Beyond Classification: Dynamic Adapter Routing for Continual Multimodal Retrieval
Pith reviewed 2026-06-28 23:00 UTC · model grok-4.3
The pith
Dynamic Adapter Routing outperforms standard CIL methods in continual multimodal retrieval using prototype-based selection and merging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
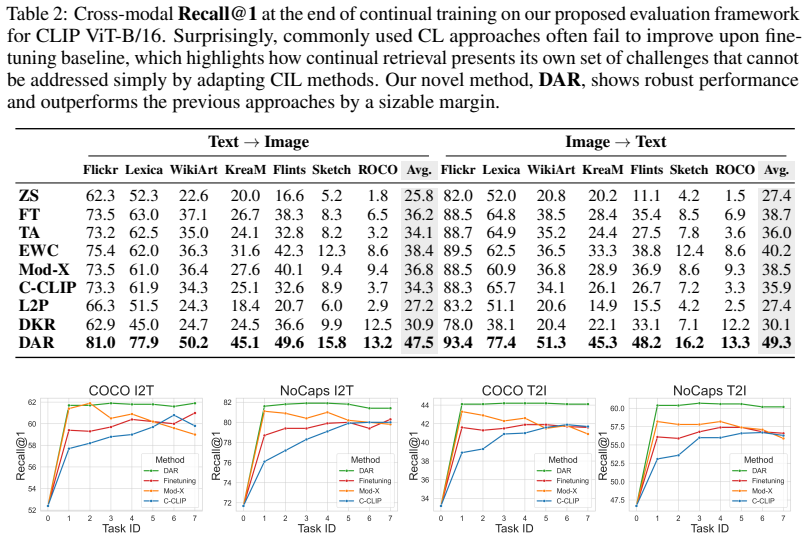
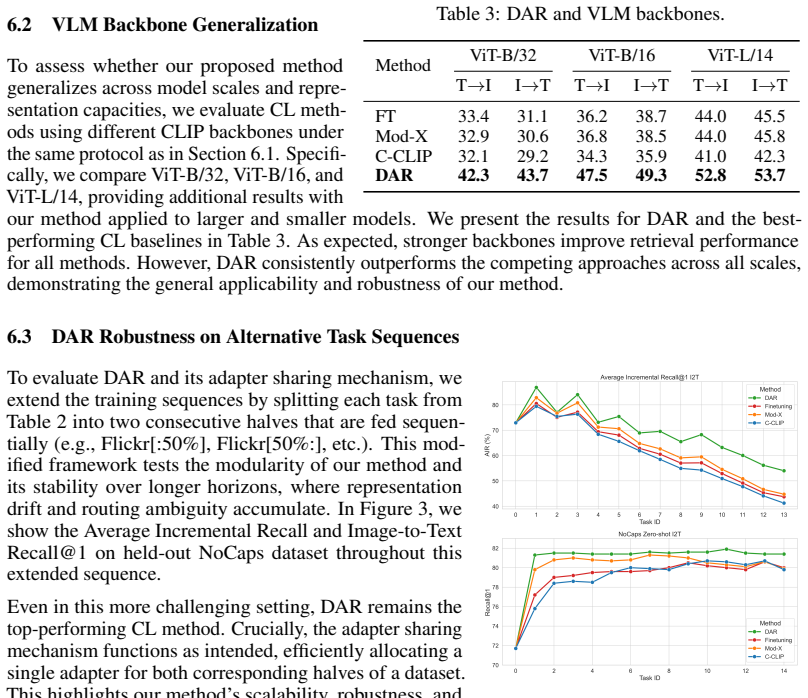
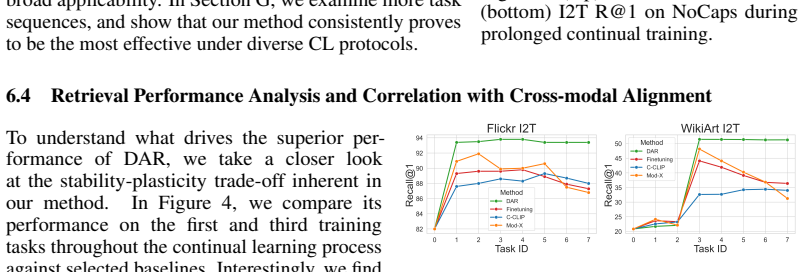
In a challenging continual multimodal retrieval scenario spanning diverse visual domains, standard class-incremental learning methods fail to yield meaningful gains, while Dynamic Adapter Routing, based on adapters selected through prototype-based routing and combined via model merging, achieves superior performance over the previous baselines and demonstrates strong generalization under out-of-distribution evaluation.
What carries the argument
Dynamic Adapter Routing (DAR), which selects adapters via prototype-based routing and combines them through model merging.
If this is right
- Standard CIL methods fail to yield meaningful gains in the more challenging CMR scenario.
- DAR achieves superior performance over the previous baselines.
- DAR demonstrates strong generalization under out-of-distribution evaluation.
- The new framework reveals unique challenges of CMR that classification-focused methods do not address.
Where Pith is reading between the lines
- The prototype-routing idea could be tested on other retrieval-heavy tasks such as image captioning or visual question answering under continual updates.
- Alternative merging techniques might further improve DAR without changing the routing step.
- The evaluation framework could serve as a testbed for retrieval-specific regularization methods beyond adapters.
Load-bearing premise
That the new principled evaluation framework for continual multimodal retrieval spanning diverse visual domains accurately captures retrieval-specific dynamics and that standard CIL methods were appropriately adapted and tested within it.
What would settle it
A result in which DAR fails to outperform adapted CIL baselines on the proposed CMR benchmark or shows no advantage on out-of-distribution test sets would falsify the central claim.
Figures

read the original abstract
While retrieval is a core function of vision-language models, continually updating these models for retrieval tasks remains critically underexplored. Existing work often approaches continual retrieval through the lens of class-incremental learning (CIL), evaluating both standard CIL methods and retrieval-oriented adaptations in settings that may not fully capture the retrieval-specific dynamics. To address this, we introduce a new, principled evaluation framework for continual multimodal retrieval (CMR) spanning diverse visual domains, and systematically evaluate common approaches within this setting. Our empirical analysis shows that standard CIL methods fail to yield meaningful gains in our more challenging scenario. Therefore, we propose Dynamic Adapter Routing (DAR), a novel approach based on adapters selected through prototype-based routing and combined via model merging.DAR achieves superior performance over the previous baselines and demonstrates strong generalization under out-of-distribution evaluation. Our results highlights the unique challenges of CMR and encourages further research in this direction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a new principled evaluation framework for continual multimodal retrieval (CMR) spanning diverse visual domains. It empirically shows that standard class-incremental learning (CIL) methods fail to yield meaningful gains in this setting and proposes Dynamic Adapter Routing (DAR), a method based on prototype-based routing for selecting adapters that are then combined via model merging. The central claim is that DAR achieves superior performance over previous baselines and demonstrates strong generalization under out-of-distribution evaluation.
Significance. If the framework accurately reflects retrieval-specific dynamics (embedding similarity, cross-modal matching, domain shifts) rather than classification proxies and the results are reproducible, the work would be significant in shifting continual learning research for vision-language models from classification to retrieval tasks, while providing a benchmark and a novel adapter-routing approach that could stimulate further CMR research.
major comments (2)
- [Abstract] Abstract: the claim of empirical superiority for DAR and failure of CIL baselines supplies no metrics (e.g., R@K, mAP), dataset details, task sequences, or experimental protocol, preventing verification that the results support the central claim.
- [Evaluation Framework] CMR framework description: no concrete information is given on domain coverage, how retrieval metrics replace classification accuracy, or the precise adaptations made to standard CIL methods (rehearsal buffers, regularization, parameter isolation) for retrieval heads instead of classifiers; this is load-bearing for the assertion that the framework captures retrieval-specific dynamics rather than introducing artifacts.
minor comments (1)
- Notation for 'prototype-based routing' and 'model merging' could be formalized with a short equation or pseudocode in the method section to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and evaluation framework. We address the two major comments point by point below and will revise the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of empirical superiority for DAR and failure of CIL baselines supplies no metrics (e.g., R@K, mAP), dataset details, task sequences, or experimental protocol, preventing verification that the results support the central claim.
Authors: We agree that the abstract would benefit from including concrete quantitative support for the central claims. In the revised version we will add key results (e.g., average R@1 and mAP gains of DAR over the strongest CIL baseline, number of domains, and task sequence length) while preserving the abstract's brevity. The full experimental protocol, datasets, and task sequences are already reported in Section 4; the abstract revision will simply surface the most salient numbers to allow immediate verification of the claims. revision: yes
-
Referee: [Evaluation Framework] CMR framework description: no concrete information is given on domain coverage, how retrieval metrics replace classification accuracy, or the precise adaptations made to standard CIL methods (rehearsal buffers, regularization, parameter isolation) for retrieval heads instead of classifiers; this is load-bearing for the assertion that the framework captures retrieval-specific dynamics rather than introducing artifacts.
Authors: We acknowledge that the current description of the CMR framework would be strengthened by additional concrete details. Section 3 already defines the shift from classification accuracy to retrieval metrics (Recall@K, mAP) and outlines the domain coverage across natural, medical, satellite, and artistic imagery, but we will expand this section with explicit lists of domains, the exact number of tasks, and the precise modifications applied to each CIL baseline (e.g., storing normalized embeddings rather than class prototypes in rehearsal buffers, adapting EWC-style regularization to cross-modal similarity losses, and replacing classifier heads with retrieval heads). These additions will make the retrieval-specific adaptations fully explicit and address the concern that the framework may introduce artifacts. revision: yes
Circularity Check
Empirical proposal with no derivation chain or self-referential reductions
full rationale
The paper introduces a new evaluation framework for continual multimodal retrieval and proposes the DAR method as an empirical solution, with all central claims resting on experimental comparisons rather than any mathematical derivation. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the approach is presented as a practical adapter-based routing technique whose performance is measured against baselines in the new setting. This is a standard empirical contribution whose validity can be checked externally via reproduction of the reported metrics, with no step reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nocaps: Novel object captioning at scale
Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. InProceedings of the IEEE/CVF international conference on computer vision, pages 8948–8957, 2019
2019
-
[2]
wikiart_recaption
AterMors. wikiart_recaption. https://huggingface.co/datasets/AterMors/wikiart_ recaption, 2024. Hugging Face dataset
2024
-
[3]
Fs-coco: Towards understanding of freehand sketches of common objects in context
Pinaki Nath Chowdhury, Aneeshan Sain, Ayan Kumar Bhunia, Tao Xiang, Yulia Gryaditskaya, and Yi-Zhe Song. Fs-coco: Towards understanding of freehand sketches of common objects in context. InEuropean conference on computer vision, pages 253–270. Springer, 2022
2022
-
[4]
Continual vision-language retrieval via dynamic knowledge rectification
Zhenyu Cui, Yuxin Peng, Xun Wang, Manyu Zhu, and Jiahuan Zhou. Continual vision-language retrieval via dynamic knowledge rectification. InProceedings of the AAAI Conference on Artificial Intelligence, pages 11704–11712, 2024
2024
-
[5]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA, pages 248–255. IEEE Computer Society, 2009
2009
-
[6]
Tic-clip: Continual training of clip models
Saurabh Garg, Mehrdad Farajtabar, Hadi Pouransari, Raviteja Vemulapalli, Sachin Mehta, Oncel Tuzel, Vaishaal Shankar, and Fartash Faghri. Tic-clip: Continual training of clip models. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[7]
kream-product-blip-captions
hahminlew. kream-product-blip-captions. https://huggingface.co/datasets/ hahminlew/kream-product-blip-captions, 2023. Hugging Face dataset
2023
-
[8]
Lora: Low-rank adaptation of large language models
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022
2022
-
[9]
Class-incremental learning with clip: Adaptive representation adjustment and parameter fusion
Linlan Huang, Xusheng Cao, Haori Lu, and Xialei Liu. Class-incremental learning with clip: Adaptive representation adjustment and parameter fusion. InEuropean Conference on Computer Vision, pages 214–231. Springer, 2024
2024
-
[10]
Editing models with task arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Ha- jishirzi, and Ali Farhadi. Editing models with task arithmetic. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[11]
CLAP4CLIP: Continual learning with probabilistic finetuning for vision-language models
Saurav Jha, Dong Gong, and Lina Yao. CLAP4CLIP: Continual learning with probabilistic finetuning for vision-language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[12]
Flintstonessv_plus_plus
Janak Kapuriya. Flintstonessv_plus_plus. https://huggingface.co/datasets/Janak12/ FlintstonesSV_Plus_Plus, 2025. Hugging Face dataset
2025
-
[13]
Flintstonessv++ : Improving story narration using visual scene graph
Janak Kapuriya and Paul Buitelaar. Flintstonessv++ : Improving story narration using visual scene graph. InText2Story@ECIR, 2025. URL https://api.semanticscholar.org/ CorpusID:279053465
2025
-
[14]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13): 35...
2017
-
[15]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical Report 0, University of Toronto, Toronto, Ontario, 2009. URL https://www.cs. toronto.edu/~kriz/learning-features-2009-TR.pdf. 10
2009
-
[16]
Coleclip: Open-domain continual learning via joint task prompt and vocabulary learning.IEEE Transactions on Neural Networks and Learning Systems, 36(8):15137–15151, 2025
Yukun Li, Guansong Pang, Wei Suo, Chenchen Jing, Yuling Xi, Lingqiao Liu, Hao Chen, Guoqiang Liang, and Peng Wang. Coleclip: Open-domain continual learning via joint task prompt and vocabulary learning.IEEE Transactions on Neural Networks and Learning Systems, 36(8):15137–15151, 2025
2025
-
[17]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[18]
C-clip: Multimodal continual learning for vision-language model
Wenzhuo Liu, Fei Zhu, Longhui Wei, and Qi Tian. C-clip: Multimodal continual learning for vision-language model. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, pages 46461–46477, 2025
2025
-
[19]
Continual learning on CLIP via incremental prompt tuning with intrinsic textual anchors.Transactions on Machine Learning Research, 2025
Haodong Lu, Xinyu Zhang, Kristen Moore, Jason Xue, Lina Yao, Anton van den Hengel, and Dong Gong. Continual learning on CLIP via incremental prompt tuning with intrinsic textual anchors.Transactions on Machine Learning Research, 2025. ISSN 2835-8856
2025
-
[20]
MAGMAX: leveraging model merging for seamless continual learning
Daniel Marczak, Bartlomiej Twardowski, Tomasz Trzcinski, and Sebastian Cygert. MAGMAX: leveraging model merging for seamless continual learning. In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedin...
2024
-
[21]
No task left behind: Isotropic model merging with common and task-specific subspaces
Daniel Marczak, Simone Magistri, Sebastian Cygert, Bartłomiej Twardowski, Andrew D Bagdanov, and Joost van de Weijer. No task left behind: Isotropic model merging with common and task-specific subspaces. InForty-second International Conference on Machine Learning, 2025
2025
-
[22]
On class orderings for incremental learning.CoRR, abs/2007.02145, 2020
Marc Masana, Bartlomiej Twardowski, and Joost van de Weijer. On class orderings for incremental learning.CoRR, abs/2007.02145, 2020
arXiv 2007
-
[23]
Semantic residual prompts for continual learning
Martin Menabue, Emanuele Frascaroli, Matteo Boschini, Enver Sangineto, Lorenzo Bonicelli, Angelo Porrello, and Simone Calderara. Semantic residual prompts for continual learning. In European Conference on Computer Vision, 2024
2024
-
[24]
Continual vision-language representation learning with off-diagonal information
Zixuan Ni, Longhui Wei, Siliang Tang, Yueting Zhuang, and Qi Tian. Continual vision-language representation learning with off-diagonal information. InProceedings of the 40th International Conference on Machine Learning, ICML’23, 2023
2023
-
[25]
Bagdanov, Simone Calderara, and Joost van de Weijer
Aniello Panariello, Daniel Marczak, Simone Magistri, Angelo Porrello, Bartłomiej Twardowski, Andrew D. Bagdanov, Simone Calderara, and Joost van de Weijer. Accurate and efficient low-rank model merging in core space. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[26]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012
2012
-
[27]
doi: 10.18653/v1/2020.emnlp-demos
Jonas Pfeiffer, Andreas Rücklé, Clifton Poth, Aishwarya Kamath, Ivan Vuli´c, Sebastian Ruder, Kyunghyun Cho, and Iryna Gurevych. AdapterHub: A framework for adapting transformers. In Qun Liu and David Schlangen, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 46–54, Online, Octob...
-
[28]
URLhttps://aclanthology.org/2020.emnlp-demos.7/
2020
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceed- ings of the 38th International Conference on Machine Learning, volume 139 ofProceedings...
2021
-
[30]
Schmidt, Sven Koitka, Obioma Pelka, Asma Ben Abacha, Alba G
Johannes Rückert, Louise Bloch, Raphael Brüngel, Ahmad Idrissi-Yaghir, Henning Schäfer, Cynthia S. Schmidt, Sven Koitka, Obioma Pelka, Asma Ben Abacha, Alba G. Seco de Herrera, Henning Müller, Peter A. Horn, Felix Nensa, and Christoph M. Friedrich. Rocov2: Radiology 11 objects in context version 2, an updated multimodal image dataset.Scientific Data, 11(1...
2024
-
[31]
Construct-vl: Data-free continual structured vl concepts learning
James Seale Smith, Paola Cascante-Bonilla, Assaf Arbelle, Donghyun Kim, Rameswar Panda, David Cox, Diyi Yang, Zsolt Kira, Rogerio Feris, and Leonid Karlinsky. Construct-vl: Data-free continual structured vl concepts learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14994–15004, 2023
2023
-
[32]
A practitioner’s guide to real-world continual multimodal pretraining
Vishaal Udandarao, Karsten Roth, Sebastian Dziadzio, Ameya Prabhu, Mehdi Cherti, Oriol Vinyals, Olivier Hénaff, Samuel Albanie, Zeynep Akata, and Matthias Bethge. A practitioner’s guide to real-world continual multimodal pretraining. In A. Globerson, L. Mackey, D. Bel- grave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Informat...
2024
-
[33]
Continual learning in cross-modal retrieval
Kai Wang, Luis Herranz, and Joost van de Weijer. Continual learning in cross-modal retrieval . In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE Computer Society, 2021
2021
-
[34]
Dy, and Tomas Pfister
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer G. Dy, and Tomas Pfister. Learning to prompt for continual learning. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 139–149, 2021
2022
-
[35]
Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
2023
-
[36]
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2, 2014
2014
-
[37]
Boosting continual learning of vision-language models via mixture-of-experts adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23219–23230, June 2024
2024
-
[38]
lexica-stable-diffusion-v1-5
yuwan0. lexica-stable-diffusion-v1-5. https://huggingface.co/datasets/yuwan0/ lexica-stable-diffusion-v1-5, 2024. Hugging Face dataset
2024
-
[39]
Preventing zero-shot transfer degradation in continual learning of vision-language models
Zangwei Zheng, Mingyuan Ma, Kai Wang, Ziheng Qin, Xiangyu Yue, and Yang You. Preventing zero-shot transfer degradation in continual learning of vision-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 19125–19136, October 2023
2023
-
[40]
Limitations
zoheb. sketch-scene. https://huggingface.co/datasets/zoheb/sketch-scene, 2025. Hugging Face dataset. 12 Appendix A Implementation details Global training protocol.Unless otherwise stated, all methods are trained with the same optimiza- tion, data, and evaluation protocol. We use CLIP ViT-B/16 initialized from the pretrained checkpoint, train for 20 epochs...
2025
-
[41]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects 27 Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.