CardioLens: Revealing the Clinical Reality Gap of MLLMs via Multi-Sequence Cardiac MRI Evaluations
Pith reviewed 2026-06-29 08:26 UTC · model grok-4.3
The pith
Current MLLMs fall short on clinical cardiac MRI tasks that require integrating evidence across sequences, views, and phases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
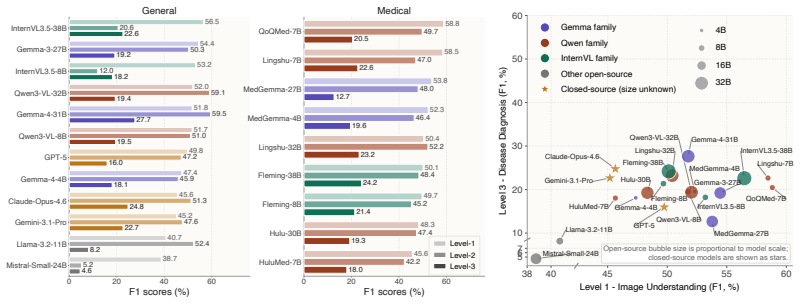
CardioLens shows that current MLLMs remain far from reliable CMR interpretation. Clinical decisions require integrating distributed evidence across sequences, views, and temporal phases, yet models perform poorly on the testbed and degrade along the workflow from image understanding to diagnosis. They also display category-collapse, defaulting to common abnormal categories rather than separating clinically distinct findings. Neither slice-selection protocols nor reasoning prompts close the gap.
What carries the argument
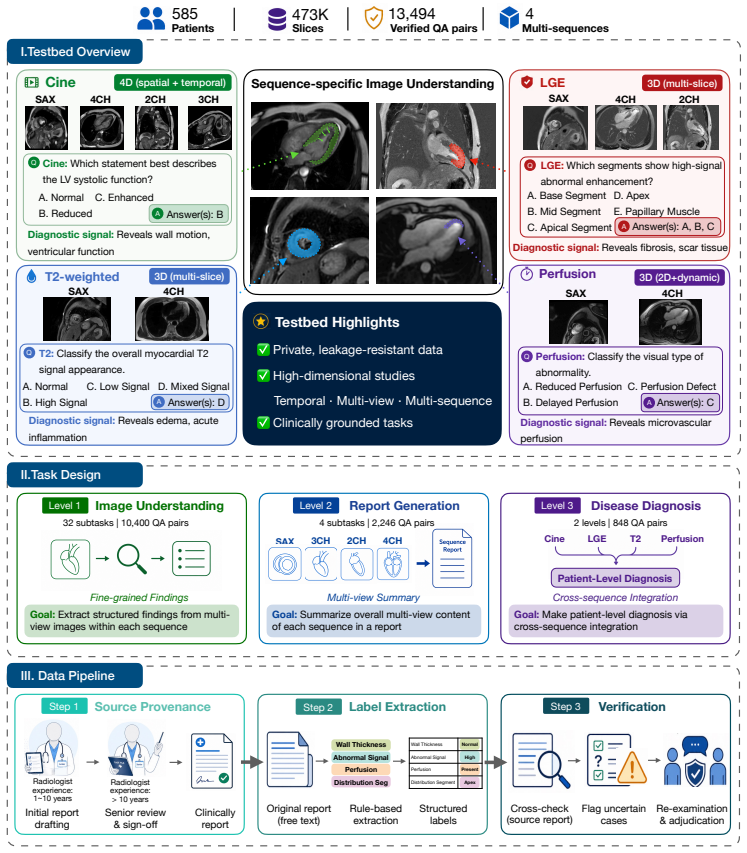
CardioLens, a leakage-resistant evaluation testbed of multi-sequence CMR QA pairs built from private hospital archives through a report-to-QA construction and verification pipeline.
If this is right
- Model performance degrades steadily from image understanding through report generation to disease diagnosis.
- Models exhibit category-collapse failure, defaulting to frequent abnormal categories instead of distinguishing distinct clinical findings.
- Changes in slice selection protocol alter performance by only about 1 percent.
- Adding explicit reasoning prompts does not improve use of visual evidence and often increases model conservatism.
Where Pith is reading between the lines
- Architectures that explicitly fuse information across multiple CMR sequences and phases may be required before reliable clinical use becomes feasible.
- The CardioLens construction pipeline could be replicated for other multi-sequence modalities such as multi-phase CT or combined PET-MRI studies.
- Any claim of clinical readiness for MLLMs in cardiology would need separate verification on distributed-evidence tasks of this type.
Load-bearing premise
The report-to-QA construction and verification pipeline from private archives produces accurate, leakage-resistant QA pairs that faithfully represent clinical CMR interpretation stages.
What would settle it
A subsequent evaluation in which multiple MLLMs reach high accuracy on the disease-diagnosis portion of CardioLens while avoiding category collapse would directly challenge the reported reality gap.
Figures




read the original abstract
Multimodal Large Language Models (MLLMs) have shown strong performance on public medical benchmarks, yet existing evaluations often remain weak proxies for clinical use, relying on isolated inputs and simplified recognition-style tasks. We introduce CardioLens, a leakage-resistant evaluation testbed for multi-sequence Cardiovascular Magnetic Resonance (CMR), constructed from private hospital archives through a rigorous report-to-QA construction and verification pipeline. CardioLens contains 473,896 slices and 13,494 verified QA pairs across 4D Cine, LGE, perfusion, and T2-weighted imaging, and evaluates three stages of CMR interpretation: image understanding, report generation, and disease diagnosis. Across 24 state-of-the-art MLLMs, CardioLens reveals a substantial clinical reality gap: models perform poorly overall, with performance degrading along the real CMR workflow. Confusion analysis further shows a category-collapse failure mode, where models default to frequent abnormal categories rather than distinguishing clinically distinct findings. To rule out MLLM-compatible input construction as the primary cause, we compare random, clinically motivated, and data-driven slice selection protocols under different slice budgets; performance changes only marginally, typically by about 1%. Explicit reasoning prompts also fail to rescue performance, often making models more conservative rather than improving visual evidence use. These results show that current MLLMs remain far from reliable CMR interpretation, where clinical decisions require integrating distributed evidence across sequences, views, and temporal phases. CardioLens provides a clinically grounded testbed for developing next-generation MLLMs toward real-world clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CardioLens, a leakage-resistant benchmark for MLLMs on multi-sequence CMR constructed from private hospital archives via a report-to-QA pipeline. It comprises 473,896 slices and 13,494 verified QA pairs spanning 4D Cine, LGE, perfusion, and T2-weighted sequences, evaluating three clinical interpretation stages (image understanding, report generation, disease diagnosis). Evaluations across 24 MLLMs show poor overall performance that degrades along the real workflow, with a category-collapse failure mode; ablations indicate slice selection and explicit reasoning prompts have marginal impact.
Significance. If the QA pairs accurately capture clinical reasoning stages, the benchmark would be significant for exposing limitations of current MLLMs on realistic, multi-sequence CMR tasks that require integrating distributed evidence across views and phases—tasks not well proxied by existing public medical benchmarks. The scale and multi-sequence coverage, plus the slice-selection ablation, are strengths that could inform future model development toward clinical deployment.
major comments (3)
- [Methods] Methods (report-to-QA construction and verification pipeline): The central claim of a substantial clinical reality gap depends on the 13,494 QA pairs faithfully representing the three interpretation stages, yet the manuscript provides no quantitative verification metrics (e.g., inter-rater agreement, label accuracy on a sampled subset, or external audit results) and releases no sample pairs, leaving open the possibility of systematic misalignment with actual radiologist reasoning.
- [Abstract and Results] Abstract and Results (performance reporting): The reported performance numbers and failure modes (including category-collapse) are presented without accompanying statistical tests, confidence intervals, or details on how the private verification pipeline was validated, which directly affects the verifiability of the claim that models 'remain far from reliable CMR interpretation'.
- [Results] Results (workflow degradation claim): The finding that performance degrades along the real CMR workflow is load-bearing for the clinical-reality-gap conclusion, but without public access to the testbed or quantified fidelity checks on the report-to-QA mapping, it is unclear whether the observed degradation reflects model limitations or artifacts in how the QA pairs were generated from reports.
minor comments (1)
- [Results] The manuscript would benefit from clearer notation distinguishing the three interpretation stages in tables or figures that report per-stage metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important issues around verifiability, statistical rigor, and reproducibility that we address point-by-point below. We agree with several observations and will incorporate clarifications and additional analyses in a revised manuscript where feasible. Privacy constraints on the private hospital data limit full public release but do not affect the internal validity of the reported results.
read point-by-point responses
-
Referee: [Methods] Methods (report-to-QA construction and verification pipeline): The central claim of a substantial clinical reality gap depends on the 13,494 QA pairs faithfully representing the three interpretation stages, yet the manuscript provides no quantitative verification metrics (e.g., inter-rater agreement, label accuracy on a sampled subset, or external audit results) and releases no sample pairs, leaving open the possibility of systematic misalignment with actual radiologist reasoning.
Authors: We appreciate this emphasis on quantitative validation. The report-to-QA pipeline (Section 3.2) was executed by board-certified cardiologists who reviewed and corrected all pairs for clinical fidelity. Internal inter-rater agreement (Cohen's kappa) and label accuracy on a 15% sampled subset were computed during construction but omitted from the original manuscript. In revision we will report these metrics (kappa > 0.82) together with a more granular description of the verification protocol. Sample pairs cannot be released publicly due to IRB restrictions on private hospital archives; however, we will offer anonymized examples to the editor or reviewers under a data-use agreement. revision: partial
-
Referee: [Abstract and Results] Abstract and Results (performance reporting): The reported performance numbers and failure modes (including category-collapse) are presented without accompanying statistical tests, confidence intervals, or details on how the private verification pipeline was validated, which directly affects the verifiability of the claim that models 'remain far from reliable CMR interpretation'.
Authors: We agree that statistical support strengthens the claims. In the revised manuscript we will add 95% bootstrap confidence intervals to all accuracy, F1, and degradation metrics and include appropriate significance tests (McNemar's test for paired model comparisons and Wilcoxon signed-rank tests for workflow-stage differences). Expanded validation details for the verification pipeline will also be moved into the main Methods section. revision: yes
-
Referee: [Results] Results (workflow degradation claim): The finding that performance degrades along the real CMR workflow is load-bearing for the clinical-reality-gap conclusion, but without public access to the testbed or quantified fidelity checks on the report-to-QA mapping, it is unclear whether the observed degradation reflects model limitations or artifacts in how the QA pairs were generated from reports.
Authors: The degradation pattern is consistent across all 24 models and is supported by the slice-selection ablations (Section 4.4) showing only marginal changes (~1%). The report-to-QA mapping was constructed to mirror the sequential clinical reasoning steps present in the original reports, with cardiologist verification ensuring no artificial simplification. In revision we will add a new subsection with explicit fidelity examples (sentence-to-QA mappings) and quantitative checks on information preservation. Public release of the testbed remains impossible under current privacy regulations. revision: partial
- Public release of the full CardioLens testbed or sample QA pairs, precluded by institutional privacy regulations governing private hospital archives.
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper is an empirical benchmark study that constructs a testbed from private archives and reports direct performance measurements of 24 MLLMs across three interpretation stages. No derivations, equations, fitted parameters, or predictions appear in the provided text. The central claim (large clinical reality gap) rests on observed accuracies and confusion patterns rather than any self-definitional, fitted-input, or self-citation reduction. The report-to-QA pipeline is described as rigorous but is not invoked as a mathematical premise that loops back on itself. This matches the default case of a self-contained empirical evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The report-to-QA construction and verification pipeline from private hospital archives produces accurate and leakage-resistant QA pairs that match real clinical CMR workflows.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35: 23716–23736, 2022
2022
-
[4]
System card:claude opus 4.6
Anthropic. System card:claude opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026
2026
-
[5]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
Mohammad Asadi, Jack W O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Fardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
-
[6]
Fan Bai, Yuxin Du, Tiejun Huang, Max Q-H Meng, and Bo Zhao. M3d: Advancing 3d medical image analysis with multi-modal large language models.arXiv preprint arXiv:2404.00578, 2024
-
[7]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities.arXiv preprint arXiv:2308.12966, 1(2):3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: Is the problem solved?IEEE Transactions on Medical Imaging, 37(11):2514–2525, 2018
Olivier Bernard, Alain Lalande, Clement Zotti, Frederick Cervenansky, Xin Yang, Pheng-Ann Heng, Irem Cetin, Karim Lekadir, Oscar Camara, Miguel Angel Gonzalez Ballester, et al. Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: Is the problem solved?IEEE Transactions on Medical Imaging, 37(11):2514–2525, 2018
2018
-
[10]
Gmai-mmbench: A comprehensive multimodal evaluation benchmark towards general medical ai.Advances in Neural Information Processing Systems, 37:94327–94427, 2024
Pengcheng Chen, Jin Ye, Guoan Wang, Yanjun Li, Zhongying Deng, Wei Li, Tianbin Li, Haodong Duan, Ziyan Huang, Yanzhou Su, et al. Gmai-mmbench: A comprehensive multimodal evaluation benchmark towards general medical ai.Advances in Neural Information Processing Systems, 37:94327–94427, 2024
2024
-
[11]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024. 10
2024
-
[12]
Amedeo Chiribiri, Andrew E Arai, Edward DiBella, Li-Yueh Hsu, Masaki Ishida, Michael Jerosch-Herold, Sebastian Kozerke, Xenios Milidonis, Reza Nezafat, Sven Plein, et al. Society for cardiovascular magnetic resonance expert consensus statement on quantitative myocardial perfusion cardiovascular magnetic resonance imaging.Journal of Cardiovascular Magnetic...
2025
-
[13]
Wei Dai, Peilin Chen, Chanakya Ekbote, and Paul Pu Liang. Qoq-med: Building multimodal clinical foundation models with domain-aware grpo training.arXiv preprint arXiv:2506.00711, 2025
-
[14]
Aligning multi-sequence cmr towards fully automated myocardial pathology segmentation.IEEE Transactions on Medical Imaging, 2023
Wangbin Ding, Lei Li, Junyi Qiu, Sihan Wang, Liqin Huang, Yinyin Chen, Shan Yang, and Xiahai Zhuang. Aligning multi-sequence cmr towards fully automated myocardial pathology segmentation.IEEE Transactions on Medical Imaging, 2023
2023
-
[15]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
google/gemma-4-31B-it
Google. google/gemma-4-31B-it. https://huggingface.co/google/gemma-4-31B-it ,
-
[17]
Hugging Face model card
-
[18]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro, 2026
2026
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
The illusion of readiness: Stress testing large frontier models on multimodal medical benchmarks.arXiv e-prints, pages arXiv–2509, 2025
Yu Gu, Jingjing Fu, Xiaodong Liu, Jeya Maria Jose Valanarasu, Noel Codella, Reuben Tan, Qianchu Liu, Ying Jin, Sheng Zhang, Jinyu Wang, et al. The illusion of readiness: Stress testing large frontier models on multimodal medical benchmarks.arXiv e-prints, pages arXiv–2509, 2025
2025
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[23]
Sunan He, Yuxiang Nie, Zhixuan Chen, Zhiyuan Cai, Hongmei Wang, Shu Yang, and Hao Chen. Meddr: Diagnosis-guided bootstrapping for large-scale medical vision-language learning.arXiv preprint arXiv:2404.15127, 1(3):6, 2024
-
[24]
Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. Omnimed- vqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170–22183, 2024
2024
-
[25]
Songtao Jiang, Yuan Wang, Sibo Song, Tianxiang Hu, Chenyi Zhou, Bin Pu, Yan Zhang, Zhibo Yang, Yang Feng, Joey Tianyi Zhou, et al. Hulu-med: A transparent generalist model towards holistic medical vision-language understanding.arXiv preprint arXiv:2510.08668, 2025
-
[26]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.arXiv preprint arXiv:2009.13081, 2020
-
[27]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[28]
Sven Koehler, Julian Kuhm, Tyler Huffaker, Daniel Young, Animesh Tandon, Florian André, Norbert Frey, Gerald Greil, Tarique Hussain, and Sandy Engelhardt. Deep learning–based aligned strain from cine cardiac mri for detection of fibrotic myocardial tissue in patients with duchenne muscular dystrophy.Radiology: Artificial Intelligence, 7(3):e240303, 2025. 11
2025
-
[29]
Emidec: A database usable for the automatic evaluation of myocardial infarction from delayed-enhancement cardiac mri.Data, 5(4):89, 2020
Alain Lalande, Zhihao Chen, Thomas Decourselle, Abdul Qayyum, Thibaut Pommier, Luc Lor- gis, Ezequiel de La Rosa, Alexandre Cochet, Yves Cottin, Dominique Ginhac, et al. Emidec: A database usable for the automatic evaluation of myocardial infarction from delayed-enhancement cardiac mri.Data, 5(4):89, 2020
2020
-
[30]
A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1): 180251, 2018
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images.Scientific data, 5(1): 180251, 2018
2018
-
[31]
Cardiac sarcoidosis: phenotypes, diagnosis, treatment, and prognosis.European heart journal, 44(17):1495–1510, 2023
Jukka Lehtonen, Valtteri Uusitalo, Pauli Pöyhönen, Mikko I Mäyränpää, and Markku Kupari. Cardiac sarcoidosis: phenotypes, diagnosis, treatment, and prognosis.European heart journal, 44(17):1495–1510, 2023
2023
-
[32]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36: 28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36: 28541–28564, 2023
2023
-
[33]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Atrial scar quantification via multi-scale cnn in the graph-cuts framework.Medical Image Analysis, 60:101595, 2020
Lei Li, Fuping Wu, Guang Yang, Lingchao Xu, Tom Wong, Raad Mohiaddin, David Firmin, Jennifer Keegan, and Xiahai Zhuang. Atrial scar quantification via multi-scale cnn in the graph-cuts framework.Medical Image Analysis, 60:101595, 2020
2020
-
[35]
Zimmer, Julia A
Lei Li, Veronika A. Zimmer, Julia A. Schnabel, and Xiahai Zhuang. Atrialgeneral: Domain generalization for left atrial segmentation of multi-center lge mris. InMedical Image Computing and Computer Assisted Intervention (MICCAI), pages 557–566, 2021
2021
-
[36]
Zimmer, Julia A
Lei Li, Veronika A. Zimmer, Julia A. Schnabel, and Xiahai Zhuang. Atrialjsqnet: A new framework for joint segmentation and quantification of left atrium and scars incorporating spatial and shape information.Medical Image Analysis, 76:102303, 2022
2022
-
[37]
Zimmer, Julia A
Lei Li, Veronika A. Zimmer, Julia A. Schnabel, and Xiahai Zhuang. Medical image analysis on left atrial lge mri for atrial fibrillation studies: A review.Medical Image Analysis, 77:102360, 2022
2022
-
[38]
Myops: A benchmark of myocardial pathology segmentation combining three-sequence cardiac magnetic resonance images.Medical Image Analysis, 87:102808, 2023
Lei Li, Fuping Wu, Sihan Wang, Xinzhe Luo, Carlos Martín-Isla, Shuwei Zhai, Jianpeng Zhang, Yanfei Liu, Zhen Zhang, Markus J Ankenbrand, et al. Myops: A benchmark of myocardial pathology segmentation combining three-sequence cardiac magnetic resonance images.Medical Image Analysis, 87:102808, 2023
2023
-
[39]
Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering. In2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021
2021
-
[40]
Chi Liu, Derek Li, Yan Shu, Robin Chen, Derek Duan, Teng Fang, and Bryan Dai. Fleming- r1: Toward expert-level medical reasoning via reinforcement learning.arXiv preprint arXiv:2509.15279, 2025
-
[41]
Deep learning segmentation of the right ventricle in cardiac mri: the m&ms challenge.IEEE Journal of Biomedical and Health Informatics, 27(7):3302– 3313, 2023
Carlos Martín-Isla, Víctor M Campello, Cristian Izquierdo, Kaisar Kushibar, Carla Sendra- Balcells, Polyxeni Gkontra, Alireza Sojoudi, Mitchell J Fulton, Tewodros Weldebirhan Arega, Kumaradevan Punithakumar, et al. Deep learning segmentation of the right ventricle in cardiac mri: the m&ms challenge.IEEE Journal of Biomedical and Health Informatics, 27(7):...
2023
-
[42]
mistralai/Mistral-Small-3.1-24B-Instruct-2503
Mistral AI. mistralai/Mistral-Small-3.1-24B-Instruct-2503. https://huggingface.co/ mistralai/Mistral-Small-3.1-24B-Instruct-2503, 2025. Hugging Face model card
2025
-
[43]
Pace, Hannah T
Danielle F. Pace, Hannah T. M. Contreras, Jennifer Romanowicz, Shruti Ghelani, Imon Ra- haman, Yue Zhang, Patricia Gao, Mohammad Imrul Jubair, Tom Yeh, Polina Golland, et al. Hvsmr-2.0: A 3d cardiovascular mr dataset for whole-heart segmentation in congenital heart disease.Scientific Data, 11(1):721, 2024. 12
2024
-
[44]
Myops-net: Myocardial pathology segmentation with flexible combination of multi-sequence cmr images.Medical image analysis, 84:102694, 2023
Junyi Qiu, Lei Li, Sihan Wang, Ke Zhang, Yinyin Chen, Shan Yang, and Xiahai Zhuang. Myops-net: Myocardial pathology segmentation with flexible combination of multi-sequence cmr images.Medical image analysis, 84:102694, 2023
2023
-
[45]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[46]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Neda Tavakoli, Amir Ali Rahsepar, Brandon C Benefield, Daming Shen, Santiago López-Tapia, Florian Schiffers, Jeffrey J Goldberger, Christine M Albert, Edwin Wu, Aggelos K Katsaggelos, et al. Scarnet: a novel foundation model for automated myocardial scar quantification from late gadolinium-enhancement images.Journal of Cardiovascular Magnetic Resonance, p...
2025
-
[49]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data.Nature Communications, 16(1):7866, 2025
Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Hui Hui, Yanfeng Wang, and Weidi Xie. Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data.Nature Communications, 16(1):7866, 2025
2025
-
[52]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision- language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Cares: A comprehensive benchmark of trustworthiness in medical vision language models.Advances in Neural Information Processing Systems, 37: 140334–140365, 2024
Peng Xia, Ze Chen, Juanxi Tian, Yangrui Gong, Ruibo Hou, Yue Xu, Zhenbang Wu, Zhiyuan Fan, Yiyang Zhou, Kangyu Zhu, et al. Cares: A comprehensive benchmark of trustworthiness in medical vision language models.Advances in Neural Information Processing Systems, 37: 140334–140365, 2024
2024
-
[55]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Cheng- hao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foun- dation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Continuous spatio-temporal memory networks for 4d cardiac cine mri segmentation
Meng Ye, Bingyu Xin, Leon Axel, and Dimitris Metaxas. Continuous spatio-temporal memory networks for 4d cardiac cine mri segmentation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 9532–9542. IEEE, 2025
2025
-
[57]
ace of spades
J Zhao, F Xu, and F Feng. Miccai mbas 2024-multi-class bi-atrial segmentation challenge, 2024. 13 A Task and Sequence Specifications in CardioLens This appendix provides the complete per-subtask and per-sequence specifications deferred from Section 2.1. Section A.1 details the clinical role of each CMR sequence. Section A.2 enumerates the 32 image underst...
2024
-
[58]
View routing.The subtask is mapped to one or more canonical views (sequence, orientation) according to Table 5. This mapping was elicited from practicing cardiac radiologists and reflects how each subtask is read in clinical practice (e.g., wall thickening from Cine SAX, valvular motion from Cine 4CH, scar localization from LGE SAX)
-
[59]
The rules are detailed per sequence below
Per-view slice extraction.For each routed view, we apply a view-specific extraction rule that exploits the known acquisition structure of that sequence (spatial stacks, cardiac-cycle frames, or 2D+t dynamic series). The rules are detailed per sequence below. Storage.All sequences are stored as 3D NIfTI volumes of shape (H, W, Z). For Cine sequences, the Z...
-
[60]
Phase 1 (spatial coverage):the end-diastolic frame from every spatial slice (Ns frames, matching the small-Krule)
-
[61]
These layers are chosen to match the conventional three-slice reporting convention (basal, mid, apical short-axis) used in both clinical reads and AHA 17-segment analysis
Phase 2 (key-layer dynamics):additional temporal frames from three clinically key layers – basal, mid, and apical – sampled uniformly per layer. These layers are chosen to match the conventional three-slice reporting convention (basal, mid, apical short-axis) used in both clinical reads and AHA 17-segment analysis
-
[62]
Phase 3 (remaining-layer dynamics):if the budget is still not filled, temporal frames from the remaining spatial layers, uniformly distributed across layers and cardiac phases
-
[63]
a slice shows basal hypertrophyrelative tothe mid-ventricular slices
Phase 4 (cross-view fallback):if all Cine SAX content is exhausted and the budget is still not filled, we draw additional frames from Cine 4CH, starting with the central spatial layer’s cardiac cycle and expanding outward. Cine 3CH and Cine 4CH use analogous cascades, falling back to each other as the final phase. LGE switches from the fixed small-K split...
-
[64]
Wall thickness assessment: Describe the overall thickness of the LV myocardium across different segments (anterior, inferior, septal, lateral)
-
[65]
Uniformity analysis: Note whether thickness is uniform or heterogeneous across segments
-
[66]
Specific observations: Identify any segments showing thinning, thickening, or bulging
-
[67]
Frame-by-frame consistency: Describe if thickness characteristics remain consistent across cardiac cycle frames
-
[68]
patchy subepicardial high signal in the basal inferolateral wall
Comparison to normal: Compare observed thickness patterns to what would be expected in normal myocardium. Example structure: "The LV myocardium shows [uniform/heterogeneous] thickness. [Specific segment observations]. [Comparison across frames]. This pattern indicates [normal/thinned/thickened/bulging] characteristics." Report Generation.Report generation...
-
[69]
Segment identification: which parts of LV are visible
-
[70]
Enhancement presence by segment: basal / mid / apical / apex / Papillary Muscle
-
[71]
Distribution along long axis: where it starts and ends
-
[72]
Consistency across frames: persists vs transient artifact
-
[73]
Options: A
Final selected segments. Options: A. Basal Segment B. Mid Segment C. Apical Segment D. Apex E. Papillary Muscle Model output: B,C,D Reason:
-
[74]
Segment identification: the images show short- and long-axis views of the left ventricle
-
[75]
Enhancement presence by segment: a prominent high-signal region of late gadolinium enhancement is visible in the mid-ventricular and apical myocardium
-
[76]
Distribution along long axis: the high-signal area begins in the mid segment and extends through the apical segment, involving the apex itself;the basal segment appears relatively spared
-
[77]
Consistency across frames: the enhancement is consistent across multiple slices, confirming a real myocardial finding rather than a transient artifact
-
[78]
the basal segment appears relatively spared,
Final selected segments: Mid (B), Apical (C), Apex (D). Prompt Prediction TP FP FN P / R / F1 (%) Standard A,B,C,D,E {A,B} {C,D,E}∅40.0 /100.0/ 57.1 Reasoning B,C,D {B} {C,D} {A} 33.3 /50.0/ 40.0 Analysis.The reasoning response reads as a coherent radiology note, yet it commits a decisive visual error: it asserts that “the basal segment appears relatively...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.