Are Full Rollouts Necessary for On-Policy Distillation?
Pith reviewed 2026-06-28 22:38 UTC · model grok-4.3
The pith
Truncated or progressively growing rollouts suffice for effective on-policy distillation on math reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
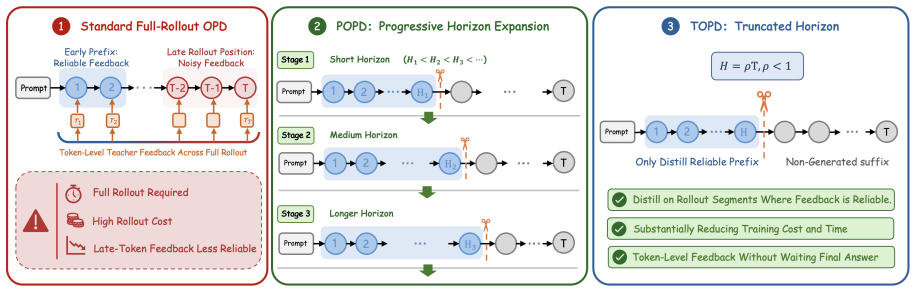
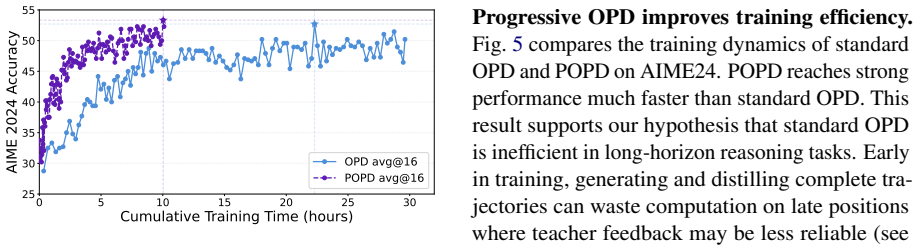
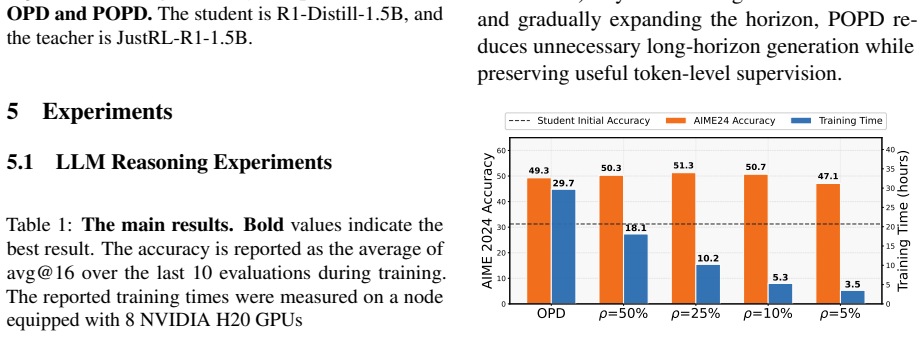
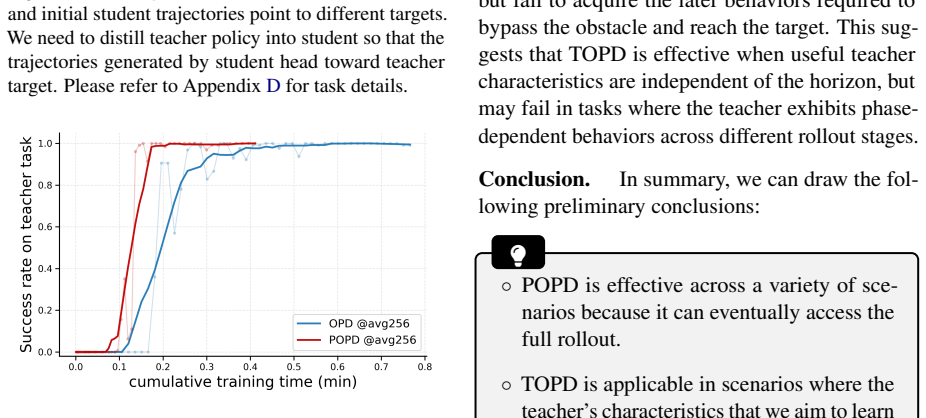
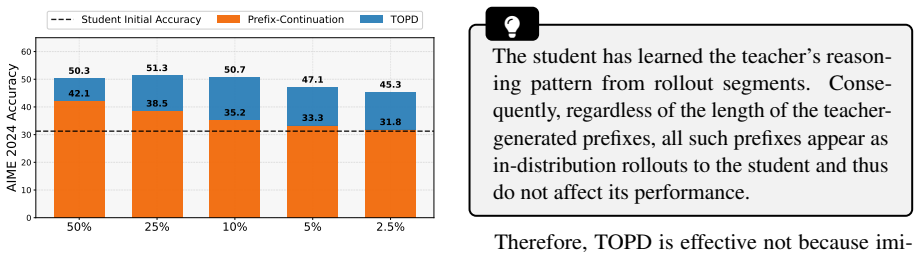
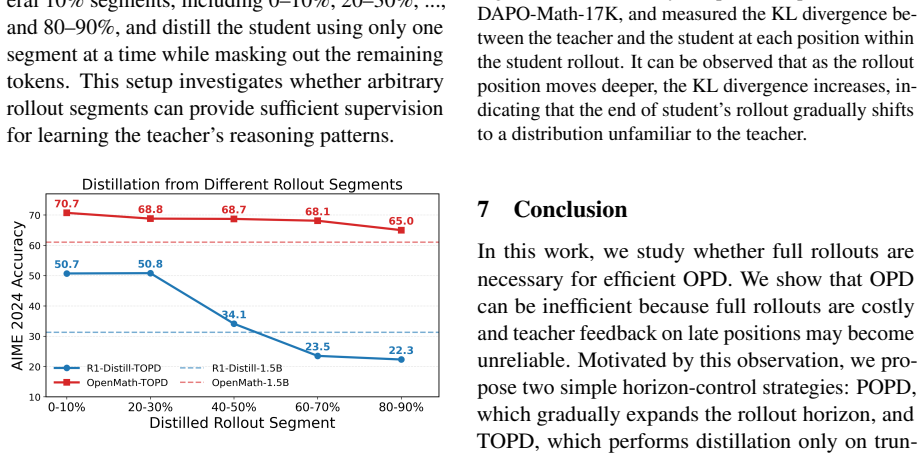
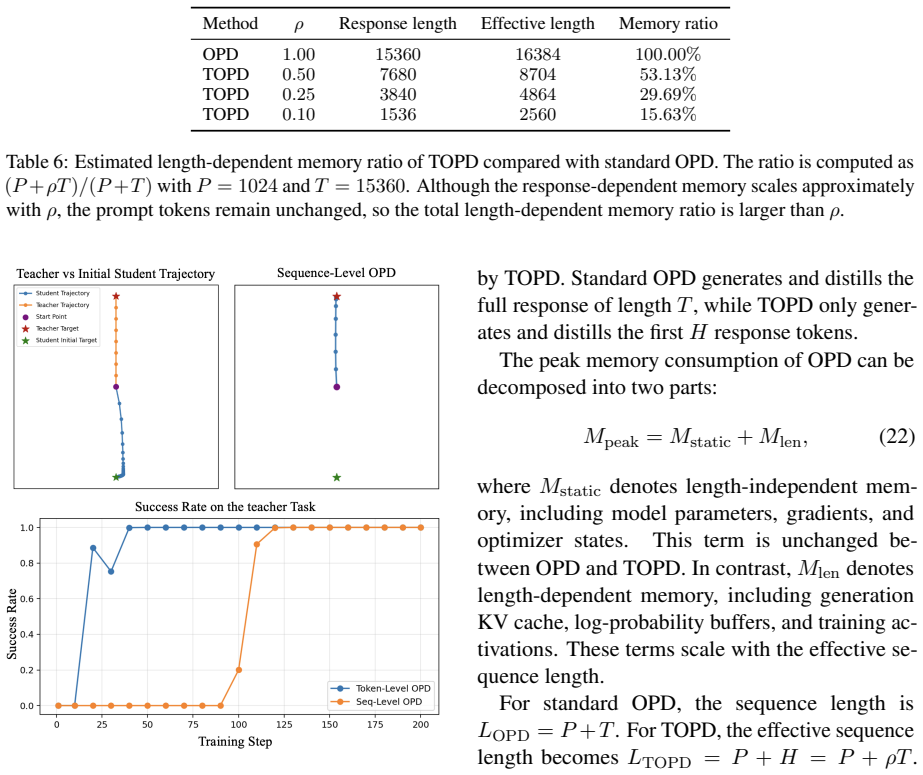
Standard on-policy distillation is bottlenecked by the need to generate full rollouts, which is costly and can expose the student to unreliable late-stage teacher feedback. Because OPD supplies learning signals throughout the sequence without requiring a complete trajectory or final reward, the authors introduce Progressive OPD, which gradually increases rollout length during training, and Truncated OPD, which fixes distillation on shorter, more reliable prefixes. On mathematical reasoning tasks, Progressive OPD improves training efficiency by up to 3× while Truncated OPD matches full-horizon performance using only 10% of the rollout length, producing large reductions in wall-clock time and
What carries the argument
Rollout horizon control via progressive expansion (POPD) or permanent truncation (TOPD) inside on-policy distillation loops.
If this is right
- Progressive expansion of the rollout horizon improves OPD training efficiency by up to 3×.
- Fixed truncation to 10% of the horizon matches the performance of full-horizon OPD on mathematical reasoning.
- Both horizon-control methods produce substantial reductions in wall-clock time and memory consumption.
- The rollout horizon itself is a primary controllable factor in OPD training cost.
Where Pith is reading between the lines
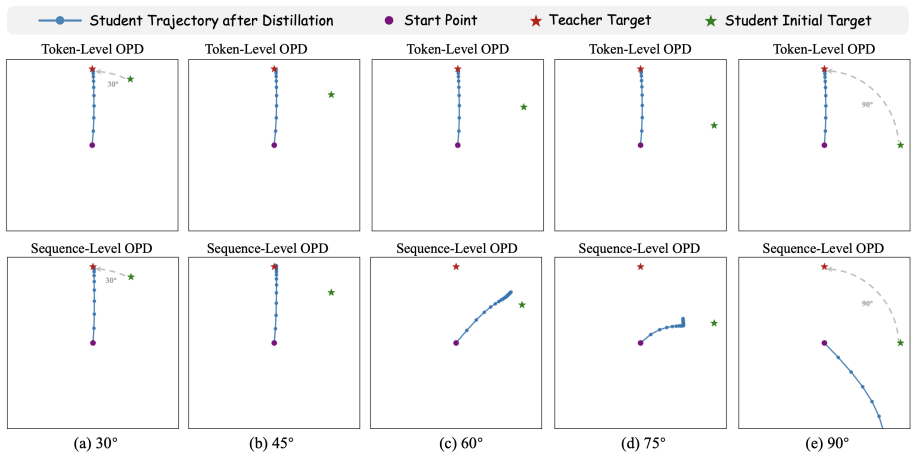
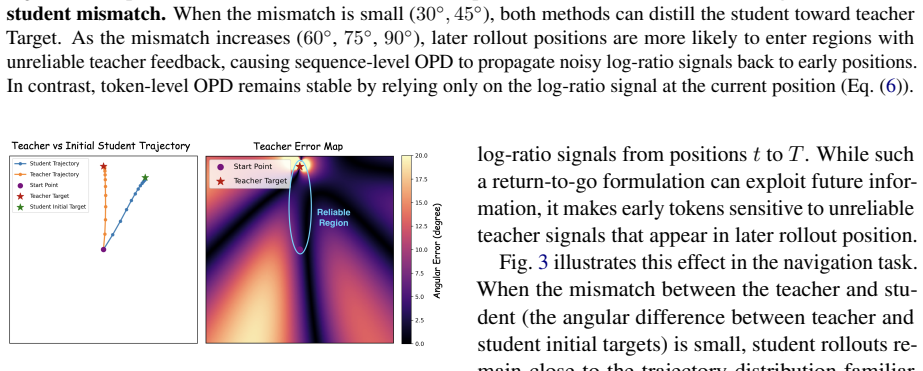
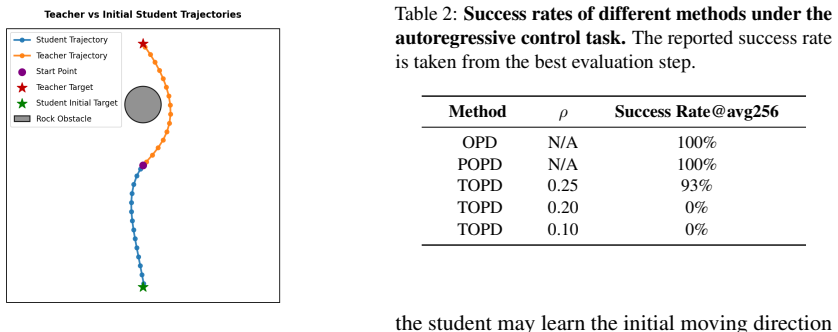
- Early truncation may shield the student from noisy or unreliable teacher signals that appear only in long rollouts during early training.
- The same horizon-limiting logic could be tested on other long-horizon domains such as code generation where dense intermediate feedback is available.
- Dynamic adjustment of horizon length based on measured feedback reliability could further reduce wasted computation.
Load-bearing premise
That teacher feedback on truncated or early-stage rollouts remains reliable and sufficient for effective learning without requiring the complete trajectory or a final answer reward.
What would settle it
A side-by-side run on the same mathematical reasoning benchmarks in which either Progressive OPD or Truncated OPD at the reported horizons produces lower final accuracy or slower convergence than standard full-rollout OPD would disprove the efficiency claims.
Figures




read the original abstract
On-policy distillation (OPD) provides dense teacher feedback along rollouts generated by the student and has emerged as a promising post-training paradigm for long-horizon reasoning. However, standard OPD typically generates full rollouts during training, which is computationally expensive and may expose the student to unreliable teacher feedback at late rollout positions, especially during early training. We identify the rollout horizon as a key bottleneck in OPD that substantially impacts training efficiency. Unlike Reinforcement Learning with Verifiable Rewards (RLVR), OPD does not require a complete trajectory or a final answer reward to provide learning signals. This observation suggests that full rollouts may not always be necessary for effective OPD. Motivated by this insight, we propose two simple horizon-control strategies: Progressive OPD (POPD), which gradually expands the rollout horizon during training, and Truncated OPD (TOPD), which permanently performs distillation on reliable truncated rollouts. Experiments on mathematical reasoning show that POPD improves the training efficiency of OPD by up to 3$\times$, while TOPD matches OPD performance using only 10\% of the rollout horizon, leading to substantial wall-clock and memory reductions. These results demonstrate that controlling the rollout horizon offers a simple and practical path to more efficient OPD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that full rollouts are unnecessary for on-policy distillation (OPD) in long-horizon reasoning because dense teacher feedback does not require complete trajectories or final-answer rewards. It introduces two horizon-control methods—Progressive OPD (POPD), which gradually expands the rollout length during training, and Truncated OPD (TOPD), which uses fixed short horizons—and reports that on mathematical reasoning tasks POPD yields up to 3× training-efficiency gains while TOPD matches standard OPD performance with only 10 % of the rollout horizon, producing wall-clock and memory savings.
Significance. If the reported efficiency gains and performance equivalence hold under rigorous controls, the work offers a practical route to lower the computational cost of OPD-based post-training by showing that truncated or progressively expanding horizons suffice when teacher signals are dense. The direct empirical tests of the two proposed strategies constitute a concrete, falsifiable contribution to efficient distillation methods.
major comments (1)
- [Experiments section] Experiments section: the claims of up to 3× efficiency improvement for POPD and performance matching for TOPD at 10 % horizon are presented without reported details on the number of random seeds, variance or statistical significance tests, or the precise baseline implementations and dataset splits; these omissions prevent verification that the measured speed-ups are robust and not artifacts of single-run variability.
minor comments (1)
- The abstract would be clearer if it named the specific mathematical reasoning benchmarks and teacher model used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation for minor revision. The single major comment concerns missing experimental details on seeds, variance, and baselines; we address this directly below and will incorporate the requested information in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the claims of up to 3× efficiency improvement for POPD and performance matching for TOPD at 10 % horizon are presented without reported details on the number of random seeds, variance or statistical significance tests, or the precise baseline implementations and dataset splits; these omissions prevent verification that the measured speed-ups are robust and not artifacts of single-run variability.
Authors: We agree that these details are necessary for verifying robustness. In the revised manuscript we will (i) report all main results as means over at least three random seeds with standard deviations, (ii) include statistical significance tests (paired t-tests or Wilcoxon) between methods where performance differences are claimed, and (iii) expand the experimental section with exact baseline code references, dataset splits, and hyper-parameter tables. These additions will be placed in a new “Experimental Details” subsection and will not alter the core claims. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical study that proposes two horizon-control strategies (POPD and TOPD) motivated by the observation that OPD supplies dense teacher feedback without requiring complete trajectories or final-answer rewards (unlike RLVR). These strategies are directly tested via experiments on mathematical reasoning tasks, reporting measured speed-ups (up to 3×) and performance equivalence at 10% horizon. No derivations, equations, fitted parameters renamed as predictions, or self-citations appear in the provided text; the central claims rest on external experimental outcomes rather than internal self-definition or load-bearing citations. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher feedback on truncated rollouts is reliable and sufficient for learning
Forward citations
Cited by 2 Pith papers
-
Blockwise Policy-Drift Gating for On-Policy Distillation
Blockwise policy-drift gating raises mean pass@8 from 0.4978 to 0.5160 on four math benchmarks by reweighting OPD losses with detached mean-normalized gates from student policy drift over 64-token blocks.
-
A Formula-Driven Survey and Research Agenda for On-Policy Distillation
A survey creates a taxonomy for on-policy distillation in LLMs that separates temporal credit assignment from vocabulary-level probability routing.
Reference graph
Works this paper leans on
-
[1]
Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
Learning to foresee: Unveiling the unlocking efficiency of on-policy distillation.arXiv preprint arXiv:2605.11739. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capabil- ity in llms via reinforcement learning.arXiv preprint arXiv:2501.12948. Wei Du, Shubham Toshniwal, Branislav Kisacanin, Sadegh Mahdavi, Ivan Moshkov, George Armstrong, Stephen Ge, Edgar Minasyan, Feng Chen, and Igor Gitman. 2025. Nemotron-math: Efficient long-context distillation of mathematical reason- ing fr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Revisiting on-policy distillation: Empiri- cal failure modes and simple fixes.arXiv preprint arXiv:2603.25562. GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunxiang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Hao- ran Wang, and 168 others...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Rethinking on-policy distillation of large lan- guage models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016. Kevin Lu and Thinking Machines Lab. 2025. On- policy distillation.Thinking Machines Lab: Con- nectionism. Https://thinkingmachines.ai/blog/on- policy-distillation. Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gon- tier, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$\pi$-Play: Multi-Agent Self-Play via Privileged Self-Distillation without External Data
π-play: Multi-agent self-play via privileged self-distillation without external data.arXiv preprint arXiv:2604.14054. 11 A Related Work MiniLLM first formalized OPD for LLMs under a reverse KL objective optimized via policy gradient (Gu et al., 2024; Yue et al., 2025). Unlike offline distillation (Kim and Rush, 2016), which aligns the student with teacher...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
In contrast, our work studies OPD efficiency from the perspective of rollout horizon control
analyze efficient OPD from the perspective of parameter dynamics and optimization behav- ior. In contrast, our work studies OPD efficiency from the perspective of rollout horizon control. We show that full rollouts are not always necessary for effective OPD, and that prioritizing reliable roll- out segments can substantially reduce training cost while pre...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.