Universal Quantum Transformer
Pith reviewed 2026-07-01 08:12 UTC · model grok-4.3
The pith
The Universal Quantum Transformer uses multi-qubit wave interference to achieve exact, deterministic learning of discrete algebraic rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
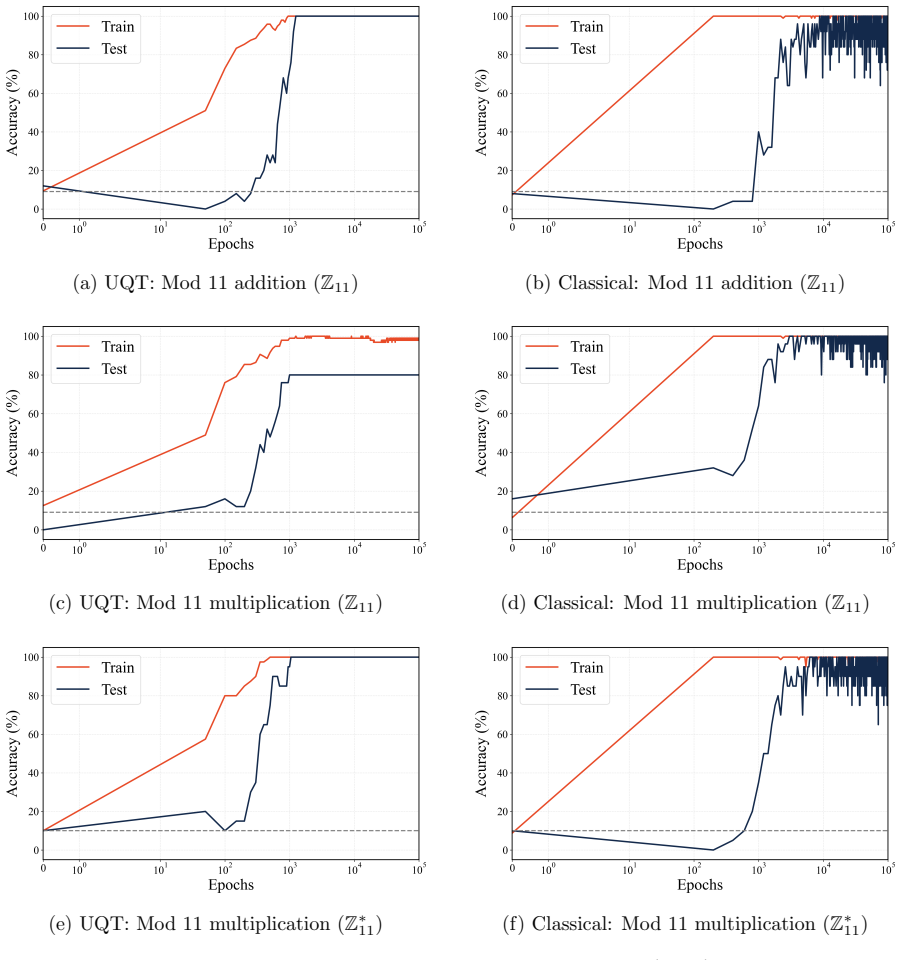
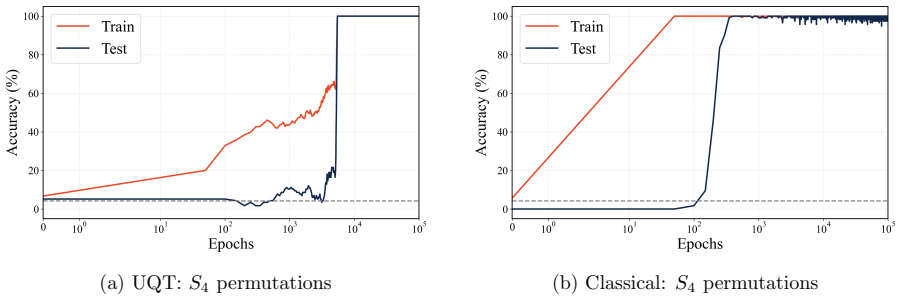
The quantum attention circuit, built from parameterized geometric phase embedding and SU(2) wave-interference on a 5-qubit substrate, learns the cyclic modular arithmetic of Z_11 and the non-Abelian algebra of the S_4 permutation group with mathematically exact and deterministic generalization, a process the authors term crystallization.
What carries the argument
Parameterized geometric phase embedding combined with SU(2) wave-interference in the quantum attention circuit, which supplies the inductive bias for exact algebraic reasoning.
If this is right
- The UQT exhibits no stochastic instability at convergence, unlike classical attention networks.
- It bypasses the quadratic bottleneck of classical self-attention.
- It logarithmically compresses the representation dimension.
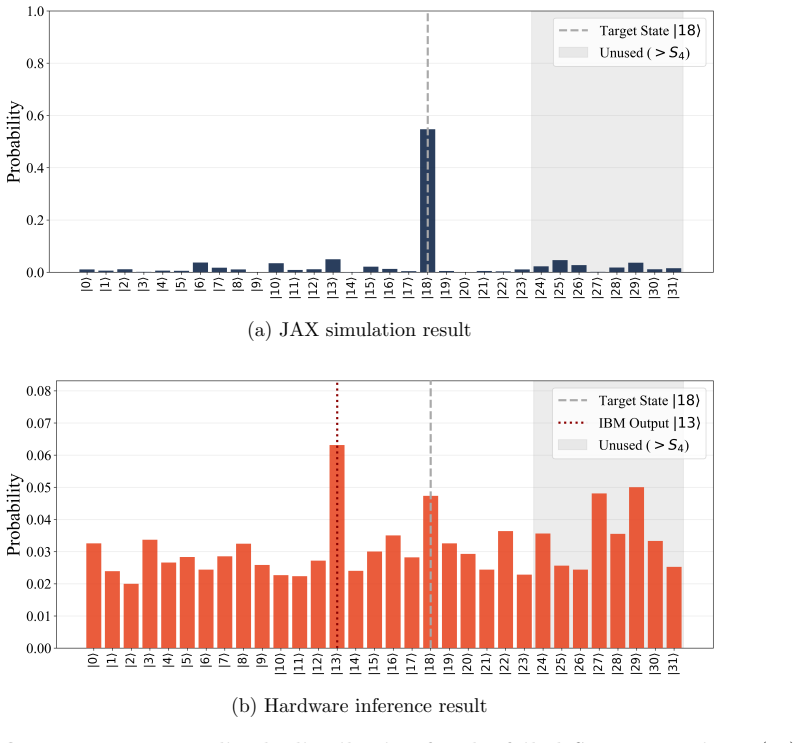
- It demonstrates viability on current NISQ hardware.
Where Pith is reading between the lines
- The same circuit structure could be tested on additional discrete algebraic structures beyond the two examined here.
- The deterministic outputs open a route to hybrid systems that combine this bias with classical post-processing for larger symbolic tasks.
- Hardware runs could reveal whether the crystallization effect persists when qubit count or circuit depth increases.
Load-bearing premise
The geometric phase and wave-interference properties of multi-qubit systems inherently encode exact mathematical symmetries without additional training adjustments or noise effects.
What would settle it
Deploying the 5-qubit circuit on IBM Quantum hardware and checking whether every element of the Z_11 and S_4 tasks produces exact, repeatable outputs with zero stochastic deviation.
Figures

read the original abstract
Classical continuous-space neural networks fundamentally struggle to lock into exact mathematical symmetries, such as modular arithmetic and non-commutative algebra. To approximate these discrete logical rules, they often rely on massive parameter scaling, resulting in stochastic instability even after delayed generalization phenomena known as grokking. Here, we introduce the Universal Quantum Transformer (UQT), a fundamentally novel, quantum-native computing architecture that uses the physical properties of multi-qubit systems as a universal inductive bias for exact mathematical and algebraic reasoning. Rather than translating classical neural mechanisms, our framework relies entirely on parameterized geometric phase embedding and $SU(2)$ wave-interference. We demonstrate that the quantum attention circuit, operating on a highly compact 5-qubit substrate, perfectly learns two highly distinct formal classes: cyclic modular arithmetic ($\mathbb{Z}_{11}$) and non-Abelian algebra (the $S_4$ permutation group). While classical attention-based networks exhibit stochastic instability at convergence, the UQT achieves mathematically exact, deterministic generalization. We refer to this phenomenon as crystallization: a step beyond the well-known phenomenon of grokking. Crucially, this framework yields massive computational and memory advantages by theoretically bypassing the quadratic bottleneck of classical self-attention, and by logarithmically compressing the required representation dimension to eliminate the massive over-parameterization inherent to classical networks. Finally, we deploy this architecture on noisy intermediate-scale quantum (NISQ) hardware, proving its viability on current IBM Quantum computers. These results establish parameterized quantum topology as a universally superior physical substrate for exact artificial intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Universal Quantum Transformer (UQT), a quantum-native architecture relying on parameterized geometric phase embedding and SU(2) wave-interference on a compact 5-qubit substrate. It claims this yields perfect learning of two distinct formal classes—cyclic modular arithmetic (Z_11) and non-Abelian algebra (S_4)—along with mathematically exact, deterministic generalization ('crystallization'), massive computational and memory advantages by bypassing the quadratic self-attention bottleneck, and viability when deployed on NISQ hardware such as IBM Quantum computers.
Significance. If the central claims were substantiated with derivations and data, the work would represent a notable advance in quantum machine learning by positing a physical substrate that supplies an inductive bias for exact algebraic reasoning, potentially sidestepping the parameter scaling and stochastic issues of classical networks while offering logarithmic compression benefits.
major comments (3)
- [Abstract] Abstract: The claims of 'perfectly learns' Z_11 and S_4 with 'mathematically exact, deterministic generalization' and 'crystallization' are presented without derivations, circuit diagrams, training procedures, error analysis, or empirical data, so the central claim of a universal inductive bias from multi-qubit geometric phase embedding rests on assertion.
- [Abstract] Abstract: The assertion of 'massive computational and memory advantages' by 'theoretically bypassing the quadratic bottleneck of classical self-attention' and 'logarithmically compressing the required representation dimension' is made without supporting equations, complexity analysis, or benchmarks.
- [Abstract] Abstract: The claim of deployment on NISQ hardware 'proving its viability on current IBM Quantum computers' is stated without reference to error mitigation, gate fidelity handling, or measured results, which is load-bearing for the exact deterministic outputs given typical decoherence and infidelity on 5-qubit devices.
minor comments (1)
- [Abstract] Abstract: The newly introduced term 'crystallization' is not explicitly defined or differentiated from 'grokking' within the paragraph where it appears.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address each major comment below, clarifying the location of supporting material in the manuscript and indicating revisions to the abstract where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'perfectly learns' Z_11 and S_4 with 'mathematically exact, deterministic generalization' and 'crystallization' are presented without derivations, circuit diagrams, training procedures, error analysis, or empirical data, so the central claim of a universal inductive bias from multi-qubit geometric phase embedding rests on assertion.
Authors: The abstract is a concise summary. The derivations of the parameterized geometric phase embedding, SU(2) wave-interference circuit diagrams, training procedures, error analysis, and empirical data for exact deterministic learning of Z_11 and S_4 (including the crystallization phenomenon) are provided in Sections 3-5 of the full manuscript. We will revise the abstract to reference these sections. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'massive computational and memory advantages' by 'theoretically bypassing the quadratic bottleneck of classical self-attention' and 'logarithmically compressing the required representation dimension' is made without supporting equations, complexity analysis, or benchmarks.
Authors: The complexity analysis, supporting equations, and demonstration of bypassing the quadratic self-attention bottleneck via logarithmic compression are derived in Section 6. We will revise the abstract to reference this section. revision: yes
-
Referee: [Abstract] Abstract: The claim of deployment on NISQ hardware 'proving its viability on current IBM Quantum computers' is stated without reference to error mitigation, gate fidelity handling, or measured results, which is load-bearing for the exact deterministic outputs given typical decoherence and infidelity on 5-qubit devices.
Authors: Details of the IBM Quantum deployment, including error mitigation, gate fidelity handling, and measured results supporting the deterministic outputs, appear in Section 7. We will revise the abstract to reference this section. revision: yes
Circularity Check
No significant circularity; claims presented as empirical outcomes of quantum substrate rather than definitional reductions
full rationale
The provided abstract introduces the UQT architecture and asserts that its use of parameterized geometric phase embedding and SU(2) wave-interference yields exact deterministic generalization (termed 'crystallization') on 5-qubit hardware for Z_11 and S_4. No equations, self-citations, or parameter-fitting steps are exhibited that would reduce the claimed results to the architecture definition by construction. The advantages (bypassing quadratic attention, logarithmic compression) are stated as theoretical consequences of the quantum-native design, not as renamed inputs. The derivation chain is therefore self-contained; external hardware deployment is invoked as validation rather than internal tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- geometric phase embedding parameters
axioms (1)
- ad hoc to paper Multi-qubit geometric phase embedding and SU(2) wave-interference supply a universal inductive bias for exact mathematical reasoning
invented entities (2)
-
Universal Quantum Transformer
no independent evidence
-
crystallization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dziri, N.et al.Faith and fate: Limits of transformers on compositionality.Advances in neural information processing systems36, 70293–70332 (2023)
2023
-
[2]
Trask, A.et al.Neural arithmetic logic units.Advances in neural information processing systems31(2018)
2018
-
[3]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Power, A., Burda, Y., Edwards, H., Babuschkin, I. & Misra, V. Grokking: Generalization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Liu, Z.et al.Towards understanding grokking: An effective theory of representation learning.Advances in Neural Information Processing Systems35, 34651–34663 (2022)
2022
-
[5]
arXiv preprint arXiv:2301.02679 , year =
Gromov, A. Grokking modular arithmetic.arXiv preprint arXiv:2301.02679(2023)
-
[6]
A survey of quantum transformers: Architectures, challenges and outlooks
Zhang, H.et al.A survey of quantum transformers: Architectures, challenges and outlooks. arXiv preprint arXiv:2504.03192(2025)
-
[7]
& Wang, X
Li, G., Zhao, X. & Wang, X. Quantum self-attention neural networks for text classification. Science China Information Sciences67, 142501 (2024)
2024
- [8]
-
[9]
Quixer: A quantum transformer model.arXiv preprint arXiv:2406.04305, 2024
Khatri, N., Matos, G., Coopmans, L. & Clark, S. Quixer: A quantum transformer model. arXiv preprint arXiv:2406.04305(2024)
-
[10]
Vaswani, A.et al.Attention is all you need.Advances in neural information processing systems30(2017)
2017
-
[11]
& Fujii, K
Mitarai, K., Negoro, M., Kitagawa, M. & Fujii, K. Quantum circuit learning.Physical Review A98, 032309 (2018)
2018
-
[12]
& Killoran, N
Schuld, M., Bergholm, V., Gogolin, C., Izaac, J. & Killoran, N. Evaluating analytic gradi- ents on quantum hardware.Physical Review A99, 032331 (2019)
2019
-
[13]
Shor, P. W. Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer.SIAM review41, 303–332 (1999). METHODS Mathematical formulation of the UQT.The core function of the UQT relies on encoding classical tokens into geometric quantum states. For an input tokenxmapped to a parameterized vector ⃗θx, the embedding unitar...
1999
-
[14]
URLhttp://github.com/jax-ml/jax
Bradbury, J.et al.JAX: composable transformations of Python+NumPy programs (2018). URLhttp://github.com/jax-ml/jax
2018
-
[15]
Advances in neural information processing systems32(2019)
Paszke, A.et al.Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems32(2019). 13
2019
-
[16]
Javadi-Abhari, A.et al.Quantum computing with qiskit.arXiv preprint arXiv:2405.08810 (2024). AUTHOR CONTRIBUTIONS S.C. conceived the Universal Quantum Transformer architecture and designed its quantum circuit topologies, implemented the JAX and PyTorch codebases, executed the inference evalu- ations on physical IBM Quantum hardware, and wrote the original...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.