SALSA: Speech Aware LLM Adaptation via Learned Steering Activation Vectors
Pith reviewed 2026-06-28 19:21 UTC · model grok-4.3
The pith
SALSA learns supervised layer-wise steering vectors to adapt speech-aware LLMs for better out-of-domain performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
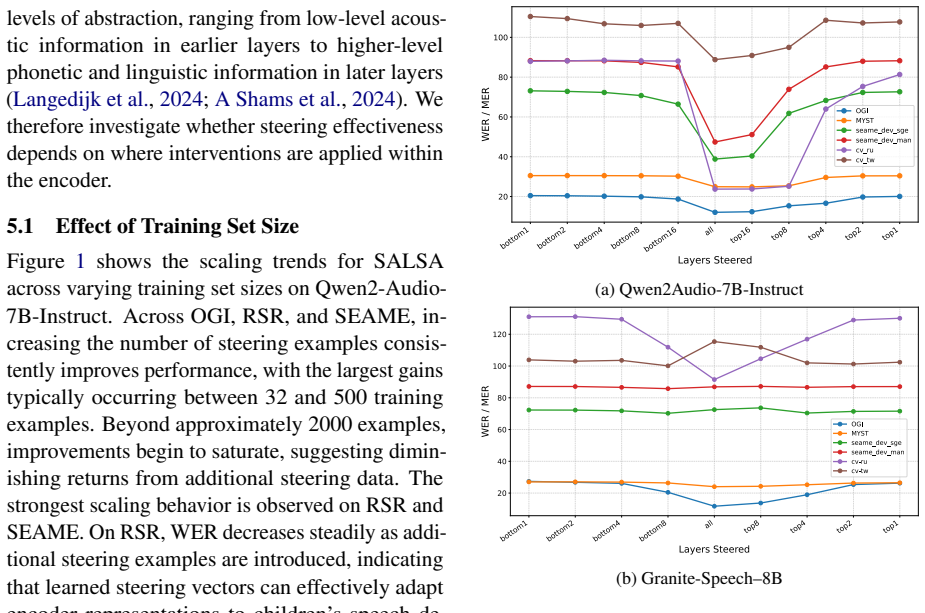
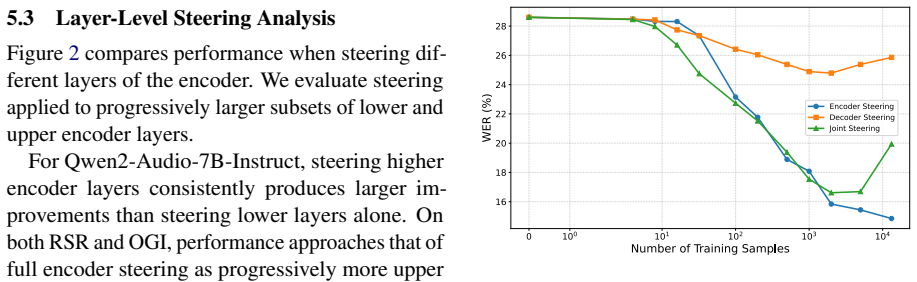
SALSA directly optimizes layer-wise steering activation vectors with a supervised objective. On children's speech, multilingual speech, and Mandarin-English code-switching benchmarks this produces up to 46.8 percent relative improvement over zero-shot inference and beats speech in-context learning baselines. Steering the encoder, particularly later layers, outperforms steering the LLM backbone; the authors conclude that the vectors adapt higher-level acoustic and phonetic representations to align with the pretrained language model rather than altering the decoder itself.
What carries the argument
Layer-wise steering activation vectors learned by supervised optimization and applied to the speech encoder.
If this is right
- Steering later encoder layers is sufficient and more effective than steering the LLM backbone for these tasks.
- The same supervised steering approach can be applied to any speech-aware LLM without changing its decoder parameters.
- Performance gains hold across children's speech, multilingual speech, and code-switching, suggesting broad utility for domain shift.
- Alignment between acoustic representations and language model space improves downstream ASR without explicit decoder changes.
Where Pith is reading between the lines
- The method could be tested on additional low-resource languages or noisy environments to check whether the same encoder-layer preference persists.
- If the learned vectors remain effective when transferred across different base LLMs, the approach would separate the cost of learning the vectors from the choice of language model.
- A natural next check is whether the same supervised steering technique works for non-ASR speech tasks such as spoken language understanding.
Load-bearing premise
The supervised objective used to learn the steering vectors produces vectors that generalize to unseen out-of-domain speech rather than overfitting to the specific training distributions of the three benchmarks.
What would settle it
Measure SALSA on a fourth speech domain with different acoustic or linguistic properties; if relative improvement over zero-shot drops to zero or becomes negative, the generalization claim fails.
Figures

read the original abstract
Speech-aware large language models often generalize poorly to out-of-domain settings. We propose SALSA (Speech-Aware LLM Adaptation via Learned Steering Activations), a lightweight adaptation method that learns layer-wise steering vectors. Unlike commonly used steering approaches that rely on contrastive activation differences, SALSA directly optimizes steering vectors using a supervised objective. Across children's speech, multilingual speech, and Mandarin-English code-switching benchmarks, SALSA substantially improves performance over zero-shot inference and speech in-context learning baselines, achieving up to 46.8% relative improvements over zero-shot. Analysis further demonstrates that steering the encoder, particularly the later layers, is more effective than steering the LLM backbone. These findings suggest that steering improves downstream ASR performance by adapting higher-level acoustic and phonetic representations to better align with the pretrained language model representation space, rather than by modifying the decoder itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SALSA, a lightweight adaptation technique that learns layer-wise steering activation vectors for speech-aware LLMs via a supervised objective rather than contrastive differences. It evaluates the approach on children's speech, multilingual speech, and Mandarin-English code-switching ASR benchmarks, reporting up to 46.8% relative improvement over zero-shot inference and gains over speech in-context learning baselines. Additional analysis indicates that steering the encoder (particularly later layers) outperforms steering the LLM backbone, suggesting the benefit arises from aligning higher-level acoustic/phonetic representations with the LM space.
Significance. If the empirical gains prove robust under proper statistical controls and generalization tests, SALSA would offer an efficient, parameter-light method for domain adaptation in speech LLMs, avoiding full fine-tuning while targeting out-of-domain robustness. This could be relevant for practical deployment in varied acoustic and linguistic conditions.
major comments (3)
- [Abstract] Abstract: the central performance claims (up to 46.8% relative improvement) are presented without error bars, dataset sizes, number of runs, or statistical significance tests. This absence prevents evaluation of whether the reported gains reflect genuine adaptation or benchmark-specific fitting, directly undermining the generalization claim.
- [Abstract] Abstract and analysis section: the supervised objective is described as producing steering vectors that generalize to out-of-domain speech, yet no details are supplied on regularization, early stopping, cross-benchmark transfer experiments, or whether test utterances share speakers/domains with the training data used to learn the vectors. Without these, the distinction between in-distribution fitting and true out-of-domain adaptation cannot be assessed.
- [Analysis] Analysis section: the claim that steering later encoder layers adapts higher-level acoustic and phonetic representations (rather than the decoder) is asserted but lacks supporting ablations, such as layer-wise activation similarity metrics, controlled interventions on phonetic vs. lexical features, or comparisons of representation alignment before/after steering.
minor comments (2)
- [Abstract] The abstract refers to 'speech in-context learning baselines' without specifying how many shots or what prompting format was used, which would aid reproducibility.
- Notation for the steering vectors and the supervised loss is not introduced in the provided abstract; a clear definition early in the methods would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the presentation of our empirical results and analysis. We address each major comment below and outline revisions to improve statistical reporting, methodological details, and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (up to 46.8% relative improvement) are presented without error bars, dataset sizes, number of runs, or statistical significance tests. This absence prevents evaluation of whether the reported gains reflect genuine adaptation or benchmark-specific fitting, directly undermining the generalization claim.
Authors: We agree that the abstract would benefit from greater transparency on experimental rigor. The main text reports results over multiple runs with standard deviations shown in tables and specifies dataset sizes in the experimental setup. In the revision we will update the abstract to reference averaging over 3 seeds and add a sentence noting that statistical significance is assessed in the results section. revision: yes
-
Referee: [Abstract] Abstract and analysis section: the supervised objective is described as producing steering vectors that generalize to out-of-domain speech, yet no details are supplied on regularization, early stopping, cross-benchmark transfer experiments, or whether test utterances share speakers/domains with the training data used to learn the vectors. Without these, the distinction between in-distribution fitting and true out-of-domain adaptation cannot be assessed.
Authors: We will expand the Methods section to clarify the optimization procedure, including any regularization and early-stopping criteria employed, and to explicitly state that official benchmark splits are used to ensure no speaker overlap between training and test utterances. Cross-benchmark transfer experiments were outside the current scope; we will note this limitation and the distinct nature of the evaluated domains. revision: yes
-
Referee: [Analysis] Analysis section: the claim that steering later encoder layers adapts higher-level acoustic and phonetic representations (rather than the decoder) is asserted but lacks supporting ablations, such as layer-wise activation similarity metrics, controlled interventions on phonetic vs. lexical features, or comparisons of representation alignment before/after steering.
Authors: The existing analysis demonstrates that encoder-layer steering, especially in later layers, yields larger gains than LLM-backbone steering. We acknowledge that additional quantitative support would strengthen the interpretation. In the revision we will add layer-wise activation similarity metrics (e.g., cosine similarity before/after steering) to the analysis or appendix. revision: yes
Circularity Check
No circularity: empirical adaptation method evaluated on held-out benchmark data
full rationale
The paper proposes SALSA as a supervised method to learn steering vectors for LLM adaptation to speech domains and reports relative improvements on test portions of children's speech, multilingual, and code-switching benchmarks. No equations, derivations, or first-principles predictions appear in the provided text. Claims rest on empirical comparisons to zero-shot and in-context baselines rather than any reduction of outputs to fitted inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Proceedings of the 40th International Conference on Machine Learning , pages=
Robust speech recognition via large-scale weak supervision , author=. Proceedings of the 40th International Conference on Machine Learning , pages=
-
[4]
Journal of Speech, Language, and Hearing Research , volume=
Diagnostic accuracy of sentence recall and past tense measures for identifying children's language impairments , author=. Journal of Speech, Language, and Hearing Research , volume=. 2019 , publisher=
2019
-
[5]
Redmond Sentence Recall (
-
[6]
and Liu, D
Preza, T. and Liu, D. and Miller, C. and Alabdallah, A. and Xiong, J. and Redmond, S. and Hadley, P. , title =
-
[7]
Guanlong Zhao and Sinem Sonsaat and Alif Silpachai and others , year =. Interspeech 2018 , pages =. doi:10.21437/Interspeech.2018-1110 , issn =
-
[8]
and Branson, M
Ardila, R. and Branson, M. and Davis, K. and others , title =. Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020) , pages =
2020
-
[9]
My Science Tutor (
Pradhan, Sameer and Cole, Ronald and Ward, Wayne , booktitle=. My Science Tutor (
-
[11]
Journal of speech language pathology and audiology , volume=
Storytelling from pictures using the Edmonton narrative norms instrument , author=. Journal of speech language pathology and audiology , volume=. 2006 , publisher=
2006
-
[12]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
TICL: Text-embedding knn for speech in-context learning unlocks speech recognition abilities of large multimodal models , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[13]
Hasegawa-Johnson , booktitle=
Haolong Zheng and Yekaterina Yegorova and Mark A. Hasegawa-Johnson , booktitle=. 2025 , url=
2025
-
[14]
Can Whisper Perform Speech-Based In-Context Learning? , year=
Wang, Siyin and Yang, Chao-Han and Wu, Ji and Zhang, Chao , booktitle=. Can Whisper Perform Speech-Based In-Context Learning? , year=
-
[16]
Forty-first International Conference on Machine Learning , year=
In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering , author=. Forty-first International Conference on Machine Learning , year=
-
[17]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , month = oct, year =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , month = oct, year =
-
[18]
International Conference on Learning Representations , volume=
Salmonn: Towards generic hearing abilities for large language models , author=. International Conference on Learning Representations , volume=
-
[19]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Wavllm: Towards robust and adaptive speech large language model , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[20]
IEEE Journal of Selected Topics in Signal Processing , year=
A survey on speech large language models for understanding , author=. IEEE Journal of Selected Topics in Signal Processing , year=
-
[21]
2023 , eprint=
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models , author=. 2023 , eprint=
2023
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
In-context learning boosts speech recognition via human-like adaptation to speakers and language varieties , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[25]
, author=
SEAME: a Mandarin-English code-switching speech corpus in south-east asia. , author=. Interspeech , volume=
-
[28]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[29]
arXiv preprint arXiv:2603.05977 , year=
Activation Steering for Accent-Neutralized Zero-Shot Text-To-Speech , author=. arXiv preprint arXiv:2603.05977 , year=
-
[32]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Steering llama 2 via contrastive activation addition , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[34]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Advances in Neural Information Processing Systems , volume=
Personalized steering of large language models: Versatile steering vectors through bi-directional preference optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
Reft: Representation finetuning for language models , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
SteerVLM: Robust Model Control through Lightweight Activation Steering for Vision Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
2025
-
[39]
Advances in Neural Information Processing Systems , volume=
Live: Learnable in-context vector for visual question answering , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Learning to Steer: Input-dependent Steering for Multimodal
Jayneel Parekh and Pegah KHAYATAN and Mustafa Shukor and Arnaud Dapogny and Alasdair Newson and Matthieu Cord , booktitle=. Learning to Steer: Input-dependent Steering for Multimodal. 2026 , url=
2026
-
[41]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[42]
2023 , editor =
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle =. 2023 , editor =
2023
-
[44]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Advancing Speech Understanding in Speech-Aware Language Models with GRPO , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[45]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[46]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Decoderlens: Layerwise interpretation of encoder-decoder transformers , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[48]
, author=
From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition. , author=. Interspeech , number=
-
[49]
Erfan A Shams, Iona Gessinger, and Julie Carson-Berndsen. 2024. https://doi.org/10.18653/v1/2024.blackboxnlp-1.16 Uncovering syllable constituents in the self-attention-based speech representations of whisper . In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 238--247, Miami, Florida, US. Associatio...
-
[50]
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, and 1 others. 2025. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras. arXiv preprint arXiv:2503.01743
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Ardila, M
R. Ardila, M. Branson, K. Davis, and 1 others. 2020. Common voice: A massively-multilingual speech corpus. In Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), pages 4211--4215
2020
-
[52]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://proceedings.neurips.cc/paper_fil...
2020
-
[53]
Yuanpu Cao, Tianrong Zhang, Bochuan Cao, Ziyi Yin, Lu Lin, Fenglong Ma, and Jinghui Chen. 2024. Personalized steering of large language models: Versatile steering vectors through bi-directional preference optimization. Advances in Neural Information Processing Systems, 37:49519--49551
2024
-
[55]
Yunfei Chu, Jin Xu, Qian Yang, and 1 others. 2024 b . Qwen2-audio technical report. arXiv preprint arXiv:2407.10759
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. 2023. https://arxiv.org/abs/2311.07919 Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models . Preprint, arXiv:2311.07919
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Avishai Elmakies, Hagai Aronowitz, Nimrod Shabtay, Eli Schwartz, Ron Hoory, and Avihu Dekel. 2026. Advancing speech understanding in speech-aware language models with grpo. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 17797--17801. IEEE
2026
- [58]
-
[59]
Alex Graves, Santiago Fern \' a ndez, Faustino Gomez, and J \" u rgen Schmidhuber. 2006. https://doi.org/10.1145/1143844.1143891 Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks . In Proc. International Conference on Machine Learning (ICML), pages 369--376
-
[60]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. http://arxiv.org/abs/2106.09685 LoRA : Low - Rank Adaptation of Large Language Models . arXiv preprint. ArXiv:2106.09685 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[62]
Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, and 1 others. 2024. Wavllm: Towards robust and adaptive speech large language model. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4552--4572
2024
- [63]
-
[64]
Anna Langedijk, Hosein Mohebbi, Gabriele Sarti, Willem Zuidema, and Jaap Jumelet. 2024. Decoderlens: Layerwise interpretation of encoder-decoder transformers. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 4764--4780
2024
-
[65]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023 a . https://proceedings.mlr.press/v202/li23q.html BLIP -2: Bootstrapping language-image pre-training with frozen image encoders and large language models . In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 19730-...
2023
-
[66]
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. 2023 b . Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36:41451--41530
2023
-
[67]
Sheng Liu, Haotian Ye, Lei Xing, and James Y. Zou. 2024. https://openreview.net/forum?id=dJTChKgv3a In-context vectors: Making in context learning more effective and controllable through latent space steering . In Forty-first International Conference on Machine Learning
2024
-
[68]
Ilya Loshchilov and Frank Hutter. 2019. https://openreview.net/forum?id=Bkg6RiCqY7 Decoupled weight decay regularization . In International Conference on Learning Representations
2019
-
[69]
Dau-Cheng Lyu, Tien Ping Tan, Engsiong Chng, and Haizhou Li. 2010. Seame: a mandarin-english code-switching speech corpus in south-east asia. In Interspeech, volume 10, pages 1986--1989
2010
-
[70]
Andrew Cameron Morris, Viktoria Maier, and Phil D Green. 2004. From wer and ril to mer and wil: improved evaluation measures for connected speech recognition. In Interspeech, 4-8, page 2004
2004
-
[71]
ASR Omnilingual, Gil Keren, Artyom Kozhevnikov, Yen Meng, Christophe Ropers, Matthew Setzler, Skyler Wang, Ife Adebara, Michael Auli, Can Balioglu, and 1 others. 2025. Omnilingual asr: Open-source multilingual speech recognition for 1600+ languages. arXiv preprint arXiv:2511.09690
-
[72]
Jayneel Parekh, Pegah KHAYATAN, Mustafa Shukor, Arnaud Dapogny, Alasdair Newson, and Matthieu Cord. 2026. https://openreview.net/forum?id=QSLlPljXxz Learning to steer: Input-dependent steering for multimodal LLM s . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2026
-
[73]
Jing Peng, Yucheng Wang, Bohan Li, Yiwei Guo, Hankun Wang, Yangui Fang, Yu Xi, Haoyu Li, Xu Li, Ke Zhang, and 1 others. 2025. A survey on speech large language models for understanding. IEEE Journal of Selected Topics in Signal Processing
2025
-
[74]
Yingzhe Peng, Chenduo Hao, Xinting Hu, Jiawei Peng, Xin Geng, and Xu Yang. 2024. Live: Learnable in-context vector for visual question answering. Advances in Neural Information Processing Systems, 37:9773--9800
2024
-
[75]
Sameer Pradhan, Ronald Cole, and Wayne Ward. 2024. My science tutor ( MyST )--a large corpus of children’s conversational speech. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 12040--12045
2024
-
[76]
Preza, D
T. Preza, D. Liu, C. Miller, A. Alabdallah, J. Xiong, S. Redmond, and P. Hadley. 2026. Novel approaches to language screening: E valuating measures of effort in a sentence recall task for school-age children. Manuscript under review
2026
-
[77]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In Proceedings of the 40th International Conference on Machine Learning, pages 28492--28518
2023
-
[78]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[79]
Sean M Redmond, Andrea C Ash, Tyler T Christopulos, and Theresa Pfaff. 2019. Diagnostic accuracy of sentence recall and past tense measures for identifying children's language impairments. Journal of Speech, Language, and Hearing Research, 62(7):2438--2454
2019
-
[80]
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. 2024. Steering llama 2 via contrastive activation addition. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504--15522
2024
-
[81]
Nathan Roll, Calbert Graham, Yuka Tatsumi, Kim Tien Nguyen, Meghan Sumner, and Dan Jurafsky. 2025. In-context learning boosts speech recognition via human-like adaptation to speakers and language varieties. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4412--4426
2025
-
[82]
George Saon, Avihu Dekel, Alexander Brooks, Tohru Nagano, Abraham Daniels, Aharon Satt, Ashish Mittal, Brian Kingsbury, David Haws, Edmilson Morais, and 1 others. 2025. Granite-speech: Open-source speech-aware llms with strong english asr capabilities. arXiv preprint arXiv:2505.08699
-
[83]
Khaldoun Shobaki, John-Paul Hosom, and Ronald A. Cole. 2000. https://doi.org/10.21437/ICSLP.2000-800 The OGI kids² speech corpus and recognizers . In 6th International Conference on Spoken Language Processing (ICSLP 2000) , pages vol. 4, 258--261
-
[84]
Anushka Sivakumar, Andrew Zhang, Zaber Hakim, and Chris Thomas. 2025. Steervlm: Robust model control through lightweight activation steering for vision language models. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23640--23665
2025
-
[85]
Nishant Subramani, Nivedita Suresh, and Matthew Peters. 2022. https://doi.org/10.18653/v1/2022.findings-acl.48 Extracting latent steering vectors from pretrained language models . In Findings of the Association for Computational Linguistics: ACL 2022, pages 566--581, Dublin, Ireland. Association for Computational Linguistics
-
[86]
Jinuo Sun, Yang Xiao, Sung Kyun Chung, Qiuchi Hu, Gongping Huang, Eun-Jung Holden, and Ting Dang. 2026. Activation steering for accent adaptation in speech foundation models. arXiv preprint arXiv:2603.05813
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[87]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. 2024. Salmonn: Towards generic hearing abilities for large language models. In International Conference on Learning Representations, volume 2024, pages 16607--16629
2024
-
[88]
Siyin Wang, Chao-Han Yang, Ji Wu, and Chao Zhang. 2024. https://doi.org/10.1109/ICASSP48485.2024.10446502 Can whisper perform speech-based in-context learning? In ICASSP 2024, pages 13421--13425
-
[89]
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D Manning, and Christopher Potts. 2024. Reft: Representation finetuning for language models. Advances in Neural Information Processing Systems, 37:63908--63962
2024
-
[90]
Haolong Zheng, Yekaterina Yegorova, and Mark Hasegawa-Johnson. 2026. Ticl: Text-embedding knn for speech in-context learning unlocks speech recognition abilities of large multimodal models. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 17912--17916. IEEE
2026
-
[91]
Hasegawa-Johnson
Haolong Zheng, Yekaterina Yegorova, and Mark A. Hasegawa-Johnson. 2025. https://openreview.net/forum?id=fXwkN9m0AE TICL +: A case study on speech in-context learning for children's speech recognition . In IEEE ASRU Satellite Workshop-AI for Children's Speech and Language
2025
-
[92]
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, and 1 others. 2023. Representation engineering: A top-down approach to ai transparency. arXiv preprint arXiv:2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.