LLM-FACETS: A Privacy-Preserving Framework for Evaluating LLM Transparency and Accountability
Pith reviewed 2026-06-28 22:33 UTC · model grok-4.3
The pith
LLM-FACETS lets non-technical users audit LLM outputs for factuality and uncertainty with all deterministic metrics kept inside a self-hosted server.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
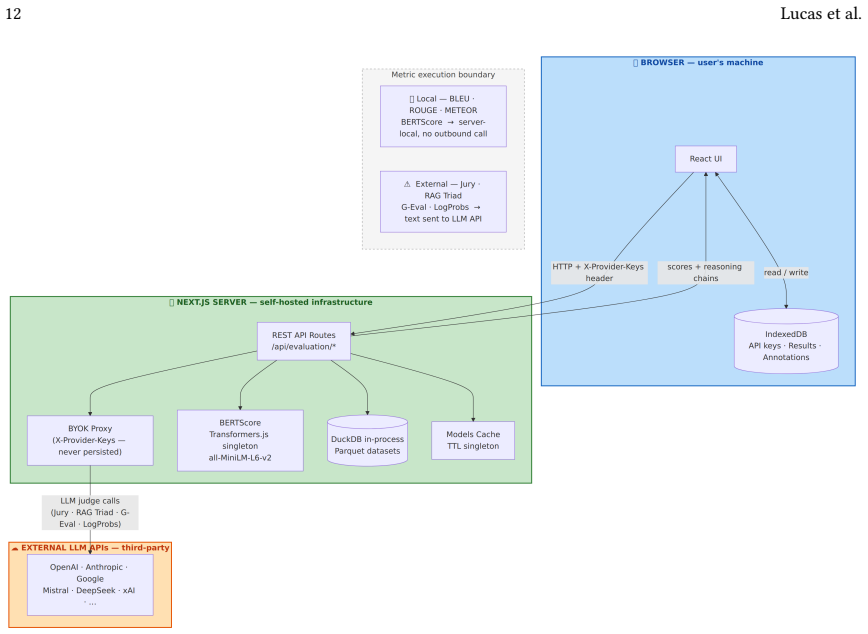
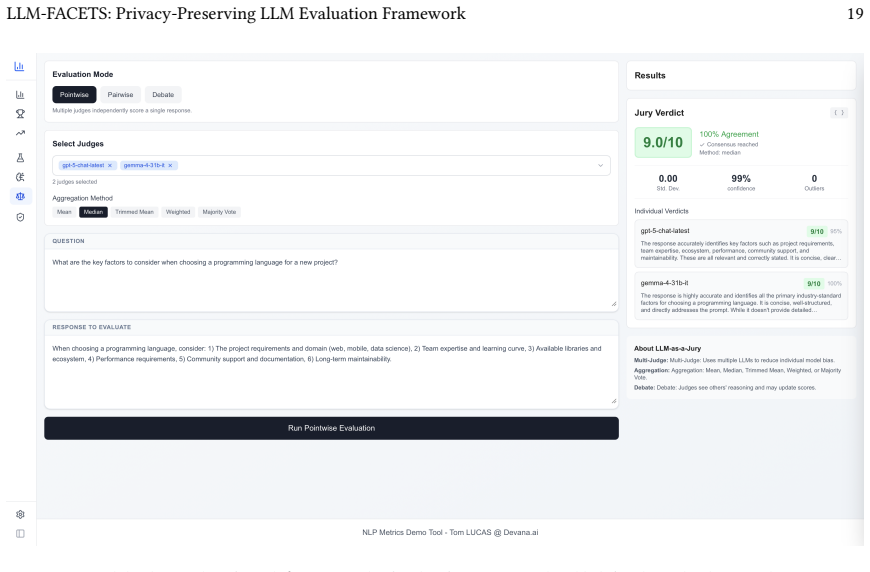
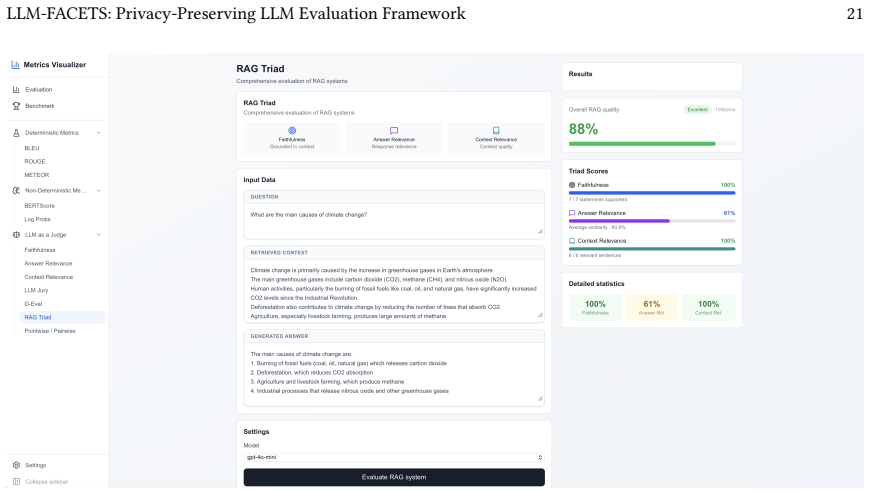
LLM-FACETS operationalizes transparency through three mechanisms: token-level log-probability visualization for epistemic uncertainty, multi-judge consensus to mitigate judge bias, and RAG Triad metrics (Faithfulness, Answer Relevance, Context Relevance) to detect and localize hallucinations, all inside an architecture where deterministic metrics execute entirely within the self-hosted server with no outbound transmission and LLM-judge metrics contact external APIs only under explicit user credential control.
What carries the argument
The plugin architecture combined with explicit separation of data flows between fully local deterministic metrics and user-controlled external LLM-judge metrics.
If this is right
- Cross-checking multiple metrics that target the same property becomes possible without changing the evaluation pipeline.
- Accountability for model outputs is separated from the teams that build the models.
- New metrics or datasets can be added through plugins without modifying the core system.
- Compliance officers and domain experts gain direct access to evaluation results that match regulatory stakeholder categories.
Where Pith is reading between the lines
- Similar local-first evaluation designs could be applied to other generative systems once equivalent local metrics exist for those systems.
- Organizations could reduce compliance risks by adopting the explicit data-flow controls when auditing models on regulated data.
- Contributors could build domain-specific plugins to extend hallucination localization to specialized fields such as medical or legal text.
Load-bearing premise
The self-hosted server and browser interface can be implemented and used by non-technical practitioners without creating new data leakage paths or demanding complex configuration.
What would settle it
A test showing that running the deterministic metrics requires sending data to external services or that non-technical users need programming skills to operate the interface would falsify the privacy and accessibility claims.
Figures






read the original abstract
Assessing whether Large Language Models outputs are factually grounded, epistemically calibrated, and methodologically reproducible is a prerequisite for responsible AI deployment. Yet auditing LLMs remains inaccessible to non-technical practitioners: existing tools require programming expertise and non-trivial environment setup, and cloud-hosted platforms transmit evaluation data to external services, creating barriers for domain experts and compliance officers legally responsible for AI oversight. We introduce LLM-FACETS (LLM FActuality Cross-EvaluaTion System): an open-source framework with a browser-accessible interface and a plugin architecture, structured around three practitioner profiles (technical experts, domain experts, compliance officers) that mirror the stakeholder categories identified in the EU AI Act and the NIST AI Risk Management Framework. The architecture makes data flows explicit: deterministic metrics (BLEU, ROUGE, BERTScore) run entirely within the self-hosted server with no outbound transmission; LLM-judge metrics contact external APIs explicitly, with users retaining full credential control. The framework operationalizes transparency through three mechanisms: token-level log-probability visualization for epistemic uncertainty, multi-judge consensus to mitigate judge bias, and RAG Triad metrics (Faithfulness, Answer Relevance, Context Relevance) to detect and localize hallucinations. A plugin architecture allows any new metric or dataset to be integrated without modifying the evaluation pipeline. The open-source implementation enables cross-checking across multiple metrics targeting the same property, ensuring reproducibility and decoupling AI accountability from the teams building the systems assessed. We verify the framework through cross-validation of 18 metric implementations against canonical reference libraries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LLM-FACETS, an open-source framework with a browser-accessible interface and plugin architecture for evaluating LLM outputs on factuality, epistemic calibration, and reproducibility. It targets three stakeholder profiles aligned with EU AI Act and NIST guidelines, makes data flows explicit (deterministic metrics like BLEU/ROUGE/BERTScore run locally with no outbound transmission; LLM-judge metrics require explicit user credentials), and operationalizes transparency via token-level log-probability visualization, multi-judge consensus, and RAG Triad metrics. The framework is verified solely through cross-validation of 18 metric implementations against reference libraries.
Significance. If the architecture claims hold, the work could meaningfully lower barriers for non-technical compliance officers and domain experts to perform reproducible LLM audits without external data transmission, directly supporting regulatory requirements for accountability. The explicit separation of metric types and plugin extensibility are practical strengths that could enable independent cross-checking.
major comments (2)
- [Abstract] Abstract: The verification statement reports only cross-validation of 18 metric implementations against canonical reference libraries. This addresses numerical agreement for deterministic metrics but supplies no evidence on network isolation, absence of unlisted HTTP calls in metric modules or the plugin loader, credential handling for LLM-judge paths, or the actual deployment steps required to run the self-hosted server and browser UI. These untested elements are load-bearing for the central privacy-preservation and accessibility claims.
- [Abstract] Abstract (architecture description): The claim that deterministic metrics execute with zero outbound transmission inside a self-hosted server while remaining usable by non-technical practitioners is presented as an architectural property but is not accompanied by any test results, deployment logs, or setup instructions that would confirm the absence of new leakage paths or non-trivial configuration requirements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical support of the privacy and deployment claims. We address each major comment below and will revise the manuscript accordingly to include additional verification details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The verification statement reports only cross-validation of 18 metric implementations against canonical reference libraries. This addresses numerical agreement for deterministic metrics but supplies no evidence on network isolation, absence of unlisted HTTP calls in metric modules or the plugin loader, credential handling for LLM-judge paths, or the actual deployment steps required to run the self-hosted server and browser UI. These untested elements are load-bearing for the central privacy-preservation and accessibility claims.
Authors: We agree that the current verification is limited to metric cross-validation and does not empirically demonstrate network isolation or deployment properties. The architecture description states that deterministic metrics run locally with no outbound transmission and that LLM-judge paths require explicit user credentials, but these are presented as design properties without supporting tests. In revision we will add a dedicated verification subsection with: (1) network traffic captures during execution of deterministic metrics, (2) static code analysis results confirming absence of unlisted HTTP endpoints in metric and plugin modules, (3) credential-handling audit for LLM-judge paths, and (4) minimal deployment logs and setup instructions for the self-hosted server and browser UI. These additions will directly address the load-bearing claims. revision: yes
-
Referee: [Abstract] Abstract (architecture description): The claim that deterministic metrics execute with zero outbound transmission inside a self-hosted server while remaining usable by non-technical practitioners is presented as an architectural property but is not accompanied by any test results, deployment logs, or setup instructions that would confirm the absence of new leakage paths or non-trivial configuration requirements.
Authors: We acknowledge that the manuscript presents the zero-outbound-transmission property as an architectural guarantee without accompanying empirical evidence or deployment artifacts. While the design isolates deterministic metrics inside the self-hosted server and requires explicit user action for external API calls, the absence of test results and setup instructions is a genuine gap. We will revise the manuscript to include network-isolation test results, sample deployment logs showing no external traffic, and concise setup instructions that demonstrate usability for non-technical practitioners without introducing new configuration leakage paths. revision: yes
Circularity Check
No circularity: framework description with external metric validation only
full rationale
The paper introduces LLM-FACETS as an open-source framework with browser interface, plugin architecture, and explicit data flows for privacy. It operationalizes transparency via token-level visualization, multi-judge consensus, and RAG Triad metrics, then verifies via cross-validation of 18 metric implementations against canonical reference libraries. No equations, derivations, fitted parameters, predictions, or self-citations appear in the provided text. The central claims rest on architectural description and external library comparisons rather than any reduction of outputs to inputs by construction. This is a standard non-circular framework paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Apache Software Foundation. 2013. Apache Parquet: Columnar Storage Format. https://parquet.apache.org
2013
-
[2]
Arize AI. 2024. Phoenix: Open-Source AI Observability Platform. [software]. https://phoenix.arize.com
2024
-
[3]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Association for Computational Linguistics, Ann Arbor, Michigan, USA, 65–72
2005
-
[4]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT). ACM, Virtual Event, Canada, 610–623. doi:10.1145/3442188.3445922
-
[5]
Confident AI. 2024. DeepEval: Open-Source LLM Evaluation Framework. Version 1.0 [software]. https://github.com/confident-ai/deepeval
2024
-
[6]
Credo AI. 2024. Credo AI: AI Governance Platform. https://www.credo.ai
2024
-
[7]
Vera Liao, Michael Muller, Mark O
Upol Ehsan, Q. Vera Liao, Michael Muller, Mark O. Riedl, and Justin D. Weisz. 2021. Expanding Explainability: Towards Social Transparency in AI Systems. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. ACM, Yokohama, Japan, 1–19. doi:10.1145/3411764.3445188 Manuscript submitted to ACM LLM-FACETS: Privacy-Preserving LLM Evalu...
-
[8]
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. 2024. RAGAS: Automated Evaluation of Retrieval Augmented Generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (EACL). Association for Computational Linguistics, Malta, 150–158. doi:10.18653/v1/2024.eacl-demo.16
-
[9]
European Parliament and Council of the European Union. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council on the Protection of Natural Persons with Regard to the Processing of Personal Data (General Data Protection Regulation). Official Journal of the European Union L 119/1. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CEL...
2016
-
[10]
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council – Artificial Intelligence Act. Official Journal of the European Union. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
2024
-
[11]
Fiddler AI. 2024. Fiddler AI: Model Performance Management Platform. https://www.fiddler.ai
2024
-
[12]
Sebastian Gehrmann, Elizabeth Clark, and Thibault Sellam. 2023. Repairing the Cracked Foundation: A Survey of Obstacles in Evaluation Practices for Generated Text.Journal of Artificial Intelligence Research77 (2023), 103–166. doi:10.1613/jair.1.13715
-
[13]
Google DeepMind. 2024. Gemini: A Family of Highly Capable Multimodal Models. https://deepmind.google/technologies/gemini/
2024
-
[14]
International Organization for Standardization. 2023. ISO/IEC 42001:2023 — Information Technology — Artificial Intelligence — Management System. https://www.iso.org/standard/81230.html
2023
-
[15]
Minsuk Kahng, Ian Tenney, Mark Neumann, Jaime Wexler, Fernanda Viégas, and Martin Wattenberg. 2024. LLM Comparator: Visual Analytics for Side-by-Side Evaluation of Large Language Models. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems. ACM, Honolulu, Hawaii, USA, 1–7. doi:10.1145/3613905.3650755
-
[16]
Spencer Kelly. 2016. compromise: Modest Natural Language Processing for JavaScript. [software]. https://github.com/spencermountain/compromise
2016
-
[17]
LangChain, Inc. 2023. LangSmith: Platform for Building Production-Grade LLM Applications. https://smith.langchain.com
2023
-
[18]
Langfuse. 2024. Langfuse: Open Source LLM Engineering Platform. [software]. https://langfuse.com
2024
-
[19]
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023. HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 6449–6464. doi:10.18653/v1/2023.emnlp-main.397
-
[20]
Vera Liao, Daniel Gruen, and Sarah Miller
Q. Vera Liao, Daniel Gruen, and Sarah Miller. 2020. Questioning the AI: Informing Design Practices for Explainable AI User Experiences. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. ACM, Honolulu, Hawaii, USA, 1–15. doi:10.1145/3313831.3376590
-
[21]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013
2004
-
[22]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Singapore, 2511–2522. doi:10.18653/v1/2023.emnlp-main.153
-
[23]
Microsoft Corporation. 2018. Presidio: Context-Aware, Pluggable and Customizable Data Protection and Anonymization Service for Text and Images. [software]. https://microsoft.github.io/presidio/
2018
-
[24]
2023.Artificial Intelligence Risk Management Framework (AI RMF 1.0)
National Institute of Standards and Technology. 2023.Artificial Intelligence Risk Management Framework (AI RMF 1.0). Technical Report NIST AI 100-1. National Institute of Standards and Technology, Gaithersburg, Maryland, USA. doi:10.6028/NIST.AI.100-1
-
[25]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, 311–318. doi:10.3115/1073083.1073135
-
[26]
Matt Post. 2018. A Call for Clarity in Reporting BLEU Scores. InProceedings of the Third Conference on Machine Translation (WMT). Association for Computational Linguistics, Brussels, Belgium, 186–191. doi:10.18653/v1/W18-6319
-
[27]
Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: An Embeddable Analytical Database. InProceedings of the 2019 ACM SIGMOD International Conference on Management of Data. ACM, Amsterdam, The Netherlands, 1981–1984. doi:10.1145/3299869.3320212
-
[28]
Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know What You Don’t Know: Unanswerable Questions for SQuAD. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, Melbourne, Australia, 784–789. doi:10.18653/v1/P18-2124
-
[29]
Elisei Rykov, Kseniia Petrushina, Maksim Savkin, Valerii Olisov, Artem Vazhentsev, Kseniia Titova, Alexander Panchenko, Vasily Konovalov, and Julia Belikova. 2025. When Models Lie, We Learn: Multilingual Span-Level Hallucination Detection with PsiloQA. HuggingFace Datasets. https://huggingface.co/datasets/s-nlp/PsiloQA. doi:10.48550/arXiv.2510.04849
-
[30]
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. 2024. ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL). Association for Computational Linguistics, M...
-
[31]
TruEra, Inc. 2024. TruLens: Evaluation and Tracking for LLM Experiments. [software]. https://github.com/truera/trulens
2024
-
[32]
Igor Tufanov, Karen Hambardzumyan, Javier Ferrando, and Elena Voita. 2024. LM Transparency Tool: Interactive Tool for Analyzing Transformer Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), Volume 3: System Demonstrations. Association for Computational Linguistics, Bangkok, Thailand, 29–41. d...
-
[33]
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. 2024. Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models. arXiv preprint arXiv:2404.18796. Manuscript submitted to ACM 28 Lucas et al. doi:10.48550/arXiv.2404.18796
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.18796 2024
-
[34]
Xenova. 2024. Transformers.js: State-of-the-Art Machine Learning for the Web. Version 2.17.2 [software]. https://github.com/xenova/transformers.js
2024
-
[35]
Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuanjing Huang. 2023. Do Large Language Models Know What They Don’t Know?. InFindings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 8653–8665. doi:10.18653/v1/2023.findings-acl.551
-
[36]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. In International Conference on Learning Representations (ICLR). OpenReview.net, Addis Ababa, Ethiopia, 1–15. https://openreview.net/forum?id= SkeHuCVFDr
2020
-
[37]
Jitian Zhao, Changho Shin, Tzu-Heng Huang, Satya Sai Srinath Namburi GNVV, and Frederic Sala. 2026. CARE: Confounder-Aware Aggregation for Reliable LLM Evaluation. arXiv preprint arXiv:2603.00039. doi:10.48550/arXiv.2603.00039
-
[38]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., New Orleans, Louisiana, USA...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.