Combinatorial Synthesis: Scaling Code RLVR via Atomic Decomposition and Recombination
Pith reviewed 2026-06-28 23:06 UTC · model grok-4.3
The pith
Decomposing code tasks into atoms and recombining them generates harder, more original training data for RLVR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
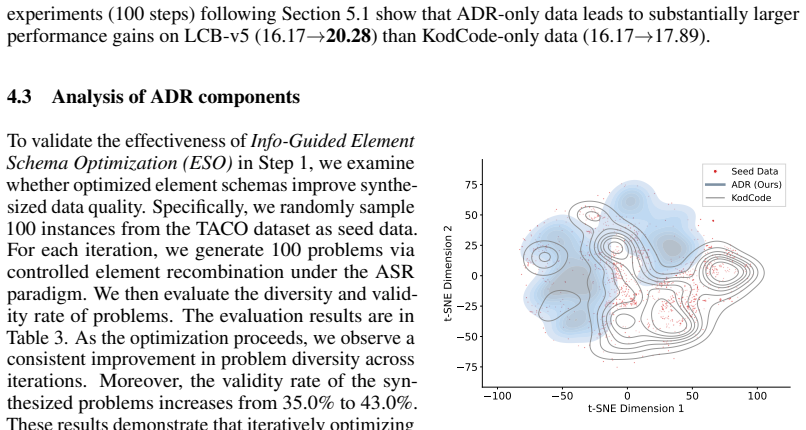
ADR generates verifiable code tasks via decomposition into atomic elements and controlled recombination, thereby enabling the generation of genuinely novel and challenging verifiable code tasks that deliver greater improvements in code ability across RLVR in diverse downstream domains.
What carries the argument
Atomic Decomposition and Recombination (ADR), the mechanism that decomposes code tasks into atomic elements while preserving verifiability and then recombines them to produce new tasks.
If this is right
- ADR tasks exhibit higher originality, difficulty, diversity, and test quality than tasks from existing baselines.
- RLVR training on ADR data produces consistent larger gains in code ability than training on baseline data.
- The gains hold across algorithmic programming, tool usage, and data science domains.
- The method replaces heuristic seed expansions with systematic combinatorial synthesis for task generation.
Where Pith is reading between the lines
- If atomic decomposition generalizes, the same recombination strategy could be applied to other verifiable domains such as mathematical proofs or scientific experiment design.
- Varying the recombination rules might let practitioners target specific difficulty bands without new human seeds.
- The approach could be combined with automated difficulty estimators to prioritize tasks near a model's current competence edge.
- Longer training runs might reveal whether the diversity of ADR tasks reduces overfitting compared with narrower heuristic sets.
Load-bearing premise
Code tasks can be decomposed into atomic elements while preserving verifiability and that controlled recombination will reliably produce genuinely novel and more challenging tasks rather than invalid or trivial ones.
What would settle it
A large-scale check showing that most recombined tasks are either unverifiable by the reward function, solvable at the same rate as the seed tasks, or fail to improve downstream RLVR performance would falsify the central claim.
Figures




















read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as the cornerstone for shaping the remarkable coding abilities of Large Language Models (LLMs). However, the scalability of RLVR is severely constrained by the scarcity of sufficiently challenging verifiable code tasks that target near the model's edge of competence. Prior studies often rely on heuristic seed expansions for data synthesis, which severely limits both novelty and difficulty. Consequently, the training value of such data fails to scale proportionally with the size of its synthesis. To this end, we propose Atomic Decomposition and Recombination (ADR), a novel framework that generates verifiable code tasks via decomposition into atomic elements and controlled recombination, thereby enabling the generation of genuinely novel and challenging verifiable code tasks. Experiments and analysis demonstrate that ADR achieves superior originality, difficulty, diversity, and test quality over existing baselines, and consistently delivers greater improvements in code ability across RLVR in diverse downstream domains, including algorithmic programming, tool usage, and data science. Our work sheds light on a new paradigm for novel code task synthesis and scalable RLVR training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Atomic Decomposition and Recombination (ADR), a framework that decomposes existing code tasks into atomic elements and recombines them under controlled conditions to synthesize novel, verifiable code tasks for Reinforcement Learning with Verifiable Rewards (RLVR). It claims that ADR-generated tasks exhibit superior originality, difficulty, diversity, and test quality relative to heuristic baselines, and that RLVR training on these tasks yields larger gains in downstream code abilities across algorithmic programming, tool usage, and data science domains.
Significance. If the experimental results hold, ADR would offer a principled, scalable route to the high-quality, edge-of-competence data that currently limits RLVR for code; the combinatorial paradigm could generalize beyond code and reduce reliance on hand-crafted or heuristically expanded seeds.
major comments (2)
- [Abstract] Abstract: the central empirical claim—that ADR achieves superior originality, difficulty, diversity, and test quality and delivers greater downstream gains—is asserted without any reported metrics, baselines, statistical tests, or sample sizes, preventing assessment of whether the data support the stated improvements.
- The weakest assumption (that atomic decomposition preserves verifiability and that recombination reliably yields non-trivial, valid tasks) is load-bearing for the entire synthesis pipeline, yet the provided text supplies no quantitative validation (e.g., rejection rates, human verification scores, or comparison of task solvability distributions) that would confirm the assumption holds at scale.
minor comments (1)
- The title refers to 'Combinatorial Synthesis' while the body uses 'Atomic Decomposition and Recombination (ADR)'; a brief clarification of the relationship between the two phrases would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim—that ADR achieves superior originality, difficulty, diversity, and test quality and delivers greater downstream gains—is asserted without any reported metrics, baselines, statistical tests, or sample sizes, preventing assessment of whether the data support the stated improvements.
Authors: We agree that the abstract would be strengthened by including key quantitative results. While the body of the paper reports the relevant metrics, baselines, and comparisons, the abstract currently summarizes at a high level. In revision we will add concise numerical highlights (e.g., relative gains in originality and downstream performance) together with the primary baselines used. revision: yes
-
Referee: The weakest assumption (that atomic decomposition preserves verifiability and that recombination reliably yields non-trivial, valid tasks) is load-bearing for the entire synthesis pipeline, yet the provided text supplies no quantitative validation (e.g., rejection rates, human verification scores, or comparison of task solvability distributions) that would confirm the assumption holds at scale.
Authors: We acknowledge the need for explicit quantitative support of this core assumption. The current manuscript contains qualitative discussion and some validity checks, but lacks the requested aggregate statistics. We will add a dedicated analysis section or table reporting rejection rates, any human verification results, and solvability distributions across the generated tasks. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes the ADR framework for generating verifiable code tasks through atomic decomposition and recombination, with all central claims (superior originality, difficulty, diversity, and downstream RLVR improvements) resting on reported experimental comparisons against baselines. No equations, fitted parameters, or self-referential definitions appear in the abstract or described methods; the derivation chain consists of an empirical pipeline whose outputs are externally validated rather than reducing to inputs by construction. Self-citations, if present, are not load-bearing for the core claims, which remain falsifiable via independent replication of the task-generation and RLVR training results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Verifiable code tasks admit decomposition into atomic elements that preserve verifiability.
- domain assumption Controlled recombination of atomic elements produces novel and more challenging tasks.
invented entities (1)
-
Atomic Decomposition and Recombination (ADR) framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, et al. Towards large reasoning models: A survey of reinforced reasoning with large language models.arXiv preprint arXiv:2501.09686, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A Survey of Reinforcement Learning for Large Reasoning Models
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Agents in software engineering: Survey, landscape, and vision.Automated Software Engineering, 32(2):70, 2025
Yanlin Wang, Wanjun Zhong, Yanxian Huang, Ensheng Shi, Min Yang, Jiachi Chen, Hui Li, Yuchi Ma, Qianxiang Wang, and Zibin Zheng. Agents in software engineering: Survey, landscape, and vision.Automated Software Engineering, 32(2):70, 2025
2025
-
[7]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, et al. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Position: Will we run out of data? limits of llm scaling based on human-generated data
Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Heim, and Marius Hobbhahn. Position: Will we run out of data? limits of llm scaling based on human-generated data. InInternational Conference on Machine Learning, pages 49523–49544. PMLR, 2024
2024
-
[9]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
2022
-
[11]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Yiyou Sun, Yuhan Cao, Pohao Huang, Haoyue Bai, Hannaneh Hajishirzi, Nouha Dziri, and Dawn Song. Rl grokking recipe: How does rl unlock and transfer new algorithms in llms? arXiv preprint arXiv:2509.21016, 2025
-
[13]
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models.arXiv preprint arXiv:2512.07783, 2025
-
[14]
Rlpr: Extrapolating rlvr to general domains without verifiers
Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, et al. Rlpr: Extrapolating rlvr to general domains without verifiers. arXiv preprint arXiv:2506.18254, 2025
-
[15]
Opencoder: The open cookbook for top-tier code large language models
Siming Huang, Tianhao Cheng, Jason Klein Liu, Weidi Xu, Jiaran Hao, Liuyihan Song, Yang Xu, Jian Yang, Jiaheng Liu, Chenchen Zhang, et al. Opencoder: The open cookbook for top-tier code large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 33167–33193, 2025
2025
-
[16]
Magicoder: empower- ing code generation with oss-instruct
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: empower- ing code generation with oss-instruct. InInternational Conference on Machine Learning, pages 52632–52657, 2024. 10
2024
-
[17]
Code alpaca: An instruction-following llama model for code generation
Sahil Chaudhary. Code alpaca: An instruction-following llama model for code generation. https://github.com/sahil280114/codealpaca, 2023
2023
-
[18]
ACECODER: Acing coder RL via automated test-case synthesis
Huaye Zeng, Dongfu Jiang, Haozhe Wang, Ping Nie, Xiaotong Chen, and Wenhu Chen. ACECODER: Acing coder RL via automated test-case synthesis. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
2025
-
[19]
KodCode: A di- verse, challenging, and verifiable synthetic dataset for coding
Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, and Radha Poovendran. KodCode: A di- verse, challenging, and verifiable synthetic dataset for coding. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[20]
Wizardcoder: Empowering code large language models with evol-instruct
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. Wizardcoder: Empowering code large language models with evol-instruct. InICLR, 2024
2024
-
[21]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Rlef: Grounding code llms in execution feedback with reinforcement learning
Jonas Gehring, Kunhao Zheng, Jade Copet, Vegard Mella, Taco Cohen, and Gabriel Synnaeve. Rlef: Grounding code llms in execution feedback with reinforcement learning. InInternational Conference on Machine Learning, 2025
2025
-
[25]
Yi Su, Dian Yu, Linfeng Song, Juntao Li, Haitao Mi, Zhaopeng Tu, Min Zhang, and Dong Yu. Crossing the reward bridge: Expanding rl with verifiable rewards across diverse domains.arXiv preprint arXiv:2503.23829, 2025
-
[26]
Rubrics as rewards: Reinforcement learning beyond verifiable domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean M Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains. InNeurIPS 2025 Workshop on Efficient Reasoning, 2025
2025
-
[27]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Autocode: Llms as problem setters for competitive programming.arXiv preprint arXiv:2510.12803, 2025
Shang Zhou, Zihan Zheng, Kaiyuan Liu, Zeyu Shen, Zerui Cheng, Zexing Chen, Hansen He, Jianzhu Yao, Huanzhi Mao, Qiuyang Mang, et al. Autocode: Llms as problem setters for competitive programming.arXiv preprint arXiv:2510.12803, 2025
-
[29]
Xinyue Zheng, Haowei Lin, Shaofei Cai, Zilong Zheng, and Yitao Liang. Unicode: A framework for generating high quality competitive coding problems.arXiv preprint arXiv:2510.17868, 2025
-
[30]
Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
2008
-
[31]
Taco: Topics in algorithmic code generation dataset.arXiv preprint arXiv:2312.14852, 2023
Rongao Li, Jie Fu, Bo-Wen Zhang, Tao Huang, Zhihong Sun, Chen Lyu, Guang Liu, Zhi Jin, and Ge Li. Taco: Topics in algorithmic code generation dataset.arXiv preprint arXiv:2312.14852, 2023
-
[32]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jia- jun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations
-
[38]
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions
Terry Yue Zhuo, Vu Minh Chien, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, et al. Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions. InThe Thirteenth International Conference on Learning Representations
-
[39]
Ds-1000: A natural and reliable benchmark for data science code generation
Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen- tau Yih, Daniel Fried, Sida Wang, and Tao Yu. Ds-1000: A natural and reliable benchmark for data science code generation. InInternational Conference on Machine Learning, pages 18319–18345. PMLR, 2023
2023
-
[40]
Measuring coding challenge competence with apps
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. Measuring coding challenge competence with apps. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2)
-
[41]
Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode.Science, 378(6624):1092–1097, 2022
2022
-
[42]
Codeforces Dataset, 2022
Jur1cek. Codeforces Dataset, 2022. 12 A Additional Experimental Setups A.1 Evaluation of Synthetic Data Quality
2022
-
[43]
We obtain data representa- tions using theall-MiniLM-L6-v2embedding model and compute cosine similarity
Originality: We select the PrimeIntellect/verifiable-coding-problems as the ref- erence dataset R, which contains 144,169 problems spanning diverse sources, including Apps [40], CodeContests [41], Codeforces [42], and TACO [31]. We obtain data representa- tions using theall-MiniLM-L6-v2embedding model and compute cosine similarity
-
[44]
We choose the non-thinking mode
Difficulty: We choose Qwen/Qwen3-4B, Qwen/Qwen3-8B, and Qwen/Qwen3-14B [34] as the representative model setM. We choose the non-thinking mode
-
[45]
For each problem, we then identify its nearest neighbor in the embedding space and record the corresponding nearest-neighbor distance
Diversity: We obtain data representations using the all-MiniLM-L6-v2 embedding model and compute the Euclidean distance between each pair of problems. For each problem, we then identify its nearest neighbor in the embedding space and record the corresponding nearest-neighbor distance. We compute the coefficient of variation (CV) of all nearest- neighbor d...
-
[46]
input ": inputs , // List of stdin strings
Test Quality: We evaluate test case quality using an LLM-as-a-Judge framework, considering both test case diversity and edge coverage. The corresponding prompt is shown in Figure 5. A.2 ADR-synthesized Data in RLVR Experiments For algorithm tasks, we follow the ADR paradigm and synthesize 5,000 training data using DeepSeek-V3.2 [ 35]. Specifically, we sel...
-
[47]
Do not reuse or merge their specific ideas
Learn the s t r u c t u r a l patterns , not the content - Extract from the examples their level of detail , r ea son in g style , and the way elements relate to each other . Do not reuse or merge their specific ideas
-
[48]
- The Strategy Div er si ty must c o r r e s p o n d to the a l g o r i t h m i c str uc tu re implied by the Core Alg or it hm Idea
Preserve internal c oh ere nc e - Ensure the four g en er ate d elements n atu ra ll y support each other : - The Story B a c k g r o u n d should o r g a n i c a l l y in tr od uc e the c o n s t r a i n t s that motivate the Core Al go ri th m Idea . - The Strategy Div er si ty must c o r r e s p o n d to the a l g o r i t h m i c str uc tu re implied b...
-
[49]
Maintain o r i g i n a l i t y and avoid c on fl ic ts - Your output must be a fully new c o n s t r u c t i o n - no copying from examples - and must avoid internal c o n t r a d i c t i o n s in constraints , methods , or c o m p l e x i t y a s s u m p t i o n s
-
[50]
You are an expert problem setter and a l g o r i t h m i s t
Ensure problem - level richness - The new c o m b i n a t i o n should have enough st ru ct ure and c o m p l e x i t y to support a m e a n i n g f u l al go ri thm problem , with : - Non - trivial de cis io ns or c o n s t r a i n t s - Multiple pl au si ble solution a p p r o a c h e s - Clear reasons for the d i f f i c u l t y c l a s s i f i c a t i...
-
[51]
You may in tr od uce new scenarios , examples , or problem twists only within the limits of the framework , in order to make the problem original and engaging
** F ra mew or k fidelity with creative f l e x i b i l i t y **: The problem must strictly respect the content , constraints , and core setup defined in the Problem Fr am ew or k . You may in tr od uce new scenarios , examples , or problem twists only within the limits of the framework , in order to make the problem original and engaging . Do not alter o...
-
[52]
The problem should en cou ra ge diverse solution s t r a t e g i e s and subtle a l g o r i t h m i c thinking
** O r i g i n a l i t y and a l g o r i t h m i c cha ll en ge **: Within the fr am ew or k boundaries , design the problem so that it is non - trivial and requires m e a n i n g f u l a l g o r i t h m i c re as on in g . The problem should en cou ra ge diverse solution s t r a t e g i e s and subtle a l g o r i t h m i c thinking
-
[53]
wait "
** No meta - comments or re as on in g steps **: Exclude all internal deliberation , step - by - step reasoning , and self - r e f e r e n t i a l phrases . Avoid using terms such as " wait " " let ’ s " or any similar language that i nd ic ate s thinking
-
[54]
The model ’ s entire output must be exactly the filled template , with no extra text or c o m m e n t a r y outside the template
** Strict output format **: Produce only a fully c om pl ete d Problem Template block . The model ’ s entire output must be exactly the filled template , with no extra text or c o m m e n t a r y outside the template
-
[55]
__main__
** Well - sp ec if ie d c o n s t r a i n t s **: Ensure input / output and formal c o n s t r a i n t s are complete , and the intended a l g o r i t h m i c c o m p l e x i t y is clear . ### Problem Fr am ew or k { fr am ew or k } ### Problem Template ‘‘‘ ** Problem Title :** [ Your problem title ] ** Tags :** [ Comma - se pa rat ed topics / tags ] ** ...
-
[56]
Each near - miss solution should be written as full e x e c u t a b l e code
-
[57]
Each solution must fail for at least one non - trivial or a d v e r s a r i a l input
-
[58]
Avoid re pe at ing the same error pattern
The mistakes should be diverse . Avoid re pe at ing the same error pattern
-
[59]
Do NOT e x p l i c i t l y state what the bug is in the code
-
[60]
Do NOT include e x p l a n a t i o n s inside the code
-
[61]
Output the sol ut io ns as a numbered list from 1 to 5. ### Problem d e s c r i p t i o n : { problem } ### Correct re fe re nc e solution : ‘‘‘ python { r e f e r e n c e _ s o l u t i o n } ‘‘‘ Figure 10: Prompt Template forStep 5: Adversarial Solution Space Refinementin ADR. You are given : - A p r o g r a m m i n g problem - A correct re fer en ce sol...
-
[62]
Analyze the common and uncommon w e a k n e s s e s likely present in the near - miss so lu ti on s
-
[63]
Design test cases that s p e c i f i c a l l y target : - Edge cases - Boundary c o n d i t i o n s - Rare corner s ce na ri os - Stress limits ( size , value ranges , ordering , s tr uc tu re ) - Implicit a s s u m p t i o n s likely made by in co rr ec t s ol ut io ns
-
[64]
The ge ne ra to r should be general and reusable , not h ard co de d for a single bug
-
[65]
Do NOT e x p l i c i t l y r efe re nc e i n d i v i d u a l near - miss s ol ut ion s in the g en er at or logic
-
[66]
Output the improved test case g en er at or as e x e c u t a b l e code or clear p s e u d o c o d e . ### Problem d e s c r i p t i o n : { problem } ### Correct re fe re nc e solution : ‘‘‘ python { r e f e r e n c e _ s o l u t i o n } ‘‘‘ ### Near - miss so lu ti ons : { n e a r _ m i s s _ s o l u t i o n s } ### Current test case g en er ato r : ‘‘‘...
-
[67]
* ** Role :** Defines * what * the task f u n d a m e n t a l l y does ; without it , the task has no semantic goal
C o m p u t a t i o n a l Obj ec ti ve 22 * ** D e f i n i t i o n :** An abstract s p e c i f i c a t i o n of the primary c o m p u t a t i o n or t r a n s f o r m a t i o n to be pe rf or me d on data , i n d e p e n d e n t of i m p l e m e n t a t i o n details . * ** Role :** Defines * what * the task f u n d a m e n t a l l y does ; without it , t...
-
[68]
Tool D e p e n d e n c y Set * ** D e f i n i t i o n :** The set of external libraries , modules , or tools that must be imported and used to a c c o m p l i s h the task . * ** Role :** D i s t i n g u i s h e s this task type as a * tool - calling * problem ; ensures the task d e m o n s t r a t e s use of specific ut il it ie s beyond core language c ...
-
[69]
* ** Role :** Ensures the task e xer ci se s p a r t i c u l a r patterns ( e
P r o c e s s i n g Logic C o n s t r a i n t s * ** D e f i n i t i o n :** High - level rules or required o p e r a t i o n s that c on str ai n how the c o m p u t a t i o n must be carried out , without p r e s c r i b i n g exact code . * ** Role :** Ensures the task e xer ci se s p a r t i c u l a r patterns ( e . g . , shu ff li ng before computing...
-
[70]
* ** Role :** E s t a b l i s h e s how external data enters the task ; ne ce ss ar y for invoking the c o m p u t a t i o n
Input In te rf ac e * ** D e f i n i t i o n :** A formal d e s c r i p t i o n of the function inputs , i nc lu din g pa ram et er names , types , defaults , and c o n s t r a i n t s . * ** Role :** E s t a b l i s h e s how external data enters the task ; ne ce ss ar y for invoking the c o m p u t a t i o n . * ** Va ri ati on Axes :** * Number of p a ...
-
[71]
* ** Role :** Defines task c o m p l e t i o n criteria ; without it , c o r r e c t n e s s cannot be ev al ua ted
Output S p e c i f i c a t i o n * ** D e f i n i t i o n :** A precise d e s c r i p t i o n of the expected output type , structure , and semantic meaning . * ** Role :** Defines task c o m p l e t i o n criteria ; without it , c o r r e c t n e s s cannot be ev al ua ted . * ** Va ri ati on Axes :** * Output data type ( float , dict , list , etc .) * S...
-
[73]
** Five - element c o m p l e t e n e s s ** You must generate ** exactly five elements ** , one for each of the f ol lo wi ng : * C o m p u t a t i o n a l Ob je ct iv e * Tool D e p e n d e n c y Set * P r o c e s s i n g Logic C o n s t r a i n t s * Input I nt er fa ce * Output S p e c i f i c a t i o n
-
[74]
* P r o c e s s i n g Logic C o n s t r a i n t s must ** m e a n i n g f u l l y co ns tr ain ** how the tools are used
** C o n s i s t e n c y c o n s t r a i n t s ** * The C o m p u t a t i o n a l Ob jec ti ve must be ** a c h i e v a b l e ** using the Tool D e p e n d e n c y Set . * P r o c e s s i n g Logic C o n s t r a i n t s must ** m e a n i n g f u l l y co ns tr ain ** how the tools are used . * Input I nt er fa ce must provide ** s u f f i c i e n t i n f ...
-
[75]
** Novel r e c o m b i n a t i o n ** 24 * Treat the three re fe ren ce sets as ** design signals ** , not te mp la te s . * The res ul ti ng element set should be p la us ib ly g e n e r a t a b l e by r e c o m b i n i n g ideas , but ** must not align exactly with any r ef ere nc e along more than one element **
-
[76]
* If tools were removed , the task should lose its defining ch ar ac te r
** Tool - calling emphasis ** * The Tool D e p e n d e n c y Set must play a ** non - trivial role ** in enabling or shaping the task . * If tools were removed , the task should lose its defining ch ar ac te r . ### Given C o m p u t a t i o n a l O bj ec tiv e { c o m p u t a t i o n a l _ o b j e c t i v e } ### Given Tool D e p e n d e n c y Set { t o ...
-
[79]
* Removing the tools should break the task
** M an dat or y Tool Usage ** * The task must i n h e r e n t l y require the s pe ci fi ed tools . * Removing the tools should break the task
-
[80]
25 * Do not rename , reorder , or omit sections
** Template Ex act ne ss ** * Follow the template str uc tu re and section order exactly . 25 * Do not rename , reorder , or omit sections
-
[81]
\"\" Return the sum of a and b . \
** Header Code A ut ho ri ty ** * Use the header code verbatim . * All required imports and the function s ig na tu re must appear there , and only there . ### Output Template ** Problem D e s c r i p t i o n :** < Concise natural - language d e s c r i p t i o n i n s t a n t i a t i n g the C o m p u t a t i o n a l O bj ect iv e and P r o c e s s i n g...
-
[82]
Data Schema * ** D e f i n i t i o n :** A precise , abstract d e s c r i p t i o n of the input data the code will consume : its origin ( file , DB , in - memory ) , high - level st ruc tu re ( table / array / tensor / graph ) , d i m e n s i o n s or shape signatures , named fields or column types , and any d i s t r i b u t i o n a l or ordering p r o ...
-
[83]
reorder rows by index list
Task Goal * ** D e f i n i t i o n :** A concise , testable d e s c r i p t i o n of the transformation , computation , or analysis to perform on the input data . It d es cr ib es the expected semantic outcome ( e . g . , " reorder rows by index list " , " no rma li ze each column in - place " , " reshape a 1 - D sequence into a 2 - D matrix ") . * ** Rol...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.