Skill Availability and Presentation Granularity in Large-Language-Model Agents: A Controlled SkillsBench Study
Pith reviewed 2026-06-28 22:19 UTC · model grok-4.3
The pith
Giving LLM agents skill documents raises task success by 18-36 percentage points while varying how the skills are written changes outcomes little.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
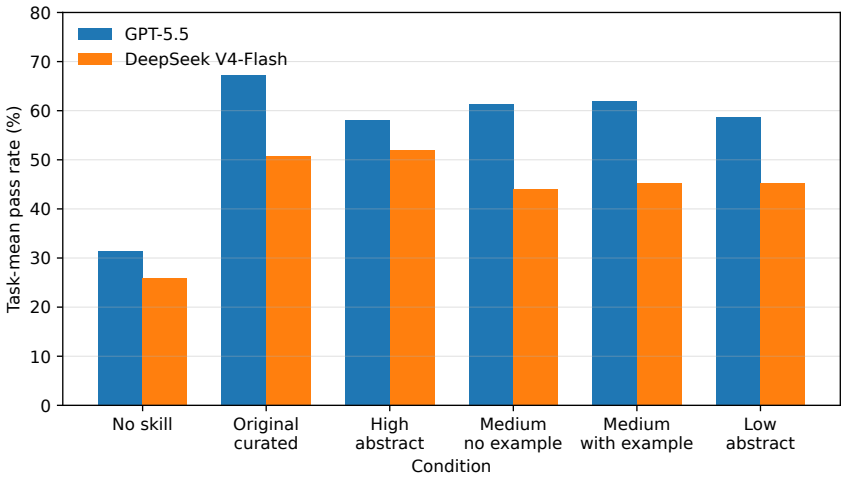
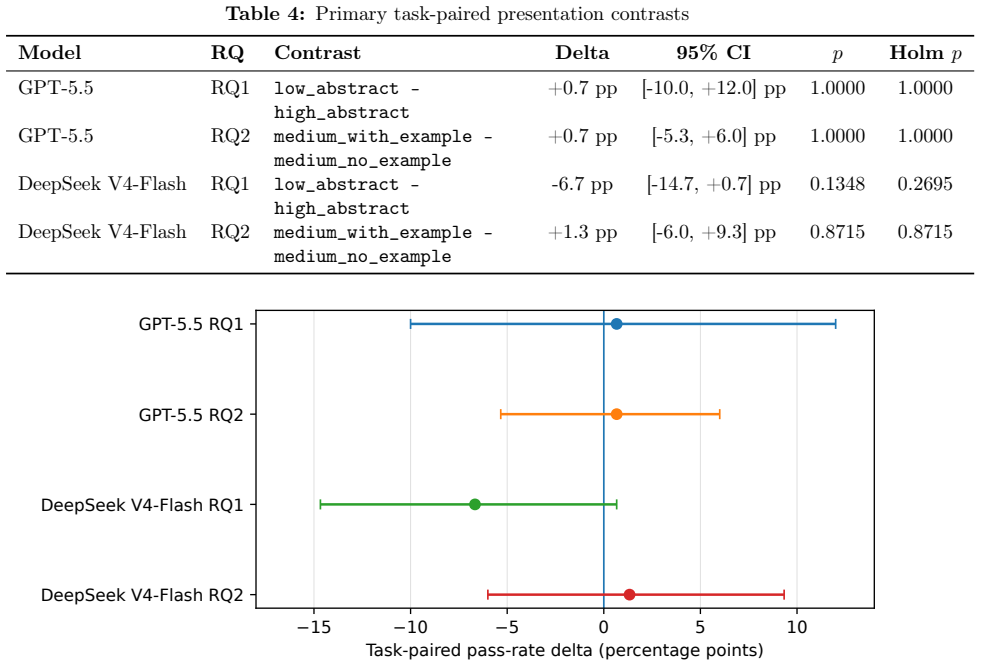
In the 30-task controlled subset, skill conditions raise mean pass rate by 26.7-36.0 points for GPT-5.5 and 18.0-26.0 points for DeepSeek V4-Flash relative to the no-skill baseline. Low-abstraction versus high-abstraction guidance differs by +0.7 points for one model and -6.7 points for the other, with both intervals crossing zero. Adding one worked example changes performance by +0.7 and +1.3 points. The same pattern holds under mean-reward checks.
What carries the argument
A pinned 30-task domain-balanced SkillsBench subset with six skill conditions (no skill plus five presentation variants) evaluated on two reasoning-enabled models over five trials per task-condition-model cell.
If this is right
- Skill availability is the dominant lever for raising agent success on these tasks.
- Low- versus high-abstraction guidance does not reliably alter outcomes.
- Adding a single worked example produces negligible gains over the no-example version.
- The pattern is preserved when performance is measured by mean reward instead of pass rate.
Where Pith is reading between the lines
- Agent builders could allocate effort first to creating usable skill documents and only later to tuning their wording.
- The finding may extend to other agent benchmarks that supply procedural knowledge at inference time.
- Larger studies could check whether granularity effects grow when tasks require more precise procedural steps.
Load-bearing premise
The chosen 30-task subset and the six skill documents were written and applied in ways that do not introduce major hidden differences between conditions.
What would settle it
Re-running the same design on a larger or differently sampled task set and finding that granularity changes produce large, consistent pass-rate differences would falsify the claim that presentation effects are small and uncertain.
Figures
read the original abstract
Skill documents provide procedural knowledge to large-language-model agents at inference time. This article studies whether the presentation granularity of controlled skill knowledge changes downstream task success. The experiment uses a pinned SkillsBench version, a 30-task domain-balanced subset validated by official oracle runs, two reasoning-enabled model configurations, six skill conditions, and five trials per task-condition-model cell. Skill availability is the clearest empirical signal. Relative to no skill, skill conditions increase task-mean pass rate by 26.7 to 36.0 percentage points for GPT-5.5 and by 18.0 to 26.0 percentage points for DeepSeek V4-Flash. The final data contain 1,800 rows, with 900 rows for each model. The task is the inference unit. Five trials are aggregated within each task-condition-model cell before paired contrasts are estimated over 30 tasks. The primary presentation contrasts are smaller and uncertain. Low-abstraction guidance differs from high-abstraction guidance by +0.7 percentage points for GPT-5.5 and -6.7 percentage points for DeepSeek V4-Flash, with both 95% bootstrap confidence intervals crossing zero. Adding one worked example to medium-abstraction guidance differs from the no-example variant by +0.7 and +1.3 percentage points. Mean-reward robustness checks preserve the same substantive conclusion. In this controlled subset, skill availability is associated with higher success than no skill, while the tested presentation-granularity changes yield small, uncertain, and model-dependent effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in a controlled experiment on a 30-task domain-balanced subset of SkillsBench (oracle-validated), skill availability substantially boosts LLM agent pass rates (26.7–36.0 pp for GPT-5.5; 18.0–26.0 pp for DeepSeek V4-Flash) relative to no-skill baselines, while presentation-granularity manipulations (low- vs. high-abstraction guidance; medium-abstraction with vs. without one worked example) yield small effects (+0.7 to -6.7 pp) whose 95% bootstrap CIs cross zero. The design uses two reasoning-enabled models, six skill conditions, five trials per task-condition-model cell, task-level aggregation before paired contrasts, 1,800 total rows, and mean-reward robustness checks.
Significance. If the results hold, the work supplies clear empirical evidence that skill-document availability dominates over granularity choices for these models and tasks. Strengths include the pinned benchmark version, oracle validation, bootstrap CIs, task-level (not trial-level) aggregation, and explicit robustness checks; these features make the separation between large availability effects and uncertain granularity effects directly testable and reproducible within the reported scope.
major comments (1)
- [Methods] Methods / Experimental Design: the six skill documents and their concrete realizations under each granularity condition are not provided (nor are excerpts or links). Because the central contrast is between availability and granularity, the absence of the actual documents leaves open the possibility of unmeasured authoring confounds in how the low-/high-abstraction and example variants were written; this directly affects interpretability of the reported small, uncertain granularity deltas.
minor comments (2)
- The abstract and results sections could explicitly state the exact number of tasks per domain in the 30-task subset and the precise definition of the 'official oracle runs' used for validation.
- Table or figure captions should clarify whether the reported percentage-point differences are raw means or model-adjusted; the bootstrap procedure (number of resamples, stratification) should be stated once in the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The recommendation for minor revision is noted, and we address the single major comment below. We agree that the point raises a valid concern for interpretability.
read point-by-point responses
-
Referee: [Methods] Methods / Experimental Design: the six skill documents and their concrete realizations under each granularity condition are not provided (nor are excerpts or links). Because the central contrast is between availability and granularity, the absence of the actual documents leaves open the possibility of unmeasured authoring confounds in how the low-/high-abstraction and example variants were written; this directly affects interpretability of the reported small, uncertain granularity deltas.
Authors: We agree that the absence of the skill documents limits the ability to assess potential authoring confounds and reduces interpretability of the granularity contrasts. In the revised version we will add the full text of all six skill documents (and their low-/high-abstraction and example variants) to an appendix. We will also include a permanent link to a public repository containing the complete documents, task prompts, and experimental materials. revision: yes
Circularity Check
No significant circularity
full rationale
The paper reports direct experimental measurements from a controlled 30-task subset of SkillsBench, with five trials per cell, bootstrap CIs, and mean-reward checks. All claims concern observed pass-rate differences between skill-availability and granularity conditions; no derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing steps. The design is self-contained against the stated oracle-validated tasks and statistical contrasts.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Bootstrap confidence intervals supply valid uncertainty estimates for task-mean pass rates aggregated over 30 tasks
- domain assumption The pinned SkillsBench 30-task subset and oracle validation ensure domain balance and task validity for measuring presentation effects
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “ReAct: Synergizing Reasoning and Acting in Language Models,” arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language Models Can Teach Themselves to Use Tools,” arXiv:2302.04761, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Y. Shen, K. Song, X. Tan, D. Li, W. Lu, and Y. Zhuang, “HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face,” arXiv:2303.17580, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anand- kumar, “Voyager: An Open-Ended Embodied Agent with Large Language Models,” arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
X. Li, W. Chen, Y. Liu, S. Zheng, X. Chen, Y. He, Y. Li, B. You, H. Shen, J. Sun, et al., “SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks,” arXiv:2602.12670, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Language Models are Few-Shot Learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., “Language Models are Few-Shot Learners,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 1877–1901
2020
-
[7]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 24824–24837
2022
-
[8]
Calibrate Before Use: Improving Few-Shot Performance of Language Models,
T. Z. Zhao, E. Wallace, S. Feng, D. Klein, and S. Singh, “Calibrate Before Use: Improving Few-Shot Performance of Language Models,” inProc. 38th Int. Conf. Mach. Learn., 2021, pp. 12697–12706
2021
-
[9]
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity,
Y. Lu, M. Bartolo, A. Moore, S. Riedel, and P. Stenetorp, “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity,” inProc. 60th Annu. Meeting Assoc. Comput. Linguistics, 2022, pp. 8086–8098
2022
-
[10]
Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design,
M. Sclar, Y. Choi, Y. Tsvetkov, and A. Suhr, “Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design,” inProc. Int. Conf. Learn. Representations, 2024
2024
-
[11]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents,
S. Yao, H. Chen, J. Yang, and K. Narasimhan, “WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 20744–20757
2022
-
[12]
WebArena: A Realistic Web Environment for Building Autonomous Agents,
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y. Bisk, D. Fried, et al., “WebArena: A Realistic Web Environment for Building Autonomous Agents,” inProc. Int. Conf. Learn. Representations, 2024
2024
-
[13]
Mind2Web: Towards a Generalist Agent for the Web,
X. Deng, Y. Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y. Su, “Mind2Web: Towards a Generalist Agent for the Web,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[14]
AgentBench: Evaluating LLMs as Agents
X. Liu, H. Yu, H. Zhang, Y. Xu, X. Lei, H. Lai, Y. Gu, H. Ding, K. Men, K. Yang, et al., “AgentBench: Evaluating LLMs as Agents,” arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
SWE- bench: Can Language Models Resolve Real-World GitHub Issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE- bench: Can Language Models Resolve Real-World GitHub Issues?” inProc. Int. Conf. Learn. Representations, 2024
2024
-
[16]
GAIA: a benchmark for General AI Assistants
G. Mialon, C. Fourrier, C. Swift, T. Wolf, Y. LeCun, and T. Scialom, “GAIA: a Benchmark for General AI Assistants,” arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments,
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, et al., “OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments,” inAdvances in Neural Information Processing Systems, vol. 37, 2024
2024
-
[18]
Equipping Agents for the Real World with Agent Skills,
Anthropic, “Equipping Agents for the Real World with Agent Skills,” Engineering Blog, Oct. 16, 2025, updated Dec. 18, 2025. [Online]. Available:https://www.anthropic.com/ engineering/equipping-agents-for-the-real-world-with-agent-skills. Accessed: May 26, 2026. 12
2025
-
[19]
Agent Skills,
Anthropic, “Agent Skills,” Claude API documentation, 2026. [Online]. Available:https: //platform.claude.com/docs/en/agents-and-tools/agent-skills/overview
2026
-
[20]
Thinking Mode,
DeepSeek, “Thinking Mode,” API documentation, 2026. [Online]. Available:https:// api-docs.deepseek.com/guides/thinking_mode
2026
-
[21]
Bootstrap Methods: Another Look at the Jackknife,
B. Efron, “Bootstrap Methods: Another Look at the Jackknife,”The Annals of Statistics, vol. 7, no. 1, pp. 1–26, 1979
1979
-
[22]
P. I. Good,Permutation, Parametric, and Bootstrap Tests of Hypotheses, 3rd ed. New York, NY, USA: Springer, 2005
2005
-
[23]
A Simple Sequentially Rejective Multiple Test Procedure,
S. Holm, “A Simple Sequentially Rejective Multiple Test Procedure,”Scandinavian Journal of Statistics, vol. 6, pp. 65–70, 1979. Author Biographies Xiaonan Xu.Xiaonan Xu received a graduate degree in Computer Information Technology from Northern Arizona University, Flagstaff, AZ, USA. His research interests include large lan- guage models and agent evaluat...
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.