Exploiting weight-space symmetries for approximating curvature
Pith reviewed 2026-06-28 19:14 UTC · model grok-4.3
The pith
Averaging over loss-invariant weight-space symmetries constructs structured Hessian approximations from single gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
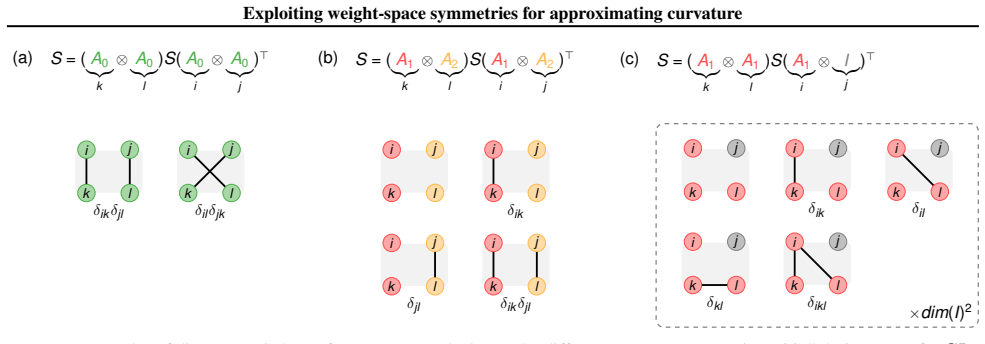
By analytically averaging over group actions that leave the loss invariant, we construct structured Hessian approximations from single gradients that can be tractably estimated, stored, and inverted. The choice of user-specified symmetry group directly governs the trade-off between approximation accuracy and computational cost. Moreover, our framework provides a unifying theoretical lens for viewing existing methods; in particular, a specific choice of symmetry group recovers Shampoo/Muon-like curvature estimates.
What carries the argument
Analytic averaging over weight-space symmetry group actions that leave the loss invariant, to produce structured Hessian approximations.
If this is right
- Structured Hessian approximations become available without requiring multiple independent gradient samples.
- Storage and inversion costs remain low enough for use inside second-order optimizers on deep networks.
- Existing methods such as Shampoo are recovered exactly when the symmetry group is chosen to match their implicit assumptions.
- The accuracy versus cost trade-off is set directly by the size and structure of the user-specified symmetry group.
Where Pith is reading between the lines
- The framework could support more efficient curvature-based pruning by highlighting directions of low approximated curvature.
- Connections to continual learning might arise if the structured approximations allow cheap updates to curvature estimates across tasks.
- The unifying lens suggests testing new symmetry groups that are architecture-specific rather than loss-invariant in the strict sense.
Load-bearing premise
The chosen symmetry group actions can be averaged analytically in closed form while preserving the essential curvature information without introducing new fitting parameters or post-hoc adjustments that depend on the specific loss or data.
What would settle it
On a small network where the exact Hessian can be computed directly, the analytically averaged approximation matches the true curvature poorly or leads to worse optimization performance than standard first-order methods.
Figures







read the original abstract
Many machine learning techniques rely on approximating a loss function's curvature, but this is notoriously hard to do at the scale of modern deep networks. Surprisingly, no previous work has exploited the curvature constraints that arise from well known weight-space symmetries in loss landscapes. By analytically averaging over group actions that leave the loss invariant, we construct structured Hessian approximations from single gradients that can be tractably estimated, stored, and inverted. The choice of user-specified symmetry group directly governs the trade-off between approximation accuracy and computational cost. Moreover, our framework provides a unifying theoretical lens for viewing existing methods; in particular, a specific choice of symmetry group recovers Shampoo/Muon-like curvature estimates. We validate our method on a range of network architectures, and deploy it to second-order optimization benchmarks, including a small language model. Our curvature estimation framework might find applications in other machine learning problems such as uncertainty estimation, continual learning, compression/pruning, training data attribution, and more.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that analytically averaging the Hessian over user-chosen weight-space symmetry group actions that leave the loss invariant yields structured curvature approximations computable from single gradients. These approximations are asserted to be tractably estimated, stored, and inverted, with the group choice controlling the accuracy-cost trade-off. A specific group recovers Shampoo/Muon-like forms, and the framework is validated on multiple network architectures plus a small language-model second-order optimization benchmark.
Significance. If the central analytical averaging holds exactly in closed form without new fitting parameters or architecture-specific adjustments, the work supplies a parameter-free unifying lens on existing curvature methods and a practical route to structured second-order information at scale. The explicit recovery of prior methods and the benchmark deployment are concrete strengths.
major comments (2)
- [§3] §3 (core construction): the claim that the group-averaged Hessian can be obtained in closed form from a single gradient while exactly preserving curvature information rests on the assumption that the chosen G commutes with the loss for arbitrary nonlinearities; no explicit expansion of residual terms is shown when biases or LayerNorm break exact invariance.
- [Abstract, §5] Abstract and §5 (validation): the reported recovery of Shampoo/Muon forms is load-bearing for the unification claim, yet the manuscript provides no side-by-side quantitative comparison of the derived approximation against the true Hessian on even a toy network where the symmetry is known to hold exactly.
minor comments (2)
- Notation for the group action and the averaged operator is introduced without a compact table of symbols, making cross-references between the general construction and the Shampoo special case harder to follow.
- Figure captions for the language-model benchmark do not state the precise optimizer step-size schedule or number of independent runs, complicating reproducibility of the reported gains.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (core construction): the claim that the group-averaged Hessian can be obtained in closed form from a single gradient while exactly preserving curvature information rests on the assumption that the chosen G commutes with the loss for arbitrary nonlinearities; no explicit expansion of residual terms is shown when biases or LayerNorm break exact invariance.
Authors: We agree that the derivation assumes the chosen group G leaves the loss exactly invariant. The framework targets user-specified groups satisfying this (e.g., weight permutations in bias-free linear layers). For biases or LayerNorm, exact invariance may fail and the result becomes an approximation. We will revise §3 to state the invariance conditions explicitly and add a short discussion of residual terms for approximate cases, including a simple illustrative expansion. revision: yes
-
Referee: [Abstract, §5] Abstract and §5 (validation): the reported recovery of Shampoo/Muon forms is load-bearing for the unification claim, yet the manuscript provides no side-by-side quantitative comparison of the derived approximation against the true Hessian on even a toy network where the symmetry is known to hold exactly.
Authors: The recovery is shown analytically. We concur that a direct numerical comparison to the true Hessian on a toy network (where symmetry holds exactly) would strengthen the claim. We will add such a side-by-side evaluation, e.g., on a small MLP, in a revised §5 or appendix. revision: yes
Circularity Check
No circularity: analytical averaging over symmetries is self-contained
full rationale
The paper's derivation constructs structured Hessian approximations directly from the analytical average over user-chosen group actions that leave the loss invariant, starting from single gradients. This is presented as a first-principles consequence of the symmetry without introducing fitted parameters, post-hoc adjustments, or reductions to prior fitted quantities. The unification with Shampoo/Muon is a special case obtained by group choice rather than an input assumption. No load-bearing self-citations, self-definitional steps, or fitted-input predictions are indicated; the framework remains independent of the target result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Runa Eschenhagen, Aaron Defazio, Tsung-Hsien Lee, Richard E
URL https://openreview.net/forum? id=dNigytemkL. Runa Eschenhagen, Aaron Defazio, Tsung-Hsien Lee, Richard E. Turner, and Hao-Jun Michael Shi. Puri- fying shampoo: Investigating shampoo’s heuristics by decomposing its preconditioner, 2025. URL https: //arxiv.org/abs/2506.03595. Kevin Frans, Pieter Abbeel, and Sergey Levine. What really matters in matrix-w...
-
[2]
Adam: A Method for Stochastic Optimization
URL https://kellerjordan.github. io/posts/muon/. Ta-Chu Kao, Kristopher Jensen, Gido van de Ven, Alberto Bernacchia, and Guillaume Hennequin. Natural continual learning: success is a journey, not (just) a destination. Advances in neural information processing systems, 34: 28067–28079, 2021. Andrej Karpathy. char-rnn. https://github.com/ karpathy/char-rnn,...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Yurii Nesterov et al.Lectures on convex optimization, vol- ume 137
URL https://openreview.net/forum? id=c6zI3Cp8c6. Yurii Nesterov et al.Lectures on convex optimization, vol- ume 137. Springer, 2018. Behnam Neyshabur, Russ R Salakhutdinov, and Nati Srebro. Path-sgd: Path-normalized optimization in deep neural networks.Advances in neural information processing systems, 28, 2015. Jorge Nocedal and Stephen J Wright.Numerica...
-
[4]
Faster gaze prediction with dense networks and Fisher pruning
URL https://proceedings.mlr.press/ v139/simsek21a.html. 11 Exploiting weight-space symmetries for approximating curvature Lucas Theis, Iryna Korshunova, Alykhan Tejani, and Ferenc Husz´ar. Faster gaze prediction with dense networks and fisher pruning.arXiv preprint arXiv:1801.05787, 2018. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Chaoqi Wang, Roger Grosse, Sanja Fidler, and Guodong Zhang
URL https://openreview.net/forum? id=IDxZhXrpNf. Chaoqi Wang, Roger Grosse, Sanja Fidler, and Guodong Zhang. Eigendamage: Structured pruning in the kronecker-factored eigenbasis. InInternational confer- ence on machine learning, pages 6566–6575. PMLR, 2019. Hermann Weyl.The classical groups: their invariants and representations, volume 1. Princeton univer...
-
[6]
This construction is necessary following the implementation details in Karpathy, 2026
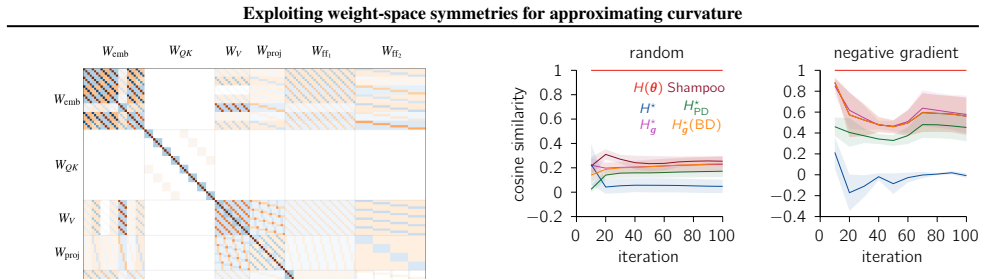
Note that WQK is a matrix with two matrices as block diagonals each representing weights WQ, and WK of query and key correspondingly. This construction is necessary following the implementation details in Karpathy, 2026. J. Details on Hessian approximation experiments In this section, we describe the details of the Hessian approximation experiments presen...
2026
-
[7]
7); 2.H ⋆ PD (Eq
the true Hessian evaluated at the orbit-averaged parameters,H ⋆ (Eq. 7); 2.H ⋆ PD (Eq. 10); 3.H ⋆ g (Eq. 11)
-
[8]
block-diagonalH ⋆ g (denoted asH ⋆ g (BD))
-
[9]
the Shampoo Hessian approximation (Sec. 2.3). Shampoo and Symo Hessian-vector productsIn Sec. 3.4 and Sec. H, we showed that the block-diagonal Symo update with curvature matrix H ⋆ g(BD) is mathematically equivalent to the Shampoo update under certain restrictions. However, this equivalence holds at the level of theupdate directionand does not imply that...
1998
-
[11]
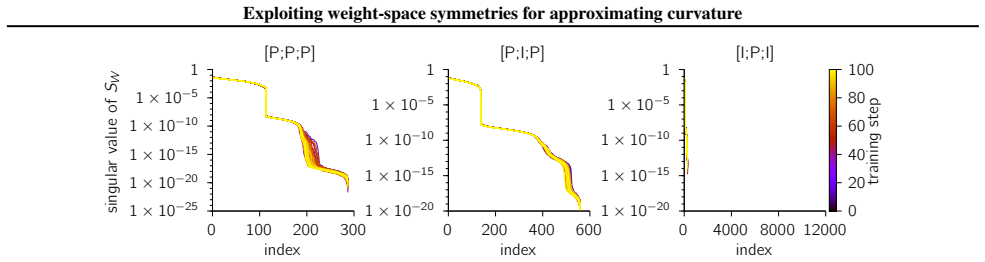
Setting the symmetry on the input space to be trivial by taking the input group as the identity, and imposing a signed permutation symmetry on each subsequent odd-indexed layer
-
[12]
Removing the scaling factor for Symo updates (i.e., √ d(i) in Eq. 76)
-
[15]
biases) and Symo/Muon for two-dimensional parameters
Use Adam for optimizing one-dimensional parameters (i.e. biases) and Symo/Muon for two-dimensional parameters
-
[16]
When calculatingH ⋆ g we assume the orbit average of the gradients is equal to zero(g ⋆ =0). In our experiments, we enforce Item 1, Item 2 and Item 7 but do not enforce the rest in order to compare the theoretically sound Symo optimization step with the empirically effective Muon update. For Item 3, since the scaling factor differs across gradient vectors...
2014
-
[17]
Using a block-diagonalH ⋆ g as the curvature matrix
-
[18]
Apply the trivial identity group for embedding weights, orthogonal group symmetries among the key, query, and value weights, and permutation group symmetries across the attention heads
-
[19]
Removing the scaling factor for Symo updates (i.e., √ d(1) in Eq. 76)
-
[20]
Removing the scaling factor for Muon updates (i.e.,max 1, p fanout/fanin (Jordan et al., 2024))
2024
-
[21]
Replacing the Newton–Schulz method for computing the update parameter (Jordan et al., 2024) with the exact inverse square-root of the outer products of the gradient vector, effectively recovering the Shampoo update (Sec. 2.3)
2024
-
[22]
embedding weights, biases, layer normalization) and Symo/Muon for two-dimensional parameters
Use Adam for optimizing one-dimensional parameters (i.e. embedding weights, biases, layer normalization) and Symo/Muon for two-dimensional parameters
-
[23]
I" for identity group #
When calculatingH ⋆ g we assume the orbit average of the gradients is equal to zero(g ⋆ =0). In our nanoGPT experiments, we enforce Item 1, Item 6 Item 7 in List K.2.2. However, similar to the autoencoder experiments, we do not enforce Item 3, Item 4 and Item 5, for the same reasons explained in Sec. K.1. We also adopt Muon’s momentum formulation, applyin...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.