Fixed-Point Masked Generative Modeling
Pith reviewed 2026-06-28 23:16 UTC · model grok-4.3
The pith
Fixed-point solvers over shared attention layers let masked generative models adapt depth and cut parameters while raising low-budget quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
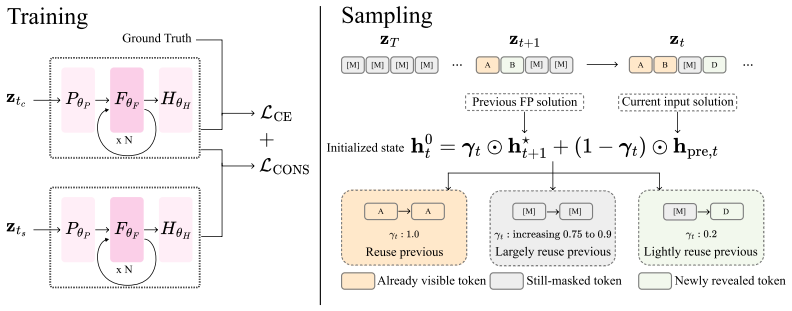
Fixed-Point Masked Generative Models replace part of the denoiser with a fixed-point solver over shared attention layers, augmented by a cross-step consistency loss and three-state reuse, to achieve adaptive depth, fewer parameters, lower training cost, and stronger performance under restricted sampling budgets across text and image tasks.
What carries the argument
Fixed-point solver over shared attention layers that iterates to convergence instead of using a fixed number of steps, combined with cross-step consistency loss and three-state reuse for stability in masked generation.
If this is right
- Training time and VRAM drop substantially while generative quality rises at fixed low budgets.
- Pre-trained masked models convert to the fixed-point form via short fine-tuning without full retraining.
- The same pattern improves both text perplexity and image FID scores when compute is constrained.
- Parameter count falls by roughly 39 percent while the model still outperforms the baseline at the same forward-pass budget.
Where Pith is reading between the lines
- The reuse pattern may extend to other iterative refinement processes that currently fix the number of steps per sample.
- Adaptive depth could reduce energy use on edge devices where total forward passes are the main cost driver.
- The consistency loss might stabilize training when sequence lengths grow beyond current test regimes.
Load-bearing premise
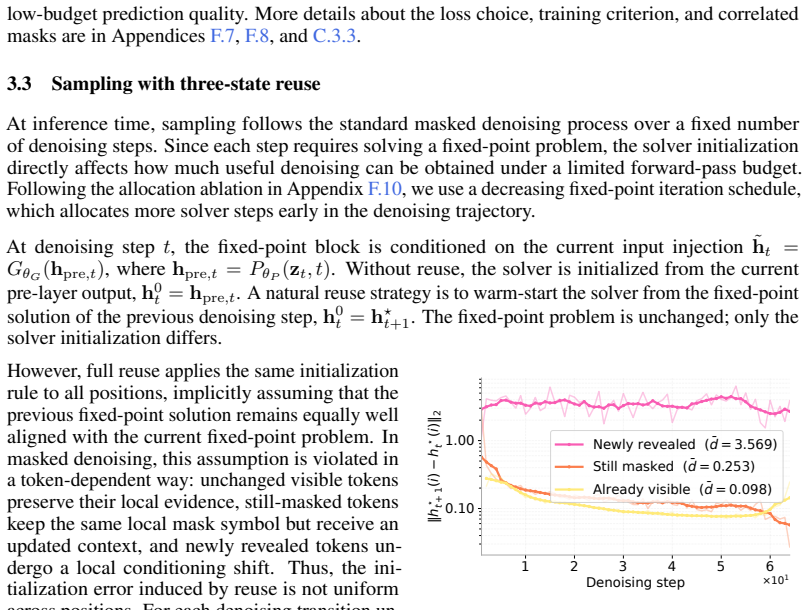
The fixed-point solver over the shared layers converges reliably and the added losses and reuse do not create instability or bias that would erase the reported quality gains.
What would settle it
A controlled run in which raising the allowed fixed-point iterations fails to improve or actively harms sample quality at every tested low budget would falsify the benefit of the adaptive solver.
Figures












read the original abstract
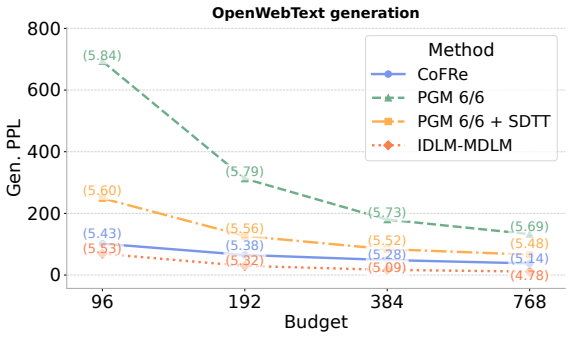
Masked Generative Models (MGMs) enable parallel decoding and achieve strong performance across modalities, but require full-sequence bidirectional transformers at every step, making training costly and degrading quality under low sampling budgets. Existing work improves efficiency via better samplers or cheaper fixed-depth denoisers, but they still allocate a fixed amount of denoiser computation to each refinement step. We introduce Fixed-Point Masked Generative Models (FP-MGMs), which replace part of the denoiser with a fixed-point solver over shared attention layers to enable adaptive depth with fewer parameters. To make it more effective for masked generation, we first introduce a cross-step consistency loss, which aligns hidden representations at neighboring denoising steps and, second, three-state reuse (3SR) which warm-starts the solver using the previous solution by treating differently unchanged, still-masked, and newly revealed tokens respectively. Together, these components define our complete training-to-inference framework for fixed-point masked generation, \emph{CoFRe}. We also show that pre-trained MGMs can be converted into FP-MGMs with short fine-tuning, avoiding full retraining. Across modalities, CoFRe improves the quality and cost trade-off. On OpenWebText, CoFRe reduces parameters by 38.8\%, training time by 11.5\%, and VRAM by 16.9\%, while improving generative perplexity from 830.8 to 101.8 at a budget of $96$ transformer-block forward passes, compared to MDLM. In ImageNette, CoFRe reduces training time by 48.6\% and VRAM by 50.7\%, while improving FID in all sample budgets tested. Overall, CoFRe offers a practical framework for cheaper training and stronger low-budget masked generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Fixed-Point Masked Generative Models (FP-MGMs) that replace part of the denoiser with a fixed-point solver over shared attention layers for adaptive depth and fewer parameters in masked generative modeling. It adds a cross-step consistency loss to align hidden states across denoising steps and three-state reuse (3SR) to warm-start the solver by distinguishing unchanged, still-masked, and newly revealed tokens. These form the CoFRe framework, which also supports short fine-tuning of pre-trained MGMs. The paper claims substantial efficiency gains (38.8% fewer parameters, 11.5% less training time, 16.9% less VRAM on OpenWebText; 48.6% less time and 50.7% less VRAM on ImageNette) and quality improvements (perplexity 830.8 to 101.8 at 96 block passes; better FID across budgets) versus MDLM.
Significance. If the results hold after verification, the work offers a practical route to lower training and inference costs in masked generative models while improving low-budget quality across text and images. The fine-tuning conversion path and explicit handling of adaptive depth via fixed-point iteration are potentially useful contributions if shown to be stable.
major comments (3)
- Abstract: the headline claims (perplexity drop from 830.8 to 101.8 at 96 passes; FID gains across budgets) rest on the fixed-point solver converging reliably and the consistency loss plus 3SR introducing no systematic bias, yet the manuscript supplies no residual-norm diagnostics, per-step iteration counts, or ablation that isolates the solver from the auxiliary objective.
- Abstract: the reported parameter (38.8%), time (11.5%), and VRAM (16.9%) reductions are presented without error bars, multiple random seeds, or controls confirming that the gains derive from the fixed-point mechanism rather than the new training losses alone.
- Abstract: no analysis is given of whether 3SR biases the learned distribution toward previously revealed tokens at low sampling budgets, which would undermine the quality-cost trade-off claim if present.
minor comments (2)
- Abstract: the acronym CoFRe is introduced without expansion.
- Abstract: comparisons are limited to MDLM; additional baselines would clarify the scope of the improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important aspects of empirical validation that we will strengthen in the revision. We address each major comment below.
read point-by-point responses
-
Referee: Abstract: the headline claims (perplexity drop from 830.8 to 101.8 at 96 passes; FID gains across budgets) rest on the fixed-point solver converging reliably and the consistency loss plus 3SR introducing no systematic bias, yet the manuscript supplies no residual-norm diagnostics, per-step iteration counts, or ablation that isolates the solver from the auxiliary objective.
Authors: We agree that explicit convergence diagnostics and an isolating ablation would strengthen the claims. In the revised manuscript we will add residual-norm plots across denoising steps, average per-step iteration counts, and an ablation that trains with the consistency loss and 3SR but replaces the fixed-point solver with a standard fixed-depth denoiser. These additions will directly verify reliable convergence and separate the solver's contribution from the auxiliary objectives. revision: yes
-
Referee: Abstract: the reported parameter (38.8%), time (11.5%), and VRAM (16.9%) reductions are presented without error bars, multiple random seeds, or controls confirming that the gains derive from the fixed-point mechanism rather than the new training losses alone.
Authors: The reported efficiency numbers compare the final CoFRe configuration against the MDLM baseline. To address the concern, the revision will include results over three random seeds with standard-error bars. We will also add a control experiment that applies the consistency loss and 3SR to a standard MGM without the fixed-point solver, allowing direct attribution of the parameter, time, and VRAM savings to the solver itself. revision: yes
-
Referee: Abstract: no analysis is given of whether 3SR biases the learned distribution toward previously revealed tokens at low sampling budgets, which would undermine the quality-cost trade-off claim if present.
Authors: The design of 3SR explicitly distinguishes unchanged, still-masked, and newly revealed tokens to preserve the original sampling distribution while accelerating convergence; the observed improvements in low-budget perplexity and FID are consistent with this intent. Nevertheless, we will add a targeted analysis in the revision that compares the empirical distribution of token reveal orders and per-token marginal probabilities between CoFRe and the baseline at low budgets (e.g., 32 and 64 passes) to rule out systematic bias. revision: yes
Circularity Check
No circularity: empirical gains are independent comparisons, not reductions to fitted inputs or self-citations
full rationale
The paper introduces FP-MGMs and the CoFRe framework via a fixed-point solver over shared attention layers, a cross-step consistency loss, and three-state reuse (3SR). Reported improvements (parameter reduction, training time, VRAM, perplexity from 830.8 to 101.8, FID) are framed as direct empirical comparisons to the MDLM baseline at fixed compute budgets. No equations, derivations, or first-principles claims are present that reduce a result to its own inputs by construction, nor is any load-bearing premise justified solely by overlapping self-citation. The central claims rest on experimental outcomes rather than algebraic equivalence or fitted-parameter renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA.Inter- national Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/ abs/2410.20672. 9
-
[2]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation.Advances in Neural Information Processing Systems (NeurIPS), 2025. URL https://arxiv.org/abs/ 2507.10524. 9
-
[3]
Zico Kolter, and Vladlen Koltun
Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. Deep Equilibrium Models.Advances in Neural Information Processing Systems (NeurIPS), 2019. URL https://arxiv.org/abs/ 1909.01377v2. 2, 4, 9
-
[4]
Fixed Point Diffusion Models.Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Xingjian Bai and Luke Melas-Kyriazi. Fixed Point Diffusion Models.Conference on Computer Vision and Pattern Recognition (CVPR), 2024. URL http://arxiv.org/abs/2401.08741. 2, 4, 5, 9, 19, 24
-
[5]
Victor Besnier, Mickael Chen, David Hurych, Eduardo Valle, and Matthieu Cord. Halton Scheduler For Masked Generative Image Transformer.International Conference on Learning Representations (ICLR), 2025. URL http://arxiv.org/abs/2503.17076. 2, 4, 7, 9, 25, 26
-
[6]
Self-Speculative Masked Diffusions.International Conference on Learning Representations (ICLR), 2026
Andrew Campbell, Valentin De Bortoli, Jiaxin Shi, and Arnaud Doucet. Self-Speculative Masked Diffusions.International Conference on Learning Representations (ICLR), 2026. URL http://arxiv.org/abs/2510.03929. 9
- [7]
-
[8]
One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One Billion Word Benchmark for Measuring Progress in Statistical Language Modeling.arXiv preprint arXiv:1312.3005, 2014. URL http://arxiv.org/abs/1312.3005. 25
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[9]
Sitong Chen, Shen Nie, Jiacheng Sun, Zijin Feng, Zhenguo Li, Ji-Rong Wen, and Chongxuan Li. Masked Diffusion Models as Energy Minimization.Advances in Neural Information Processing Systems (NeurIPS), 2025. URLhttp://arxiv.org/abs/2509.13866. 2 10
-
[10]
Marco Comunità, Zhi Zhong, Akira Takahashi, Shiqi Yang, Mengjie Zhao, Koichi Saito, Yukara Ikemiya, Takashi Shibuya, Shusuke Takahashi, and Yuki Mitsufuji. SpecMaskGIT: Masked Generative Modeling of Audio Spectrograms for Efficient Audio Synthesis and Beyond.arXiv preprint arXiv:2406.17672, 2024. URLhttp://arxiv.org/abs/2406.17672. 2
-
[11]
Vision Transformers Need Registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision Transformers Need Registers.International Conference on Learning Representations (ICLR), 2024. URL http://arxiv.org/abs/2309.16588. 26
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Univer- sal Transformers.International Conference on Learning Representations (ICLR), 2019. URL http://arxiv.org/abs/1807.03819. 2, 9
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[13]
Imagenet: A large-scale hierarchical image database.Conference on Computer Vision and Pattern Recognition (CVPR),
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database.Conference on Computer Vision and Pattern Recognition (CVPR),
- [14]
-
[15]
Justin Deschenaux and Caglar Gulcehre. Promises, outlooks and challenges of Diffusion Language Modeling.arXiv preprint arXiv:2406.11473, 2024. URL https://arxiv.org/ abs/2406.11473. 2, 25
-
[16]
Justin Deschenaux and Caglar Gulcehre. Beyond autoregression: Fast LLMs via Self-Distillation Through Time.International Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2410.21035. 3, 9, 26, 32, 38
-
[17]
Justin Deschenaux, Lan Tran, and Caglar Gulcehre. Partition Generative Modeling: Masked Modeling Without Masks.International Conference on Learning Representations (ICLR), 2026. URLhttp://arxiv.org/abs/2505.18883. 2, 9, 27, 31, 32
-
[18]
Continuous diffusion for categorical data
Sander Dieleman, Laurent Sartran, Arman Roshannai, Nikolay Savinov, Yaroslav Ganin, Pierre H. Richemond, Arnaud Doucet, Robin Strudel, Chris Dyer, Conor Durkan, Curtis Hawthorne, Rémi Leblond, Will Grathwohl, and Jonas Adler. Continuous diffusion for cate- gorical data.arXiv preprint arXiv:2211.15089, 2022. URL https://arxiv.org/abs/2211. 15089. 27
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [20]
-
[21]
Samy Wu Fung, Howard Heaton, Qiuwei Li, Daniel McKenzie, Stanley Osher, and Wotao Yin. JFB: Jacobian-Free Backpropagation for Implicit Networks.Association for the Advancement of Artificial Intelligence (AAAI), 2022. URLhttps://arxiv.org/abs/2103.12803v4. 19
-
[22]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
-
[23]
Zhengyang Geng, Ashwini Pokle, and J. Zico Kolter. One-Step Diffusion Distillation via Deep Equilibrium Models.Advances in Neural Information Processing Systems (NeurIPS), 2023. URLhttps://arxiv.org/abs/2401.08639. 9
-
[24]
Lee, and Dimitris Papailiopoulos
Angeliki Giannou, Shashank Rajput, Jy yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers.International Conference on Machine Learning (ICML), 2023. URLhttps://arxiv.org/abs/2301.13196. 2
-
[25]
OpenWebText corpus
Aaron Gokaslan and Vanya Cohen. OpenWebText corpus. http://Skylion007.github. io/OpenWebTextCorpus, 2019. 3, 7
2019
-
[26]
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. Scaling Diffusion Language Models via Adaptation from Autoregressive Models.International Conference on Learning Representations (ICLR), 2025. URLhttp://arxiv.org/abs/2410.17891. 9 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
J. H. Halton. Algorithm 247: Radical-inverse quasi-random point sequence.Communications of the ACM, 7(12):701–702, 1964. ISSN 0001-0782. doi: 10.1145/355588.365104. URL https://doi.org/10.1145/355588.365104. 4, 26
-
[28]
Demystifying MaskGIT Sampler and Beyond: Adaptive Order Selection in Masked Diffusion
Satoshi Hayakawa, Yuhta Takida, Masaaki Imaizumi, Hiromi Wakaki, and Yuki Mitsufuji. Demystifying MaskGIT Sampler and Beyond: Adaptive Order Selection in Masked Diffusion. Transactions on Machine Learning Research, 2026. URL http://arxiv.org/abs/2510. 04525. 2
2026
-
[29]
Reasoning with Latent Tokens in Diffusion Language Models.arXiv preprint arXiv:2602.03769, 2026
Andre He, Sean Welleck, and Daniel Fried. Reasoning with Latent Tokens in Diffusion Language Models.arXiv preprint arXiv:2602.03769, 2026. URL http://arxiv.org/abs/ 2602.03769. 2
-
[30]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in Neural Information Processing Systems (NeurIPS), 2017. URL https://arxiv.org/abs/ 1706.08500. 7
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
The curious case of neural text degeneration.International Conference on Learning Representations (ICLR), 2020
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration.International Conference on Learning Representations (ICLR), 2020. URL https://openreview.net/forum?id=rygGQyrFvH. 31
2020
-
[32]
arXiv preprint arXiv:2510.05725 , url =
Chunsan Hong, Seonho An, Min-Soo Kim, and Jong Chul Ye. Improving Discrete Diffusion Unmasking Policies Beyond Explicit Reference Policies.International Conference on Learning Representations (ICLR), 2026. URLhttp://arxiv.org/abs/2510.05725. 9
-
[33]
Emiel Hoogeboom, David Ruhe, Jonathan Heek, Thomas Mensink, and Tim Salimans. Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD.arXiv preprint arXiv:2603.20155, 2026. URLhttps://arxiv.org/abs/2603.20155. 9
-
[34]
Imagenette: A smaller subset of 10 easily classified classes from ImageNet
Jeremy Howard. Imagenette: A smaller subset of 10 easily classified classes from ImageNet. https://github.com/fastai/imagenette, 2019. 3, 7
2019
-
[35]
Learning Unmasking Policies for Diffusion Language Models
Metod Jazbec, Theo X. Olausson, Louis Béthune, Pierre Ablin, Michael Kirchhof, João Monteiro, Victor Turrisi, Jason Ramapuram, and Marco Cuturi. Learning Unmasking Policies for Diffusion Language Models.arXiv preprint arXiv:2512.09106, 2026. URL http://arxiv.org/abs/2512.09106. 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Ahmadreza Jeddi, Marco Ciccone, and Babak Taati. LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation.International Conference on Learning Representations (ICLR), 2026. URLhttps://arxiv.org/abs/2602.11451. 9
-
[37]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks.arXiv preprint arXiv:2510.04871, 2025. URLhttps://arxiv.org/abs/2510.04871. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
arXiv preprint arXiv:2502.06768 , archiveprefix =
Jaeyeon Kim, Kulin Shah, Vasilis Kontonis, Sham Kakade, and Sitan Chen. Train for the Worst, Plan for the Best: Understanding Token Ordering in Masked Diffusions.International Conference on Machine Learning (ICML), 2025. URLhttp://arxiv.org/abs/2502.06768. 9
-
[39]
Stop Training for the Worst: Progressive Unmasking Accelerates Masked Diffusion Training
Jaeyeon Kim, Jonathan Geuter, David Alvarez-Melis, Sham Kakade, and Sitan Chen. Stop Training for the Worst: Progressive Unmasking Accelerates Masked Diffusion Training.arXiv preprint arXiv:2602.10314, 2026. URLhttp://arxiv.org/abs/2602.10314. 9
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Minseo Kim, Chenfeng Xu, Coleman Hooper, Harman Singh, Ben Athiwaratkun, Ce Zhang, Kurt Keutzer, and Amir Gholami. CDLM: Consistency Diffusion Language Models for Faster Sampling.Conference on Machine Learning and Systems (MLSys), 2026. URL https: //arxiv.org/abs/2511.19269. 9
-
[41]
Similarity of neural network representations revisited.International Conference on Machine Learning (ICML),
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited.International Conference on Machine Learning (ICML),
-
[42]
URLhttps://arxiv.org/abs/1905.00414. 22 12
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[43]
IDLM: Inverse-distilled Diffusion Language Models
David Li, Nikita Gushchin, Dmitry Abulkhanov, Eric Moulines, Ivan Oseledets, Maxim Panov, and Alexander Korotin. IDLM: Inverse-distilled Diffusion Language Models.arXiv preprint arXiv:2602.19066, 2026. URLhttps://arxiv.org/abs/2602.19066. 9, 32
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Xiang Li, Kai Qiu, Hao Chen, Jason Kuen, Jiuxiang Gu, Bhiksha Raj, and Zhe Lin. Imagefolder: Autoregressive image generation with folded tokens.arXiv preprint arXiv:2410.01756, 2024. URLhttps://arxiv.org/abs/2410.01756. 7, 25
-
[45]
XQ-GAN: An open-source image tokenization framework for autoregressive generation
Xiang Li, Kai Qiu, Hao Chen, Jason Kuen, Jiuxiang Gu, Jindong Wang, Zhe Lin, and Bhiksha Raj. XQ-GAN: An open-source image tokenization framework for autoregressive generation. arXiv preprint arXiv:2412.01762, 2024. URL https://arxiv.org/abs/2412.01762. 7, 25
-
[46]
Divergence frontiers for generative models: Sample complexity, quantization effects, and frontier integrals.Advances in Neural Information Processing Systems (NeurIPS), 2021
Lang Liu, Krishna Pillutla, Sean Welleck, Sewoong Oh, Yejin Choi, and Zaid Harchaoui. Divergence frontiers for generative models: Sample complexity, quantization effects, and frontier integrals.Advances in Neural Information Processing Systems (NeurIPS), 2021. URL https://openreview.net/forum?id=Z_J5bCb4Rra. 30
2021
-
[47]
Sulin Liu, Juno Nam, Andrew Campbell, Hannes Stärk, Yilun Xu, Tommi Jaakkola, and Rafael Gómez-Bombarelli. Think While You Generate: Discrete Diffusion with Planned Denoising.International Conference on Learning Representations (ICLR), 2025. URL https: //arxiv.org/abs/2410.06264. 9
-
[48]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution.International Conference on Machine Learning (ICML), 2024. URLhttp://arxiv.org/abs/2310.16834. 26
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models
Omer Luxembourg, Haim Permuter, and Eliya Nachmani. Plan for Speed: Dilated Scheduling for Masked Diffusion Language Models.arXiv preprint arXiv:2506.19037, 2025. URL http://arxiv.org/abs/2506.19037. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
David Mizrahi, Roman Bachmann, O ˘guzhan Fatih Kar, Teresa Yeo, Mingfei Gao, Afshin Dehghan, and Amir Zamir. 4M: Massively Multimodal Masked Modeling.Advances in Neural Information Processing Systems (NeurIPS), 2023. URL http://arxiv.org/abs/ 2312.06647. 2
-
[51]
Shen Nie, Fengqi Zhu, Chao Du, Tianyu Pang, Qian Liu, Guangtao Zeng, Min Lin, and Chongxuan Li. Scaling up Masked Diffusion Models on Text.International Conference on Learning Representations (ICLR), 2025. URLhttp://arxiv.org/abs/2410.18514. 25
-
[52]
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, and Chongxuan Li. Your absorbing discrete diffusion secretly models the conditional distributions of clean data.International Conference on Learning Representations (ICLR), 2025. URL https: //arxiv.org/abs/2406.03736. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Yong-Hyun Park, Chieh-Hsin Lai, Satoshi Hayakawa, Yuhta Takida, and Yuki Mitsufuji. “Jump Your Steps”: Optimizing Sampling Schedule of Discrete Diffusion Models.International Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/ 2410.07761. 9
-
[54]
Path Planning for Masked Diffusion Model Sampling.arXiv preprint arXiv:2502.03540, 2025
Fred Zhangzhi Peng, Zachary Bezemek, Sawan Patel, Jarrid Rector-Brooks, Sherwood Yao, Avishek Joey Bose, Alexander Tong, and Pranam Chatterjee. Path Planning for Masked Diffusion Model Sampling.arXiv preprint arXiv:2502.03540, 2025. URL http://arxiv. org/abs/2502.03540. 2, 9
-
[55]
MAUVE: Measuring the gap between neural text and human text using divergence frontiers.Advances in Neural Information Processing Systems (NeurIPS),
Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. MAUVE: Measuring the gap between neural text and human text using divergence frontiers.Advances in Neural Information Processing Systems (NeurIPS),
-
[56]
URLhttps://openreview.net/forum?id=Tqx7nJp7PR. 30, 31
-
[57]
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, and Daniel Y . Fu. Parcae: Scaling laws for stable looped language models.arXiv preprint arXiv:2604.12946, 2026. URL https: //arxiv.org/abs/2604.12946. 2, 9, 25 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Generative Frontiers: Why Evaluation Matters for Diffusion Language Models
Patrick Pynadath, Jiaxin Shi, and Ruqi Zhang. Generative frontiers: Why evaluation matters for diffusion language models.arXiv preprint arXiv:2604.02718, 2026. URL https://arxiv. org/abs/2604.02718. 44
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
Language models are unsupervised multitask learners, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019. URL https://openai.com/ blog/better-language-models/. 26
2019
-
[60]
Rotskoff, Molei Tao, and Lexing Ying
Yinuo Ren, Haoxuan Chen, Yuchen Zhu, Wei Guo, Yongxin Chen, Grant M. Rotskoff, Molei Tao, and Lexing Ying. Fast Solvers for Discrete Diffusion Models: Theory and Applications of High-Order Algorithms.Advances in Neural Information Processing Systems (NeurIPS), 2025. URLhttp://arxiv.org/abs/2502.00234. 9
-
[61]
Chiu, Alexander Rush, and V olodymyr Kuleshov
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T. Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and Effective Masked Diffusion Language Models.Advances in Neural Information Processing Systems (NeurIPS),
-
[62]
arXiv preprint arXiv:2406.07524 , year =
URLhttp://arxiv.org/abs/2406.07524. 2, 3, 7, 8, 25, 26, 44
-
[63]
The Diffusion Duality.International Conference on Machine Learning (ICML), 2025
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin Chiu, and V olodymyr Kuleshov. The Diffusion Duality.International Conference on Machine Learning (ICML), 2025. URLhttp://arxiv.org/abs/2506.10892. 9
-
[64]
Improved Techniques for Training GANs
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in Neural Information Processing Systems (NeurIPS), 2016. URLhttps://arxiv.org/abs/1606.03498. 7
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[66]
URLhttp://arxiv.org/abs/2604.02340. 2
work page internal anchor Pith review Pith/arXiv arXiv
- [67]
-
[68]
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable Length Video Generation From Open Domain Textual Description.arXiv preprint arXiv:2210.02399, 2022. URLhttp://arxiv.org/abs/2210.02399. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[69]
Guanghan Wang, Yair Schiff, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Remasking dis- crete diffusion models with inference-time scaling.Advances in Neural Information Processing Systems (NeurIPS), 2025. URLhttps://arxiv.org/abs/2503.00307. 2, 30, 31
-
[70]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7B: Diffusion Large Language Models.arXiv preprint arXiv:2508.15487, 2025. URLhttp://arxiv.org/abs/2508.15487. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Zebin You, Jingyang Ou, Xiaolu Zhang, Jun Hu, Jun Zhou, and Chongxuan Li. Effective and Efficient Masked Image Generation Models.International Conference on Machine Learning (ICML), 2025. URLhttp://arxiv.org/abs/2503.07197. 2
-
[73]
URLhttp://arxiv.org/abs/2602.11698. 9
work page internal anchor Pith review Pith/arXiv arXiv
-
[74]
Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, and Lu Jiang
Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G. Hauptmann, Ming-Hsuan Yang, Yuan Hao, Irfan Essa, and Lu Jiang. MAGVIT: Masked Generative Video Transformer.Conference on Computer Vision and Pattern Recognition (CVPR), 2023. URL https://openaccess.thecvf.com/content/CVPR2023/papers/ Yu_MAGVIT_Masked_Generative_Video_Tr...
2023
-
[75]
Shuibai Zhang, Caspian Zhuang, Chihan Cui, Zhihan Yang, Fred Zhangzhi Peng, Yanxin Zhang, Haoyue Bai, Zack Jia, Yang Zhou, Guanhua Chen, and Ming Liu. Expert-choice routing enables adaptive computation in diffusion language models.arxiv preprint arXiv:2604.01622, 2026. URLhttps://arxiv.org/abs/2604.01622. 2
-
[76]
Kaiwen Zheng, Yongxin Chen, Hanzi Mao, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling.International Conference on Learning Representations (ICLR), 2025. URLhttp://arxiv.org/abs/2409.02908. 26, 27, 31
-
[77]
Yuanzhi Zhu, Xi Wang, Stéphane Lathuilière, and Vicky Kalogeiton. Di$\mathtt{[M]}$O: Distilling Masked Diffusion Models into One-step Generator.Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. URL http://arxiv.org/abs/ 2503.15457. 9 15 Contents 1 Introduction 1 2 Background 3 2.1 Discrete generative models and masked g...
-
[78]
For language modeling, we tune on OWT for 100k steps with sequence length 128 in order to obtain fast and cheap comparisons
Choice of tuning setup.We first select the target setting for hyperparameter tuning. For language modeling, we tune on OWT for 100k steps with sequence length 128 in order to obtain fast and cheap comparisons
-
[79]
We evaluate a small grid of candidate architectures and retain the best-performing one
Architecture tuning.We tune the number of preprocessing and postprocessing layers in the fixed-point backbone, while keeping the fixed-point solver hyperparameters at the default values of Bai and Melas-Kyriazi [4]. We evaluate a small grid of candidate architectures and retain the best-performing one
-
[80]
This isolates the effect of the implicit solver from that of the backbone architecture
Solver tuning.With the architecture fixed, we tune the fixed-point solver budget, including the number of no-gradient and with-gradient iterations. This isolates the effect of the implicit solver from that of the backbone architecture
-
[81]
Learning-rate tuning.With both the architecture and solver settings fixed, we tune the learning rate over a logarithmic grid and select the value that gives the best validation performance
-
[82]
Boundary check.Whenever the best hyperparameter lies at the edge of the tested range, we extend the search range and repeat the evaluation until the selected value is not on the boundary
-
[83]
24 D.1.2 Learning-rate and solver tuning We tune the main optimization and solver hyperparameters through small-scale experiments before running the full training jobs
Final selection.Finally, we choose the configuration that performs best under this tuning protocol and use it for the full training runs. 24 D.1.2 Learning-rate and solver tuning We tune the main optimization and solver hyperparameters through small-scale experiments before running the full training jobs. We first test the base learning rate used for MDLM...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.