Learning to Adapt: Self-Improving Web Agent via Cognitive-Aware Exploration
Pith reviewed 2026-06-28 22:16 UTC · model grok-4.3
The pith
SCALE lets web agents use three adversarial roles to discover their own limitations and expand capabilities through exploration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
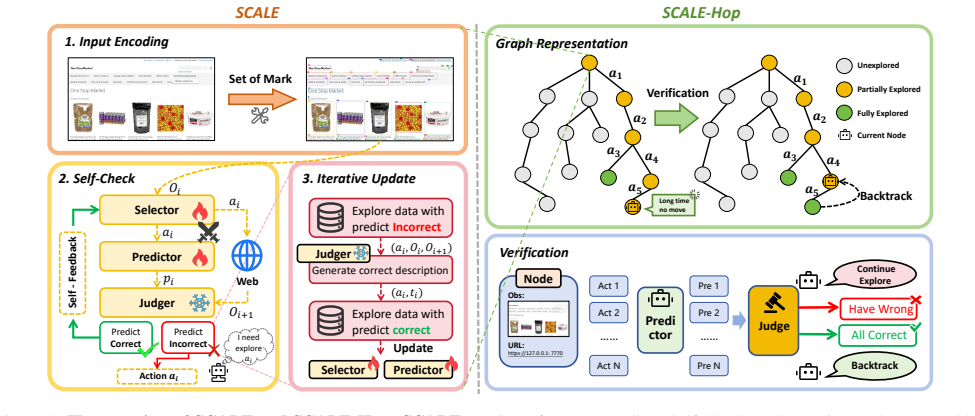
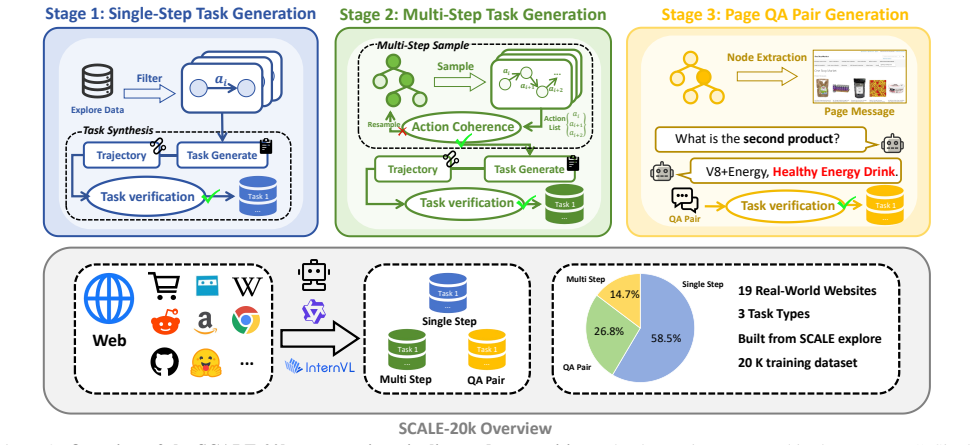
By deploying Selector, Predictor, and Judger in an adversarial loop, agents can autonomously locate their limitations and enlarge their cognitive boundaries via direct environmental exploration; SCALE-Hop further aids global planning, and the resulting traces produce the SCALE-20k dataset that improves MLLM results across real websites without handcrafted pipelines or expert trajectories.
What carries the argument
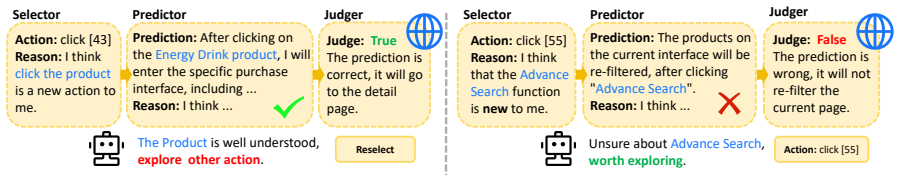
The three adversarial roles (Selector, Predictor, Judger) that interact to surface the agent's limitations, together with the SCALE-Hop graph exploration strategy.
If this is right
- Agents adapt to complex dynamic web environments without external expert demonstrations.
- Multiple MLLMs achieve higher task success and better transfer across different websites.
- Exploration traces become a source of training data that replaces handcrafted pipelines.
- The approach scales to building more autonomous web agents from real-site interactions.
Where Pith is reading between the lines
- The same role-based self-critique loop could be tested in non-web domains such as mobile app control or code execution agents.
- Measuring how well SCALE-Hop avoids traps on sites with deeper navigation structures would test its planning benefit directly.
- Releasing SCALE-20k allows other groups to benchmark new exploration methods against the same real-world task distribution.
Load-bearing premise
The three adversarial roles can autonomously discover the agent's limitations and expand its cognitive boundaries through environmental exploration without requiring handcrafted pipelines or expert trajectories.
What would settle it
An experiment that applies the same web tasks to MLLMs with and without the three adversarial roles and finds no measurable gain in success rate or generalization.
Figures

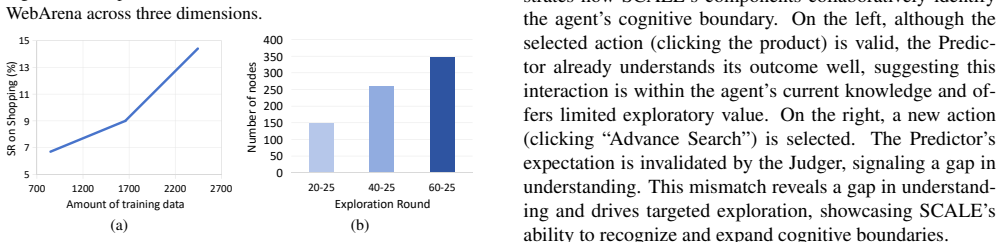
read the original abstract
Recent advances in Multimodal Large Language Models (MLLMs) have led to promising progress in web agents. However, existing web agents often rely on handcrafted execution pipelines or expensive expert trajectories, limiting their adaptability to complex, dynamic environments. To address these challenges, we propose SCALE (Self-Cognitive-Aware Learning and Exploration), which leverages three adversarial roles, Selector, Predictor, and Judger to autonomously discover the agent's limitations and expand its cognitive boundaries through environmental exploration. Moreover, we propose SCALE-Hop, a graph exploration strategy that facilitates global planning and helps agents avoid local exploration traps. To further support learning, we construct SCALE-20k, a large-scale dataset collected from 19 real-world websites, containing diverse task types and structured demonstrations generated from SCALE's exploration traces. Experimental results show that our approach significantly improves the performance and generalization of multiple MLLMs in various web environments. Our framework offers a scalable and generalizable solution for building truly autonomous and adaptive web agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SCALE (Self-Cognitive-Aware Learning and Exploration), a framework that uses three adversarial roles—Selector, Predictor, and Judger—together with the SCALE-Hop graph exploration strategy to enable web agents to autonomously discover their own limitations and generate exploration traces. These traces are used to construct the SCALE-20k dataset from 19 real-world websites; the authors claim that fine-tuning multiple MLLMs on this data yields significant gains in performance and generalization across web environments without relying on handcrafted pipelines or expert trajectories.
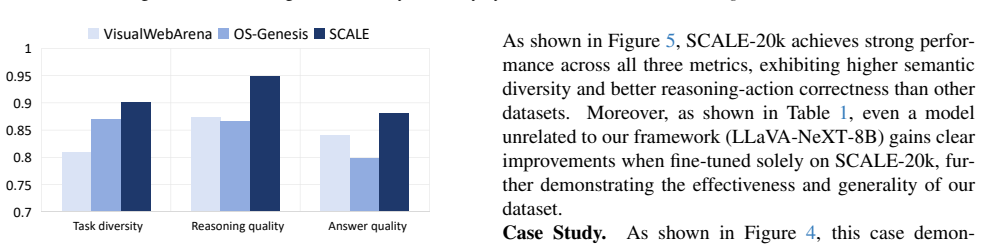
Significance. If the reported gains are reproducible and the autonomy claim holds, the work would provide a concrete route to scalable, self-generated training data for web agents and reduce dependence on expert demonstrations. The SCALE-Hop mechanism and the three-role adversarial setup could be of broader interest for exploration in partially observable environments.
major comments (2)
- [Abstract, §3] Abstract and §3 (Role Definitions): The central claim that the Selector/Predictor/Judger roles 'autonomously discover the agent's limitations ... without requiring handcrafted pipelines' is load-bearing for the self-improving loop and the purity of SCALE-20k. The manuscript must supply the exact system prompts, interaction protocol, termination criteria, and initial seeding procedure so that readers can verify whether domain-specific heuristics are encoded in the role definitions.
- [§4, Table X] §4 (Experiments) and Table X: The abstract asserts 'significantly improves the performance and generalization of multiple MLLMs' yet the provided abstract supplies no numerical results, baselines, error bars, or ablation statistics. The experimental section must report concrete metrics (success rate, generalization gap, etc.) with statistical controls; without them the performance claim cannot be evaluated.
minor comments (2)
- [§3.2] Notation for SCALE-Hop graph construction is introduced without a formal definition or pseudocode; a small algorithm box would improve clarity.
- [§4.1] The manuscript should state the exact number of websites, task categories, and total trajectories in SCALE-20k (currently only '19 real-world websites' and '20k' are given).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and enhancements.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Role Definitions): The central claim that the Selector/Predictor/Judger roles 'autonomously discover the agent's limitations ... without requiring handcrafted pipelines' is load-bearing for the self-improving loop and the purity of SCALE-20k. The manuscript must supply the exact system prompts, interaction protocol, termination criteria, and initial seeding procedure so that readers can verify whether domain-specific heuristics are encoded in the role definitions.
Authors: We agree that full transparency on the role definitions is necessary to support the autonomy claim. In the revised manuscript we will add the complete system prompts for Selector, Predictor, and Judger as a new appendix. We will also expand Section 3 to include the precise interaction protocol, termination criteria, and initial seeding procedure, allowing readers to directly inspect whether any domain-specific heuristics are present. revision: yes
-
Referee: [§4, Table X] §4 (Experiments) and Table X: The abstract asserts 'significantly improves the performance and generalization of multiple MLLMs' yet the provided abstract supplies no numerical results, baselines, error bars, or ablation statistics. The experimental section must report concrete metrics (success rate, generalization gap, etc.) with statistical controls; without them the performance claim cannot be evaluated.
Authors: We acknowledge that the abstract currently states the performance improvement only qualitatively. In the revision we will update the abstract to report key quantitative results (e.g., success-rate gains and generalization gaps). We will also augment Section 4 and Table X with explicit baselines, error bars, ablation statistics, and statistical controls so that the performance claims can be fully evaluated. revision: yes
Circularity Check
No significant circularity; framework generates new traces rather than re-deriving inputs
full rationale
The paper proposes SCALE using three roles (Selector, Predictor, Judger) and SCALE-Hop to generate exploration traces, from which SCALE-20k is constructed, followed by experimental validation on MLLMs. No equations, fitted parameters, or self-referential derivations appear. The central claim rests on the generated dataset and empirical gains, which are independent of the input assumptions once the roles execute. No load-bearing self-citation chains or ansatz smuggling are quoted. This matches the default expectation of a non-circular empirical framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 6, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
What limits virtual agent application? om- nibench: A scalable multi-dimensional benchmark for essen- tial virtual agent capabilities
Wendong Bu, Yang Wu, Qifan Yu, Minghe Gao, Bingchen Miao, Zhenkui Zhang, Kaihang Pan, Yunfei Li, Mengze Li, Wei Ji, et al. What limits virtual agent application? om- nibench: A scalable multi-dimensional benchmark for essen- tial virtual agent capabilities. InInternational Conference on Machine Learning, pages 5725–5748. PMLR, 2025. 1
2025
-
[3]
Edge: Enhanced grounded gui un- derstanding with enriched multi-granularity synthetic data
Xuetian Chen, Hangcheng Li, Jiaqing Liang, Sihang Jiang, and Deqing Yang. Edge: Enhanced grounded gui un- derstanding with enriched multi-granularity synthetic data. arXiv preprint arXiv:2410.19461, 2024. 1
-
[4]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 2, 6, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Rico: A mobile app dataset for building data- driven design applications
Biplab Deka, Zifeng Huang, Chad Franzen, Joshua Hib- schman, Daniel Afergan, Yang Li, Jeffrey Nichols, and Ran- jitha Kumar. Rico: A mobile app dataset for building data- driven design applications. InProceedings of the 30th annual ACM symposium on user interface software and technology, pages 845–854, 2017. 3
2017
-
[6]
Mind2web: Towards a generalist agent for the web, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web, 2023. 3
2023
-
[7]
Yu Gu, Kai Zhang, Yuting Ning, Boyuan Zheng, Boyu Gou, Tianci Xue, Cheng Chang, Sanjari Srivastava, Yanan Xie, Peng Qi, et al. Is your llm secretly a world model of the in- ternet? model-based planning for web agents.arXiv preprint arXiv:2411.06559, 2024. 1, 3
-
[8]
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. We- bvoyager: Building an end-to-end web agent with large mul- timodal models.arXiv preprint arXiv:2401.13919, 2024. 1, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Openwebvoyager: Building multimodal web agents via it- erative real-world exploration, feedback and optimization,
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Hong- ming Zhang, Tianqing Fang, Zhenzhong Lan, and Dong Yu. Openwebvoyager: Building multimodal web agents via it- erative real-world exploration, feedback and optimization,
-
[10]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14281– 14290, 2024. 1
2024
-
[11]
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwe- barena: Evaluating multimodal agents on realistic visual web tasks.arXiv preprint arXiv:2401.13649, 2024. 1, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Tree search for language model agents.arXiv preprint arXiv:2407.01476, 2024
Jing Yu Koh, Stephen McAleer, Daniel Fried, and Ruslan Salakhutdinov. Tree search for language model agents.arXiv preprint arXiv:2407.01476, 2024. 1, 2, 10
-
[13]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024. 6, 10, 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19498– 19508, 2025. 1
2025
-
[15]
Quanfeng Lu, Wenqi Shao, Zitao Liu, Fanqing Meng, Box- uan Li, Botong Chen, Siyuan Huang, Kaipeng Zhang, Yu Qiao, and Ping Luo. Gui odyssey: A comprehensive dataset for cross-app gui navigation on mobile devices.arXiv preprint arXiv:2406.08451, 2024. 1
-
[16]
Boosting virtual agent learning and reasoning: A step-wise, multi-dimensional, and generalist reward model with benchmark
Bingchen Miao, Yang Wu, Minghe Gao, Qifan Yu, Wen- dong Bu, Wenqiao Zhang, Yunfei Li, Siliang Tang, Tat-Seng Chua, and Juncheng Li. Boosting virtual agent learning and reasoning: A step-wise, multi-dimensional, and generalist reward model with benchmark. InForty-second Interna- tional Conference on Machine Learning, 2025. 1
2025
-
[17]
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Mot- wani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent q: Advanced reasoning and learning for autonomous ai agents.arXiv preprint arXiv:2408.07199, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023. 3
2023
-
[19]
Sentence-BERT: Sen- tence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sen- tence embeddings using Siamese BERT-networks. InPro- ceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 3982–3992, Hong Kong, China, 2019. As- sociation for Computational Lin...
2019
-
[20]
Grounded Reinforcement Learning for Visual Reasoning
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J Tarr, Aviral Kumar, and Katerina Fragki- adaki. Grounded reinforcement learning for visual reason- ing.arXiv preprint arXiv:2505.23678, 2025. 6, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Learn-by-interact: A data-centric framework for self-adaptive agents in realistic environments
Hongjin Su, Ruoxi Sun, Jinsung Yoon, Pengcheng Yin, Tao Yu, and Sercan ¨O Arık. Learn-by-interact: A data-centric framework for self-adaptive agents in realistic environments. arXiv preprint arXiv:2501.10893, 2025. 3
-
[22]
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Li- heng Chen, Zhoumianze Liu, et al. Os-genesis: Automating gui agent trajectory construction via reverse task synthesis. arXiv preprint arXiv:2412.19723, 2024. 1, 2, 3, 6, 10
-
[23]
Gaurav Verma, Rachneet Kaur, Nishan Srishankar, Zhen Zeng, Tucker Balch, and Manuela Veloso. Adapta- gent: Adapting multimodal web agents with few-shot learning from human demonstrations.arXiv preprint arXiv:2411.13451, 2024. 1
-
[24]
Omniparser: A unified framework for text spotting key information extraction and table recognition
Jianqiang Wan, Sibo Song, Wenwen Yu, Yuliang Liu, Wen- qing Cheng, Fei Huang, Xiang Bai, Cong Yao, and Zhibo Yang. Omniparser: A unified framework for text spotting key information extraction and table recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15641–15653, 2024. 11
2024
-
[25]
A survey on large language model based au- tonomous agents.Frontiers of Computer Science, 18(6): 186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based au- tonomous agents.Frontiers of Computer Science, 18(6): 186345, 2024. 1
2024
-
[26]
Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890,
Shuai Wang, Weiwen Liu, Jingxuan Chen, Yuqi Zhou, Weinan Gan, Xingshan Zeng, Yuhan Che, Shuai Yu, Xinlong Hao, Kun Shao, et al. Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890,
-
[27]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Dingwen Yang, Chenyang Liao, Xin Guo, Wei He, Songyang Gao, Lu Chen, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, and Yu-Gang Jiang. Agentgym: Evolv- ing large language model-based agents across diverse envi- ronments.arXiv preprint arXiv:240...
-
[29]
Osworld: Benchmark- ing multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmark- ing multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024. 1, 2, 3
2024
-
[30]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tian- bao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. Aguvis: Unified pure vision agents for autonomous gui interaction.arXiv preprint arXiv:2412.04454, 2024. 1, 2, 3, 6, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v.arXiv preprint arXiv:2310.11441, 2023. 4, 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
React: Synergizing rea- soning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing rea- soning and acting in language models. InInternational Con- ference on Learning Representations (ICLR), 2023. 1, 2
2023
-
[33]
GPT-4V(ision) is a Generalist Web Agent, if Grounded
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v (ision) is a generalist web agent, if grounded. arXiv preprint arXiv:2401.01614, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Agentstudio: A toolkit for building general virtual agents.arXiv preprint arXiv:2403.17918, 2024
Longtao Zheng, Zhiyuan Huang, Zhenghai Xue, Xinrun Wang, Bo An, and Shuicheng Yan. Agentstudio: A toolkit for building general virtual agents.arXiv preprint arXiv:2403.17918, 2024. 1
-
[35]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web en- vironment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 1 Learning to Adapt: Self-Improving Web Agent via Cognitive-Aware Exploration Supplementary Material Overview In...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
The action command should start with action: followed by a concise command.(for example,action: click [<insert item number in picture>], type [<insert item number in picture>][<typing text>],action: hover [<insert item number in picture>],action: scroll [<down or up>])
-
[37]
The action command should be a simple com- mand without any extra explanation
-
[38]
Immediately following the action command, provide a reason starting withreason:that explains why you chose this action and why its effect is unknown, requiring exploration
-
[39]
When you usetypeorfillaction you must provide the specific element in the im- age and the fill content
The only possible actions you can generate are:scroll,click,hover,type, or fill. When you usetypeorfillaction you must provide the specific element in the im- age and the fill content. For example:type [1][chips]
-
[40]
Click [ob- ject]
Your output must include both the action and reason parts, separated by a newline, exactly in the following format: action: <insert action> reason: <insert why you choose this action, and why this action will lead to unknown interactions> In any given instance, you should generate only one action and its corresponding reason. If it hasn’t been generated b...
-
[41]
N/A” in the bracket. Output Format: First, generate the reasoning process for the action. Then, generate the action in the correct format. Start with a
that matches the set range. In summary, the next action I will perform is```click [16]``` STEP 4: User Input: Image Observation: Task Description: You are an intelligent agent completing web-based tasks. Based on the user’s objective (i.e. instruc- tion), current interface information (i.e. screenshot and its corresponding accessibility tree), and action ...
-
[44]
reason”: “<brief justification about reasoning quality>
Screenshots for context. Your Objective: - Evaluate ONLY the REASONING (not the ac- tion’s optimality). Prioritize ACCURACY over length. - If the task is simple, concise reasoning is pre- ferred; if complex, more elaboration is accept- able. - The reasoning MUST be tightly aligned with the final action/answer: no off-topic chains, and no mismatch between ...
-
[45]
OBJECTIVE — the task goal
-
[46]
Agent’s reasoning and proposed next action (as- sistant content)
-
[47]
Your Objective: - Evaluate whether the proposed NEXT ACTION (or final answer) is the BEST choice for the current environment/state
Screenshots for context. Your Objective: - Evaluate whether the proposed NEXT ACTION (or final answer) is the BEST choice for the current environment/state. - STRICTLY check the following RULES are obeyed:
-
[48]
The action must be V ALID given the current observation
-
[49]
Only ONE action at a time
-
[50]
Follow examples to reason step by step and then issue the next action
-
[51]
In summary, the next action I will perform is
Correct output format: must start with the phrase: “In summary, the next action I will perform is” followed by the action inside triple backticks. - The action MUST be one of the ALLOWED AC- TIONS (whitelist): Page Operation Actions: - click [id] - type [id] [content] (optional enter suppres- sion: type [id] [content] [0]) - hover [id] - press [key comb] ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.