UNISON: A Unified Sound Generation and Editing Framework via Deep LLM Fusion
Pith reviewed 2026-06-28 20:33 UTC · model grok-4.3
The pith
A single model with 621M-732M parameters unifies text-to-audio, text-to-speech, zero-shot cloning, mixed generation, and multiple audio editing tasks under one set of weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A single latent diffusion model with layer-wise deep fusion of uniformly sampled hidden states from a frozen MLLM into corresponding MM-DiT blocks, plus a unified multi-task design that encodes task identity only through a channel-wise mask and VAE concatenation, can jointly solve text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition while sharing one set of 621M-732M trainable parameters and matching or exceeding specialist models.
What carries the argument
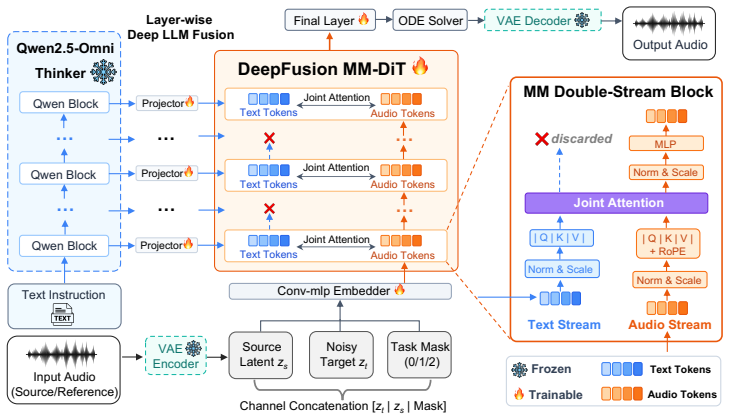
Layer-wise deep LLM fusion that injects hidden states from uniformly sampled layers of a frozen MLLM into MM-DiT blocks via learned projections, paired with channel-wise mask and VAE concatenation to encode task identity.
If this is right
- One set of weights suffices for both open-ended generation and precise temporal editing of mixed speech and sound scenes.
- Depth-matched conditioning from multiple LLM layers improves following of complex editing instructions compared with single-layer baselines.
- Online GPU-side multi-task data synthesis with task-homogeneous batching and two-stage curriculum stabilizes joint training across seven tasks.
- The resulting model size remains roughly four times smaller than prior unified audio systems while matching their accuracy.
- Seamless mixing of speech and environmental sound, plus zero-shot cloning, emerges from the shared architecture without extra components.
Where Pith is reading between the lines
- Deployment of audio AI could become simpler if only one model needs to be hosted instead of separate generators and editors.
- The frozen-LLM approach may allow future scaling by swapping in larger language models without retraining the diffusion backbone.
- Task-homogeneous batching combined with curriculum learning could transfer to other multi-task generative settings beyond audio.
- If the mask-and-concatenation scheme generalizes, similar lightweight task encoding might reduce parameter overhead in unified video or music models.
Load-bearing premise
Uniformly sampled hidden states from multiple layers of a frozen MLLM, when injected through learned projections, supply depth-matched semantic conditioning that improves instruction following, and a channel-wise mask plus VAE concatenation alone is enough to distinguish tasks without any task-specific modules.
What would settle it
An ablation that replaces the multi-layer LLM injection with single-layer injection and removes the channel-wise mask, then measures whether instruction-following accuracy on speech-in-scene editing drops below the performance of the full UNISON model.
Figures






read the original abstract
We present UNISON, a latent diffusion framework that unifies speech generation, sound generation, and audio editing within a single model. A single model handles text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition, all of which share a single set of weights. Our architecture features two core designs: (1) Layer-wise deep LLM fusion, which injects hidden states from uniformly sampled layers of a frozen MLLM into corresponding MM-DiT blocks via learned projections, providing depth-matched semantic conditioning that improves instruction following over single-layer baselines; and (2) a unified multi-task architecture where task identity is encoded solely by a channel-wise mask and source audio is provided through VAE-encoded channel concatenation. Training is stabilized by an online GPU-side multi-task data synthesis pipeline with task-homogeneous batching and a two-stage curriculum. With 621M--732M trainable parameters, UNISON achieves results competitive with or exceeding task-specialist models across evaluated domains, while being roughly $4\times$ smaller than comparable unified systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents UNISON, a latent diffusion framework unifying speech generation, sound generation, and audio editing in a single model with 621M-732M trainable parameters. Core designs include layer-wise deep LLM fusion (injecting uniformly sampled hidden states from a frozen MLLM into corresponding MM-DiT blocks via learned projections) and a multi-task architecture using only channel-wise masks for task identity plus VAE-encoded channel concatenation for source audio. Training uses an online GPU-side multi-task data synthesis pipeline with task-homogeneous batching and two-stage curriculum. The model is claimed to handle text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level editing, speech-in-scene editing, and timed temporal composition while achieving results competitive with or exceeding task-specialist models and being ~4x smaller than comparable unified systems.
Significance. If the performance claims hold with rigorous quantitative support, the work would demonstrate a meaningful step toward efficient unified audio models by showing that depth-matched LLM conditioning and minimal task encoding can support broad task coverage without task-specific components. This could reduce model proliferation in the field and highlight the value of deep fusion over single-layer baselines.
minor comments (2)
- The abstract states competitive results but does not report specific metrics, baselines, datasets, or error bars; the full manuscript should include these in a dedicated results section with tables for each task.
- Notation for the channel-wise mask and VAE concatenation should be formalized with an equation or diagram in the methods section to clarify how task identity is encoded without additional components.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for noting the potential significance of demonstrating efficient unified audio modeling via depth-matched LLM fusion and minimal task encoding. We are pleased that the work is viewed as a possible step toward reducing model proliferation if the quantitative claims hold under rigorous evaluation. Below we respond to the points raised.
Circularity Check
No significant circularity identified
full rationale
The abstract and description contain no equations, derivations, or self-citations that could reduce any claimed prediction or result to its inputs by construction. Architectural choices such as layer-wise LLM fusion via learned projections and task encoding via channel-wise mask plus VAE concatenation are presented as design decisions without any fitted-input-called-prediction pattern or self-definitional loop. The unified model is described as achieving competitive results through standard training procedures, with no load-bearing self-citation chains or ansatz smuggling visible. This is the normal self-contained case for an empirical architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[5]
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. 2020. Vggsound: A large-scale audio-visual dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 721--725. IEEE
2020
-
[6]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, JianZhao JianZhao, Kai Yu, and Xie Chen. 2025. F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6255--6271
2025
-
[7]
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, and Yuki Mitsufuji. 2025. Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 28901--28911
2025
-
[8]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. 2023. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models. arXiv preprint arXiv:2311.07919
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D Manning. 2019. What does bert look at? an analysis of bert’s attention. In Proceedings of the 2019 ACL workshop BlackboxNLP: analyzing and interpreting neural networks for NLP, pages 276--286
2019
-
[10]
Alexis Conneau, Alexei Baevski, Ronan Collobert, Abdelrahman Mohamed, and Michael Auli. 2021. Unsupervised cross-lingual representation learning for speech recognition. In Interspeech 2021, pages 2426--2430
2021
-
[11]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre D \'e fossez. 2023. Simple and controllable music generation. In Advances in Neural Information Processing Systems, volume 36
2023
-
[13]
Zhihao Du, Qian Chen, Xian Shi, Xiang Lv, Zhifu Gao, Changfeng Gao, Hui Wang, Dong Yu, Jianzong Pan, and Fan Wang. 2024 a . Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens. arXiv preprint arXiv:2407.05407
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, and 1 others. 2024. E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts. In 2024 IEEE spoken language technology workshop (SLT), pages 682--689. IEEE
2024
-
[16]
Zach Evans, Julian D Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons. 2025. Stable audio open. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE
2025
-
[17]
Zhifu Gao, Zerui Li, Jiaming Wang, Haoneng Luo, Xian Shi, Mengzhe Chen, Yabin Li, Lingyun Zuo, Zhihao Du, Zhangyu Xiao, and Shiliang Zhang. 2023. Funasr: A fundamental end-to-end speech recognition toolkit. In Interspeech 2023, pages 1593--1597
2023
-
[18]
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Audio set: An ontology and human-labeled dataset for audio events. In 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 776--780. IEEE
2017
-
[19]
Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, and Soujanya Poria. 2023. Text-to-audio generation using instruction-tuned LLM and latent diffusion model. In Proceedings of the 31st ACM International Conference on Multimedia, pages 3590--3598
2023
-
[20]
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Guha Balakrishnan, and Vicente Ordonez. 2026. Taming data and transformers for audio generation. International Journal of Computer Vision, 134(3):87
2026
-
[21]
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, and 1 others. 2024. Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 885--890. IEEE
2024
-
[22]
Jonathan Ho and Tim Salimans. 2021. Classifier-free diffusion guidance. In NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications
2021
-
[24]
Chia-Yu Hung, Navonil Majumder, Zhifeng Kong, Ambuj Mehrish, Amir Zadeh, Chuan Li, Rafael Valle, Bryan Catanzaro, and Soujanya Poria. 2026. Tangoflux: Super fast and faithful text to audio generation with flow matching and clap-ranked preference optimization. In International Conference on Learning Representations
2026
-
[25]
Ziyue Jiang, Qian Yang, Jialong Zuo, Zhenhui Ye, Rongjie Huang, Yi Ren, and Zhou Zhao. 2023. Fluentspeech: Stutter-oriented automatic speech editing with context-aware diffusion models. In Findings of the Association for Computational Linguistics: ACL 2023, pages 11655--11671
2023
-
[26]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. Audiocaps: Generating captions for audios in the wild. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 119--132
2019
-
[27]
Qiuqiang Kong, Yin Cao, Turab Iqbal, Yuxuan Wang, Wenwu Wang, and Mark D Plumbley. 2020. Panns: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:2880--2894
2020
-
[28]
Felix Kreuk, Gabriel Synnaeve, Adam Polyak, Uriel Singer, Alexandre D \'e fossez, Jade Copet, Devi Parikh, Yaniv Taigman, and Yossi Adi. 2023. Audiogen: Textually guided audio generation. In International Conference on Learning Representations
2023
-
[29]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. 2023. Flow matching for generative modeling. In International Conference on Learning Representations
2023
-
[30]
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. 2023 a . Audioldm: Text-to-audio generation with latent diffusion models. In International Conference on Machine Learning, pages 21450--21474. PMLR
2023
-
[31]
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, and Mark D Plumbley. 2024. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:2871--2883
2024
-
[32]
Xingchao Liu, Chengyue Gong, and Qiang Liu. 2023 b . Flow straight and fast: Learning to generate and transfer data with rectified flow. In International Conference on Learning Representations
2023
-
[33]
Hila Manor and Tomer Michaeli. 2024. Zero-shot unsupervised and text-based audio editing using DDPM inversion. In International Conference on Machine Learning, pages 34603--34629. PMLR
2024
-
[34]
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D Plumbley, Yuexian Zou, and Wenwu Wang. 2024. Wavcaps: A chatgpt-assisted weakly-labelled audio captioning dataset for audio-language multimodal research. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32:3339--3354
2024
-
[35]
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. 2022. Sdedit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations
2022
-
[36]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195--4205
2023
-
[38]
Chunyu Qiang, Kang Yin, Xiaopeng Wang, Yuzhe Liang, Jiahui Zhao, Ruibo Fu, Tianrui Wang, Cheng Gong, Chen Zhang, Longbiao Wang, and 1 others. 2026 b . Instructaudio: Unified speech and music generation with natural language instruction. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 17722--17726. IEEE
2026
-
[39]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492--28518. PMLR
2023
-
[40]
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2023. https://arxiv.org/abs/2104.09864 Roformer: Enhanced transformer with rotary position embedding . Preprint, arXiv:2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Jaesung Tae, Hyeongju Kim, and Taesu Kim. 2022. Editts: Score-based editing for controllable text-to-speech. In Interspeech 2022, pages 421--425
2022
-
[42]
Bingda Tang, Boyang Zheng, Sayak Paul, and Saining Xie. 2025. Exploring the deep fusion of large language models and diffusion transformers for text-to-image synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 28586--28595
2025
-
[44]
Silero Team. 2024. Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier. https://github.com/snakers4/silero-vad
2024
-
[45]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. Bert rediscovers the classical nlp pipeline. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 4593--4601
2019
-
[46]
Zeyue Tian, Binxin Yang, Zhaoyang Liu, Jiexuan Zhang, Ruibin Yuan, Hubery Yin, Qifeng Chen, Chen Li, Jing Lv, Wei Xue, and 1 others. 2026. Audio-omni: Extending multi-modal understanding to versatile audio generation and editing. In ACM SIGGRAPH
2026
-
[48]
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, and 1 others. 2023. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Xueyao Zhang, Shunsi Zhang, and Zhizheng Wu. 2025. Maskgct: Zero-shot text-to-speech with masked generative codec transformer. In International Conference on Learning Representations, volume 2025, pages 47127--47150
2025
-
[50]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1--5. IEEE
2023
-
[51]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, and 1 others. 2025. Qwen2.5-omni technical report. arXiv preprint arXiv:2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Haohan Guo, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Zhou Zhao, Xixin Wu, and Helen M. Meng. 2024. Uniaudio: Towards universal audio generation with large language models. In International Conference on Machine Learning, pages 56422--56447. PMLR
2024
-
[53]
Zhuoyuan Yao, Di Wu 0061, Xiong Wang, Binbin Zhang, Fan Yu, Chao Yang, Zhendong Peng, Xiaoyu Chen, Lei Xie, and Xin Lei. 2021. Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit. In interspeech, volume 2021, pages 4054--4058
2021
-
[54]
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. 2019. Libritts: A corpus derived from librispeech for text-to-speech. In Interspeech 2019, pages 1526--1530
2019
-
[55]
Han Zhu, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhaoqing Li, Weiji Zhuang, Long Lin, and Daniel Povey. 2025. Zipvoice: Fast and high-quality zero-shot text-to-speech with flow matching. In IEEE Automatic Speech Recognition and Understanding Workshop (ASRU)
2025
-
[56]
Kim, C.D. et al. (2019). AudioCaps: Generating Captions for Audios in The Wild. NAACL-HLT 2019
2019
- [57]
- [58]
-
[59]
Tian, Z. et al. (2026). Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing. arXiv:2604.10708
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Cai, Q. et al. (2025). HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer. arXiv:2505.22705
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Deng, C. e¸t al. (2025). Emerging Properties in Unified Multimodal Pretraining. arXiv:2505.14683
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
Du, Z. et al. (2024). CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models. arXiv:2412.10117
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Eskimez, S.E. et al. (2024). E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS
2024
-
[64]
Tae, J. et al. (2021). EdiTTS: Score-based Editing for Controllable Text-to-Speech
2021
- [65]
-
[66]
Tenney, I. et al. (2019). BERT Rediscovers the Classical NLP Pipeline. ACL 2019
2019
-
[67]
Jawahar, G. et al. (2019). What Does BERT Look At? An Analysis of BERT's Attention. BlackboxNLP, ACL 2019
2019
-
[68]
Chen, Y. et al. (2024). F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching
2024
-
[69]
Jiang, Z. et al. (2022). FluentSpeech: Stutter-Oriented Automatic Speech Editing with Context-Aware Diffusion Models
2022
- [70]
-
[71]
He, H. et al. (2024). Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
2024
-
[72]
Qiang, D. et al. (2025). InstructAudio
2025
- [73]
-
[74]
Wang, Y. et al. (2024). MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
2024
-
[75]
Cheng, H.K. et al. (2025). MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis. CVPR 2025
2025
- [76]
-
[77]
Xu, Z. et al. (2025). Qwen2.5-Omni Technical Report
2025
-
[78]
Su, J. et al. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding
2021
-
[79]
Meng, C. et al. (2021). SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
2021
-
[80]
Evans, Z. et al. (2024). Stable Audio Open
2024
-
[81]
Ghosal, D. et al. (2023). Text-to-Audio Generation using Instruction-Tuned LLM and Latent Diffusion Model
2023
- [82]
-
[83]
Yang, D. et al. (2024). UniAudio: An Audio Foundation Model Toward Universal Audio Generation. ICML 2024
2024
-
[84]
Qiang, D. et al. (2025). UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions. arXiv:2604.22209
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[85]
Zhu, H. et al. (2025). ZipVoice: Fast and High-Quality Zero-Shot Text-to-Speech with Flow Matching
2025
-
[86]
& Michaeli, T
Manor, H. & Michaeli, T. (2024). Zero-Shot Unsupervised and Text-Based Audio Editing Using DDPM Inversion
2024
-
[87]
Anastassiou, P. et al. (2024). Seed-TTS: A Family of High-Quality Versatile Speech Generation Models. arXiv:2406.02430
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[88]
Kong, Q. et al. (2020). PANNs: Large-Scale Pretrained Audio Neural Networks for Audio Pattern Recognition. IEEE/ACM Trans. Audio, Speech, Lang. Process., 28, 2880--2894
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.