Zamba2-VL Technical Report
Pith reviewed 2026-06-28 22:32 UTC · model grok-4.3
The pith
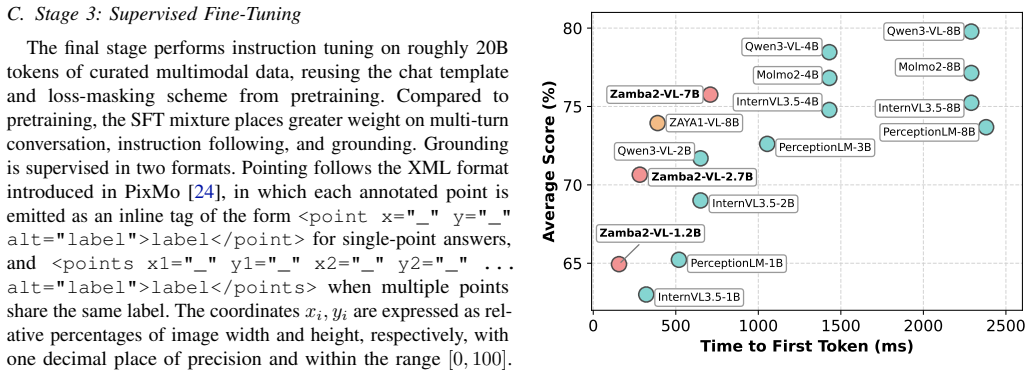
Zamba2-VL matches leading transformer vision-language models on accuracy benchmarks while cutting time-to-first-token by roughly ten times at matched scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Zamba2-VL shows that a hybrid architecture of Mamba2 state-space layers plus a limited set of shared transformer blocks can deliver competitive accuracy on a wide suite of vision-language benchmarks while inheriting near-linear prefill compute and a small constant recurrent state from its backbone, resulting in substantially lower time-to-first-token than pure transformer models of the same parameter count.
What carries the argument
Zamba2 hybrid architecture that interleaves Mamba2 state-space layers with a small number of shared transformer blocks to combine linear-time prefill scaling with selective attention capacity.
If this is right
- The 1.2B, 2.7B, and 7B models reach parity with current top open-weight transformer VLMs on standard image and multimodal tasks.
- Time-to-first-token drops by approximately an order of magnitude relative to transformer baselines of equal size.
- The efficiency advantage widens at the smallest scales, directly benefiting on-device and edge inference.
- The models outperform all previously reported SSM-based and hybrid vision-language models on the same benchmark suite.
- Public release of weights and inference code enables immediate use and further community scaling.
Where Pith is reading between the lines
- The same hybrid pattern could be tested on video or audio inputs to check whether the TTFT savings persist in longer-sequence multimodal settings.
- If the recurrent state remains small under continued scaling, the approach might support longer context windows without the quadratic cost of full attention.
- Device-level deployment at 1-3B parameters becomes more practical once the first-token latency falls into the sub-100 ms range on typical mobile hardware.
Load-bearing premise
Benchmark scores and time-to-first-token measurements were collected under training data, evaluation protocols, and hardware conditions identical to those used for the cited transformer and prior hybrid baselines.
What would settle it
A controlled side-by-side run of Zamba2-VL and a matched transformer model on the same hardware, identical training data mixture, and fixed evaluation prompts that either eliminates the reported TTFT gap or shows a clear accuracy drop.
Figures

read the original abstract
We present Zamba2-VL, a suite of vision-language models built on Zamba2, a hybrid language-model architecture combining Mamba2 state-space layers with a small number of shared transformer blocks. Across a broad range of image understanding, reasoning, OCR, grounding, and counting benchmarks, Zamba2-VL is competitive with leading Transformer-based open-weight VLMs of comparable scale, including the Molmo2, Qwen3-VL, and InternVL3.5 families, and substantially outperforms prior SSM-based and hybrid VLMs such as VL-Mamba, Cobra, and mmMamba. Inheriting the near-linear prefill compute and small, near-constant recurrent state of its Zamba2 backbone, Zamba2-VL delivers roughly an order of magnitude lower time-to-first-token (TTFT) than these Transformer baselines at matched parameter scale, with the efficiency gap most pronounced at the smaller 1.2B and 2.7B scales most relevant to on-device and edge deployment. We release three models -- 1.2B, 2.7B, and 7B -- together with inference code at https://huggingface.co/collections/Zyphra/zamba2-vl.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Zamba2-VL, a family of vision-language models (1.2B, 2.7B, 7B parameters) built on the Zamba2 hybrid architecture that combines Mamba2 state-space layers with a small number of shared transformer blocks. It claims these models are competitive with leading open-weight Transformer VLMs (Molmo2, Qwen3-VL, InternVL3.5) across image understanding, reasoning, OCR, grounding, and counting benchmarks, substantially outperform prior SSM/hybrid VLMs (VL-Mamba, Cobra, mmMamba), and deliver roughly 10x lower time-to-first-token latency than Transformer baselines at matched scale, with the largest gains at smaller sizes. The work releases the three models and inference code.
Significance. If the benchmark and latency claims hold under matched training data, optimization, and evaluation conditions, the result would establish that hybrid Mamba2-Transformer designs can reach Transformer-level VLM accuracy while providing near-linear prefill scaling and constant-state inference, with particular value for on-device and edge deployment. The public release of models and code is a positive contribution to reproducibility in efficient VLM research.
major comments (2)
- [Abstract and benchmark results section] Abstract and benchmark results section: the central claim that Zamba2-VL is competitive with Molmo2/Qwen3-VL/InternVL3.5 and delivers an order-of-magnitude TTFT reduction attributes these outcomes to the hybrid architecture, yet no explicit statement confirms that pretraining corpus size, instruction-tuning data volume/quality, optimization schedule, evaluation prompts, or hardware match those used for the cited baselines; without such controls the performance gap cannot be isolated from data or tuning differences.
- [Training details section] Training details section: the manuscript does not report the total tokens seen during pretraining or the composition of the vision-language instruction data relative to the baselines, which is load-bearing for the claim that the architecture (rather than data scale) drives competitiveness.
minor comments (2)
- Figure captions and table footnotes should explicitly state the evaluation harness, prompt templates, and whether zero-shot or few-shot settings were used for each benchmark to allow direct replication.
- The abstract states 'roughly an order of magnitude lower TTFT'; the main text should report exact measured values with hardware specifications and batch size for both Zamba2-VL and the Transformer baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for clearer statements on training controls. The efficiency claims stem directly from the Zamba2 architecture and were measured under consistent inference conditions; the accuracy claims report observed competitiveness without asserting isolation from data differences. We will revise the manuscript to make these distinctions explicit and to include available details on our training data. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract and benchmark results section] Abstract and benchmark results section: the central claim that Zamba2-VL is competitive with Molmo2/Qwen3-VL/InternVL3.5 and delivers an order-of-magnitude TTFT reduction attributes these outcomes to the hybrid architecture, yet no explicit statement confirms that pretraining corpus size, instruction-tuning data volume/quality, optimization schedule, evaluation prompts, or hardware match those used for the cited baselines; without such controls the performance gap cannot be isolated from data or tuning differences.
Authors: We agree that the manuscript does not explicitly state matched conditions across all dimensions. The TTFT reduction is architectural (inherited from Zamba2's near-linear prefill and constant-state inference) and was measured on identical hardware and inference settings; this claim does not depend on training data. The benchmark competitiveness is reported as observed performance without claiming it results solely from the architecture. We will revise the abstract and results section to separate these claims, add an explicit caveat that training conditions are not matched, and note that evaluation prompts and hardware were standardized for our latency measurements. This revision clarifies the scope without overstating architectural impact on accuracy. revision: yes
-
Referee: [Training details section] Training details section: the manuscript does not report the total tokens seen during pretraining or the composition of the vision-language instruction data relative to the baselines, which is load-bearing for the claim that the architecture (rather than data scale) drives competitiveness.
Authors: The manuscript is a technical report focused on the hybrid architecture and resulting efficiency/accuracy rather than exhaustive training ablations. We do not claim architecture alone drives competitiveness. Our own pretraining and instruction-tuning details (token counts and data sources) were omitted to keep the report concise; we will add them in a revised training-details section or appendix. Direct side-by-side comparison of data composition with the cited baselines is not feasible, as their full pretraining corpora and instruction data mixtures are not fully disclosed in public reports. The revised text will avoid any implication of matched data scales. revision: partial
Circularity Check
No circularity: empirical performance claims rest on external benchmarks
full rationale
The paper is a technical report presenting Zamba2-VL models and their benchmark results against external baselines. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing premises appear in the provided text. Claims of competitiveness and TTFT improvements are framed as direct empirical observations rather than reductions to quantities defined by the authors' own choices, so the report is self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4v(ision) system card
OpenAI. Gpt-4v(ision) system card. September 2023. Accessed: 2026-04-10
2023
-
[2]
Deepseek-ocr: Contexts optical compression, 2025
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression, 2025
2025
-
[3]
olmocr 2: Unit test rewards for document ocr, 2025
Jake Poznanski, Luca Soldaini, and Kyle Lo. olmocr 2: Unit test rewards for document ocr, 2025
2025
-
[4]
Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning, 2025
LASA Team, Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, Yu Sun, Junao Shen, Chaojun Wang, Jie Tan, Deli Zhao, Tingyang Xu, Hao Zhang, and Yu Rong. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning, 2025
2025
-
[5]
Towards medical complex reasoning with llms through medical verifiable problems
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, and Benyou Wang. Towards medical complex reasoning with llms through medical verifiable problems. pages 14552–14573, 01 2025
2025
-
[6]
Ui-tars- 2 technical report: Advancing gui agent with multi-turn reinforcement learning, 2025
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, Wanjun Zhong, Yining Ye, Yujia Qin, Yuwen Xiong, et al. Ui-tars- 2 technical report: Advancing gui agent with multi-turn reinforcement learning, 2025
2025
-
[7]
OpenCUA: Open foundations for computer- use agents
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, Zhennan Shen, Zhuokai Li, et al. OpenCUA: Open foundations for computer- use agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[8]
Molmoweb: Open visual web agent and open data for the open web, 2026
Tanmay Gupta, Piper Wolters, Zixian Ma, Peter Sushko, Rock Yuren Pang, Diego Llanes, Yue Yang, Taira Anderson, Boyuan Zheng, Zhongzheng Ren, Harsh Trivedi, Taylor Blanton, Caleb Ouellette, Winson Han, Ali Farhadi, and Ranjay Krishna. Molmoweb: Open visual web agent and open data for the open web, 2026
2026
-
[9]
Openvla: An open- source vision-language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, et al. Openvla: An open- source vision-language-action model. In Pulkit Agrawal, Oliver Kroemer, and Wolfram Burgard, editors,Proceed- ings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learning Research, pages 2679–2713. PMLR, 06–09 Nov 2025
2025
-
[10]
Gemini robotics: Bringing ai into the physical world, 2025
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, Steven Bohez, Konstantinos Bousmalis, Anthony Brohan, Thomas Buschmann, Arunkumar Byravan, Serkan Cabi, Ken Caluwaerts, et al. Gemini robotics: Bringing ai into the ...
2025
-
[11]
From vision to action: En- abling real-world agentic VLMs
Aravilli Atchuta Ram. From vision to action: En- abling real-world agentic VLMs. In1st Workshop on VLM4RWD @ NeurIPS 2025, 2025
2025
-
[12]
DriveLM: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. DriveLM: Driving with graph visual question answering. In First Vision and Language for Autonomous Driving and Robotics Workshop, 2024
2024
-
[13]
Waslan- der, Yu Liu, and Hongsheng Li
Hao Shao, Yuxuan Hu, Letian Wang, Steven L. Waslan- der, Yu Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15120–15130, 2023
2024
-
[14]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, 2021
2021
-
[15]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollar, and Ross Girshick. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, October 2023
2023
-
[17]
Oriane Sim ´eoni, Huy V . V o, Maximilian Seitzer, Fed- 9 erico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Rama- monjisoa, Francisco Massa, Daniel Haziza, et al. Dinov3, 2025
2025
-
[18]
Flamingo: a visual language model for few-shot learning
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, An- toine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
2022
-
[19]
Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[21]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, et al. Qwen3-vl technical report, 2025
2025
-
[22]
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025
2025
-
[23]
Glm-4.5v and glm-4.1v- thinking: Towards versatile multimodal reasoning with scalable reinforcement learning, 2026
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5v and glm-4.1v- thinking: Towards versatile multimodal reasoning with scalable reinforcement learning, 2026
2026
-
[24]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceed- ings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025
2025
-
[25]
Gpt-4 technical report, 2024
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, et al. Gpt-4 technical report, 2024
2024
-
[26]
The claude model card addendum - claude 3.5 family, 2024
Anthropic. The claude model card addendum - claude 3.5 family, 2024
2024
-
[27]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
2024
-
[28]
Transformer upgrade road: 4
Su Jianlin. Transformer upgrade road: 4. Rotating position coding of two-dimensional positions, May 2021
2021
-
[29]
Transformer upgrade road: 17
Su Jianlin. Transformer upgrade road: 17. Simple Thinking of Multimodal Position Coding, Mar 2024
2024
-
[30]
Rotary position embedding for vision transformer
Byeongho Heo, Song Park, Dongyoon Han, and Sangdoo Yun. Rotary position embedding for vision transformer. InEuropean Conference on Computer Vision (ECCV), volume 15068 ofLecture Notes in Computer Science, pages 289–305. Springer, 2024
2024
-
[31]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Haoyu Liu, Sucheng Ren, Tingyu Zhu, Peng Wang, Cihang Xie, Alan Yuille, Zeyu Zheng, and Feng Wang. Spiral rope: Rotate your rotary positional embeddings in the 2d plane.arXiv preprint arXiv:2602.03227, 2026
-
[33]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models.ICCV, 2025
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models.ICCV, 2025
2025
-
[34]
Pvc: Progressive visual token compression for unified image and video processing in large vision-language models
Chenyu Yang, Xuan Dong, Xizhou Zhu, Weijie Su, Jiahao Wang, Hao Tian, Zhe Chen, Wenhai Wang, Lewei Lu, and Jifeng Dai. Pvc: Progressive visual token compression for unified image and video processing in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24939–24949, 2025
2025
-
[35]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
From pixels to words – towards native vision-language primitives at scale
Haiwen Diao, Mingxuan Li, Silei Wu, Linjun Dai, Xiaohua Wang, Hanming Deng, Lewei Lu, Dahua Lin, and Ziwei Liu. From pixels to words – towards native vision-language primitives at scale. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[37]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Transformers are SSMs: Gener- alized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Gener- alized models and efficient algorithms through structured state space duality. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[39]
Vision mamba: Efficient visual representation learning with bidirectional state space model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[40]
VMamba: Visual state space model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. VMamba: Visual state space model. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[41]
Yanyuan Qiao, Zheng Yu, Longteng Guo, Sihan Chen, Zijia Zhao, Mingzhen Sun, Qi Wu, and Jing Liu. VL- Mamba: Exploring state space models for multimodal learning.arXiv preprint arXiv:2403.13600, 2024
-
[42]
Han Zhao, Min Zhang, Wei Zhao, Pengxiang Ding, Siteng Huang, and Donglin Wang. Cobra: Extending 10 mamba to multi-modal large language model for efficient inference.arXiv preprint arXiv:2403.14520, 2024
-
[43]
Georgios Abouelenin, Eva Triantafyllou, Derry Wijaya, and Ellie Pavlick. Shaking up VLMs: Comparing transformers and structured state space models for vision & language modeling.arXiv preprint arXiv:2409.05395, 2024
-
[44]
Bencheng Liao, Hongyuan Tao, Qian Zhang, Tianheng Cheng, Yingyue Li, Haoran Yin, Wenyu Liu, and Xinggang Wang. Multimodal mamba: Decoder-only multimodal state space model via quadratic to linear distillation.arXiv preprint arXiv:2502.13145, 2025
-
[45]
arXiv preprint arXiv:2411.15242 , year=
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, Anna Golubeva, Vasudev Shyam, James Whittington, Jonathan Pilault, and Beren Millidge. The Zamba2 suite: Technical report.arXiv preprint arXiv:2411.15242, 2024
-
[46]
Zamba: A compact 7B SSM hybrid model
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, and Beren Millidge. Zamba: A compact 7B SSM hybrid model. arXiv preprint arXiv:2405.16712, 2024
-
[47]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language models with video understanding and grounding.arXiv preprint arXiv:2601.10611, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Jang Hyun Cho, Andrea Madotto, Effrosyni Mavroudi, Triantafyllos Afouras, Tushar Nagarajan, Muhammad Maaz, Yale Song, Tengyu Ma, Shuming Hu, Suyog Jain, et al. Perceptionlm: Open-access data and mod- els for detailed visual understanding.arXiv preprint arXiv:2504.13180, 2025
-
[49]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, Ziyong Feng, Ziwei Liu, Bo Li, and Jiankang Deng. Llava-onevision-1.5: Fully open framework for democratized multimodal training....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305, Singapore, December 2023. Association for Computational Linguistics
2023
-
[52]
Do you see me : A multidimensional benchmark for evaluating visual perception in multimodal LLMs
Aditya Sanjiv Kanade and Tanuja Ganu. Do you see me : A multidimensional benchmark for evaluating visual perception in multimodal LLMs. In Vera Demberg, Kentaro Inui, and Llu ´ıs Marquez, editors,Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7285–7326, Rabat, Moro...
-
[53]
Association for Computational Linguistics
-
[54]
Dash: Detection and assessment of systematic hallucinations of vlms
Maximilian Augustin, Yannic Neuhaus, and Matthias Hein. Dash: Detection and assessment of systematic hallucinations of vlms. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[55]
Eureka: Intelligent feature engineering for enterprise AI cloud resource demand prediction
Hangxuan Li, Renjun Jia, Xuezhang Wu, zeqi zheng, Yunjie Qian, and Xianling Zhang. Eureka: Intelligent feature engineering for enterprise AI cloud resource demand prediction. In1st Workshop on VLM4RWD @ NeurIPS 2025, 2025
2025
-
[56]
Khan, Waseem Ullah, and Mohsen Guizani
Ahmed Sharshar, Latif U. Khan, Waseem Ullah, and Mohsen Guizani. Vision-language models for edge networks: A comprehensive survey.IEEE Internet of Things Journal, 12(16):32701–32724, 2025
2025
-
[57]
Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models
Jiaming Zhang, Junhong Ye, Xingjun Ma, Yige Li, Yunfan Yang, Chen Yunhao, Jitao Sang, and Dit-Yan Yeung. Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[58]
AdvEDM: Fine- grained adversarial attack against VLM-based embodied agents
Yichen Wang, Hangtao Zhang, Hewen Pan, Ziqi Zhou, Xianlong Wang, Peijin Guo, Lulu Xue, Shengshan Hu, Minghui Li, and Leo Yu Zhang. AdvEDM: Fine- grained adversarial attack against VLM-based embodied agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[59]
Scene understanding via scene representation generation with vision-language models
Yuan Chen and Peng Shi. Scene understanding via scene representation generation with vision-language models. In1st Workshop on VLM4RWD @ NeurIPS 2025, 2025
2025
-
[60]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455– 14465, 2024
2024
-
[61]
Mmdrive: Interactive scene un- derstanding beyond vision with multi-representational fusion.Information Fusion, 133:104314, 2026
Minghui Hou, Wei-Hsing Huang, Shaofeng Liang, Daizong Liu, Tai-Hao Wen, Gang Wang, Runwei Guan, and Weiping Ding. Mmdrive: Interactive scene un- derstanding beyond vision with multi-representational fusion.Information Fusion, 133:104314, 2026
2026
-
[62]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Deng, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
MambaVision: A hybrid mamba-transformer vision backbone.arXiv preprint arXiv:2407.08083, 2024
Ali Hatamizadeh and Jan Kautz. MambaVision: A hybrid mamba-transformer vision backbone.arXiv preprint arXiv:2407.08083, 2024
-
[65]
Samy Jelassi, David Brandfonbrener, Sham M. Kakade, and Eran Malach. Repeat after me: Transformers are better than state space models at copying.arXiv preprint 11 arXiv:2402.01032, 2024
-
[66]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avshalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, and Yoav Shoham. Jamba: A hybrid transformer-mamba languag...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Laion-5b: an open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: an open large-scale dataset for training next generation image-text models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22. Cu...
2022
-
[68]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server.ArXiv, abs/1504.00325, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[69]
Conceptual captions: A cleaned, hy- pernymed, image alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hy- pernymed, image alt-text dataset for automatic image captioning. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, Melbourne, Australia...
2018
-
[70]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. InComputer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part XVII, page 370–387, Berlin, Heidelberg, 2024. Springer-Verlag
2024
-
[71]
MiniGPT-4: Enhancing vision- language understanding with advanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing vision- language understanding with advanced large language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[72]
Tallyqa: Answering complex counting questions
Manoj Acharya, Kushal Kafle, and Christopher Kanan. Tallyqa: Answering complex counting questions. InPro- ceedings of the AAAI conference on artificial intelligence, volume 33, pages 8076–8084, 2019
2019
-
[73]
Synthetic data for text localisation in natural images
Ankush Gupta, Andrea Vedaldi, and Andrew Zisserman. Synthetic data for text localisation in natural images. InIEEE Conference on Computer Vision and Pattern Recognition, 2016
2016
-
[74]
Ocr-vqa: Visual question an- swering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question an- swering by reading text in images. In2019 International Conference on Document Analysis and Recognition (ICDAR), pages 947–952, 2019
2019
-
[75]
Plotqa: Reasoning over scientific plots
Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar. Plotqa: Reasoning over scientific plots. InProceedings of the ieee/cvf winter conference on applications of computer vision, pages 1527–1536, 2020
2020
-
[76]
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, ´Akos K ´ad´ar, Adam Trischler, and Yoshua Bengio. Figureqa: An annotated figure dataset for visual reasoning.arXiv preprint arXiv:1710.07300, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[77]
Dvqa: Understanding data visualizations via question answering
Kushal Kafle, Brian Price, Scott Cohen, and Christopher Kanan. Dvqa: Understanding data visualizations via question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5648–5656, 2018
2018
-
[78]
Effective training data synthesis for improving mllm chart understanding
Yuwei Yang, Zeyu Zhang, Yunzhong Hou, Zhuowan Li, Gaowen Liu, Ali Payani, Yuan-Sen Ting, and Liang Zheng. Effective training data synthesis for improving mllm chart understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2653–2663, 2025
2025
-
[79]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Jing Li, Xiangyu Zhang, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[80]
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.International Journal of Computer Vision, 128:1956–1981, 2020
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, Tom Duerig, and Vittorio Ferrari. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.International Journal of Computer Vision, 128...
1956
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.