Language Models Learn Constructional Semantics, Not To Mention Syntax: Investigating LM Understanding of Paired-Focus Constructions
Pith reviewed 2026-06-28 22:02 UTC · model grok-4.3
The pith
Modestly sized language models grasp rare paired-focus constructions like 'let alone' and link them to world knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
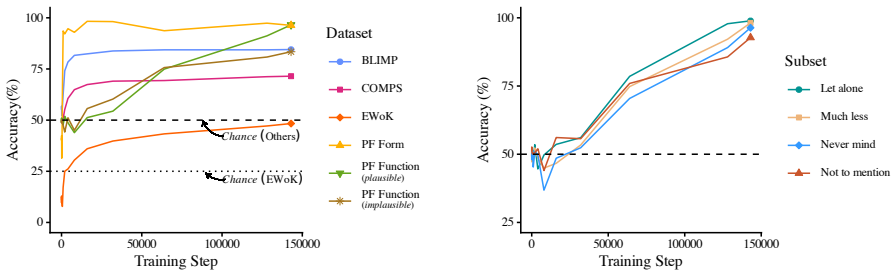
Modestly sized open-source models are sensitive to both the forms and the meanings of Paired-Focus constructions; semantic understanding emerges later in training than syntactic knowledge and correlates with gains in some domains of world knowledge, while models trained on human-scale data fail at all meaning evaluations.
What carries the argument
A novel dataset that isolates Paired-Focus construction meanings by combining scalar adjectival semantics with general world knowledge; it forces models to apply the construction's specific semantic contribution rather than lexical or surface patterns.
If this is right
- Modestly sized open-source models can acquire understanding of rare constructions without extreme scale.
- Semantic knowledge of Paired-Focus constructions develops after their syntactic patterns during training.
- Acquisition of Paired-Focus semantics tracks improvements in selected world-knowledge domains.
- Models trained only on human-scale data remain unable to handle the meanings of these constructions.
Where Pith is reading between the lines
- The observed link suggests that constructional semantics and factual knowledge may reinforce each other during learning.
- If the correlation is causal, methods that boost general world knowledge could also improve handling of rare constructions.
- The result raises the possibility that similar late-emerging semantic patterns hold for other low-frequency constructions.
Load-bearing premise
The new test items using scalar adjectives and world knowledge actually measure constructional semantic understanding instead of unrelated surface patterns or background facts.
What would settle it
A controlled follow-up in which models that pass the current tests are shown to succeed by relying only on word associations rather than the paired-focus meaning, or in which the reported correlation between construction learning and world-knowledge gains disappears under stricter controls.
Figures




read the original abstract
Grasping the semantics of rare constructions (form-meaning pairings) has been shown to be a challenging problem that has currently only been solved by the largest LLMs. It remains an open question if open-source models have robust constructional understanding, and if so, what learning dynamics underlie the acquisition of this knowledge. Focusing on a set of rare Paired-Focus constructions in English (e.g. "let alone", "much less"), we construct a novel dataset to test their meanings using both scalar adjectival semantics and general world knowledge. Testing a wide range of models differing in parameter count, architecture, and pretraining dataset size, we find that several modestly sized models are sensitive to both the forms and the meanings of Paired-Focus constructions, though models trained on human-scale data fail at all meaning evaluations. Turning to training dynamics for a set of open-checkpoint models, we find that Paired-Focus understanding emerges later in training than Paired-Focus syntactic knowledge, and that learning of Paired-Focus semantics is correlated with gains in some domains of world knowledge. Overall, our empirical results support the conclusion that modestly sized open-source models can grasp the rare Paired-Focus constructions, and demonstrate a connection between knowledge of Paired-Focus constructions and other meaning domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modestly sized open-source language models can grasp the semantics of rare Paired-Focus constructions (e.g., 'let alone', 'much less') via a novel dataset testing scalar adjectival semantics and world knowledge; several such models succeed on both form and meaning, while human-scale-data models fail; Paired-Focus semantics emerges later than syntax during training and correlates with gains in certain world-knowledge domains.
Significance. If the isolation of constructional semantics holds, the work provides empirical evidence that constructional understanding is not limited to the largest models, links it to broader meaning domains via checkpoint analysis, and supplies a reusable dataset for rare constructions.
major comments (2)
- [§3] §3 (Dataset): No control conditions are described that hold scalar adjectives and world-knowledge facts constant while replacing the Paired-Focus connector with a neutral one (e.g., 'and' or 'but'); without these, success on the novel items cannot be attributed to the form-meaning pairing rather than independent scalar or factual reasoning.
- [§4.3] §4.3 (Training Dynamics): The reported correlation between Paired-Focus semantic performance and world-knowledge benchmarks lacks a control correlation with unrelated semantic tasks or a permutation test; this leaves open whether the link is specific or an artifact of overall capability growth.
minor comments (2)
- [Table 1] Table 1 and §2.2: clarify the exact pretraining data sizes labeled 'human-scale' and list the precise model checkpoints used for the dynamics analysis.
- [§4.1] §4.1: report exact item counts per condition and any exclusion criteria for the novel dataset items.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the attribution of our results to constructional semantics. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Dataset): No control conditions are described that hold scalar adjectives and world-knowledge facts constant while replacing the Paired-Focus connector with a neutral one (e.g., 'and' or 'but'); without these, success on the novel items cannot be attributed to the form-meaning pairing rather than independent scalar or factual reasoning.
Authors: We agree that neutral-connector controls would more cleanly isolate the contribution of the Paired-Focus form-meaning pairing. Our current items were constructed so that the scalar ordering and world-knowledge facts are only licensed under the construction (as described in §3), but we acknowledge the referee's point that this is not sufficient without explicit baselines. We will add matched control items using 'and'/'but' in the revised dataset and re-run the model evaluations to quantify the drop in performance. revision: yes
-
Referee: [§4.3] §4.3 (Training Dynamics): The reported correlation between Paired-Focus semantic performance and world-knowledge benchmarks lacks a control correlation with unrelated semantic tasks or a permutation test; this leaves open whether the link is specific or an artifact of overall capability growth.
Authors: The referee is correct that the reported correlations could reflect general capability growth rather than a specific link. While we chose the world-knowledge domains on theoretical grounds (their relevance to scalar reasoning), we did not include unrelated-task controls or permutation tests. In revision we will add (i) correlations against unrelated semantic benchmarks and (ii) a permutation test that shuffles the Paired-Focus scores, to demonstrate specificity. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations
full rationale
The paper reports results from constructing a novel dataset and running model evaluations on Paired-Focus constructions, including correlations with world-knowledge benchmarks and training dynamics. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear; all central claims rest on observed performance metrics that are measured directly rather than reduced to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Test items built from scalar adjectives and world-knowledge facts isolate constructional meaning rather than unrelated surface or factual knowledge.
Reference graph
Works this paper leans on
-
[1]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
A method for studying semantic construal in grammatical constructions with interpretable contex- tual embedding spaces. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 242–261, Toronto, Canada. Association for Computational Lin- guistics. Anne Cocos, Skyler Wharton, Ellie Pavlick, Ma...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
InProceedings of the 58th Annual Meeting of the Association for Computational Lin- guistics, pages 5387–5403, Online
Harnessing the linguistic signal to predict scalar inferences. InProceedings of the 58th Annual Meeting of the Association for Computational Lin- guistics, pages 5387–5403, Online. Association for Computational Linguistics. Wesley Scivetti, Tatsuya Aoyama, Ethan Wilcox, and Nathan Schneider. 2025a. UnpackingLet Alone: Human-scale models generalize to a ra...
2025
-
[3]
InProceedings of the First International Workshop on Construction Grammars and NLP (CxGs+NLP , GURT/SyntaxFest 2023), pages 85–95, Washington, D.C
Construction grammar provides unique in- sight into neural language models. InProceedings of the First International Workshop on Construction Grammars and NLP (CxGs+NLP , GURT/SyntaxFest 2023), pages 85–95, Washington, D.C. Association for Computational Linguistics. Leonie Weissweiler, Valentin Hofmann, Abdullatif Kök- sal, and Hinrich Schütze. 2022. The ...
2023
-
[4]
Seq vs seq: An open suite of paired encoders and decoders.Preprint, arXiv:2507.11412. Bryan Wilkinson and Oates Tim. 2016. A gold standard for scalar adjectives. InProceedings of the Tenth In- ternational Conference on Language Resources and Evaluation (LREC’16), pages 2669–2675, Portorož, Slovenia. European Language Resources Association (ELRA). Xiulin Y...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.