Shared Doubt: Zero-Shot Cross-Lingual Confidence Estimation for Language Models
Pith reviewed 2026-06-28 22:26 UTC · model grok-4.3
The pith
A linear probe trained only on English can predict answer reliability in other languages without any retraining or target data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
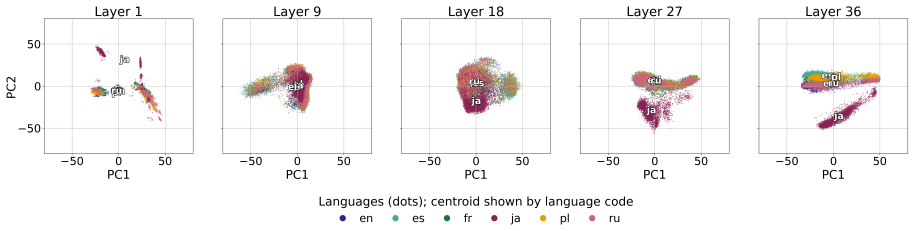
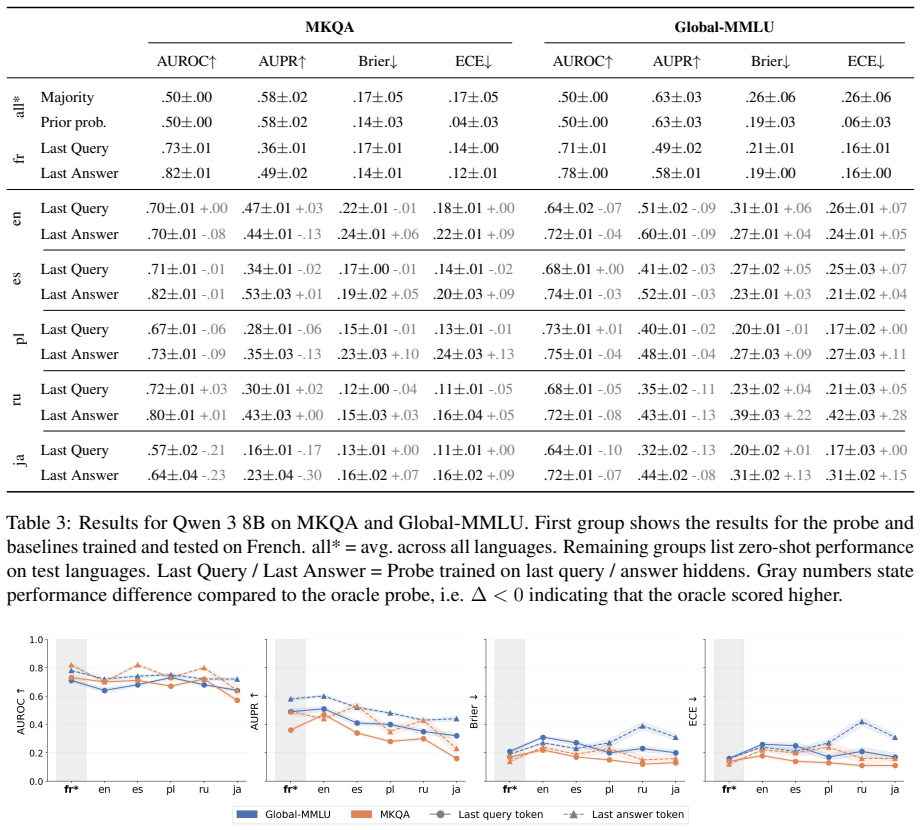
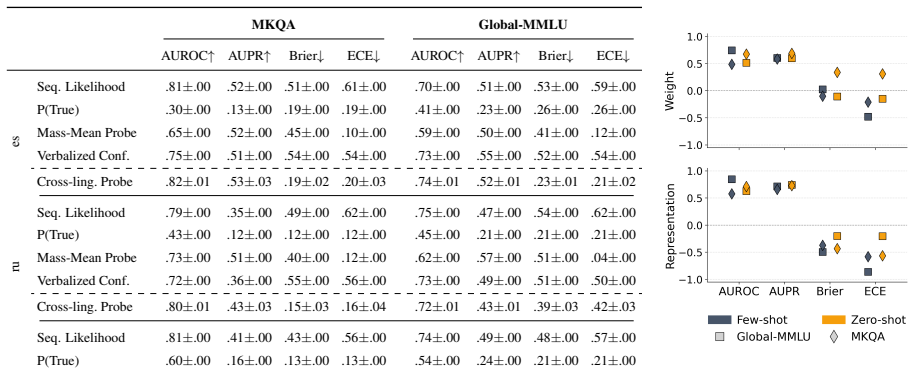
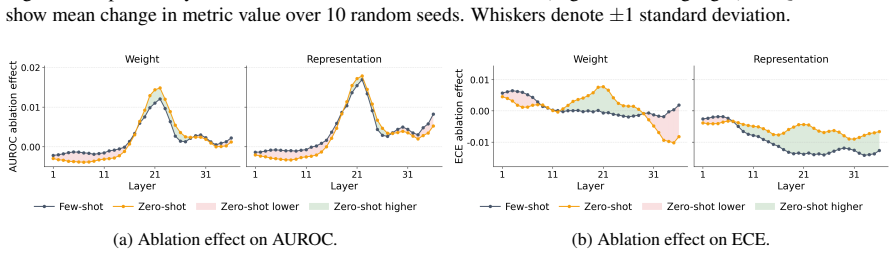
Multilingual LLMs encode shared, language-transferable confidence features in their intermediate representations. A lightweight linear probe trained to predict answer correctness directly from these representations on one language generalizes zero-shot to unseen, typologically diverse languages without target-language supervision. Learned layer weights and ablations show that confidence features concentrate in middle layers across languages, indicating a shared confidence subspace. The probe matches or exceeds other popular confidence estimation methods while requiring no retraining.
What carries the argument
Linear probe on intermediate hidden states that predicts answer correctness, with learned per-layer weights that highlight middle-layer contributions.
If this is right
- Confidence estimation becomes feasible for languages lacking labeled data or resources for retraining.
- Deployment of LLMs in multilingual settings gains a lightweight, reusable reliability signal.
- Model analysis can focus on middle layers to study where reliability information is represented.
- Zero-shot transfer reduces the need for parallel confidence datasets across languages.
Where Pith is reading between the lines
- Similar probes might transfer other properties such as factuality or uncertainty beyond binary correctness.
- The middle-layer concentration could be tested in monolingual models to check if the subspace is inherently multilingual.
- Performance dependence on language similarity suggests pairing source and target languages by typological distance for best results.
- The method could be extended to generation tasks other than open-ended QA without new supervision.
Load-bearing premise
Multilingual models contain confidence features in intermediate layers that remain consistent enough across languages for a probe trained in one language to extract them in others without adaptation.
What would settle it
The probe achieving near-chance accuracy on a language family distant from the training language, or ablations showing no consistent middle-layer concentration of predictive features across models.
Figures














read the original abstract
Confidence estimation (CE), i.e., quantifying the reliability of a model's prediction, has attracted great interest in the context of large language models (LLMs). However, most studies focus on English, ignoring the multilingual reality of LLM usage, while many CE methods degrade or require retraining across languages. To address this gap, we investigate whether multilingual LLMs encode shared, language-transferable confidence features in open-ended question answering. We use a lightweight linear probe that predicts answer correctness directly from intermediate representations. Trained monolingually, the probe generalizes zero-shot to unseen, typologically diverse languages without target-language supervision. Learned layer weights and multiple ablations reveal that confidence features concentrate in middle layers across languages, suggesting a shared confidence subspace. While zero-shot cross-lingual performance depends on similarity to the source language, the probe provides a strong baseline without any retraining and compares favorably to other popular confidence estimation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multilingual LLMs encode shared, language-transferable confidence features in intermediate representations for open-ended QA. A lightweight linear probe trained monolingually on one language's representations predicts answer correctness and generalizes zero-shot to typologically diverse unseen languages without any target-language supervision or adaptation. Ablations and learned layer weights indicate that these confidence features concentrate in middle layers across languages, forming a shared subspace; zero-shot performance varies with source-target similarity but the probe serves as a strong baseline compared to other CE methods.
Significance. If the empirical results hold, the work provides a simple, parameter-light method for cross-lingual confidence estimation that avoids retraining or target supervision, directly addressing the multilingual gap in CE research. The layer-concentration finding and ablations offer evidence for a shared confidence subspace in multilingual models, which could inform future probing and interpretability studies. The zero-shot generalization across diverse languages is a notable strength if supported by the full experimental details.
minor comments (3)
- [§4] §4 (Experiments): clarify the exact set of languages used for training vs. zero-shot testing and report the typological diversity metrics (e.g., language family, script, resource level) to allow readers to assess the strength of the generalization claim.
- [Table 2] Table 2 or equivalent results table: include standard deviations or confidence intervals over multiple runs/seeds for the zero-shot accuracies, as single-point estimates make it hard to judge whether the probe reliably outperforms the compared CE baselines.
- [§5.2] §5.2 (Layer analysis): the statement that features 'concentrate in middle layers' would benefit from a quantitative definition (e.g., threshold on normalized weights or entropy of the weight distribution) rather than relying solely on visualization.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work, the detailed summary, and the recommendation for minor revision. No specific major comments appear in the report, so we have no points requiring point-by-point response or manuscript changes at this stage.
Circularity Check
No significant circularity
full rationale
The paper is an empirical study that trains a linear probe on intermediate LLM representations in one language and evaluates zero-shot transfer to other languages. The abstract and summary describe experimental results, layer-weight analysis, and ablations without any equations, derivations, or self-citations that reduce the reported generalization to a fitted quantity by construction. The central claim rests on observed performance differences across languages and layers rather than on any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- linear probe weights
axioms (1)
- domain assumption Intermediate representations of multilingual LLMs contain confidence features that are transferable across languages
Reference graph
Works this paper leans on
-
[1]
LLM internal states reveal hallucination risk faced with a query. InProceedings of the 7th Black- boxNLP Workshop: Analyzing and Interpreting Neu- ral Networks for NLP, pages 88–104, Miami, Florida, US. Association for Computational Linguistics. Ziwei Ji, Lei Yu, Yeskendir Koishekenov, Yejin Bang, Anthony Hartshorn, Alan Schelten, Cheng Zhang, 10 Pascale ...
-
[2]
Confidently wrong: Exploring the calibration and expression of (un) certainty of large language models in a multilingual setting. InProceedings of the workshop on multimodal, multilingual natu- ral language generation and multilingual WebNLG Challenge (MM-NLG 2023), pages 1–9. Sneha Kudugunta, Ankur Bapna, Isaac Caswell, and Orhan Firat. 2019. Investigati...
-
[3]
The Linear Representation Hypothesis and the Geometry of Large Language Models
A unifying view on dataset shift in classifica- tion.Pattern recognition, 45(1):521–530. Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. 2015. Obtaining well calibrated proba- bilities using bayesian binning. InProceedings of the AAAI conference on artificial intelligence, volume 29. OpenAI. 2025. Introducing GPT-4.1 in the API. https: //open...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[4]
Wenfang Sun, Xinyuan Song, Pengxiang Li, Lu Yin, Yefeng Zheng, and Shiwei Liu
Global mmlu: Understanding and addressing cultural and linguistic biases in multilingual evalua- tion.Preprint, arXiv:2412.03304. Wenfang Sun, Xinyuan Song, Pengxiang Li, Lu Yin, Yefeng Zheng, and Shiwei Liu. 2025. The curse of depth in large language models.CoRR, abs/2502.05795. Yuqiao Tan, Shizhu He, Kang Liu, and Jun Zhao. 2025. Neural incompatibility:...
-
[5]
InFindings of the Association for Computa- tional Linguistics: EMNLP 2022, pages 2707–2735
Exploring predictive uncertainty and calibra- tion in nlp: A study on the impact of method & data scarcity. InFindings of the Association for Computa- tional Linguistics: EMNLP 2022, pages 2707–2735. Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Oh. 2024. Calibrating large language models using their generations only. InProceedings of the...
-
[6]
On the calibration of multilingual question answering llms.arXiv preprint arXiv:2311.08669. Dongkeun Yoon, Seungone Kim, Sohee Yang, Sunky- oung Kim, Soyeon Kim, Yongil Kim, Eunbi Choi, Yireun Kim, and Minjoon Seo. 2025. Reason- ing models better express their confidence.arXiv preprint arXiv:2505.14489. Hongchuan Zeng, Senyu Han, Lu Chen, and Kai Yu
-
[7]
Converging to a lingua franca: Evolution of linguistic regions and semantics alignment in mul- tilingual large language models. InProceedings of the 31st International Conference on Computational Linguistics, pages 10602–10617, Abu Dhabi, UAE. Association for Computational Linguistics. Caiqi Zhang, Chang Shu, Ehsan Shareghi, and Nigel Collier. 2025a. All ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.