Recognition: unknown
π-Play: Multi-Agent Self-Play via Privileged Self-Distillation without External Data
Pith reviewed 2026-05-10 13:40 UTC · model grok-4.3
The pith
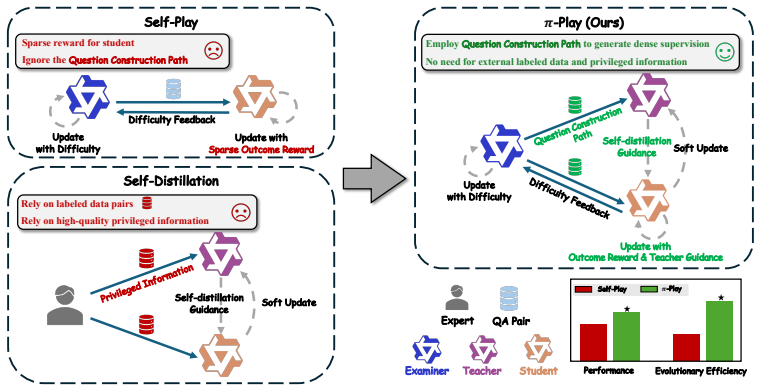
Self-play generates its own privileged context through question construction paths to enable dense self-distillation without external data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Self-play naturally produces a question construction path during examiner task generation; this path captures the reverse solution process and supplies privileged context that lets a teacher model densely supervise a student through self-distillation, turning sparse-reward self-play into a dense-feedback self-evolution framework that requires no external data or human feedback.
What carries the argument
The question construction path (QCP), an intermediate artifact generated alongside tasks that encodes the reverse solution process, used as privileged context for self-distillation inside the multi-agent π-Play framework.
If this is right
- Data-free π-Play surpasses the performance of fully supervised search agents on information-seeking tasks.
- Evolutionary efficiency increases by a factor of two to three times compared with conventional self-play.
- Dense supervision from QCP improves credit assignment over sparse outcome rewards alone.
- The framework scales multi-agent self-evolution without any dependence on curated datasets or human feedback.
Where Pith is reading between the lines
- Generation artifacts like QCP may be exploitable as internal supervision signals in other self-play or generative agent domains beyond search tasks.
- The method could be extended by searching for analogous construction paths in non-reasoning generation settings to broaden its applicability.
- Iterative refinement of how QCP is extracted and used might further reduce variance in the self-evolution loop over multiple rounds.
Load-bearing premise
The question construction path that arises naturally during self-play task generation supplies high-quality privileged context that supports effective dense self-distillation without introducing bias or requiring external validation.
What would settle it
An experiment in which student models trained with QCP-based distillation show no gain or a loss in performance relative to standard self-play, or in which QCP supervision introduces measurable bias that harms final agent capability.
Figures










read the original abstract
Deep search agents have emerged as a promising paradigm for addressing complex information-seeking tasks, but their training remains challenging due to sparse rewards, weak credit assignment, and limited labeled data. Self-play offers a scalable route to reduce data dependence, but conventional self-play optimizes students only through sparse outcome rewards, leading to low learning efficiency. In this work, we observe that self-play naturally produces a question construction path (QCP) during task generation, an intermediate artifact that captures the reverse solution process. This reveals a new source of privileged information for self-distillation: self-play can itself provide high-quality privileged context for the teacher model in a low-cost and scalable manner, without relying on human feedback or curated privileged information. Leveraging this insight, we propose Privileged Information Self-Play ($\pi$-Play), a multi-agent self-evolution framework. In $\pi$-Play, an examiner generates tasks together with their QCPs, and a teacher model leverages QCP as privileged context to densely supervise a student via self-distillation. This design transforms conventional sparse-reward self-play into a dense-feedback self-evolution loop. Extensive experiments show that data-free $\pi$-Play surpasses fully supervised search agents and improves evolutionary efficiency by 2-3$\times$ over conventional self-play.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes π-Play, a multi-agent self-play framework in which an examiner generates tasks along with their question construction paths (QCPs); a teacher then uses the QCP as privileged context to perform dense self-distillation on a student. This converts conventional sparse-reward self-play into a dense-feedback self-evolution loop that is claimed to be entirely data-free. The central empirical claims are that data-free π-Play surpasses fully supervised search agents and improves evolutionary efficiency by 2–3× relative to standard self-play.
Significance. If the core claims are substantiated, the work offers a scalable route to dense supervision in search-agent training without curated data or human feedback. The identification of QCP as a naturally occurring privileged artifact is a creative observation that could generalize beyond the reported domain.
major comments (2)
- [§3.2] §3.2 (Privileged Self-Distillation): The assertion that examiner-generated QCPs supply high-quality, low-bias privileged supervision is load-bearing for the superiority claim, yet the manuscript provides no external correctness signal or validation step; because the examiner and student belong to the same model family, any systematic error in reverse reasoning is directly distilled, creating a closed-loop bias risk that conventional sparse self-play avoids.
- [§5] §5 (Experiments): The reported 2–3× efficiency gain and outperformance of fully supervised agents are stated without ablations that isolate the contribution of QCP-based dense distillation versus sparse outcome rewards alone, without reported statistical significance, run counts, or variance, and without explicit baselines for the supervised agents, rendering the central performance claims unverifiable from the presented evidence.
minor comments (1)
- [Abstract] The abstract asserts 'extensive experiments' but supplies no summary of metrics, dataset sizes, or statistical tests; a one-sentence overview of the evaluation protocol would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and indicate the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Privileged Self-Distillation): The assertion that examiner-generated QCPs supply high-quality, low-bias privileged supervision is load-bearing for the superiority claim, yet the manuscript provides no external correctness signal or validation step; because the examiner and student belong to the same model family, any systematic error in reverse reasoning is directly distilled, creating a closed-loop bias risk that conventional sparse self-play avoids.
Authors: We acknowledge the potential for bias propagation when distilling QCPs within the same model family, as systematic errors in reverse reasoning could indeed be reinforced without an external correctness signal. The QCP is generated as an intrinsic byproduct of the examiner's task construction process rather than an independently verified artifact, which distinguishes it from curated privileged information but does not eliminate the closed-loop risk. We will revise the manuscript by adding a dedicated limitations paragraph in §3.2 and §6 that explicitly discusses this bias concern, contrasts it with sparse self-play, and outlines mitigation strategies such as periodic sparse-reward anchoring or cross-model distillation in future extensions. This addition clarifies the scope of the claims without altering the core method. revision: partial
-
Referee: [§5] §5 (Experiments): The reported 2–3× efficiency gain and outperformance of fully supervised agents are stated without ablations that isolate the contribution of QCP-based dense distillation versus sparse outcome rewards alone, without reported statistical significance, run counts, or variance, and without explicit baselines for the supervised agents, rendering the central performance claims unverifiable from the presented evidence.
Authors: We agree that the experimental evidence must be strengthened to make the efficiency and performance claims verifiable. In the revised manuscript we will expand §5 with: (i) explicit ablations that isolate QCP-based dense distillation from sparse outcome rewards alone; (ii) results reported as means and standard deviations over at least five independent runs together with statistical significance tests; and (iii) detailed specifications of the fully supervised search-agent baselines, including their training regimes, data sources, and hyper-parameters. These revisions will directly address the gaps noted by the referee. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical framework where self-play generates QCP as an observed artifact used for dense self-distillation. The central performance claims (surpassing supervised agents, 2-3× efficiency gains) are asserted via extensive experiments rather than mathematical derivations that reduce to inputs by construction. No equations, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the abstract or description. The loop is grounded in task outcomes and external benchmarks, making the finding self-contained against the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
From Context to Skills: Can Language Models Learn from Context Skillfully?
Ctx2Skill lets language models autonomously evolve context-specific skills via multi-agent self-play, improving performance on context learning tasks without human supervision.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations, pages 1–18, Vienna, Austria, 2024. OpenReview.net
2024
-
[2]
Hao Chen, Zhexin Hu, Jiajun Chai, Haocheng Yang, Hang He, Xiaohan Wang, Wei Lin, Luhang Wang, Guojun Yin, and Zhuofeng zhao. Toolforge: A data synthesis pipeline for multi-hop search without real-world apis.arXiv preprint arXiv:2512.16149, 2025
-
[3]
Self- questioning language models.arXiv preprint arXiv:2508.03682,
Lili Chen, Mihir Prabhudesai, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Self- questioning language models.arXiv preprint arXiv:2508.03682, 2025
-
[4]
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.arXiv preprint arXiv:2401.01335, 2024
-
[5]
Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. Srft: A single-stage method with supervised and reinforcement fine-tuning for reasoning.arXiv preprint arXiv:2506.19767, 2025
-
[6]
Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl, 2025
Jiaxuan Gao, Wei Fu, Minyang Xie, Shusheng Xu, Chuyi He, Zhiyu Mei, Banghua Zhu, and Yi Wu. Beyond ten turns: Unlocking long-horizon agentic search with large-scale asynchronous rl.arXiv preprint arXiv:2508.07976, 2025. 10
-
[7]
Shixiang Gu, Timothy Lillicrap, Zoubin Ghahramani, Richard E Turner, and Sergey Levine. Q-prop: Sample-efficient policy gradient with an off-policy critic.arXiv preprint arXiv:1611.02247, 2016
-
[8]
MiniLLM: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, pages 1–24, Vienna, Austria, 2024. OpenReview.net
2024
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, Barcelona, Spain (Online), 2020. International Committee on Computational Linguistics
2020
-
[11]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2026
work page internal anchor Pith review arXiv 2026
-
[12]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review arXiv 2026
-
[13]
Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training LLMs to reason and leverage search engines with reinforcement learning. InSecond Conference on Language Modeling, 2025
2025
-
[14]
Weld, and Luke Zettlemoyer
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601–1611, Vancouver, Canada, July 2017. Association for Computational Linguistics
2017
-
[15]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6769–6781, Online, 2020. Association for Computational Linguistics
2020
-
[16]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
2019
-
[17]
Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592, 2025
-
[18]
Bo Liu, Leon Guertler, Simon Yu, Zichen Liu, Penghui Qi, Daniel Balcells, Mickel Liu, Cheston Tan, Weiyan Shi, Min Lin, Wee Sun Lee, and Natasha Jaques. Spiral: Self-play on zero-sum games incentivizes reasoning via multi-agent multi-turn reinforcement learning.arXiv preprint arXiv:2506.24119, 2026
-
[19]
Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
-
[20]
Hongliang Lu, Yuhang Wen, Pengyu Cheng, Ruijin Ding, Jiaqi Guo, Haotian Xu, Chutian Wang, Haonan Chen, Xiaoxi Jiang, and Guanjun Jiang. Search self-play: Pushing the frontier of agent capability without supervision.arXiv preprint arXiv:2510.18821, 2025. 11
-
[21]
On-policy distillation
Kevin Lu and Thinking Machines Lab. On-policy distillation. Thinking Machines Lab: Connectionism, 2025
2025
-
[22]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 9802–9822, Toronto, Canada, 2023. Association for Computa...
2023
-
[23]
OpenAI OpenAI, Matthias Plappert, Raul Sampedro, Tao Xu, Ilge Akkaya, Vineet Kosaraju, Peter Welinder, Ruben D’Sa, Arthur Petron, Henrique P. d. O. Pinto, Alex Paino, Hyeonwoo Noh, Lilian Weng, Qiming Yuan, Casey Chu, and Wojciech Zaremba. Asymmetric self-play for automatic goal discovery in robotic manipulation.arXiv preprint arXiv:2101.04882, 2021
-
[24]
Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
-
[25]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, Singapore, 2023. Association for Computational Linguistics
2023
-
[26]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. Crisp: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Jordan, and Pieter Abbeel
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation. InThe F ourth Inter- national Conference on Learning Representations, pages 1–14, San Juan, Puerto Rico, 2016. OpenReview.net
2016
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review arXiv 2026
-
[30]
R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. R1-searcher: Incentivizing the search capability in llms via reinforcement learning.arXiv preprint arXiv:2503.05592, 2025
work page internal anchor Pith review arXiv 2025
-
[31]
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. Zerosearch: Incentivize the search capability of llms without searching.arXiv preprint arXiv:2505.04588, 2025
-
[32]
Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[33]
Dynamic dual-granularity skill bank for agentic rl.arXiv preprint arXiv:2603.28716, 2026
Songjun Tu, Chengdong Xu, Qichao Zhang, Yaocheng Zhang, Xiangyuan Lan, Linjing Li, and Dongbin Zhao. Dynamic dual-granularity skill bank for agentic rl.arXiv preprint arXiv:2603.28716, 2026
-
[34]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review arXiv 2022
-
[35]
OpenClaw-RL: Train Any Agent Simply by Talking
Yinjie Wang, Xuyang Chen, Xiaolong Jin, Mengdi Wang, and Ling Yang. Openclaw-rl: Train any agent simply by talking.arXiv preprint arXiv:2603.10165, 2026. 12
work page Pith review arXiv 2026
-
[36]
Ziliang Wang, Xuhui Zheng, Kang An, Cijun Ouyang, Jialu Cai, Yuhang Wang, and Yichao Wu. Stepsearch: Igniting llms search ability via step-wise proximal policy optimization.arXiv preprint arXiv:2505.15107, 2025
-
[37]
Webdancer: Towards autonomous information seeking agency
Jialong Wu, Baixuan Li, Runnan Fang, Wenbiao Yin, Liwen Zhang, Zhenglin Wang, Zhengwei Tao, Ding-Chu Zhang, Zekun Xi, Xiangru Tang, Yong Jiang, Pengjun Xie, Fei Huang, and Jingren Zhou. Webdancer: Towards autonomous information seeking agency. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, pages 1–29, RSan Diego, USA, 2025...
2025
-
[38]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[39]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Lan- guage Processing, pages 2369–2380, Brussels, Belgium, 2018. Association for Computational ...
2018
-
[40]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, pages 1–33, Kigali, Rwanda, 2023. OpenReview.net
2023
-
[41]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review arXiv 2026
-
[42]
Self-rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. Self-rewarding language models. InProceedings of the 41st International Conference on Machine Learning, pages 57905–57923, Vienna, Austria, 2024. PMLR
2024
-
[43]
Promoting efficient reasoning with verifiable stepwise reward.arXiv preprint arXiv:2508.10293, 2025
Chuhuai Yue, Chengqi Dong, Yinan Gao, Hang He, Jiajun Chai, Guojun Yin, and Wei Lin. Promoting efficient reasoning with verifiable stepwise reward.arXiv preprint arXiv:2508.10293, 2025
-
[44]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, pages 1–36, RSan Diego, USA, 2025. Curran Associates Inc
2025
- [45]
-
[46]
Yaocheng Zhang, Haohuan Huang, Zijun Song, Yuanheng Zhu, Qichao Zhang, Zijie Zhao, and Dongbin Zhao. Criticsearch: Fine-grained credit assignment for search agents via a retrospective critic.arXiv preprint arXiv:2511.12159, 2025
-
[47]
Offline goal- conditioned reinforcement learning with elastic-subgoal diffused policy learning
Yaocheng Zhang, Yuanheng Zhu, Yuqian Fu, Songjun Tu, and Dongbin Zhao. Offline goal- conditioned reinforcement learning with elastic-subgoal diffused policy learning. InProceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, page 2336–2344, Richland, SC, 2025. International Foundation for Autonomous Agents and Multia-...
2025
-
[48]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026. 13
work page internal anchor Pith review arXiv 2026
-
[49]
DeepResearcher: Scaling deep research via reinforcement learning in real-world environments
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. DeepResearcher: Scaling deep research via reinforcement learning in real-world environments. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, page 414–431, Suzhou, China, 2025. Association for Computational Linguistics. ...
2025
-
[50]
FC Barcelona Rugby League
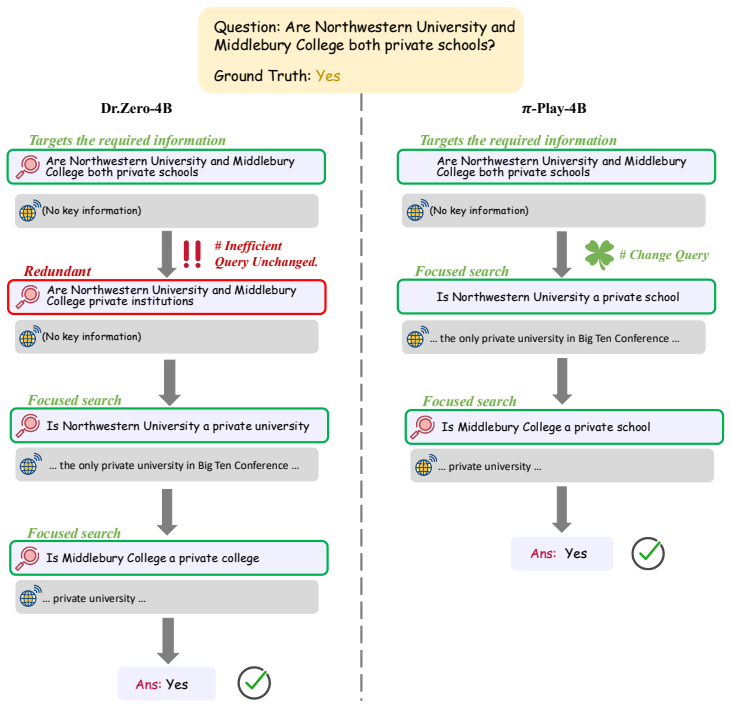
Compared with SQLM* and Dr.Zero, π-Play demonstrates fewer search actions and lower query redundancy. Avg Accuracy↑Search Count↓Query Redundancy↓ SQLM* 35.7 2.3 0.43 Dr.Zero 38.0 2.4 0.48 π-Play 39.6 1.9 0.37 18 B.4 Case Study We present QCP examples generated by the examiner during the π-Play training process. The QCPs for different hop settings are pres...
2010
-
[51]
Hop 1 is the starting entity found in the document
Hop: A node in the reasoning chain. Hop 1 is the starting entity found in the document. Hop n is the final answer. ### Inputs
-
[52]
n: the exact number of hops in the reasoning chain (requiring n-1 searches)
-
[53]
### Process & Tools
Source document: the full source text. ### Process & Tools
-
[54]
- Select a specific entity, event or detail explicitly mentioned in the text
Analyze the Document and Select the Starting Point - Read and analyze the source document. - Select a specific entity, event or detail explicitly mentioned in the text. This entity becomes Hop 1 (the initial clue)
-
[55]
The result is Hop 2
Design the Chain Forwards - From Hop 1 to Hop 2: Identify a factual attribute or relation of Hop 1 that is NOT in the text but can be found via search. The result is Hop 2. - Iterate: Continue connecting the current Hop i to the next Hop i+1 using deterministic, verifiable relation found via search. - Stop at Hop n: Continue this process until you have ex...
-
[56]
</think>`when you plan connections or receive new information
Reasoning & Search Protocol - Always reason inside`<think> ... </think>`when you plan connections or receive new information. - For each hop transition that requires external information, issue search query using`< tool_call> ... </tool_call>`. - Search results will be provided between`<tool_response> ... </tool_response>`by the system
-
[57]
Output Format - Emit a numbered sequence of EXACTLY n-1 search steps. For each search i (1 to n-1), produce: `<think> Reasoning step i: Identify Hop i in document/search results, formulate query to reach Hop i+1 </think>` `<tool_call> Query to search Hop i+1 </tool_call>` `[Wait for search results in <tool_response> from system]` - After completing all se...
-
[58]
Example template for Hop n = 1, i.e. no search: `<think> [Explain how Hop 1 is selected from the source document and how the question is formulated] </think>` `<question> [Question based solely on the text entity Hop 1] </question>` `<answer> [Answer (Hop 1)] </answer>`
-
[59]
Example template for Hop n = 3, i.e. 2 searches: `<think> [Reasoning step 1: Find Hop 1 in the source document, formulate the query to reach Hop 2] </think>` `<tool_call> [Search query to find Hop 2 based on Hop 1] </tool_call>` `[Wait for search results in <tool_response> from system]` `<think> [Reasoning step 2: Reason on search results to identify Hop ...
-
[60]
Every subsequent hop must be supported by the corresponding search results
Start in Document: Hop 1 must be explicitly present in the source text. Every subsequent hop must be supported by the corresponding search results
-
[61]
Search is mandatory for n > 1: Each link between hops beyond Hop 1 must use the search engine
-
[62]
Exact search count: Emit exactly (n-1)`<tool_call>`entries, no more, no fewer
-
[63]
No spoilers: The question must mention only Hop 1; do not include or hint at intermediate hops
-
[64]
Clarity: The question is self-contained; the answer is concise and direct (no extra commentary, formatting or explanation)
-
[65]
No hop should be skippable or derivable without its immediate predecessor
Chain integrity: Each hop must depend strictly on the previous hop. No hop should be skippable or derivable without its immediate predecessor. Now, generate a question and its answer with n = {hops} hops starting from the following source document: {document} Figure 10:Initial instructions for the examiner in π-play.Our prompt for examiner is developed ba...
-
[66]
Precise Searching: When generating search queries, ensure they are specific, semantically complete, and directly target the key information you are missing
-
[67]
Context Retention: Remember prior conversations and search results, maintaining logical consistency across multiple rounds of searching
-
[68]
Termination Judgment: When information are sufficient to determine the answer, immediately stop searching and output the answer
-
[69]
Reference to Privileged Information: When outputting search actions and answers, refer to the question construction process in privileged information, but do not directly output the ground- truth in the first turn or directly use extra information from the source document
-
[70]
Steven Febey
Search Boundary Constraint: When searching, do not introduce information that is not contained in the question or search results, even if it exists in the source document. ### Example (Only showcase the logical style, please do not directly imitate the specific content ) #### User This is the reverse solution process of the question (i.e., the process of ...
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.