The Dynamic-Probabilistic Consistency Gap in Chaotic Surrogate Modeling
Pith reviewed 2026-06-28 23:20 UTC · model grok-4.3
The pith
Open-loop Gaussian rollout objectives create a dynamic-probabilistic consistency gap by penalizing Jacobian-generated covariance growth in chaotic surrogate models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
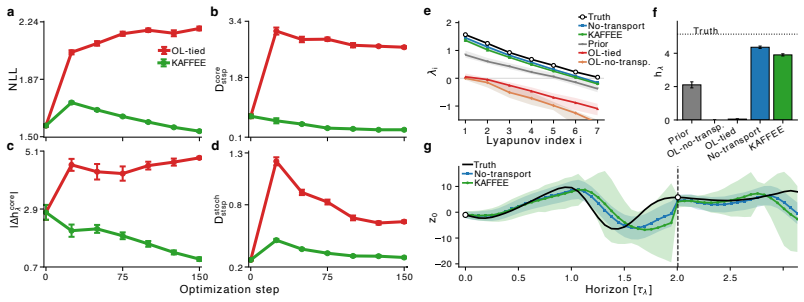
Open-loop Gaussian rollout objectives penalize Jacobian-generated covariance growth in chaotic systems, encouraging optimization shortcuts that weaken physical expansion or decouple uncertainty from the tangent dynamics. KAFFEE closes this dynamic-probabilistic consistency gap by evaluating likelihood on innovations and transporting covariance via Jacobians, yielding better invariant reconstruction on stochastic hyperchaotic Lorenz-96 and largely preserving zero-shot dynamics across 13 systems during probabilistic adaptation of a foundation model.
What carries the argument
The dynamic-probabilistic consistency (DPC) gap, produced when open-loop Gaussian objectives penalize covariance growth arising from learned local Jacobians in chaotic regimes.
If this is right
- KAFFEE reduces core collapse, noise masking, and blind uncertainty on stochastic hyperchaotic Lorenz-96.
- KAFFEE improves reconstruction of dynamical invariants relative to open-loop objectives.
- KAFFEE maintains competitive predictive scores while enabling in-context Bayesian filtering.
- KAFFEE largely preserves zero-shot dynamics when adapting a DSR foundation model across 13 chaotic systems.
Where Pith is reading between the lines
- The gap may reduce trustworthiness of uncertainty estimates for long-horizon forecasts in chaotic domains.
- Similar decoupling could occur in other rollout-based probabilistic losses beyond Gaussian objectives.
- KAFFEE-style local filtering may offer a route to consistent uncertainty in high-dimensional surrogate models outside the tested systems.
Load-bearing premise
That likelihood evaluation on local innovations combined with Jacobian-based covariance transport in a differentiable extended Kalman filter will close the consistency gap without creating new inconsistencies in chaotic regimes.
What would settle it
Direct comparison of whether covariance growth under KAFFEE remains aligned with the learned Jacobians on a new hyperchaotic system where open-loop training produced measurable decoupling.
Figures






read the original abstract
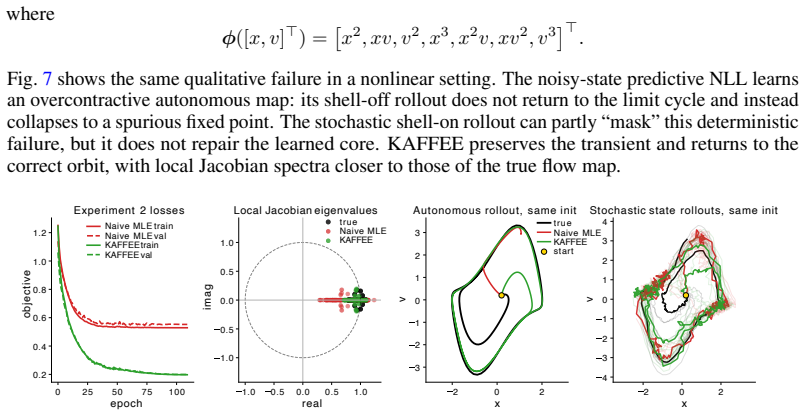
Dynamical systems reconstruction (DSR) aims to learn surrogate models that capture the dynamics underlying time-series data. Reliably deploying these surrogates requires uncertainty estimates consistent with the learned dynamics. We expose a dynamic-probabilistic consistency (DPC) gap: the pursuit of finite-horizon probabilistic objectives can degrade dynamics or decouple predictive uncertainty from the local tangent dynamics it ought to reflect. We isolate three mechanisms behind this gap: core collapse, noise masking, and blind uncertainty. Specifically, we show that open-loop Gaussian rollout objectives can penalize Jacobian-generated covariance growth in chaotic systems, encouraging optimization shortcuts that weaken physical expansion or decouple uncertainty from it. To mitigate this gap, we propose KAFFEE (Kalman-Aware Framework For Ergodic Emulation), a differentiable extended Kalman filter-based training framework that evaluates likelihood on local predictive residuals (innovations) while transporting covariance through learned local Jacobians. On stochastic hyperchaotic Lorenz-96, KAFFEE reduces the identified failure modes, improves reconstruction of dynamical invariants relative to open-loop objectives, and maintains competitive predictive scores. We further show that the DPC gap appears when probabilistically adapting a DSR foundation model across 13 chaotic systems, where KAFFEE enables in-context Bayesian filtering while largely preserving zero-shot dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify a dynamic-probabilistic consistency (DPC) gap in dynamical systems reconstruction for chaotic systems, where open-loop Gaussian rollout objectives degrade dynamics or decouple uncertainty via three mechanisms (core collapse, noise masking, blind uncertainty). It proposes KAFFEE, a differentiable extended Kalman filter training framework using innovations likelihood and learned local Jacobians for covariance transport. Experiments reportedly show reduced failure modes and improved dynamical invariants on stochastic hyperchaotic Lorenz-96, plus better preservation of zero-shot dynamics when adapting a foundation model across 13 systems.
Significance. If the central claim holds, the work identifies a practically relevant inconsistency between probabilistic training objectives and chaotic dynamics that affects uncertainty-aware surrogate modeling. The KAFFEE approach offers a concrete, differentiable mechanism to enforce consistency via EKF-style innovations, which could improve reliability of long-horizon predictions and invariant preservation in scientific applications of DSR.
major comments (2)
- [Section describing KAFFEE and its EKF implementation] The central claim that KAFFEE closes the DPC gap rests on the assumption that learned local Jacobians in the differentiable EKF transport covariance consistently with the tangent dynamics. No direct diagnostic (e.g., comparison of propagated covariance to local Lyapunov structure or ensemble statistics beyond training horizon) is provided for the hyperchaotic Lorenz-96 case, leaving the causal link between the innovations objective and the reported improvements unverified.
- [Experimental results on stochastic hyperchaotic Lorenz-96] The isolation of the three mechanisms (core collapse, noise masking, blind uncertainty) and their attribution to open-loop Gaussian rollouts is load-bearing for the motivation. The experimental section reports overall improvements but lacks targeted ablations or metrics that separately quantify each mechanism's reduction under KAFFEE versus baselines.
minor comments (2)
- [Abstract] The abstract states that KAFFEE 'maintains competitive predictive scores' but does not specify the exact scores or baselines used for comparison.
- [Methods] Notation for the innovation covariance and how the likelihood is evaluated on local predictive residuals should be made explicit with an equation reference.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript accordingly to strengthen the evidence.
read point-by-point responses
-
Referee: [Section describing KAFFEE and its EKF implementation] The central claim that KAFFEE closes the DPC gap rests on the assumption that learned local Jacobians in the differentiable EKF transport covariance consistently with the tangent dynamics. No direct diagnostic (e.g., comparison of propagated covariance to local Lyapunov structure or ensemble statistics beyond training horizon) is provided for the hyperchaotic Lorenz-96 case, leaving the causal link between the innovations objective and the reported improvements unverified.
Authors: We agree that a direct diagnostic would provide stronger verification of covariance transport consistency with tangent dynamics. The current manuscript supports the claim via theoretical derivation of the DPC gap and empirical improvements in invariants and failure modes. In revision we will add a diagnostic comparing EKF-propagated covariance growth against the local Lyapunov spectrum computed from the learned Jacobians, plus ensemble statistics on the hyperchaotic Lorenz-96 case. revision: yes
-
Referee: [Experimental results on stochastic hyperchaotic Lorenz-96] The isolation of the three mechanisms (core collapse, noise masking, blind uncertainty) and their attribution to open-loop Gaussian rollouts is load-bearing for the motivation. The experimental section reports overall improvements but lacks targeted ablations or metrics that separately quantify each mechanism's reduction under KAFFEE versus baselines.
Authors: The three mechanisms are isolated via theoretical analysis of open-loop Gaussian objectives in chaotic systems. Experiments demonstrate overall reduction in associated failure modes under KAFFEE. We acknowledge the value of separate quantification and will add targeted ablations in revision, including Jacobian-norm statistics for core collapse, calibration metrics for noise masking, and variance analysis for blind uncertainty. revision: yes
Circularity Check
No circularity: derivation relies on empirical evaluation of proposed framework on external benchmarks
full rationale
The paper defines the dynamic-probabilistic consistency gap conceptually, identifies mechanisms via analysis of open-loop objectives, and introduces KAFFEE as a differentiable EKF-based alternative. All reported improvements (on stochastic Lorenz-96 and 13-system adaptation) are measured against standard chaotic benchmarks using independent metrics for dynamical invariants and predictive scores. No equations, fitted parameters, or self-citations are shown reducing any central claim to its own inputs by construction; the framework and gap analysis remain self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Local linear approximations via Jacobians are sufficient to transport covariance in the training objective for chaotic systems.
Reference graph
Works this paper leans on
-
[1]
D Durstewitz, G Koppe, and M. I Thurm. Reconstructing computational system dynamics from neural data with recurrent neural networks.Nature Reviews Neuroscience, 24(11):693–710, 2023
2023
-
[2]
Generalized Teacher Forcing for Learning Chaotic Dynamics
F Hess, Z Monfared, M Brenner, and D Durstewitz. Generalized Teacher Forcing for Learning Chaotic Dynamics. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 202 ofProceedings of Machine Learning Research, pages 13017–13049, 2023
2023
-
[4]
Out-of-Domain Generalization in Dynamical Systems Reconstruction
N Göring, F Hess, M Brenner, Z Monfared, and D Durstewitz. Out-of-Domain Generalization in Dynamical Systems Reconstruction. InProceedings of the 41st International Conference on Machine Learning, ICML’24, 2024
2024
-
[5]
Invariant Measures in Time-Delay Coordinates for Unique Dynamical System Identification.Phys
J Botvinick-Greenhouse, R Martin, and Y Yang. Invariant Measures in Time-Delay Coordinates for Unique Dynamical System Identification.Phys. Rev. Lett., 135(16):167202, 2025
2025
-
[6]
Y Lu, E Orlova, and R Willett
R Jiang, P. Y Lu, E Orlova, and R Willett. Training neural operators to preserve invariant measures of chaotic attractors. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, 2023
2023
-
[7]
Reconstructing bifurcation diagrams of chaotic circuits with reservoir computing.Phys
H Luo, Y Du, H Fan, X Wang, J Guo, and X Wang. Reconstructing bifurcation diagrams of chaotic circuits with reservoir computing.Phys. Rev. E, 109(2):024210, 2024
2024
-
[8]
T Yang, and N Chandramoorthy
J Park, N. T Yang, and N Chandramoorthy. When are dynamical systems learned from time series data statistically accurate? InAdvances in Neural Information Processing Systems, volume 37, pages 43975–44008, 2024
2024
-
[9]
Y Wan, J
Y Schiff, Z. Y Wan, J. B Parker, S Hoyer, V Kuleshov, F Sha, and L Zepeda-Núñez. DySLIM: Dynamics stable learning by invariant measure for chaotic systems. InProceedings of the 41st International Conference on Machine Learning, ICML’24, 2024
2024
-
[10]
A Gottwald and S Reich
G. A Gottwald and S Reich. Supervised learning from noisy observations: Combining machine-learning techniques with data assimilation.Physica D: Nonlinear Phenomena, 423:132911, 2021. ISSN 01672789. 10
2021
-
[11]
F Psaros, X Meng, Z Zou, L Guo, and G
A. F Psaros, X Meng, Z Zou, L Guo, and G. E Karniadakis. Uncertainty quantification in scientific machine learning: Methods, metrics, and comparisons.Journal of Computational Physics, 477:111902, 2023. ISSN 00219991
2023
-
[12]
Cambridge University Press, 1 edition, 2015
S Reich and C Cotter.Probabilistic Forecasting and Bayesian Data Assimilation. Cambridge University Press, 1 edition, 2015. ISBN 978-1-107-06939-8 978-1-107-66391-6 978-1-107-70680-4
2015
-
[13]
On the Kalman filter error covariance collapse into the unstable subspace
A Trevisan and L Palatella. On the Kalman filter error covariance collapse into the unstable subspace. Nonlinear Processes in Geophysics, 18(2):243–250, 2011
2011
-
[14]
D. J. C MacKay. Bayesian interpolation.Neural Comput., 4(3):415–447, 1992. ISSN 0899-7667
1992
-
[15]
E Rasmussen and C
C. E Rasmussen and C. K. I Williams.Gaussian Processes for Machine Learning. MIT Press, Cambridge, MA, 2006
2006
-
[16]
P Eckmann and D Ruelle
J. P Eckmann and D Ruelle. Ergodic theory of chaos and strange attractors.Rev. Mod. Phys., 57(3): 617–656, 1985
1985
-
[17]
Data Assimilation for Chaotic Dynamics
A Carrassi, M Bocquet, J Demaeyer, C Grudzien, P Raanes, and S Vannitsem. Data Assimilation for Chaotic Dynamics. In S. K Park and L Xu, editors,Data Assimilation for Atmospheric, Oceanic and Hydrologic Applications (Vol. IV), pages 1–42. Springer International Publishing, Cham, 2022. ISBN 978-3-030-77721-0 978-3-030-77722-7
2022
-
[18]
J Hemmer and D Durstewitz
C. J Hemmer and D Durstewitz. True Zero-Shot Inference of Dynamical Systems Preserving Long-Term Statistics. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[19]
B Lai, A Bao, and W Gilpin
J. B Lai, A Bao, and W Gilpin. Panda: A pretrained forecast model for chaotic dynamics. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[20]
Position: A Dynamical Systems Perspective is Needed to Advance Time Series Modeling
C Liu, B Zhao, J Ding, and Y Li. ChaosNexus: A Foundation Model for ODE-based Chaotic System Forecasting with Hierarchical Multi-scale Awareness.arXiv preprint arXiv:2602.16864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Computational aspects of maximum likelihood estimation and reduction in sensitivity function calculations.IEEE Transactions on Automatic Control, 19(6):774–783, 1974
N Gupta and R Mehra. Computational aspects of maximum likelihood estimation and reduction in sensitivity function calculations.IEEE Transactions on Automatic Control, 19(6):774–783, 1974. ISSN 0018-9286
1974
-
[22]
Parameter estimation in non-linear state-space models by automatic differentiation of non-linear kalman filters
A Gorad, Z Zhao, and S Särkkä. Parameter estimation in non-linear state-space models by automatic differentiation of non-linear kalman filters. In2020 IEEE 30th International Workshop on Machine Learning for Signal Processing (MLSP), pages 1–6, 2020
2020
-
[23]
Institute of Mathematical Statistics Textbooks
S Särkkä and L Svensson.Bayesian Filtering and Smoothing. Institute of Mathematical Statistics Textbooks. Cambridge University Press, second edition, 2023
2023
-
[24]
Sigma-point filtering and smoothing based parameter estimation in nonlinear dynamic systems.Journal of advances in information fusion, 11(1):15, 2016
J Kokkala, A Solin, and S Särkkä. Sigma-point filtering and smoothing based parameter estimation in nonlinear dynamic systems.Journal of advances in information fusion, 11(1):15, 2016
2016
-
[25]
Backprop KF: Learning discriminative deterministic state estimators
T Haarnoja, A Ajay, S Levine, and P Abbeel. Backprop KF: Learning discriminative deterministic state estimators. InProceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, pages 4383–4391, 2016
2016
-
[26]
C Tanoh, M Deistler, J
I. C Tanoh, M Deistler, J. H Macke, and S Linderman. Identifying multi-compartment Hodgkin-Huxley models with high-density extracellular voltage recordings. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[27]
N Lorenz
E. N Lorenz. Predictability: A problem partly solved. InProc. Seminar on Predictability, Reading, UK, ECMWF, volume 1, pages 1–18, 1996
1996
-
[28]
Bifurcations in the Learning of Recurrent Neural Networks
K Doya. Bifurcations in the Learning of Recurrent Neural Networks. InProceedings of the 1992 IEEE International Symposium on Circuits and Systems, 1992
1992
-
[29]
A framework for machine learning of model error in dynamical systems
M Levine and A Stuart. A framework for machine learning of model error in dynamical systems. Communications of the American Mathematical Society, 2(7):283–344, 2022. ISSN 2692-3688
2022
-
[30]
Scheduled sampling for sequence prediction with recurrent Neural networks
S Bengio, O Vinyals, N Jaitly, and N Shazeer. Scheduled sampling for sequence prediction with recurrent Neural networks. InProceedings of the 29th International Conference on Neural Information Processing Systems - Volume 1, NIPS’15, pages 1171–1179, 2015
2015
-
[31]
Sequence Level Training with Recurrent Neural Networks
M Ranzato, S Chopra, M Auli, and W Zaremba. Sequence Level Training with Recurrent Neural Networks. In4th International Conference on Learning Representations, ICLR 2016, 2016. 11
2016
-
[32]
Continuous-time system identification with neural networks: Model structures and fitting criteria.European Journal of Control, 59:69–81, 2021
M Forgione and D Piga. Continuous-time system identification with neural networks: Model structures and fitting criteria.European Journal of Control, 59:69–81, 2021
2021
-
[33]
Nonlinear state-space identification using deep encoder networks
G Beintema, R Toth, and M Schoukens. Nonlinear state-space identification using deep encoder networks. InProceedings of the 3rd Conference on Learning for Dynamics and Control, volume 144 ofProceedings of Machine Learning Research, pages 241–250, 2021
2021
-
[34]
I Beintema, M Schoukens, and R Tóth
G. I Beintema, M Schoukens, and R Tóth. Deep subspace encoders for nonlinear system identification. Automatica, 156(C), 2023. ISSN 0005-1098
2023
-
[35]
E Rasmussen, and R Murray-Smith
A Girard, C. E Rasmussen, and R Murray-Smith. Multiple-step ahead prediction for non linear dynamic systems–a Gaussian process treatment with propagation of the uncertainty. InSixteenth Annual Conference on Neural Information Processing Systems, volume 15, pages 529–536, 2002
2002
-
[36]
Probabilistic recurrent state-space models
A Doerr, C Daniel, M Schiegg, N.-T Duy, S Schaal, M Toussaint, and T Sebastian. Probabilistic recurrent state-space models. InInternational Conference on Machine Learning, pages 1280–1289, 2018
2018
-
[37]
Revisiting structured variational autoencoders
Y Zhao and S Linderman. Revisiting structured variational autoencoders. InInternational Conference on Machine Learning, pages 42046–42057, 2023
2023
-
[38]
M Mikhaeil, L
M Brenner, F Hess, J. M Mikhaeil, L. F Bereska, Z Monfared, P.-C Kuo, and D Durstewitz. Tractable Dendritic RNNs for Reconstructing Nonlinear Dynamical Systems. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, 2022
2022
-
[39]
E Turner and M Sahani
R. E Turner and M Sahani. Two problems with variational expectation maximisation for time series models. InBayesian Time Series Models, pages 104–124. Cambridge University Press, 2011. ISBN 978-0-511-98467-9
2011
-
[40]
Mind the Gap when Conditioning Amortised Inference in Sequential Latent-Variable Models
J Bayer, M Soelch, A Mirchev, B Kayalibay, and P van der Smagt. Mind the Gap when Conditioning Amortised Inference in Sequential Latent-Variable Models. InInternational Conference on Learning Representations, 2021
2021
-
[41]
A Fuller.Measurement Error Models
W. A Fuller.Measurement Error Models. Wiley Series in Probability and Statistics. John Wiley & Sons, New York, 1987
1987
-
[42]
P Buonaccorsi
J Staudenmayer and J. P Buonaccorsi. Measurement Error in Linear Autoregressive Models.Journal of the American Statistical Association, 100(471):841–852, 2005. ISSN 01621459
2005
-
[43]
M Mikhaeil, Z Monfared, and D Durstewitz
J. M Mikhaeil, Z Monfared, and D Durstewitz. On the difficulty of learning chaotic dynamics with RNNs. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, 2022
2022
-
[44]
E Sa˘gtekin, C Bredenberg, and C Savin
A. E Sa˘gtekin, C Bredenberg, and C Savin. Error Forcing in Recurrent Neural Networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[45]
A Herz, D Durstewitz, and G Koppe. Teacher Forcing as Generalized Bayes: Optimization Geometry Mismatch in Switching Surrogates for Chaotic Dynamics.arXiv preprint arXiv:2604.25904, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Identifying nonlinear dynamical systems via generative recurrent neural networks with applications to fMRI.PLOS Computational Biology, 15(8):1–35, 2019
G Koppe, H Toutounji, P Kirsch, S Lis, and D Durstewitz. Identifying nonlinear dynamical systems via generative recurrent neural networks with applications to fMRI.PLOS Computational Biology, 15(8):1–35, 2019
2019
-
[47]
J Hemmer, Z Monfared, and D Durstewitz
M Brenner, C. J Hemmer, Z Monfared, and D Durstewitz. Almost-Linear RNNs Yield Highly Interpretable Symbolic Codes in Dynamical Systems Reconstruction. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[48]
N Lorenz
E. N Lorenz. Deterministic Nonperiodic Flow.Journal of the Atmospheric Sciences, 20(2):130–141, 1963
1963
-
[49]
V Sip, M Breyton, S Petkoski, and V Jirsa. Double projection for reconstructing dynamical systems: Between stochastic and deterministic regimes.arXiv preprint arXiv:2510.01089, 2026
-
[50]
L Wong, R
X Li, T.-K. L Wong, R. T. Q Chen, and D Duvenaud. Scalable Gradients for Stochastic Differential Equations. InProceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 3870–3882, 2020
2020
-
[51]
Data assimilation in the geosciences: An overview of methods, issues, and perspectives.WIREs Climate Change, 9(5):e535, 2018
A Carrassi, M Bocquet, L Bertino, and G Evensen. Data assimilation in the geosciences: An overview of methods, issues, and perspectives.WIREs Climate Change, 9(5):e535, 2018. ISSN 1757-7780, 1757-7799. 12
2018
-
[52]
Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: A case study with the Lorenz 96 model
J Brajard, A Carrassi, M Bocquet, and L Bertino. Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: A case study with the Lorenz 96 model. Journal of Computational Science, 44:101171, 2020. ISSN 18777503
2020
-
[53]
Online learning of both state and dynamics using ensemble Kalman filters.Foundations of Data Science, 3(3):305–330, 2021
M Bocquet, A Farchi, and Q Malartic. Online learning of both state and dynamics using ensemble Kalman filters.Foundations of Data Science, 3(3):305–330, 2021. ISSN 2639-8001
2021
-
[54]
A comparison of combined data assimilation and machine learning methods for offline and online model error correction.Journal of Computational Science, 55:101468, 2021
A Farchi, M Bocquet, P Laloyaux, M Bonavita, and Q Malartic. A comparison of combined data assimilation and machine learning methods for offline and online model error correction.Journal of Computational Science, 55:101468, 2021. ISSN 18777503
2021
-
[55]
S Finn, C Durand, S Cheng, Y Chen, I Pasmans, and A Carrassi
M Bocquet, A Farchi, T. S Finn, C Durand, S Cheng, Y Chen, I Pasmans, and A Carrassi. Accurate deep learning-based filtering for chaotic dynamics by identifying instabilities without an ensemble.Chaos: An Interdisciplinary Journal of Nonlinear Science, 34(9):091104, 2024. ISSN 1054-1500, 1089-7682
2024
-
[56]
M Adrian, D Sanz-Alonso, and R Willett. Auto-differentiable data assimilation: Co-learning of states, dynamics, and filtering algorithms.arXiv preprint arXiv:2603.20891, 2026
-
[57]
Probabilistic Retrofitting of Learned Simulators
C Diaconu, M Cranmer, R. E Turner, T Marwah, and P Mukhopadhyay. Probabilistic Retrofitting of Learned Simulators.arXiv preprint arXiv:2603.01949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
E Sa˘gtekin, F Pei, M Gloeckler, and J Macke
M Pals, A. E Sa˘gtekin, F Pei, M Gloeckler, and J Macke. Inferring stochastic low-rank recurrent neural networks from neural data. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), volume 37, pages 18225–18264, 2024
2024
-
[59]
A Wan and R Van Der Merwe
E. A Wan and R Van Der Merwe. The unscented Kalman filter for nonlinear estimation. InProceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No. 00EX373), pages 153–158, 2000
2000
-
[60]
The ensemble Kalman filter: Theoretical formulation and practical implementation.Ocean Dynamics, 53(4):343–367, 2003
G Evensen. The ensemble Kalman filter: Theoretical formulation and practical implementation.Ocean Dynamics, 53(4):343–367, 2003
2003
-
[61]
Rao–Blackwellised Particle Filtering for Dynamic Bayesian Networks
A Doucet, N de Freitas, K Murphy, and S Russell. Rao–Blackwellised Particle Filtering for Dynamic Bayesian Networks. InProceedings of the 16th Conference on Uncertainty in Artificial Intelligence (UAI), 2000
2000
-
[62]
Y Zhao and I. M Park. Variational online learning of neural dynamics.Frontiers in computational neuroscience, 14:71, 2020
2020
-
[63]
M Dowling, Y Zhao, and I. M Park. eXponential FAmily dynamical systems (XFADS): Large-scale nonlinear gaussian state-space modeling.Advances in Neural Information Processing Systems, 37:13458– 13488, 2024
2024
-
[64]
Integrating Multimodal Data for Joint Generative Modeling of Complex Dynamics
M Brenner, F Hess, G Koppe, and D Durstewitz. Integrating Multimodal Data for Joint Generative Modeling of Complex Dynamics. InProceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[65]
G Chang, K
P. G Chang, K. P Murphy, and M Jones. On diagonal approximations to the extended Kalman filter for online training of Bayesian neural networks. InContinual Lifelong Learning Workshop at ACML 2022, 2022
2022
-
[66]
G Chang, G Durán-Martín, A Shestopaloff, M Jones, and K
P. G Chang, G Durán-Martín, A Shestopaloff, M Jones, and K. P Murphy. Low-rank extended Kalman filtering for online learning of neural networks from streaming data. In S Chandar, R Pascanu, H Sedghi, and D Precup, editors,Proceedings of The 2nd Conference on Lifelong Learning Agents, volume 232 of Proceedings of Machine Learning Research, pages 1025–1071, 2023
2023
-
[67]
The Rank-Reduced Kalman Filter: Approximate Dynamical- Low-Rank Filtering In High Dimensions
J Schmidt, P Hennig, J Nick, and F Tronarp. The Rank-Reduced Kalman Filter: Approximate Dynamical- Low-Rank Filtering In High Dimensions. InThirty-Seventh Conference on Neural Information Processing Systems, 2023
2023
-
[68]
Chaotic dynamics and the role of covariance inflation for reduced rank Kalman filters with model error.Nonlinear Processes in Geophysics, 25(3):633–648, 2018
C Grudzien, A Carrassi, and M Bocquet. Chaotic dynamics and the role of covariance inflation for reduced rank Kalman filters with model error.Nonlinear Processes in Geophysics, 25(3):633–648, 2018. ISSN 1607-7946
2018
-
[69]
H Jazwinski.Stochastic Processes and Filtering Theory, volume 64 ofMathematics in Science and Engineering
A. H Jazwinski.Stochastic Processes and Filtering Theory, volume 64 ofMathematics in Science and Engineering. Elsevier, 1970. ISBN 978-0-12-381550-7
1970
-
[70]
Variational Sequential Monte Carlo
C Naesseth, S Linderman, R Ranganath, and D Blei. Variational Sequential Monte Carlo. InProceed- ings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning Research, 2018. 13
2018
-
[71]
A Le, M Igl, T Rainforth, T Jin, and F Wood
T. A Le, M Igl, T Rainforth, T Jin, and F Wood. Auto-Encoding Sequential Monte Carlo. InInternational Conference on Learning Representations, 2018
2018
-
[72]
J Maddison, J Lawson, G Tucker, N Heess, M Norouzi, A Mnih, A Doucet, and Y Teh
C. J Maddison, J Lawson, G Tucker, N Heess, M Norouzi, A Mnih, A Doucet, and Y Teh. Filtering Variational Objectives. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[73]
Stochastic stability of the discrete-time extended Kalman filter.IEEE Transactions on Automatic Control, 44(4):714–728, 1999
K Reif, S Gunther, E Yaz, and R Unbehauen. Stochastic stability of the discrete-time extended Kalman filter.IEEE Transactions on Automatic Control, 44(4):714–728, 1999. ISSN 00189286
1999
-
[74]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y Bengio, N Léonard, and A Courville. Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[75]
Gaussian Error Linear Units (GELUs)
D Hendrycks and K Gimpel. Gaussian Error Linear Units (GELUs).arXiv preprint arXiv:1606.08415, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Adam: A Method for Stochastic Optimization
D. P Kingma and J Ba. Adam: A Method for Stochastic Optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[77]
On the Variance of the Adaptive Learning Rate and Beyond
L Liu, H Jiang, P He, W Chen, X Liu, J Gao, and J Han. On the Variance of the Adaptive Learning Rate and Beyond. InInternational Conference on Learning Representations, 2020
2020
-
[78]
R Hershey and P
J. R Hershey and P. A Olsen. Approximating the Kullback Leibler Divergence Between Gaussian Mixture Models. In2007 IEEE International Conference on Acoustics, Speech and Signal Processing - ICASSP ’07, pages IV–317–IV–320, 2007
2007
-
[79]
Lyapunov Characteristic Exponents for smooth dynamical systems and for hamiltonian systems; a method for computing all of them
G Benettin, L Galgani, A Giorgilli, and J.-M Strelcyn. Lyapunov Characteristic Exponents for smooth dynamical systems and for hamiltonian systems; a method for computing all of them. Part 1: Theory. Meccanica, 15(1):9–20, 1980. ISSN 0025-6455, 1572-9648
1980
-
[80]
Comparison of Different Methods for Computing Lyapunov Exponents.Progress of Theoretical Physics, 83(5):875–893, 1990
K Geist, U Parlitz, and W Lauterborn. Comparison of Different Methods for Computing Lyapunov Exponents.Progress of Theoretical Physics, 83(5):875–893, 1990. ISSN 0033-068X
1990
-
[81]
perfect surrogate model
W Gilpin. Chaos as an interpretable benchmark for forecasting and data-driven modelling. InAdvances in Neural Information Processing Systems, volume 34, 2021. 14 A Theory Details and Proofs This section supplements the theory in the main text: the proof of volume pressure localization, a noisy-state attenuation diagnostic, and the anti-contractive mechani...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.