Not All Synthetic Data Is Yours to Learn From
Pith reviewed 2026-06-28 22:47 UTC · model grok-4.3
The pith
Synthetic data improves a language model only when it matches the model's existing capabilities in a relational way.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
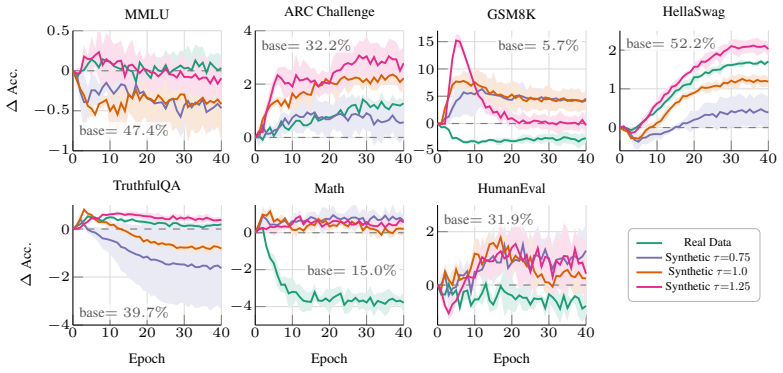
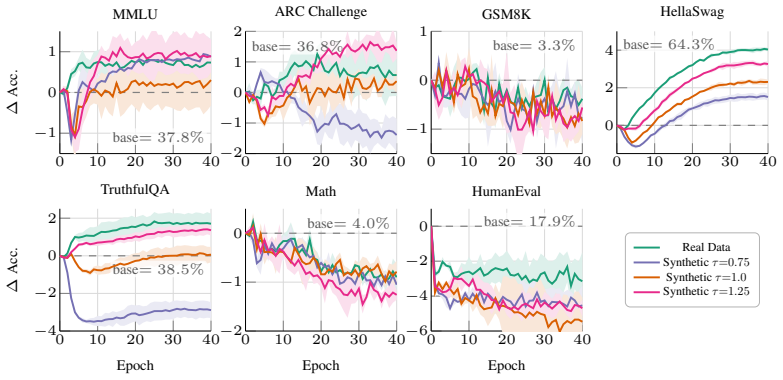
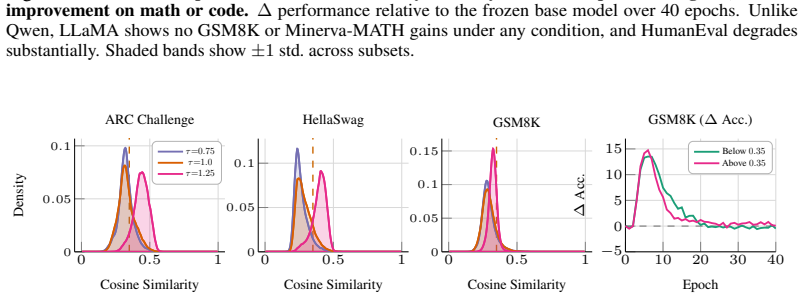
In prompt-free unconditional self-training, synthetic data utility is relational rather than intrinsic: self-generated data works best, same-lineage transfer outperforms stronger but differently trained sources, and cross-family transfer is substantially weaker. Neither benchmark-level semantic similarity nor average per-token likelihood under the student predicts which corpora help. In controlled Pythia experiments, benchmark utility is preserved or improved while held-out exact-match extraction drops by over 95 percent with no forget set, privacy objective, or targeted unlearning. These results indicate that prompt-free self-training works by amplifying what the student already knows, not
What carries the argument
The latent capability resurfacing hypothesis, which states that weak self-training amplifies capabilities already present in the pretrained model only when the synthetic source is compatible with the student.
If this is right
- Self-generated data is the most effective source for this form of self-training.
- Same-lineage synthetic corpora transfer better than stronger but differently trained sources.
- Cross-family synthetic data yields substantially weaker gains.
- Benchmark gains can occur while verbatim memorization of the training text falls sharply without any explicit unlearning step.
Where Pith is reading between the lines
- Compatibility between source and student might be estimated in advance from training history or architecture to select useful synthetic corpora.
- The observed separation of capability gains from memorization could be useful in privacy-sensitive settings where reduced extraction is desirable.
- The same relational pattern may appear in other self-improvement loops such as iterative preference optimization on model-generated outputs.
Load-bearing premise
The controlled Pythia setup and chosen benchmarks accurately isolate the relational compatibility effect and the memorization decoupling without unstated data selection or controls.
What would settle it
A cross-family synthetic corpus that improves the student model as much as same-lineage data while still producing the 95 percent drop in exact-match extraction would falsify the relational-compatibility claim.
Figures






read the original abstract
Can a language model improve from plain text sampled from itself, with no prompts, no teacher, no verifier, and no reward model? Yes, but only when the synthetic corpus is compatible with the student, a relational property of the source-student pair rather than an intrinsic property of the data. We call this the latent capability resurfacing hypothesis: weak self-training can amplify capabilities already present in the pretrained model, but only under this compatibility condition. We study this in the minimal setting of prompt-free unconditional self-training, where base language models are fine-tuned on text generated from the BOS token alone, with no task specification or external supervision. We report three findings. First, synthetic utility is relational rather than intrinsic: self-generated data is the most effective source, same-lineage transfer outperforms stronger but differently trained sources, and cross-family transfer is substantially weaker. Second, common intrinsic proxies fail: neither benchmark-level semantic similarity nor average per-token likelihood under the student predicts which corpora help. Third, this regime produces a surprising byproduct. In controlled Pythia experiments, capability and verbatim memorization decouple: benchmark utility is preserved or improved while held-out exact-match extraction drops by over 95 percent, with no forget set, privacy objective, or targeted unlearning. Together, these results suggest that prompt-free self-training works by amplifying what the student already knows, not by importing structure from the data. They also reveal a regime in which capability and verbatim memorization can be separated without any explicit unlearning objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines prompt-free unconditional self-training of language models on text generated from the BOS token. It claims that synthetic data utility is a relational property of the source-student pair (self-generated data most effective, same-lineage transfer outperforms cross-family), that standard intrinsic proxies like semantic similarity or per-token likelihood fail to predict utility, and that in controlled Pythia experiments benchmark utility is preserved while held-out exact-match extraction drops over 95% with no forget set or unlearning objective. This supports the 'latent capability resurfacing hypothesis' that weak self-training amplifies preexisting capabilities under a compatibility condition rather than importing structure.
Significance. If the relational utility and decoupling results hold under rigorous controls, the work would provide a concrete empirical basis for viewing self-training as capability amplification rather than data importation, with direct implications for privacy-preserving model improvement and synthetic data selection. The absence of any external supervision or reward model makes the minimal setting a useful testbed for isolating mechanisms in LLM self-improvement.
major comments (2)
- [Abstract and experimental sections describing Pythia setup] The decoupling result (benchmark utility preserved while exact-match extraction on held-out data falls >95%) is load-bearing for the latent capability resurfacing hypothesis, yet the manuscript provides no description of how the held-out sequences are constructed (sampling method, length distribution, diversity criteria, or post-generation filtering). Without this, it is impossible to exclude the possibility that the drop is an artifact of distributional shift between the synthetic corpus and the held-out set rather than evidence of memorization decoupling.
- [Findings 1 and 2] The claim that 'synthetic utility is relational rather than intrinsic' rests on comparisons across self-generated, same-lineage, and cross-family sources, but the manuscript does not report the number of runs, statistical tests, or controls for model scale and training duration that would be needed to establish that same-lineage transfer is reliably superior to stronger but differently trained sources.
minor comments (2)
- [Abstract] The abstract states three findings and a hypothesis but supplies no dataset sizes, benchmark lists, or statistical details; these should be summarized even at the abstract level for a self-contained empirical paper.
- [Introduction and hypothesis statement] Notation for 'compatibility condition' is introduced informally; a precise definition or operationalization (e.g., via a measurable distance between source and student distributions) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate additional details where needed.
read point-by-point responses
-
Referee: [Abstract and experimental sections describing Pythia setup] The decoupling result (benchmark utility preserved while exact-match extraction on held-out data falls >95%) is load-bearing for the latent capability resurfacing hypothesis, yet the manuscript provides no description of how the held-out sequences are constructed (sampling method, length distribution, diversity criteria, or post-generation filtering). Without this, it is impossible to exclude the possibility that the drop is an artifact of distributional shift between the synthetic corpus and the held-out set rather than evidence of memorization decoupling.
Authors: We agree that the construction details for the held-out set are essential to substantiate the decoupling result. The sequences were generated unconditionally from the BOS token using identical sampling parameters to the synthetic corpus (temperature 1.0, no nucleus sampling) but with disjoint random seeds, lengths sampled from the empirical distribution of the training data, and post-filtering to remove any exact matches or high-similarity sequences to the training set. In the revised manuscript we will add an explicit subsection describing the sampling method, length distribution, diversity criteria (minimum unique n-gram count), and filtering steps, along with a control analysis confirming comparable perplexity and embedding distributions between the held-out and synthetic sets to address distributional shift concerns. revision: yes
-
Referee: [Findings 1 and 2] The claim that 'synthetic utility is relational rather than intrinsic' rests on comparisons across self-generated, same-lineage, and cross-family sources, but the manuscript does not report the number of runs, statistical tests, or controls for model scale and training duration that would be needed to establish that same-lineage transfer is reliably superior to stronger but differently trained sources.
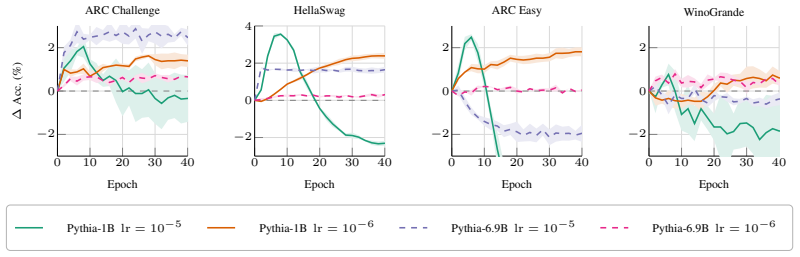
Authors: We acknowledge that explicit reporting of run counts and statistical tests would strengthen the relational utility claim. The reported trends were observed consistently across five model scales (Pythia 70M–2.8B) with fixed training duration and token count for all conditions; however, the main text presents single-run results. In revision we will report results from three independent seeds per configuration, add error bars, and include paired statistical tests (e.g., Wilcoxon) for the key same-lineage vs. cross-family comparisons while retaining the existing scale and duration controls. revision: partial
Circularity Check
No significant circularity; empirical study with independent experimental observations
full rationale
The paper is an empirical study reporting observations from controlled experiments on prompt-free self-training of language models. No equations or derivations are present that reduce any result to a fitted parameter defined by the same data or to a self-citation chain. The latent capability resurfacing hypothesis is an interpretive label for experimental outcomes (relational utility, failure of intrinsic proxies, and capability-memorization decoupling in Pythia setups), not a mathematical claim derived from inputs by construction. The 95% exact-match drop is presented as a measured experimental byproduct, not a prediction forced by fitting. Any self-citations are not load-bearing for the central claims, which rest on the reported experimental controls and benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Language models can be fine-tuned on text generated unconditionally from the BOS token.
invented entities (1)
-
latent capability resurfacing hypothesis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=kpLRYtPGt3. Yauhen Babakhin, Radek Osmulski, Ronay Ak, Gabriel de Souza Pereira Moreira, Mengyao Xu, Benedikt Schifferer, Bo Liu, and Even Oldridge. Llama-Embed-Nemotron-8B: A universal text embedding model for multilingual and cross-lingual tasks, 2025. URL https://arxiv.org/ abs/2511.07025. Stella Biderman, Hailey Scho...
-
[2]
URLhttps://arxiv.org/abs/1803.05457. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/ abs/2110.14168. Yunzhen Feng, Elvis Dohmatob, Pu Yang,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.acl-long.805 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.