Benchmarking Recursive-Collapse Warning Claims Under Matched False-Positive Control
Pith reviewed 2026-06-28 21:01 UTC · model grok-4.3
The pith
A benchmark framework tests recursive-collapse warnings under a locked 3-7% false-positive contract and reports non-acceptance as a first-class outcome.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
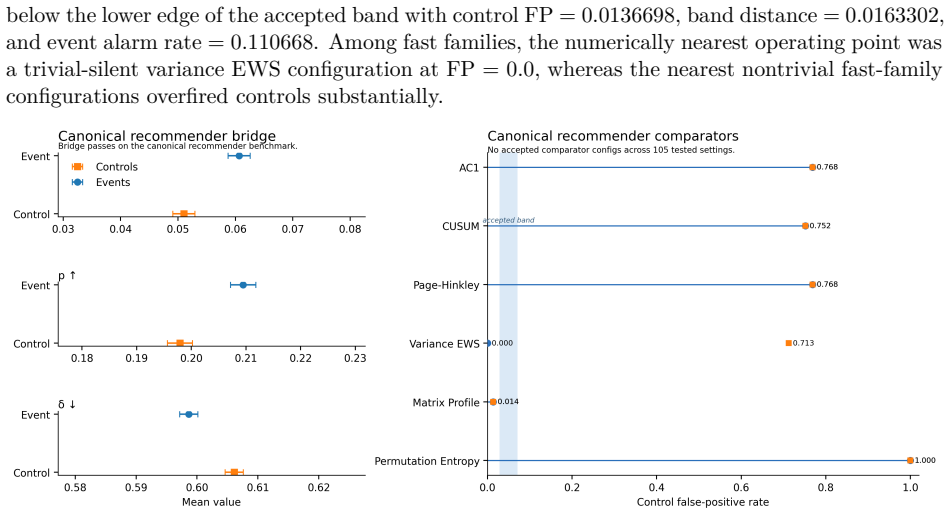
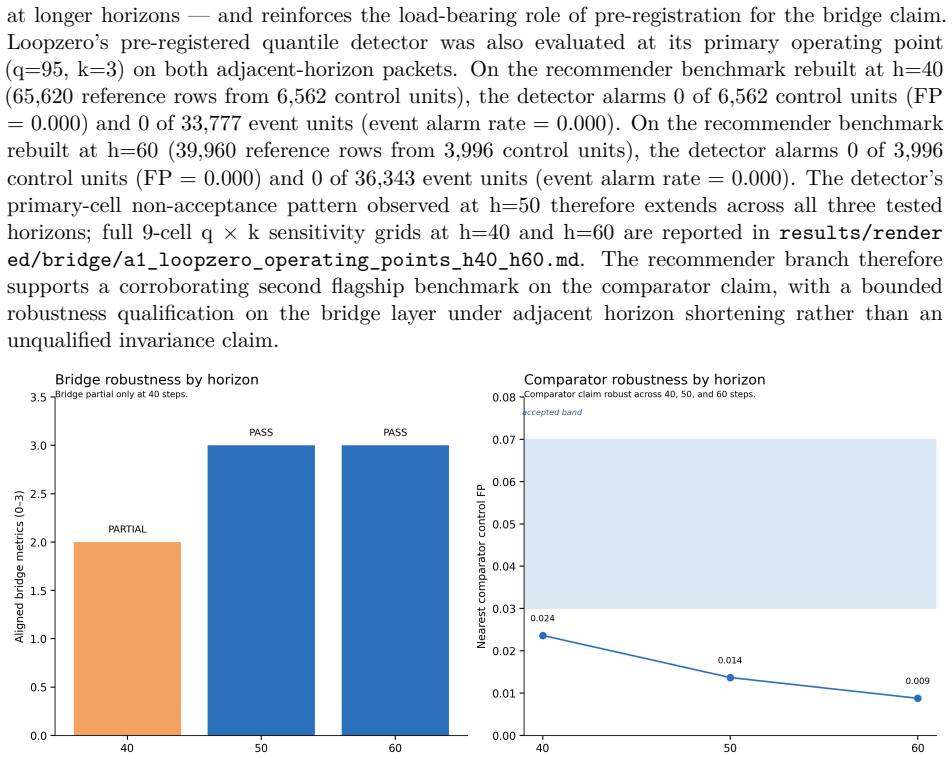
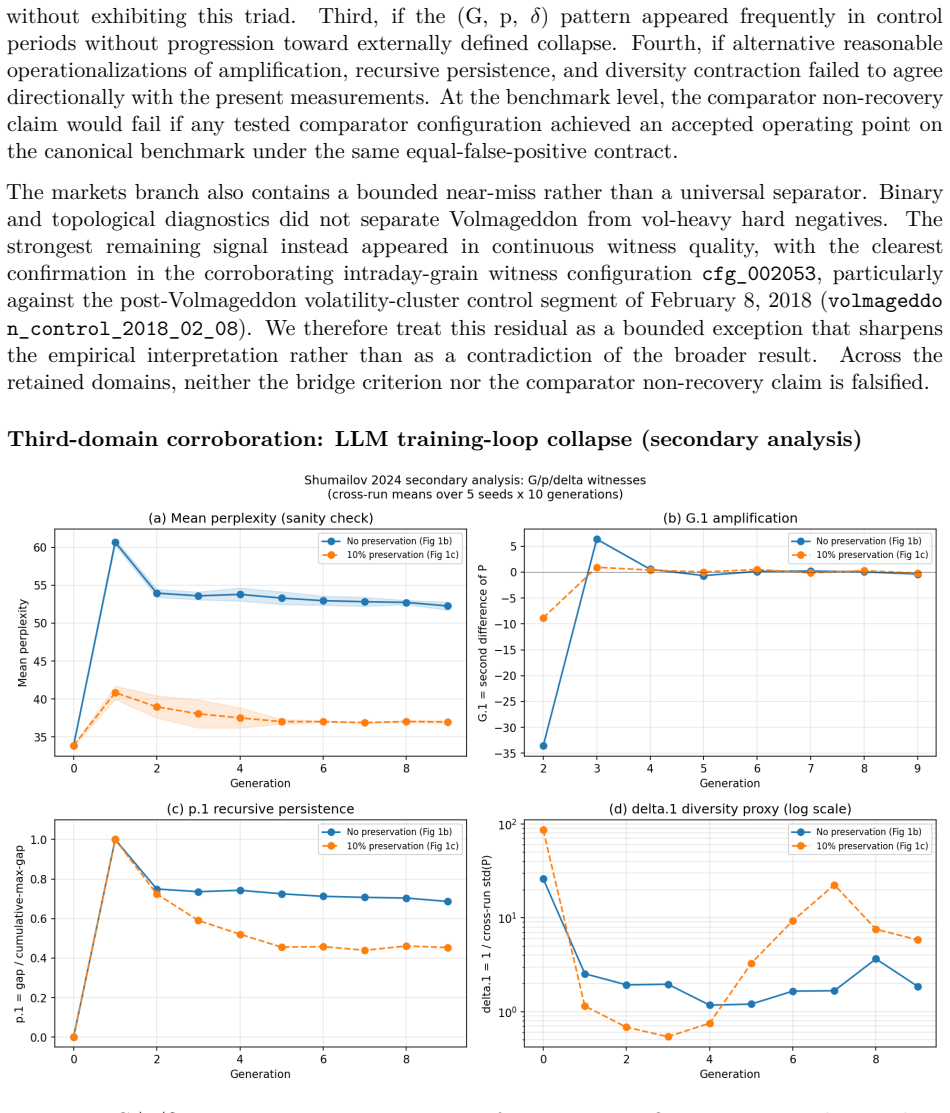
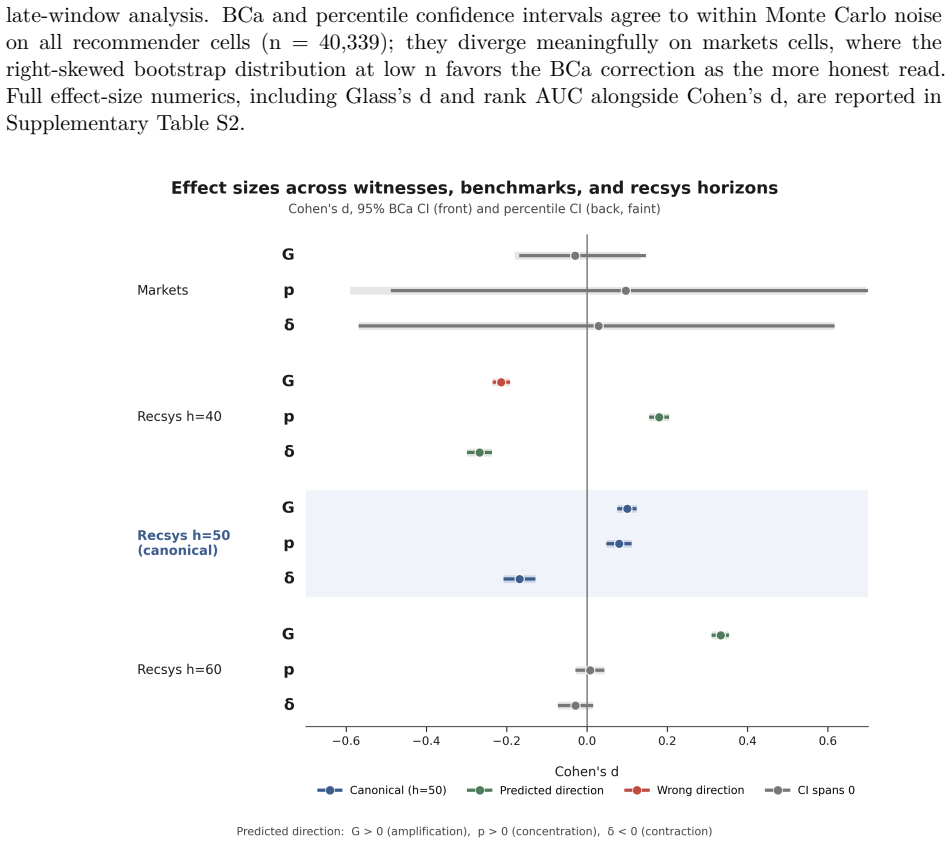
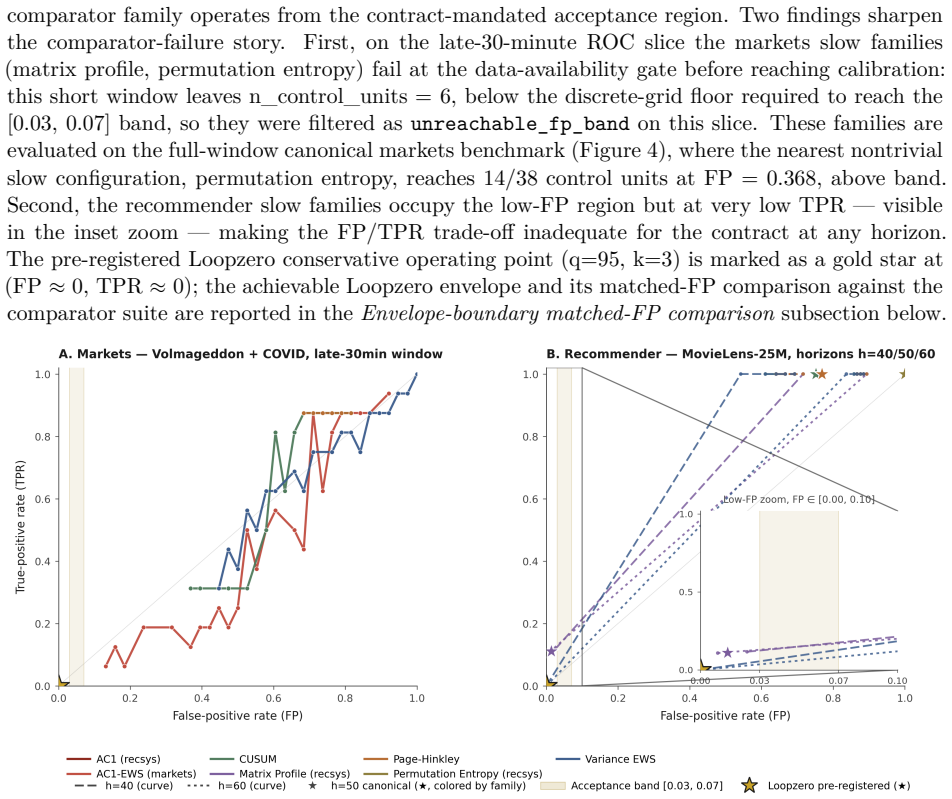
Loopzero supplies a claim-bounded benchmark framework in which recursive-collapse warning claims are evaluated only under an explicit, locked false-positive contract with FP rates fixed between 0.03 and 0.07. On two frozen public-artifact benchmarks the paper finds that no tested detector, including its pre-registered quantile detector, achieves an accepted operating point. Directional alignment of the telemetry pattern holds on both benchmarks, while adjacent-horizon and row-level limitations are disclosed. Digitized trajectories from an earlier LLM study are also directionally consistent, though matched-FP evaluation in that domain is left for later work.
What carries the argument
Loopzero, a claim-bounded benchmark framework that enforces a pre-registered equal-false-positive contract so every detector faces the identical alert budget on frozen benchmarks.
If this is right
- Detectors for recursive collapse can now be compared under identical alert budgets rather than differing sensitivities.
- Non-acceptance under the contract counts as a valid scientific result when evaluating warning claims.
- The same contract and frozen data can be reused to test additional detectors without changing the alert budget.
- Directional consistency of the gain-persistence-diversity pattern can be checked separately from whether any detector meets the budget.
- The framework can be applied to additional domains such as LLM training loops once matched false-positive evaluation is performed there.
Where Pith is reading between the lines
- The framework could be extended to streaming data if the same frozen telemetry patterns become available in real time.
- Similar locked-budget benchmarks might be constructed for other self-reinforcing systems such as power grids or biological feedback loops.
- If the directional pattern proves stable across more datasets, it would point to measurable early-warning windows before visible failure occurs.
Load-bearing premise
The directional telemetry pattern of rising gain, recursive persistence, and declining diversity accurately identifies collapse-like regimes in the chosen benchmarks before overt failure.
What would settle it
Re-running the same frozen benchmarks with any detector that produces an accepted operating point inside the pre-registered 0.03-0.07 false-positive window would show whether the non-acceptance result is detector-specific or inherent to the framework.
Figures


read the original abstract
Recursive systems can enter collapse-like regimes -- self-reinforcing amplification, persistent recursion, and narrowing diversity that mask accelerating internal degradation -- before overt failure becomes visible. We introduce Loopzero, a claim-bounded benchmark framework for testing whether recursive failures follow a directional telemetry pattern: rising gain (G), recursive persistence (p), and declining diversity ($\delta$). The claim boundary is specified in Lean; the Lean artifact does not verify real telemetry, benchmark validity, or detector performance. We evaluate the bridge on two frozen public-artifact benchmarks: a segmented public-markets benchmark (Volmageddon 2018, COVID MWCB 2020) and a MovieLens-25M offline deterministic recommender replay. Detectors are evaluated under a locked equal-false-positive contract (FP $\in$ [0.03, 0.07], pre-registered) so all configurations face the same alert budget. Neither tested standard comparators nor Loopzero's pre-registered quantile detector achieved an accepted operating point. Directional witness alignment held on both canonical benchmarks, with adjacent-horizon and row-level limitations disclosed. Digitized Shumailov et al. (2024) LLM training-loop trajectories are directionally consistent with the pattern; matched-FP evaluation in that domain is deferred. The contribution is a reproducible, falsifiable benchmark framework for evaluating recursive-collapse warning claims under an explicit alert-budget contract -- non-acceptance reported as a first-class scientific outcome.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Loopzero, a claim-bounded benchmark framework for testing recursive-collapse warning claims via a directional telemetry pattern (rising gain G, recursive persistence p, declining diversity δ). The claim boundary is formalized in Lean, but the artifact explicitly does not verify real telemetry, benchmark validity, or detector performance. Evaluations on frozen public benchmarks (segmented markets data from Volmageddon 2018 and COVID MWCB 2020; MovieLens-25M recommender replay) use a locked equal-FP contract (FP ∈ [0.03, 0.07]); neither standard comparators nor the pre-registered quantile detector reach an accepted operating point. Directional alignment is reported, with adjacent-horizon and row-level limitations disclosed. Non-acceptance is positioned as a first-class outcome. Digitized Shumailov et al. (2024) trajectories are noted as directionally consistent, with matched-FP evaluation deferred.
Significance. If the framework is adopted, it supplies a reproducible, falsifiable protocol for evaluating collapse-warning claims under an explicit alert-budget contract. Treating non-acceptance as valid and disclosing that the Lean spec does not verify telemetry or benchmarks are explicit strengths that reduce over-claim risk. The matched-FP design and public-artifact benchmarks enable direct replication.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly cross-reference the precise Lean theorem or claim-boundary definition (e.g., by theorem name or file) so readers can locate the formal boundary without ambiguity.
- Notation for the telemetry variables G, p, and δ is introduced in the abstract but would benefit from a dedicated definitions subsection or table in the main text to ensure consistent usage across the benchmarks section.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, clear summary of the claim-bounded framework, and recommendation to accept. The report correctly identifies the core contribution (reproducible protocol under locked FP budget, non-acceptance as valid outcome, Lean spec boundaries) and the explicit limitations disclosed in the manuscript.
Circularity Check
No significant circularity; framework claim is self-contained
full rationale
The manuscript introduces Loopzero as a claim-bounded benchmark framework under an explicit alert-budget contract, with non-acceptance treated as a first-class outcome. It explicitly states that the Lean artifact specifies only the claim boundary and does not verify telemetry, benchmark validity, or detector performance. No equations, fitted parameters, or self-citations are presented as deriving the directional pattern (G, p, δ) or the benchmarks; the contribution is the reproducible evaluation protocol itself. The reported outcomes (no accepted operating point, directional alignment with disclosed limitations) are consistent with the framework's design rather than reducing to it by construction. This meets the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recursive systems can enter collapse-like regimes characterized by rising gain (G), recursive persistence (p), and declining diversity (δ) before overt failure.
invented entities (1)
-
Loopzero
no independent evidence
Forward citations
Cited by 1 Pith paper
-
When Top-1 Fails: Calibrating LoRA Monitors for Masked Diffusion LMs
Empirical test shows top-1 argmax concentration has zero precision as collapse warning in DLM LoRA training due to pre-equilibrium saturation while max gradient norm provides usable but family-specific detection on sh...
Reference graph
Works this paper leans on
-
[1]
Augustin, P., Cheng, I.-H. and Van den Bergen, L. (2021). Volmageddon and the failure of short volatility products. Financial Analysts Journal . https://doi.org/10.1080/0015198X.2021.1913040 Bandt, C. and Pompe, B. (2002). Permutation entropy: a natural complexity measure for time series. Physical Review Letters, 88, 174102. https://doi.org/10.1103/PhysRe...
-
[2]
https://www.sec.gov/news/studies/2010/marketevents-report.pdf Chaney, A.J.B., Stewart, B.M
Report, SEC / CFTC. https://www.sec.gov/news/studies/2010/marketevents-report.pdf Chaney, A.J.B., Stewart, B.M. and Engelhardt, B.E. (2018). How algorithmic confounding in recommendation systems increases homogeneity and decreases utility. ACM RecSys. https://doi. org/10.1145/3240323.3240370 Dakos, V., Carpenter, S.R., Brock, W.A., Ellison, A.M., Guttal, ...
-
[3]
Loopzero at envelope boundary (q=50, k=3): 11 false alarms / 4755 controls (FP=0.002313), 2681 true detections / 35584 events (TPR=0.0753)
(3559, 33777) 3559 6 Panel: recsys_h50 Panel n_control_units=4755, n_event_units=35584. Loopzero at envelope boundary (q=50, k=3): 11 false alarms / 4755 controls (FP=0.002313), 2681 true detections / 35584 events (TPR=0.0753). 5 family status lower (ctrl, evt) upper (ctrl, evt) gap n_bp no comparator breakpoint at this boundary FP insufficient_data— — — ...
2004
-
[4]
— the methodologically appropriate response to the small-cluster regime — is deferred to follow-up work. Effect sizes at scenario grain (B3) Witness Measure Point Percentile 95% CI BCa 95% CI G cohens_d -0.0293 [-0.0916, +0.0489] [-0.0932, +0.0473] G glasss_d -0.0285 [-0.0934, +0.0472] [-0.0938, +0.0472] G rank_auc +0.5073 [+0.4569, +0.5581] [+0.4520, +0....
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.