BiSegMamba: Efficient Bidirectional Tri-Oriented Mamba for 3D Medical Image Segmentation
Pith reviewed 2026-06-28 22:57 UTC · model grok-4.3
The pith
BiSegMamba processes 3D medical volumes bidirectionally across three orthogonal directions with adaptive fusion to cut computation while preserving segmentation accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
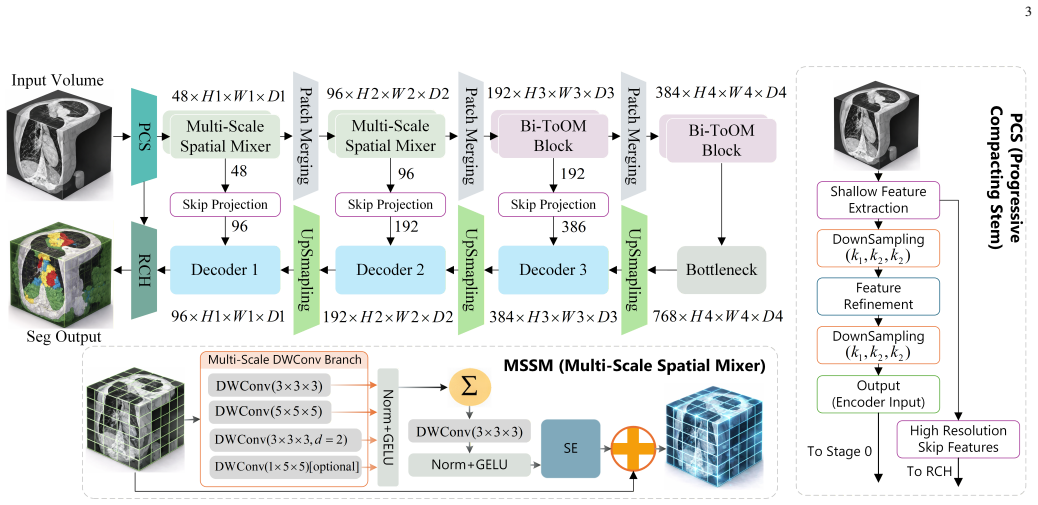
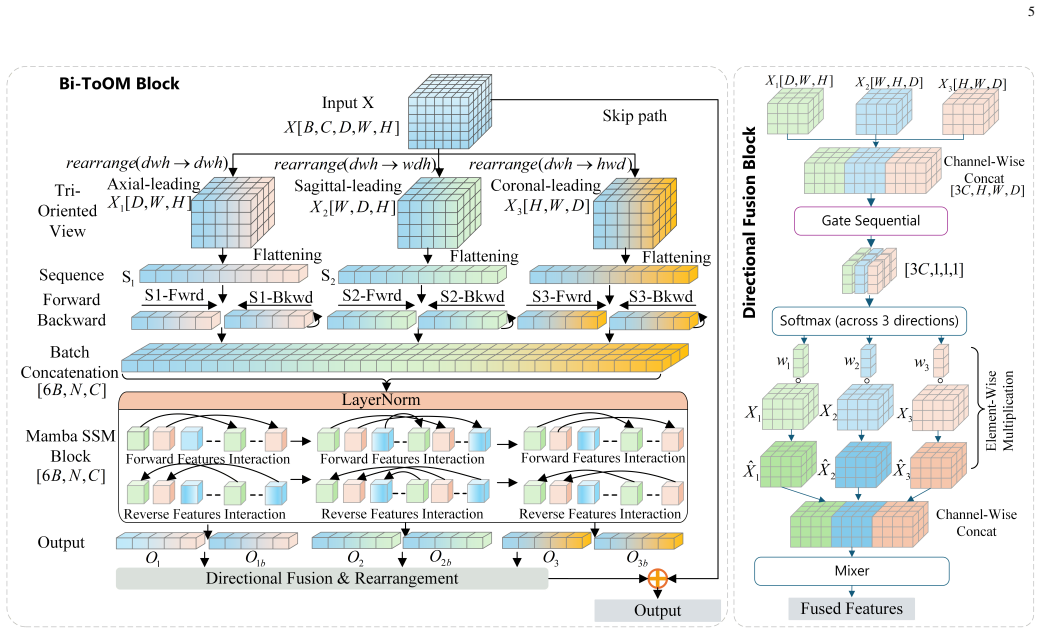
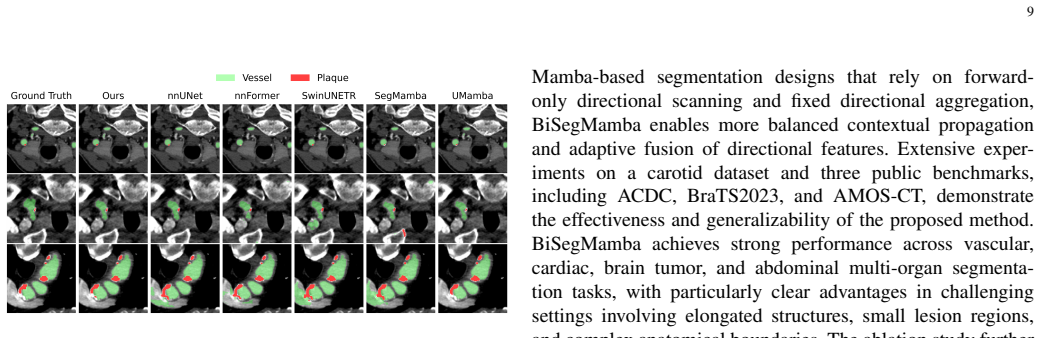
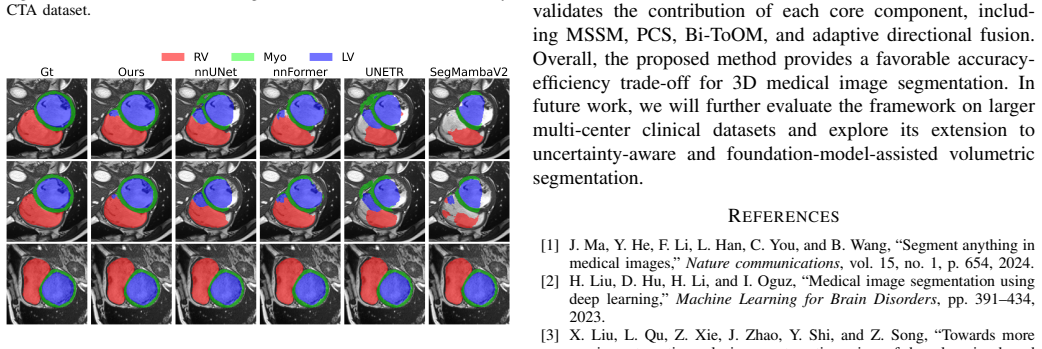
BiSegMamba follows a compact-to-detail layout in which a progressive compacting stem keeps shallow high-resolution features for reconstruction while shifting reasoning to a compact latent space; a multi-scale spatial mixer handles local anatomy early on; bidirectional tri-oriented Ortho Mamba blocks jointly process forward and backward sequences from three orthogonal views; and adaptive directional fusion replaces fixed summation with input-dependent channel-wise weights across orientations. On a carotid CTA collection and the BraTS2023, ACDC, and AMOS-CT benchmarks this yields segmentation performance that is slightly better on brain tumors, clearly better on cardiac and vascular cases, and
What carries the argument
The bidirectional tri-oriented Ortho Mamba (Bi-ToOM) block, which jointly processes forward and backward scan sequences from multiple orthogonal views, together with adaptive directional fusion (ADF) that learns input-dependent weights to replace fixed directional summation.
If this is right
- BiSegMamba matches or exceeds SegMamba-V2 on BraTS2023 while using substantially fewer FLOPs.
- Clear accuracy gains appear on ACDC cardiac and carotid vascular segmentation tasks.
- The same architecture generalizes across brain-tumor, cardiac, vascular, and abdominal multi-organ volumes.
- Peak memory and compute drop enough to support denser or higher-resolution 3D inputs on the same hardware.
Where Pith is reading between the lines
- The adaptive fusion mechanism could be ported to other multi-view or multi-directional sequence models outside medical imaging.
- The compact-to-detail stem pattern may reduce memory pressure in any 3D vision task that must retain fine surface detail.
- If the bidirectional tri-oriented scanning proves robust, similar joint forward-backward processing could be tested on 4D or time-series volumetric data.
- Hardware benchmarks on edge devices would show whether the reported FLOPs reduction translates into clinically usable inference speed.
Load-bearing premise
Observed accuracy and efficiency gains on the carotid CTA set and the three public benchmarks are caused by the progressive compacting stem, multi-scale spatial mixer, bidirectional tri-oriented blocks, and adaptive fusion rather than by differences in training schedules, preprocessing, or hyper-parameters.
What would settle it
Re-train both BiSegMamba and SegMamba-V2 from scratch on identical data splits, preprocessing pipelines, and hyper-parameter settings for the carotid CTA, ACDC, and BraTS2023 datasets, then compare Dice scores and measured FLOPs.
Figures


read the original abstract
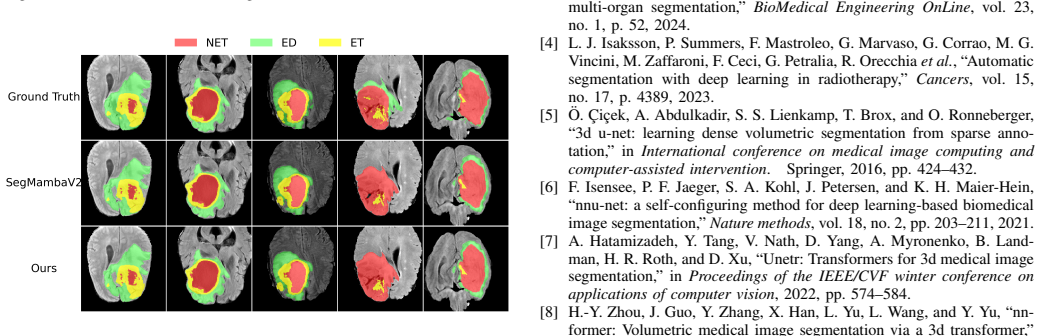
Accurate 3D medical image segmentation requires both long-range volumetric context and fine boundary preservation. CNN-based methods have limited global dependency modeling, while Transformer-based models are often computationally expensive for dense 3D inputs. Recent Mamba-based methods provide an efficient alternative, but existing volumetric designs still depend on repeated high-resolution scanning, forward-only sequential modeling, and fixed directional summation, causing high cost, scan-order bias, and suboptimal directional aggregation. We propose BiSegMamba, an efficient bidirectional tri-oriented Mamba network for 3D medical image segmentation. BiSegMamba follows a compact-to-detail design, where a progressive compacting stem (PCS) enables efficient latent-space reasoning while retaining shallow high-resolution features for reconstruction. A multi-scale spatial mixer (MSSM) captures local anatomical patterns in early stages, and the proposed bidirectional tri-oriented Ortho Mamba (Bi-ToOM) block models long-range dependencies from multiple orthogonal views using jointly processed forward and backward scan sequences. Adaptive directional fusion (ADF) learns input-dependent channel-wise weights across scan orientations, replacing fixed summation with orientation-aware fusion. Experiments on a collected carotid CTA dataset and three public benchmarks, BraTS2023, ACDC, and AMOS-CT, show that BiSegMamba generalizes well across vascular, cardiac, brain tumor, and abdominal multi-organ segmentation tasks. Compared with SegMamba-V2, BiSegMamba achieves slightly better performance on BraTS2023 and clear improvements on ACDC and the carotid dataset, while reducing computational cost by up to 77.9% FLOPs, demonstrating a strong accuracy-efficiency balance for general 3D medical image segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BiSegMamba, a Mamba-based 3D segmentation network that introduces a progressive compacting stem (PCS), multi-scale spatial mixer (MSSM), bidirectional tri-oriented Ortho Mamba (Bi-ToOM) block, and adaptive directional fusion (ADF) to enable efficient bidirectional multi-view long-range modeling while preserving high-resolution details. It reports competitive or superior Dice scores to SegMamba-V2 on BraTS2023, ACDC, AMOS-CT, and a private carotid CTA dataset, together with up to 77.9% FLOPs reduction, claiming a favorable accuracy-efficiency trade-off across vascular, cardiac, brain-tumor, and abdominal tasks.
Significance. If the reported gains prove attributable to the architectural components under matched training conditions, the work would advance practical Mamba designs for dense 3D medical volumes by mitigating scan-order bias and fixed directional summation, offering a lower-cost alternative to Transformer-based models without sacrificing volumetric context.
major comments (3)
- [§4 Experiments] §4 Experiments (including Table 1 and any protocol description): The manuscript provides no explicit statement, table, or supplementary material confirming that all baselines (SegMamba-V2 and others) were trained and evaluated with identical data splits, preprocessing, augmentation pipelines, optimizer schedules, and epoch counts as BiSegMamba. Without this parity, the attribution of the observed Dice improvements on ACDC and carotid CTA, as well as the 77.9% FLOPs reduction, to PCS/MSSM/Bi-ToOM/ADF remains unverified.
- [§4.3 Ablation studies] §4.3 Ablation studies (if present) or §4.2 comparative tables: No ablation isolating each proposed module (PCS, MSSM, Bi-ToOM, ADF) under fixed training settings is referenced in the experimental summary; without such controlled ablations the individual contributions cannot be disentangled from possible hyperparameter or implementation differences.
- [Table 1] Table 1 (quantitative results): All reported metrics are single point estimates with neither standard deviations from multiple random seeds nor statistical significance tests, so it is impossible to judge whether the “slightly better” BraTS2023 result or the “clear improvements” on ACDC/carotid are reliable.
minor comments (2)
- [Abstract] Abstract: the phrase “up to 77.9% FLOPs” should specify the exact dataset, input resolution, and baseline configuration that produces the maximum reduction.
- Notation: the acronym CTA is used without expansion on first appearance; likewise, the precise meaning of “tri-oriented” and “Ortho Mamba” should be clarified at their first use in §3.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment point by point below and commit to revisions that enhance experimental transparency without misrepresenting the original work.
read point-by-point responses
-
Referee: [§4 Experiments] §4 Experiments (including Table 1 and any protocol description): The manuscript provides no explicit statement, table, or supplementary material confirming that all baselines (SegMamba-V2 and others) were trained and evaluated with identical data splits, preprocessing, augmentation pipelines, optimizer schedules, and epoch counts as BiSegMamba. Without this parity, the attribution of the observed Dice improvements on ACDC and carotid CTA, as well as the 77.9% FLOPs reduction, to PCS/MSSM/Bi-ToOM/ADF remains unverified.
Authors: We agree that explicit confirmation of matched experimental conditions is essential for attributing gains to the proposed components. Although our implementation used identical protocols for all models, the manuscript omitted a clear statement of this parity. In the revision we will add a dedicated paragraph in §4 explicitly listing the shared data splits, preprocessing, augmentations, optimizer, learning-rate schedule, and epoch count, and state that SegMamba-V2 and other baselines were retrained or evaluated under these exact settings. revision: yes
-
Referee: [§4.3 Ablation studies] §4.3 Ablation studies (if present) or §4.2 comparative tables: No ablation isolating each proposed module (PCS, MSSM, Bi-ToOM, ADF) under fixed training settings is referenced in the experimental summary; without such controlled ablations the individual contributions cannot be disentangled from possible hyperparameter or implementation differences.
Authors: The referee is correct that the current experimental section does not contain module-isolated ablations. We will add a new subsection 4.3 that starts from a common baseline and incrementally incorporates PCS, MSSM, Bi-ToOM, and ADF under strictly fixed training settings, reporting Dice and FLOPs at each step. This controlled study will directly quantify the contribution of each component. revision: yes
-
Referee: [Table 1] Table 1 (quantitative results): All reported metrics are single point estimates with neither standard deviations from multiple random seeds nor statistical significance tests, so it is impossible to judge whether the “slightly better” BraTS2023 result or the “clear improvements” on ACDC/carotid are reliable.
Authors: We acknowledge that single-run point estimates limit statistical interpretation. In the revised manuscript we will rerun the key comparisons (BiSegMamba vs. SegMamba-V2) on BraTS2023, ACDC, and the carotid dataset with at least three different random seeds, reporting mean Dice scores and standard deviations. This will allow readers to assess the reliability of the reported gains. revision: yes
Circularity Check
No significant circularity; empirical architecture validated on external benchmarks
full rationale
The manuscript introduces architectural modules (PCS, MSSM, Bi-ToOM, ADF) and reports empirical gains versus SegMamba-V2 on BraTS2023, ACDC, AMOS-CT and a carotid CTA dataset. No derivation chain, equations, or first-principles predictions appear; performance attribution rests on experimental comparisons rather than any self-definitional mapping, fitted-input relabeling, or self-citation load-bearing step. The work is therefore self-contained against external benchmarks with no reduction of claims to their own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Bidirectional tri-oriented Ortho Mamba (Bi-ToOM) block
no independent evidence
-
Adaptive directional fusion (ADF)
no independent evidence
-
Progressive compacting stem (PCS)
no independent evidence
-
Multi-scale spatial mixer (MSSM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Segment anything in medical images,
J. Ma, Y . He, F. Li, L. Han, C. You, and B. Wang, “Segment anything in medical images,”Nature communications, vol. 15, no. 1, p. 654, 2024
2024
-
[2]
Medical image segmentation using deep learning,
H. Liu, D. Hu, H. Li, and I. Oguz, “Medical image segmentation using deep learning,”Machine Learning for Brain Disorders, pp. 391–434, 2023
2023
-
[3]
Towards more precise automatic analysis: a systematic review of deep learning-based multi-organ segmentation,
X. Liu, L. Qu, Z. Xie, J. Zhao, Y . Shi, and Z. Song, “Towards more precise automatic analysis: a systematic review of deep learning-based multi-organ segmentation,”BioMedical Engineering OnLine, vol. 23, no. 1, p. 52, 2024
2024
-
[4]
Automatic segmentation with deep learning in radiotherapy,
L. J. Isaksson, P. Summers, F. Mastroleo, G. Marvaso, G. Corrao, M. G. Vincini, M. Zaffaroni, F. Ceci, G. Petralia, R. Orecchiaet al., “Automatic segmentation with deep learning in radiotherapy,”Cancers, vol. 15, no. 17, p. 4389, 2023
2023
-
[5]
3d u-net: learning dense volumetric segmentation from sparse anno- tation,
¨O. C ¸ ic ¸ek, A. Abdulkadir, S. S. Lienkamp, T. Brox, and O. Ronneberger, “3d u-net: learning dense volumetric segmentation from sparse anno- tation,” inInternational conference on medical image computing and computer-assisted intervention. Springer, 2016, pp. 424–432
2016
-
[6]
nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,
F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,”Nature methods, vol. 18, no. 2, pp. 203–211, 2021
2021
-
[7]
Unetr: Transformers for 3d medical image segmentation,
A. Hatamizadeh, Y . Tang, V . Nath, D. Yang, A. Myronenko, B. Land- man, H. R. Roth, and D. Xu, “Unetr: Transformers for 3d medical image segmentation,” inProceedings of the IEEE/CVF winter conference on applications of computer vision, 2022, pp. 574–584
2022
-
[8]
nn- former: V olumetric medical image segmentation via a 3d transformer,
H.-Y . Zhou, J. Guo, Y . Zhang, X. Han, L. Yu, L. Wang, and Y . Yu, “nn- former: V olumetric medical image segmentation via a 3d transformer,” IEEE transactions on image processing, vol. 32, pp. 4036–4045, 2023
2023
-
[9]
Mamba-unet: Unet- like pure visual mamba for medical image segmentation,
Z. Wang, J.-Q. Zheng, Y . Zhang, G. Cui, and L. Li, “Mamba-unet: Unet- like pure visual mamba for medical image segmentation,”arXiv preprint arXiv:2402.05079, 2024
-
[10]
Vm-unet: Vision mamba unet for medical image segmentation,
J. Ruan, J. Li, and S. Xiang, “Vm-unet: Vision mamba unet for medical image segmentation,”ACM Transactions on Multimedia Computing, Communications and Applications, 2024
2024
-
[11]
Vi- sion mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vi- sion mamba: Efficient visual representation learning with bidirectional state space model,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 62 429–62 442
2024
-
[12]
U-Mamba: Enhancing Long-range Dependency for Biomedical Image Segmentation
J. Ma, F. Li, and B. Wang, “U-mamba: Enhancing long-range dependency for biomedical image segmentation,”arXiv preprint arXiv:2401.04722, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation,
Z. Xing, T. Ye, Y . Yang, G. Liu, and L. Zhu, “Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation,” in International conference on medical image computing and computer- assisted intervention. Springer, 2024, pp. 578–588
2024
-
[14]
Segmamba-v2: Long-range sequential modeling mamba for general 3d medical image segmentation,
Z. Xing, T. Ye, Y . Yang, D. Cai, B. Gai, X.-J. Wu, F. Gao, and L. Zhu, “Segmamba-v2: Long-range sequential modeling mamba for general 3d medical image segmentation,”IEEE Transactions on Medical Imaging, 2025. 10
2025
-
[15]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inInternational Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241
2015
-
[16]
V-net: Fully convolutional neural networks for volumetric medical image segmentation,
F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in2016 fourth international conference on 3D vision (3DV). Ieee, 2016, pp. 565–571
2016
-
[17]
Attention U-Net: Learning Where to Look for the Pancreas
O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, K. Mori, S. McDonagh, N. Y . Hammerla, B. Kainzet al., “Atten- tion u-net: Learning where to look for the pancreas,”arXiv preprint arXiv:1804.03999, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
3d mri brain tumor segmentation using autoencoder reg- ularization,
A. Myronenko, “3d mri brain tumor segmentation using autoencoder reg- ularization,” inInternational MICCAI brainlesion workshop. Springer, 2018, pp. 311–320
2018
-
[19]
3d ux-net: A large kernel volumetric convnet modernizing hierarchical transformer for medical image segmentation,
H. H. Lee, S. Bao, Y . Huo, and B. A. Landman, “3d ux-net: A large kernel volumetric convnet modernizing hierarchical transformer for medical image segmentation,” inThe Eleventh International Conference on Learning Representations
-
[20]
Mednext: transformer-driven scaling of convnets for medical image segmentation,
S. Roy, G. Koehler, C. Ulrich, M. Baumgartner, J. Petersen, F. Isensee, P. F. Jaeger, and K. H. Maier-Hein, “Mednext: transformer-driven scaling of convnets for medical image segmentation,” inInternational confer- ence on medical image computing and computer-assisted intervention. Springer, 2023, pp. 405–415
2023
-
[21]
Transbts: Multimodal brain tumor segmentation using transformer,
W. Wang, C. Chen, M. Ding, H. Yu, S. Zha, and J. Li, “Transbts: Multimodal brain tumor segmentation using transformer,” inInterna- tional conference on medical image computing and computer-assisted intervention. Springer, 2021, pp. 109–119
2021
-
[22]
Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation,
Y . Xie, J. Zhang, C. Shen, and Y . Xia, “Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation,” inInternational conference on medical image computing and computer-assisted inter- vention. Springer, 2021, pp. 171–180
2021
-
[23]
Swin-unet: Unet-like pure transformer for medical image segmenta- tion,
H. Cao, Y . Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, and M. Wang, “Swin-unet: Unet-like pure transformer for medical image segmenta- tion,” inEuropean conference on computer vision. Springer, 2022, pp. 205–218
2022
-
[24]
Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,
A. Hatamizadeh, V . Nath, Y . Tang, D. Yang, H. R. Roth, and D. Xu, “Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,” inInternational MICCAI brainlesion workshop. Springer, 2021, pp. 272–284
2021
-
[25]
Transunet: Rethinking the u-net architecture design for medical image segmentation through the lens of transformers,
J. Chen, J. Mei, X. Li, Y . Lu, Q. Yu, Q. Wei, X. Luo, Y . Xie, E. Adeli, Y . Wanget al., “Transunet: Rethinking the u-net architecture design for medical image segmentation through the lens of transformers,”Medical Image Analysis, vol. 97, p. 103280, 2024
2024
-
[26]
Missformer: An effective transformer for 2d medical image segmentation,
X. Huang, Z. Deng, D. Li, X. Yuan, and Y . Fu, “Missformer: An effective transformer for 2d medical image segmentation,”IEEE transactions on medical imaging, vol. 42, no. 5, pp. 1484–1494, 2022
2022
-
[27]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “Vmamba: Visual state space model,”Advances in neural information processing systems, vol. 37, pp. 103 031–103 063, 2024
2024
-
[29]
nn- mamba: 3d biomedical image segmentation, classification and landmark detection with state space model,
H. Gong, L. Kang, Y . Wang, Y . Wang, X. Wan, X. Wu, and H. Li, “nn- mamba: 3d biomedical image segmentation, classification and landmark detection with state space model,” in2025 IEEE 22nd International Symposium on Biomedical Imaging (ISBI). IEEE, 2025, pp. 1–5
2025
-
[30]
Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved?
O. Bernard, A. Lalande, C. Zotti, F. Cervenansky, X. Yang, P.-A. Heng, I. Cetin, K. Lekadir, O. Camara, M. A. G. Ballesteret al., “Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved?”IEEE transactions on medical imaging, vol. 37, no. 11, pp. 2514–2525, 2018
2018
-
[31]
A. F. Kazerooni, N. Khalili, X. Liu, D. Gandhi, Z. Jiang, S. M. Anwar, J. Albrecht, M. Adewole, U. Anazodo, H. Andersonet al., “The brain tumor segmentation in pediatrics (brats-peds) challenge: focus on pediatrics (cbtn-connect-dipgr-asnr-miccai brats-peds),”arXiv preprint arXiv:2404.15009, 2024
-
[32]
Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation,
Y . Ji, H. Bai, C. Ge, J. Yang, Y . Zhu, R. Zhang, Z. Li, L. Zhanng, W. Ma, X. Wanet al., “Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation,”Advances in neural information processing systems, vol. 35, pp. 36 722–36 732, 2022
2022
-
[33]
Swinunetr-v2: Stronger swin transformers with stagewise convolu- tions for 3d medical image segmentation,
Y . He, V . Nath, D. Yang, Y . Tang, A. Myronenko, and D. Xu, “Swinunetr-v2: Stronger swin transformers with stagewise convolu- tions for 3d medical image segmentation,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 416–426
2023
-
[34]
Training like a medical resident: Context-prior learning toward universal medical image segmentation,
Y . Gao, “Training like a medical resident: Context-prior learning toward universal medical image segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 11 194–11 204
2024
-
[35]
Swin smt: Global sequential modeling for enhancing 3d medical image segmentation,
S. Płotka, M. Chrabaszcz, and P. Biecek, “Swin smt: Global sequential modeling for enhancing 3d medical image segmentation,” inInterna- tional Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2024, pp. 689–698
2024
-
[36]
Vsmtrans: A hybrid paradigm integrating self-attention and convolution for 3d medical image segmentation,
T. Liu, Q. Bai, D. A. Torigian, Y . Tong, and J. K. Udupa, “Vsmtrans: A hybrid paradigm integrating self-attention and convolution for 3d medical image segmentation,”Medical image analysis, vol. 98, p. 103295, 2024
2024
-
[37]
Upping the game: How 2d u-net skip connections flip 3d segmenta- tion,
X. Huang, Y . Guo, J. Huang, T. Zhang, H. He, S. Jiang, and Y . Sun, “Upping the game: How 2d u-net skip connections flip 3d segmenta- tion,”Advances in Neural Information Processing Systems, vol. 37, pp. 87 282–87 309, 2024
2024
-
[38]
Mamba goes home: Hierarchical soft mixture-of-experts for 3d medical image segmentation,
S. Płotka, G. Mert, M. Chrabaszcz, E. Szczurek, and A. Sitek, “Mamba goes home: Hierarchical soft mixture-of-experts for 3d medical image segmentation,”Advances in Neural Information Processing Systems, vol. 38, pp. 97 871–97 909, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.