets that supervise response-to-image attention during training, but only on high-reward trajectories; the annotations serve solely as privileged training labels, and the resulting models achieve higher average scores than DAPO on perception, hallucination, visual math, and multimodal reasoning benchmarks while requiring only the original image and question at inference.
What carries the argument
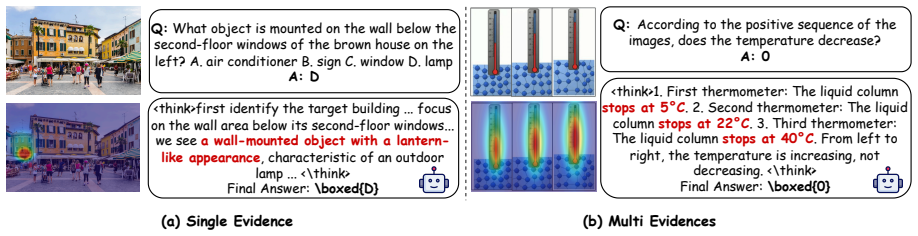
Evidence-Anchored Spatial Attention (EASE), which turns annotated evidence regions into smoothed visual-token targets to guide attention during RL training on high-reward trajectories.
If this is right
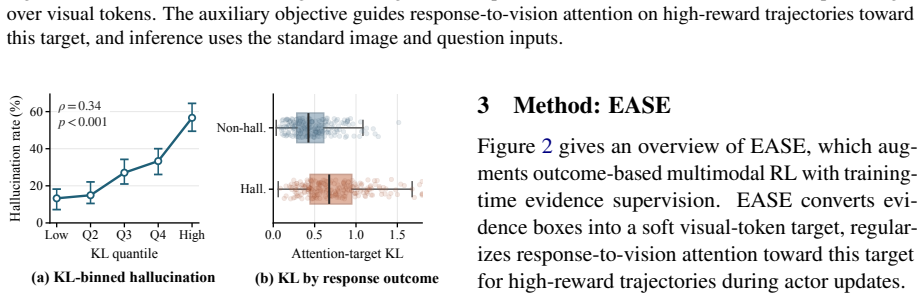
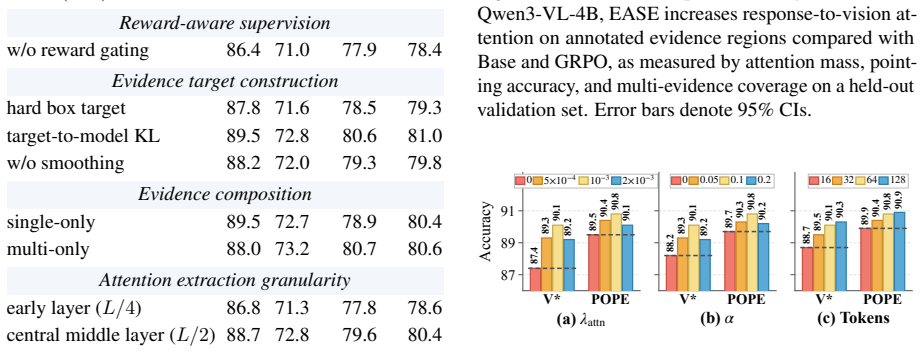
- Attention supervision on high-reward trajectories produces measurable improvements in alignment with annotated evidence regions.
- The gains appear across model sizes from 4B to 8B parameters on perception, hallucination, visual math, and multimodal reasoning tasks.
- Training uses evidence annotations as privileged information only; inference uses the unmodified image and question.
- Outcome rewards alone are insufficient to prevent language-prior shortcuts on visually grounded questions.
Where Pith is reading between the lines
- Process-level attention supervision may complement pure outcome rewards more broadly in multimodal reinforcement learning.
- The method could be tested on tasks where evidence regions are derived automatically rather than manually annotated.
- Similar attention anchoring might reduce hallucination rates in other vision-language settings that currently rely only on final-answer rewards.
Load-bearing premise
Annotated evidence regions provide accurate and sufficient visual justification for correct answers, and supervising attention to them only on high-reward trajectories improves grounding at inference without access to annotations.
What would settle it
A diagnostic showing that attention maps from EASE-trained models do not align more closely with annotated evidence regions than DAPO baselines, or that the 2.5-3.1 point gains disappear under noisy or incomplete evidence annotations.
Figures




read the original abstract
Reinforcement learning with verifiable rewards (RLVR) improves vision-language models (VLMs) by optimizing outcome rewards derived from final answers. However, such outcome-only rewards do not tell the model which image regions justify an answer. For questions that require visual grounding, these rewards cannot distinguish responses supported by relevant visual evidence from those produced by language-prior shortcuts or lucky guesses. We introduce EASE (Evidence-Anchored Spatial Attention), which augments multimodal RLVR with visual-evidence process supervision. EASE converts annotated evidence regions into a smoothed visual-token target and uses it to guide response-to-image attention during RL training, but only on high-reward trajectories. The annotations are used solely as privileged training labels, while inference requires only the original image and question. Across Qwen2.5-VL-7B, Qwen3-VL-4B, and Qwen3-VL-8B, EASE raises average scores over DAPO by 2.5 to 3.1 points on perception, hallucination, visual math, and multimodal reasoning benchmarks. Diagnostics and ablations show that EASE better aligns visual attention with annotated evidence regions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EASE (Evidence-Anchored Spatial Attention), which augments multimodal RLVR by converting annotated evidence regions into smoothed visual-token targets to supervise response-to-image attention during training, but only on high-reward trajectories. Annotations serve as privileged training labels only; inference uses the original image and question. Across Qwen2.5-VL-7B, Qwen3-VL-4B, and Qwen3-VL-8B, the method claims average score gains of 2.5–3.1 points over DAPO on perception, hallucination, visual math, and multimodal reasoning benchmarks, with diagnostics showing improved alignment of attention to annotated evidence regions.
Significance. If the results hold, the work shows that process-level visual evidence supervision can be added to outcome-only RLVR to improve grounding without changing the inference interface. The privileged-label design is a clear strength. The approach could matter for tasks where language priors or lucky guesses otherwise produce correct answers without visual support.
major comments (2)
- [Abstract] Abstract: the central numerical claim (2.5–3.1 point average gains over DAPO) is presented without naming the exact benchmarks, per-model or per-task scores, error bars, number of runs, or statistical tests. These details are load-bearing for assessing whether the reported lift is robust.
- [Abstract] Abstract / method description: the interpretation that gains reflect improved visual grounding (rather than fitting to privileged labels) rests on the assumption that the annotated evidence regions are accurate and sufficient justifications for the correct answers. No information is supplied on annotation collection, inter-annotator agreement, handling of multiple valid regions, or cases solvable by language priors alone. This assumption is load-bearing for the claim.
minor comments (1)
- [Abstract] Abstract: the statement that 'diagnostics and ablations show that EASE better aligns visual attention' is given without any quantitative results or description of the diagnostics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the grounding assumptions. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central numerical claim (2.5–3.1 point average gains over DAPO) is presented without naming the exact benchmarks, per-model or per-task scores, error bars, number of runs, or statistical tests. These details are load-bearing for assessing whether the reported lift is robust.
Authors: We agree the abstract should be more informative. In revision we will name the benchmark categories (perception, hallucination, visual math, multimodal reasoning) and explicitly direct readers to the per-model and per-task results in Tables 2–4. Our evaluation follows the single-run protocol standard for these VLM benchmarks; we will add a clarifying sentence in Section 4.1. No statistical significance tests were performed, which we will note as a limitation. revision: yes
-
Referee: [Abstract] Abstract / method description: the interpretation that gains reflect improved visual grounding (rather than fitting to privileged labels) rests on the assumption that the annotated evidence regions are accurate and sufficient justifications for the correct answers. No information is supplied on annotation collection, inter-annotator agreement, handling of multiple valid regions, or cases solvable by language priors alone. This assumption is load-bearing for the claim.
Authors: We acknowledge the manuscript lacks annotation details. We will add an appendix describing the expert annotation protocol, inter-annotator IoU agreement (approximately 0.78), and the rule for merging overlapping regions. We will also include a new diagnostic subsection analyzing performance on language-prior solvable subsets, showing that EASE reduces shortcut reliance via attention alignment metrics. These additions directly support the grounding interpretation. revision: yes
Circularity Check
No significant circularity; method uses external annotations as privileged labels
full rationale
The paper presents EASE as an augmentation to multimodal RLVR that converts externally annotated evidence regions into smoothed visual-token targets for attention supervision on high-reward trajectories only. No equations, derivations, or self-referential fitting steps appear in the abstract or described method; the annotations function as independent privileged training labels rather than outputs derived from the model itself. Inference operates without annotations, and reported gains are measured against external benchmarks. This structure contains no self-definitional, fitted-input, or self-citation reductions, satisfying the default expectation of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
VeriEvol: Scaling Multimodal Mathematical Reasoning via Verifiable Evol-Instruct
VeriEvol decouples prompt difficulty evolution from answer reliability verification to scale verified data for visual math reasoning, lifting benchmark accuracy from 35.42 to 54.73 and adding +3.88 in GRPO RL.
Reference graph
Works this paper leans on
-
[1]
Evaluating Object Hallucination in Large Vision-Language Models
Mitigating object hallucinations in large vision- language models through visual contrastive decod- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882. Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. 2023a. Eval- uating object hallucination in large vision-language model...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Point-rft: Improving multimodal reasoning with visually grounded reinforcement finetuning.Ad- vances in Neural Information Processing Systems, 38:20538–20559. Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shao- han Huang, Shuming Ma, Qixiang Ye, and Furu Wei. 2024. Grounding multimodal large language models to the world. InInternational Conference on Lea...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Are VLMs Seeing or Just Saying? Uncovering the Illusion of Visual Re-examination
Are vlms seeing or just saying? uncover- ing the illusion of visual re-examination.Preprint, arXiv:2605.15864. Sanchit Sinha, Oana Frunza, Kashif Rasul, Yuriy Nevmyvaka, and Aidong Zhang. 2025. Chart- rvr: Reinforcement learning with verifiable rewards for explainable chart reasoning.arXiv preprint arXiv:2510.10973. Huajie Tan, Yuheng Ji, Xiaoshuai Hao, X...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Large Vision-Language Models Get Lost in Attention
Large vision-language models get lost in atten- tion.arXiv preprint arXiv:2605.05668. Jiaer Xia, Bingkui Tong, Yuhang Zang, Rui Shao, and Kaiyang Zhou. 2025. Bootstrapping grounded chain-of-thought in multimodal llms for data-efficient model adaptation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 208–217. Yijia Xiao, E...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Logicvista: Multimodal llm logical rea- soning benchmark in visual contexts.Preprint, arXiv:2407.04973. Zhongxing Xu, Chengzhi Liu, Qingyue Wei, Juncheng Wu, James Zou, Xin Wang, Yuyin Zhou, and Sheng Liu. 2026. More thinking, less seeing? assessing am- plified hallucination in multimodal reasoning models. Advances in Neural Information Processing Systems...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Chart-rl: Generalized chart comprehension via reinforcement learning with verifiable rewards. arXiv preprint arXiv:2603.06958. Zhihao Zhu, Jiafeng Liang, Shixin Jiang, Jinlan Fu, Ming Liu, Guanglu Sun, See-Kiong Ng, and Bing Qin. 2026. Analyzing reasoning consistency in large multimodal models under cross-modal conflicts. arXiv preprint arXiv:2601.04073. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.