Semantic Triplet Restoration: A Novel Protocol for Hierarchical Table Understanding in Large Language Models
Pith reviewed 2026-06-28 22:18 UTC · model grok-4.3
The pith
Semantic triplets restore table hierarchy for LLMs and reduce input tokens versus HTML.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
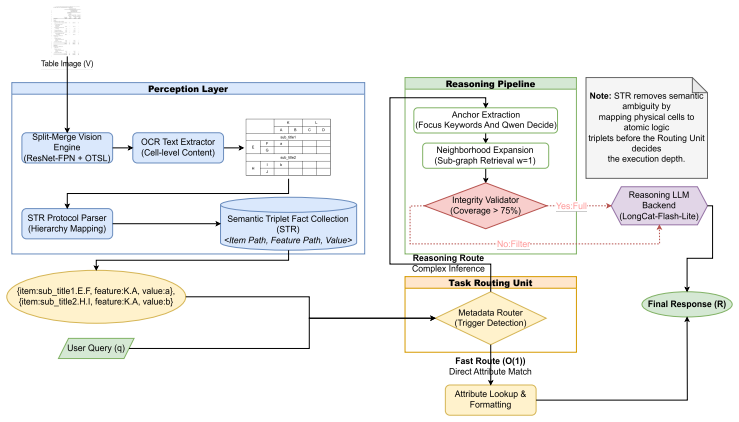
The paper establishes that rewriting each cell as an explicit semantic triplet consisting of an item path for the row-wise entity, a feature path for the hierarchical attribute, and the cell value allows large language models to recover implicit hierarchical relations without the overhead of layout markup, and that a query-aware router can select appropriate renderings or filtered subsets to achieve performance that matches or exceeds HTML-based methods on table question answering while lowering token counts.
What carries the argument
Semantic Triplet Restoration protocol that converts cells to <item path, feature path, value> triplets together with the TripletQL query-aware router for selecting renderings.
If this is right
- STR matches or exceeds HTML baselines on four table-QA benchmarks in Chinese and English.
- STR uses fewer input tokens than HTML representations of the same tables.
- The token and accuracy benefits of STR increase as model size decreases.
- The benefits of STR increase as table context length increases.
Where Pith is reading between the lines
- The triplet format may allow direct integration with semantic parsers that operate on path-like structures rather than markup.
- Smaller models deployed under token budgets could become viable for table tasks that currently require larger models.
- The approach might generalize to other grid-like or hierarchical data such as forms or spreadsheets if the same path-based encoding is applied.
Load-bearing premise
Converting cells to item-path feature-path value triplets preserves all necessary hierarchical and alignment information without loss, and TripletQL can choose renderings without introducing new errors or omissions.
What would settle it
An evaluation on a held-out table-QA benchmark where the triplet method produces lower accuracy than an HTML baseline on the same questions despite using comparable or fewer tokens.
Figures







read the original abstract
Table question answering requires models to recover semantic relations encoded implicitly by two-dimensional layout, merged cells, and hierarchical headers. Current pipelines typically use HTML or Markdown as intermediate table representations, but these layout-oriented serializations introduce markup overhead and require large language models to infer header-cell alignments from row and column spans. We propose Semantic Triplet Restoration (STR), a protocol that rewrites each cell as an atomic fact <item path, feature path, value>, where the item path specifies the row-wise entity, the feature path specifies the hierarchical attribute, and the value contains the cell content. We also present TripletQL, a lightweight query-aware router that uses STR to select an appropriate rendering or filtered subset of triplets for each question. Across four Chinese and English table-QA benchmarks, STR matches or improves upon HTML-based baselines while reducing input tokens. The relative benefit grows for smaller language models and longer table contexts, suggesting that explicit semantic representations are especially useful under constrained inference budgets. Code and data are available at https://github.com/Phoenix-ni/STR.git .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Semantic Triplet Restoration (STR), a protocol that rewrites each table cell as an atomic triplet <item path, feature path, value> to explicitly encode row-wise entities and hierarchical attributes, along with TripletQL, a lightweight query-aware router that selects renderings or filtered subsets. The central empirical claim is that STR matches or exceeds HTML-based baselines across four Chinese and English table-QA benchmarks while reducing input tokens, with relative gains increasing for smaller language models and longer table contexts.
Significance. If the results hold after verification of the representation rules and experimental details, the approach could provide a more token-efficient alternative to layout-oriented serializations for hierarchical table understanding, particularly under constrained inference budgets. The public release of code and data at the cited GitHub repository is a clear strength that aids reproducibility.
major comments (2)
- [Abstract] Abstract: performance results on four benchmarks are stated without any description of experimental setup, baselines, error bars, or statistical tests. This prevents verification of whether the data support the claimed improvements and is load-bearing for the paper's primary contribution.
- [STR protocol description] The construction rules for item paths and feature paths (especially under merged cells, row/column spans, and multi-level headers) are not provided. The central claim that the triplet format preserves all necessary hierarchical alignments and semantics without loss (required to attribute gains to the representation rather than TripletQL or model behavior) cannot be evaluated without these rules.
minor comments (1)
- Notation for the triplet format is introduced clearly in the abstract but would benefit from an explicit example table showing path construction for a merged cell.
Simulated Author's Rebuttal
We thank the referee for these constructive comments. We address each major point below and will revise the manuscript accordingly to improve verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: performance results on four benchmarks are stated without any description of experimental setup, baselines, error bars, or statistical tests. This prevents verification of whether the data support the claimed improvements and is load-bearing for the paper's primary contribution.
Authors: We agree that the abstract lacks sufficient experimental context. In the revised manuscript we will expand the abstract to briefly name the four benchmarks, note the HTML baselines, and indicate that results report means with standard deviations from multiple runs along with statistical tests detailed in Section 4. revision: yes
-
Referee: [STR protocol description] The construction rules for item paths and feature paths (especially under merged cells, row/column spans, and multi-level headers) are not provided. The central claim that the triplet format preserves all necessary hierarchical alignments and semantics without loss (required to attribute gains to the representation rather than TripletQL or model behavior) cannot be evaluated without these rules.
Authors: We acknowledge that the current manuscript does not supply explicit construction rules for item and feature paths under merged cells, spans, or multi-level headers. We will add a dedicated subsection with formal rules and examples for these cases to demonstrate semantic preservation and to support attribution of gains to the triplet representation. revision: yes
Circularity Check
No circularity: empirical protocol evaluated on external benchmarks
full rationale
The paper defines STR as a rewriting protocol into <item path, feature path, value> triplets and TripletQL as a selection router, then reports empirical results on four table-QA benchmarks. No equations, fitted parameters, or derivations are present that reduce a claimed prediction to the input representation by construction. The performance claim is tested against external HTML baselines rather than being forced by the definition of the triplet format itself. Any self-citations (none visible in the provided text) would not be load-bearing for the central empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The triplet format <item path, feature path, value> captures all relevant hierarchical semantic relations present in the original table layout.
invented entities (2)
-
Semantic Triplet Restoration (STR) protocol
no independent evidence
-
TripletQL router
no independent evidence
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Boming Chen, Zining Wang, Zhentao Guo, Jianqiang Liu, Chen Duan, Yu Gu, Kai Zhou, and Pengfei Yan. 2026. https://arxiv.org/abs/2604.02880 Instructtable: Improving table structure recognition through instructions . arXiv preprint arXiv:2604.02880
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. 2020. https://arxiv.org/abs/1909.02164 Tabfact: A large-scale dataset for table-based fact verification . In Proceedings of the International Conference on Learning Representations (ICLR)
-
[5]
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, Yue Zhang, Yubo Zhang, Handong Zheng, Jing Zhang, Jun Zhang, Yi Liu, Dianhai Yu, and Yanjun Ma. 2025. https://arxiv.org/abs/2510.14528 Paddleocr-vl: Boosting multilingual document parsing via a 0.9b ultra-compact vision-language mo...
-
[6]
Jonathan Herzig, Pawel Krzysztof Nowak, Thomas M \"u ller, Francesco Piccinno, and Julian Eisenschlos. 2020. https://aclanthology.org/2020.acl-main.398/ TAPAS : Weakly supervised table parsing via pre-training . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 4320--4333
2020
- [7]
- [8]
- [9]
- [10]
-
[11]
Zhang Li, Yuliang Liu, Qiang Liu, Zhiyin Ma, Ziyang Zhang, Shuo Zhang, Biao Yang, Zidun Guo, Jiarui Zhang, Xinyu Wang, and Xiang Bai. 2025. https://arxiv.org/abs/2506.05218 Monkeyocr: Document parsing with a structure-recognition-relation triplet paradigm . Preprint, arXiv:2506.05218
-
[12]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://aclanthology.org/2024.tacl-1.9/ Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
2024
-
[13]
Alfonso Ure \ n a-L \'o pez, Eugenio Mart \'i nez C \'a mara, and Jose Camacho-Collados
Jorge Os \'e s Grijalba, L. Alfonso Ure \ n a-L \'o pez, Eugenio Mart \'i nez C \'a mara, and Jose Camacho-Collados. 2024. https://aclanthology.org/2024.lrec-main.1179/ Question answering over tabular data with D ata B ench: A large-scale empirical evaluation of LLM s . In Proceedings of the 2024 Joint International Conference on Computational Linguistics...
2024
-
[14]
Panupong Pasupat and Percy Liang. 2015. https://aclanthology.org/P15-1146/ Compositional semantic parsing on semi-structured tables . In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP), pages 1470--1480
2015
- [15]
-
[16]
Zipeng Qiu, You Peng, Guangxin He, Binhang Yuan, and Chen Wang. 2024. https://arxiv.org/abs/2411.19504 TQA-Bench : Evaluating LLM s for multi-table question answering with scalable context and symbolic extension . arXiv preprint arXiv:2411.19504
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Sahil Sen, Akhil Kasturi, Elias Lumer, Anmol Gulati, and Vamse Kumar Subbiah. 2026. https://arxiv.org/abs/2605.15184 Is Grep all you need? how agent harnesses reshape agentic search . arXiv preprint arXiv:2605.15184
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Yuan Sui, Mengyu Zhou, Mingjie Zhou, Shi Han, and Dongmei Zhang. 2024. https://doi.org/10.1145/3616855.3635831 Table meets LLM : Can large language models understand structured table data? a benchmark and empirical study . In Proceedings of the 17th ACM International Conference on Web Search and Data Mining (WSDM '24), pages 645--654. ACM. ArXiv preprint ...
-
[19]
Rishit Tyagi, Mohit Gupta, and Rahul Bouri. 2025. https://aclanthology.org/2025.semeval-1.292/ A estar at S em E val-2025 task 8: Agentic LLM s for question answering over tabular data . In Proceedings of the 19th International Workshop on Semantic Evaluation (SemEval-2025), pages 2249--2255, Vienna, Austria. Association for Computational Linguistics
2025
-
[20]
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, Bo Zhang, Liqun Wei, Zhihao Sui, Wei Li, Botian Shi, Yu Qiao, Dahua Lin, and Conghui He. 2024. https://arxiv.org/abs/2409.18839 Mineru: An open-source solution for precise document content extraction . Preprint, arXiv:2409.18839
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, and Tianzhen Sun. 2025. https://ojs.aaai.org/index.php/AAAI/article/view/33979 Tablebench: A comprehensive and complex benchmark for table question answering . In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25497--25506
2025
-
[22]
Jingfeng Yang, Aditya Gupta, Shyam Upadhyay, Luheng He, Rahul Goel, and Shachi Paul. 2022. https://aclanthology.org/2022.acl-long.40/ TableFormer : Robust transformer modeling for table-text encoding . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), pages 528--537
2022
-
[23]
Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel. 2020. https://aclanthology.org/2020.acl-main.745/ TaBERT : Pretraining for joint understanding of textual and tabular data . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), pages 8413--8426
2020
-
[24]
Yitong Zhou, Mingyue Cheng, Qingyang Mao, Jiahao Wang, Feiyang Xu, and Xin Li. 2025. https://arxiv.org/abs/2412.20662 Enhancing table recognition with vision LLM s: A benchmark and neighbor-guided toolchain reasoner . In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence (IJCAI-25), pages 2503--2511. International J...
- [25]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.