Stateful Online Monitoring Catches Distributed Agent Attacks
Pith reviewed 2026-06-28 21:52 UTC · model grok-4.3
The pith
Stateful monitors that cluster weak signals across many agent transcripts detect distributed attacks 30 percent earlier than single-transcript checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
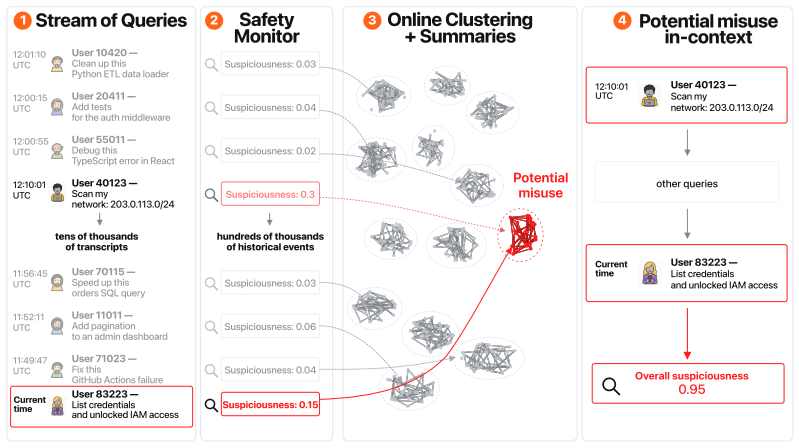
A real-time clustering monitor that aggregates weak suspiciousness signals across many agent transcripts and escalates only rarely to a language model can detect misuse that is distributed across user accounts, catching such attacks 30 percent earlier than standard monitors and flagging them before they reach the most harmful stages while adding negligible additional latency for approximately 99 percent of user traffic.
What carries the argument
real-time clustering of weak suspiciousness signals across many agent transcripts, with rare escalation to a language model for group review
If this is right
- Distributed attacks that split tasks across accounts become detectable even when each separate transcript appears benign.
- Misuse can be identified and stopped before it reaches its most damaging stages.
- The added monitoring imposes negligible latency on the large majority of ordinary user traffic.
- The detection advantage narrows as the volume of benign background traffic grows very large.
- The same monitor also catches ordinary jailbreaks because attackers reuse attack variants across accounts.
Where Pith is reading between the lines
- Organizations running large fleets of agents may need to maintain cross-account signal logs to enable this form of group-level monitoring.
- The approach could be tested on other forms of distributed misuse beyond cybersecurity tasks, such as coordinated content generation or data exfiltration.
- Scaling the clustering step to production volumes will require careful engineering to keep the rare escalation rate low enough to avoid overloading the language-model reviewer.
- Privacy considerations arise when weak signals from many accounts are aggregated, even if only the final escalation step uses full transcripts.
Load-bearing premise
The simulated datacenter traffic used in the evaluation is representative of real user behavior and the clustering step can reliably combine weak signals without excessive false positives or missed attacks when background traffic becomes very large.
What would settle it
Running the clustering monitor on actual production logs containing millions of real accounts and measuring whether false-positive rates rise sharply or coordinated attacks are still missed.
Figures










read the original abstract
Language models can find thousands of severe software vulnerabilities, and agents are increasingly being misused for cyberattacks. To avoid detection, attackers frequently distribute their misuse, splitting a harmful task across many user accounts so each individual transcript looks benign. Because safety monitors score only one agent context at a time, they are structurally blind to misuse that is only visible in aggregate, across many accounts. We show this gap is real by building, to our knowledge, the first distributed agent attack, a multi-agent scaffold that completes hard cybersecurity tasks while hiding the harmful objective across subagents with limited contexts, evading a standard monitor that catches it only a fifth as often as prior agent attacks. Towards a defense, we develop an online stateful monitor that uses real-time clustering to collect weak suspiciousness signals across many agent transcripts, and escalates only rarely to a language model that flags misuse across user accounts. In evaluations with large-scale simulated datacenter traffic, our monitor Pareto dominates standard monitors, catching distributed attacks 30% earlier and flagging cyber misuse before it reaches the most harmful stages. Crucially, this comes at negligible additional latency for ~99% of user traffic. This detection advantage persists but narrows as the benign background traffic grows very large. After an extensive red-teaming exercise, we improve the defense and surprisingly also find that it catches standard jailbreaks, since adaptive attackers reuse attack variants across accounts. Our results point toward a new class of safety monitors which reason over groups of users rather than isolated transcripts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces distributed agent attacks in which harmful cybersecurity tasks are split across multiple limited-context agents to evade single-transcript monitors, demonstrates that a standard monitor catches such attacks only one-fifth as often as prior attacks, and proposes a stateful online monitor that performs real-time clustering of weak suspiciousness signals across transcripts, escalating rarely to an LM for cross-account decisions. In large-scale simulated datacenter traffic, the monitor is claimed to detect attacks 30% earlier, flag misuse before its most harmful stages, and impose negligible latency on ~99% of traffic, with the advantage narrowing at very large benign volumes; an extensive red-teaming exercise also shows incidental detection of standard jailbreaks.
Significance. If the empirical results hold, the work identifies a structural limitation of per-transcript monitors and supplies the first concrete defense that reasons over groups of users, supported by an extensive red-teaming exercise and an empirical demonstration on simulated traffic. This points toward a new class of safety mechanisms for multi-agent systems.
major comments (2)
- [Evaluation] Evaluation section: the central 30% earlier detection and Pareto-dominance claims rest on simulated datacenter traffic, yet the manuscript supplies no details on the clustering algorithm, exact metrics used to compute the 30% figure, error bars, data exclusion rules, or simulation fidelity to real user behavior; the abstract itself notes that the advantage narrows with very large background traffic but provides no quantitative scaling curves or false-positive rates at those volumes.
- [§3 and Evaluation] §3 (monitor design) and Evaluation: the claim that the clustering step aggregates weak signals without excessive false positives or missed coordinated attacks is load-bearing for the negligible-overhead and operational-advantage assertions, but no analysis of clustering behavior or false-positive scaling with transcript volume is reported.
minor comments (2)
- [§3] Notation for the suspiciousness signal and escalation threshold is introduced without a clear summary table or pseudocode, making the online clustering procedure harder to follow.
- [Red-teaming section] The red-teaming improvements are described qualitatively; quantitative before/after metrics on detection rate and false-positive impact would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for improving the transparency of our evaluation. We address each major point below and will revise the manuscript accordingly to provide the requested details and analyses.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central 30% earlier detection and Pareto-dominance claims rest on simulated datacenter traffic, yet the manuscript supplies no details on the clustering algorithm, exact metrics used to compute the 30% figure, error bars, data exclusion rules, or simulation fidelity to real user behavior; the abstract itself notes that the advantage narrows with very large background traffic but provides no quantitative scaling curves or false-positive rates at those volumes.
Authors: We agree that these methodological details are essential for reproducibility and to substantiate the central claims. In the revised manuscript we will expand the Evaluation section with: the precise clustering algorithm (online incremental k-means on fixed-dimensional embeddings with cosine distance and a cap of 50 clusters), the exact definition of the 30% earlier detection metric (mean reduction in attack turns to first escalation, computed over 100 independent runs), error bars derived from those runs, explicit data exclusion criteria (transcripts shorter than 4 turns discarded), and a fidelity discussion noting that benign traffic is drawn from sampled production logs while attack traffic is generated by our scaffold. We will also add quantitative scaling plots of detection latency and false-positive rate versus benign volume from 10^4 to 10^6 transcripts. revision: yes
-
Referee: [§3 and Evaluation] §3 (monitor design) and Evaluation: the claim that the clustering step aggregates weak signals without excessive false positives or missed coordinated attacks is load-bearing for the negligible-overhead and operational-advantage assertions, but no analysis of clustering behavior or false-positive scaling with transcript volume is reported.
Authors: We acknowledge that an explicit analysis of clustering behavior is required to support the overhead and advantage claims. We will add to §3 a description of the clustering hyperparameters and introduce a new subsection in Evaluation that reports: false-positive rate versus total transcript volume, an ablation study on the suspiciousness threshold, and a check that recall on the distributed attack suite remains high. These additions will directly address the scaling behavior and confirm that weak-signal aggregation does not produce excessive false positives. revision: yes
Circularity Check
No circularity: purely empirical evaluation of a monitor on simulated traffic
full rationale
The paper describes construction of a distributed attack scaffold and a stateful clustering-based monitor, then reports measured performance (detection latency, false-positive impact, Pareto dominance) on large-scale simulated datacenter traffic. No equations, first-principles derivations, or 'predictions' appear; all claims are direct experimental outcomes. No self-citation is load-bearing for the central results, and the design is not defined in terms of its own measured outputs. This matches the expected non-finding for an empirical systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Aggarwal, Jiawei Han, Jianyong Wang, and Philip S
Charu C. Aggarwal, Jiawei Han, Jianyong Wang, and Philip S. Yu. A framework for clustering evolving data streams. In Proceedings of the 29th International Conference on Very Large Data Bases, pages 81--92, 2003. doi:10.1016/B978-012722442-8/50016-1. URL https://www.vldb.org/conf/2003/papers/S04P02.pdf
-
[3]
Mitre att&ck: State of the art and way forward
Bader Al-Sada, Alireza Sadighian, and Gabriele Oligeri. Mitre att&ck: State of the art and way forward. ACM Computing Surveys, 57 0 (1): 0 1--37, 2024
2024
-
[4]
Disrupting the first reported ai-orchestrated cyber espionage campaign
Anthropic . Disrupting the first reported ai-orchestrated cyber espionage campaign. Technical report, Anthropic, November 2025 a . URL https://assets.anthropic.com/m/ec212e6566a0d47/original/Disrupting-the-first-reported-AI-orchestrated-cyber-espionage-campaign.pdf. Accessed: 2025-12-12
2025
-
[5]
Threat intelligence report: August 2025
Anthropic . Threat intelligence report: August 2025. Technical report, Anthropic, August 2025 b . URL https://www-cdn.anthropic.com/b2a76c6f6992465c09a6f2fce282f6c0cea8c200.pdf. Accessed: 2025-12-12
2025
-
[6]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. tau^2 -bench: Evaluating conversational agents in a dual-control environment. arXiv preprint arXiv: 2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Benchmarking Misuse Mitigation Against Covert Adversaries
Davis Brown, Mahdi Sabbaghi, Luze Sun, Alexander Robey, George J. Pappas, Eric Wong, and Hamed Hassani. Benchmarking misuse mitigation against covert adversaries, June 2025. URL https://arxiv.org/abs/2506.06414
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Feng Cao, Martin Ester, Weining Qian, and Aoying Zhou. Density-based clustering over an evolving data stream with noise. In Proceedings of the Sixth SIAM International Conference on Data Mining , pages 328--339, 2006. doi:10.1137/1.9781611972764.29. URL https://www.cs.sfu.ca/ ester/papers/SDM2006.DenStream.final.pdf
-
[9]
Assessing Claude Mythos Preview's cybersecurity capabilities
Nicholas Carlini, Newton Cheng, Keane Lucas, Michael Moore, Milad Nasr, Vinay Prabhushankar, Winnie Xiao Hakeem Angulu, Evyatar Ben Asher, Jackie Bow, Keir Bradwell, Ben Buchanan, David Forsythe, Daniel Freeman, Alex Gaynor, Xinyang Ge, Logan Graham, Kyla Guru, Hasnain Lakhani, Matt McNiece, Mojtaba Mehrara, Renee Nichol, Adnan Pirzada, Sophia Porter, And...
2026
-
[10]
Constitutional classifiers++: Efficient production-grade defenses against universal jailbreaks
Hoagy Cunningham, Jerry Wei, Zihan Wang, Andrew Persic, Alwin Peng, Jordan Abderrachid, Raj Agarwal, Bobby Chen, Andy Dau, Alek Dimitriev, Logan Howard, Yijin Hua, Rob Gilson, Mu Lin, Christopher Liu, Vladimir Mikulik, Rohit Mittapalli, Clare O'Hara, Jin Pan, Nikhil Saxena, Alex Silverstein, Yue Song, Giulio Zhou, Jan Leike, Jared Kaplan, Ethan Perez, and...
2026
-
[11]
Glukhov, Ziwen Han, Ilia Shumailov, Vardan Papyan, and Nicolas Papernot
D. Glukhov, Ziwen Han, Ilia Shumailov, Vardan Papyan, and Nicolas Papernot. Breach by a thousand leaks: Unsafe information leakage in `safe' ai responses. International Conference on Learning Representations, 2024
2024
-
[12]
Gtig ai threat tracker: Advances in threat actor usage of ai tools
GTIG . Gtig ai threat tracker: Advances in threat actor usage of ai tools. Technical report, Google Threat Intelligence Group, November 2025. URL https://services.google.com/fh/files/misc/advances-in-threat-actor-usage-of-ai-tools-en.pdf. Accessed: 2025-12-12
2025
-
[13]
Clustering data streams based on shared density between micro-clusters
Michael Hahsler and Matthew Bola \ n os. Clustering data streams based on shared density between micro-clusters. IEEE Transactions on Knowledge and Data Engineering, 28 0 (6): 0 1449--1461, 2016. doi:10.1109/TKDE.2016.2522412. URL https://dblp.org/rec/journals/tkde/HahslerB16.html
-
[14]
Vibecrime: Preparing your organization for the next generation of agentic ai cybercrime
Stephen Hilt and Robert McArdle. Vibecrime: Preparing your organization for the next generation of agentic ai cybercrime. Research report, Trend Micro, 2025. URL https://documents.trendmicro.com/assets/research-reports/crimininal-agentic-ai_research-paper.pdf. Accessed: 2025-12-12
2025
-
[15]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv: 2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66
2024
-
[17]
Dragan, and Jacob Steinhardt
Erik Jones, Anca D. Dragan, and Jacob Steinhardt. Adversaries can misuse combinations of safe models. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste - Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 , Proce...
2025
-
[18]
Building production-ready probes for gemini
János Kramár, Joshua Engels, Zheng Wang, Bilal Chughtai, Rohin Shah, Neel Nanda, and Arthur Conmy. Building production-ready probes for gemini. arXiv preprint arXiv: 2601.11516, 2026
-
[19]
Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers
Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. Drattack: Prompt decomposition and reconstruction makes powerful llm jailbreakers. Conference on Empirical Methods in Natural Language Processing, 2024. doi:10.48550/arXiv.2402.16914
-
[20]
Justin W. Lin, Eliot Krzysztof Jones, Donovan Julian Jasper, Ethan Jun-shen Ho, Anna Wu, Arnold Tianyi Yang, Neil Perry, Andy Zou, Matt Fredrikson, J. Zico Kolter, Percy Liang, Dan Boneh, and Daniel E. Ho. Comparing AI agents to cybersecurity professionals in real-world penetration testing, December 2025. URL https://arxiv.org/abs/2512.09882
-
[21]
Weblinx: Real-world website navigation with multi-turn dialogue
Xing Han L \`u , Zden e k Kasner, and Siva Reddy. Weblinx: Real-world website navigation with multi-turn dialogue. arXiv preprint arXiv:2402.05930, 2024
-
[22]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Disrupting malicious uses of ai: October 2025
OpenAI . Disrupting malicious uses of ai: October 2025. Technical report, OpenAI Threat Intelligence Team, October 2025. URL https://cdn.openai.com/threat-intelligence-reports/7d662b68-952f-4dfd-a2f2-fe55b041cc4a/disrupting-malicious-uses-of-ai-october-2025.pdf. Accessed: 2025-12-12
2025
-
[24]
GPT-5.5 System Card
OpenAI . GPT-5.5 System Card . https://deploymentsafety.openai.com/gpt-5-5/introduction, April 2026. OpenAI Deployment Safety Hub. Accessed: 2026-04-23
2026
-
[25]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, Amanda Askell, Nathan Bailey, Joe Benton, Emma Bluemke, Samuel R. Bowman, Eric Christiansen, Hoagy Cunningham, Andy Dau, Anjali Gopal, Rob Gilson, Logan Graham, Logan Howard, Nimit Kalra, Taesung Lee, Kevin Lin, Peter Lofgren, Fra...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Alex Tamkin, Miles McCain, Kunal Handa, Esin Durmus, Liane Lovitt, Ankur Rathi, Saffron Huang, Alfred Mountfield, Jerry Hong, Stuart Ritchie, Michael Stern, Brian Clarke, Landon Goldberg, Theodore R. Sumers, Jared Mueller, William McEachen, Wes Mitchell, Shan Carter, Jack Clark, Jared Kaplan, and Deep Ganguli. Clio: Privacy-preserving insights into real-w...
-
[27]
Openhands trajectories with qwen3-coder-480b-a35b-instruct
Maria Trofimova, Anton Shevtsov, Badertdinov Ibragim, Konstantin Pyaev, Simon Karasik, and Alexander Golubev. Openhands trajectories with qwen3-coder-480b-a35b-instruct. Nebius blog, 2025. URL https://nebius.com/blog/posts/openhands-trajectories-with-qwen3-coder-480b. Accessed: 2026-05-29
2025
-
[28]
The voyage 4 model family: Shared embedding space with moe architecture, January 2026
Voyage AI . The voyage 4 model family: Shared embedding space with moe architecture, January 2026. URL https://blog.voyageai.com/2026/01/15/voyage-4/
2026
-
[29]
Swe-agent: Agent-computer interfaces enable automated software engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37: 0 50528--50652, 2024
2024
-
[30]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=WE_vluYUL-X
2023
-
[31]
Monitoring decomposition attacks in llms with lightweight sequential monitors
Chen Yueh-Han, Nitish Joshi, Yulin Chen, Maksym Andriushchenko, Rico Angell, and He He. Monitoring decomposition attacks in llms with lightweight sequential monitors. arXiv preprint arXiv: 2506.10949, 2025
-
[32]
Cybench: A framework for evaluating cybersecurity capabilities and risks of language models
Andy K Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Jasper, et al. Cybench: A framework for evaluating cybersecurity capabilities and risks of language models. arXiv preprint arXiv:2408.08926, 2024
-
[33]
Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y
Andy K. Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y. Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu, Sara Hong, Nardos Demilew, Shivatmica Murgai, Jason Tran, Nishka Kacheria, Ethan Ho, Denis Liu, Lauren McLane, Olivia Bruvik, Dai-Rong Han, Seungwoo Kim, Akhil Vyas, Cuiyuanxiu Chen, Ryan Li, Weiran Xu, Jonathan Z. Ye, Prerit Ch...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.