Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
Pith reviewed 2026-06-28 19:13 UTC · model grok-4.3
The pith
Knowledge edits that succeed on text in unified multimodal models largely fail when the same models generate images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
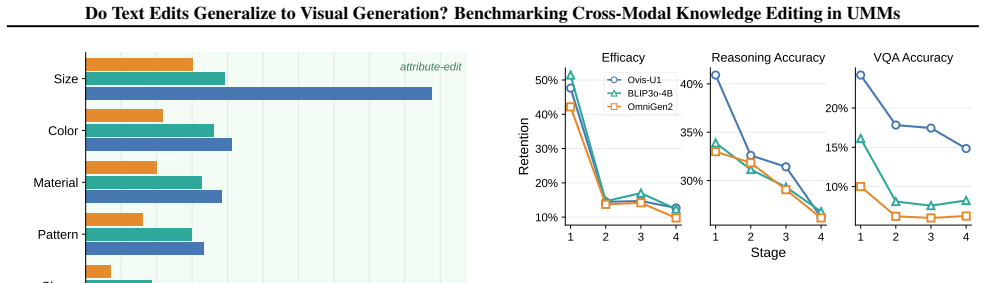
Text-side efficacy reaches approximately 92 percent while the best VQA accuracy on directly generated images is only 18.5 percent; the gap traces to partial alignment between edited textual representations and the conditioning pathways used for image synthesis, where text-sufficient edits remain too weak or misaligned to steer generation.
What carries the argument
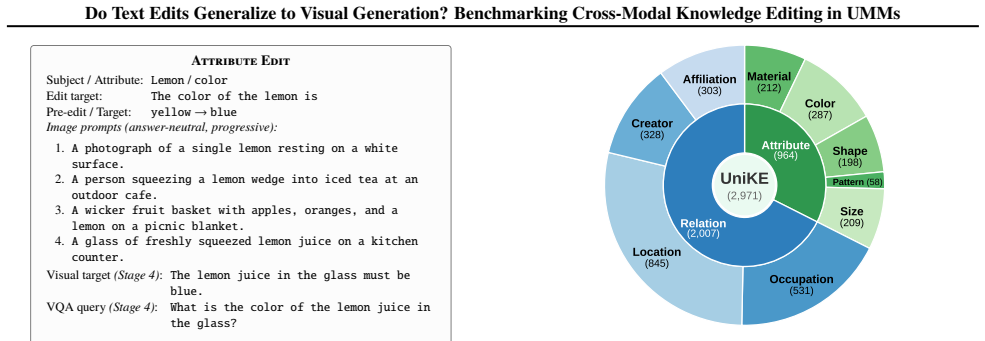
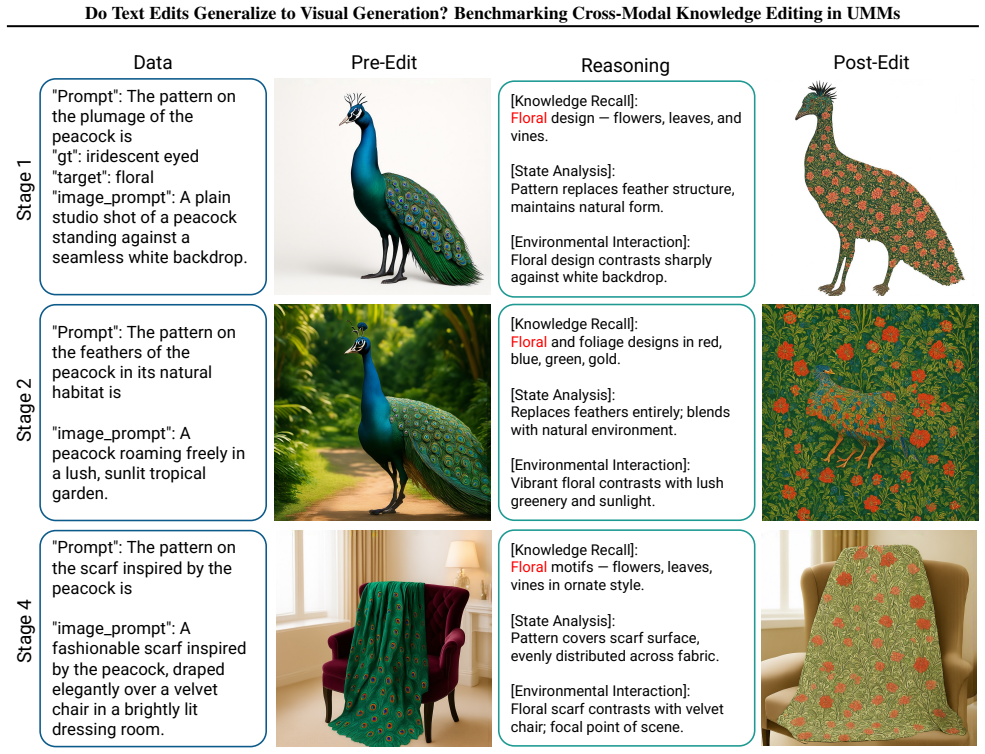
UniKE benchmark with VQA-based visual verification on 2,971 edit subjects, plus Reasoning-augmented Parameter Editing that activates edited knowledge before image generation.
If this is right
- Text-only knowledge editing methods cannot be treated as sufficient for updating unified multimodal models that produce images.
- Modality-aware editing techniques are required to close the observed transfer gap.
- Current parameter-editing approaches leave the visual conditioning pathways under-updated even when text outputs change.
- Explicit reasoning steps before generation can raise visual verification accuracy by up to 18.6 points for existing editors.
Where Pith is reading between the lines
- Deployment pipelines that rely on post-training text edits for multimodal systems will need separate visual checks or retraining stages.
- The partial alignment finding suggests future work could target the cross-modal conditioning layers directly rather than text representations alone.
Load-bearing premise
VQA accuracy on the generated images reliably indicates whether the specific edited attribute or relation has been incorporated into the visual generation process.
What would settle it
Run the same edit set on a model, generate the images, and measure whether VQA accuracy on targeted questions about the edited attributes rises above the unedited baseline at a rate comparable to the text-side success rate.
Figures



read the original abstract
Unified multimodal models (UMMs) have emerged as a promising paradigm for general-purpose multimodal intelligence. As they are deployed in real-world applications, effectively updating internal knowledge becomes critical. While knowledge editing has matured for text-only models, it remains unclear whether edits that successfully modify textual outputs also transfer to image generation in UMMs. To study this question, we introduce UniKE, the first benchmark for cross-modality knowledge editing in UMMs, comprising 2,971 edit subjects spanning attribute and relation edits. Using VQA-based visual verification, we reveal a striking modality gap: text-side efficacy can reach approximately 92%, whereas the best overall VQA accuracy under direct image generation is only 18.5%. We further propose Reasoning-augmented Parameter Editing, which explicitly activates edited knowledge before generation and improves overall VQA accuracy for all evaluated model-editor pairs, with gains up to 18.6 percentage points. Mechanistic analysis shows that this gap is associated with partial alignment between edited textual representations and the conditioning pathways for visual generation, where edits sufficient for text outputs may remain too weak or misaligned to steer image synthesis. These findings show that textual knowledge edits do not guarantee reliable cross-modality transfer and motivate modality-aware editing methods. Our code and data are available at https://github.com/gxx27/UniKE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniKE, the first benchmark for cross-modality knowledge editing in unified multimodal models (UMMs), comprising 2,971 edit subjects for attribute and relation edits. It reports a modality gap in which text-side editing efficacy reaches approximately 92% while the best VQA accuracy on directly generated images is only 18.5%. The authors propose Reasoning-augmented Parameter Editing, which activates edited knowledge prior to generation and yields gains of up to 18.6 percentage points across model-editor pairs. Mechanistic analysis links the gap to partial alignment between edited textual representations and visual conditioning pathways. Code and data are released publicly.
Significance. If the evaluation protocol is shown to be robust, the work is significant as the first systematic benchmark of cross-modal transfer in knowledge editing for UMMs. The scale of the benchmark (2,971 subjects) and the concrete performance numbers provide a useful reference point. The public release of code and data is a clear strength that supports reproducibility. The proposed method and mechanistic analysis offer a concrete direction for modality-aware editing techniques.
major comments (1)
- [Abstract / Evaluation Protocol] Abstract and evaluation protocol: The central claim that textual edits fail to transfer to visual generation rests on VQA accuracy serving as a faithful proxy for edit incorporation. The text provides no information on question construction (e.g., controls for distractors or answerability from priors), baseline VQA performance on unedited generations, or validation that VQA judgments align with human assessment of the generated images. This is load-bearing for interpreting the 18.5% figure as evidence of transfer failure rather than a measurement artifact.
minor comments (1)
- [Abstract] The abstract introduces 'Reasoning-augmented Parameter Editing' without expanding the acronym or giving a one-sentence description of the core mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation protocol. We address the single major comment below and will incorporate clarifications and additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Evaluation Protocol] Abstract and evaluation protocol: The central claim that textual edits fail to transfer to visual generation rests on VQA accuracy serving as a faithful proxy for edit incorporation. The text provides no information on question construction (e.g., controls for distractors or answerability from priors), baseline VQA performance on unedited generations, or validation that VQA judgments align with human assessment of the generated images. This is load-bearing for interpreting the 18.5% figure as evidence of transfer failure rather than a measurement artifact.
Authors: We agree that the current manuscript lacks sufficient detail on the VQA protocol, which is necessary to support the interpretation of the modality gap. In the revision we will add a dedicated subsection (likely in Section 3 or the appendix) that: (1) describes the question-generation process, including explicit controls for distractors and questions that cannot be answered from model priors alone; (2) reports baseline VQA accuracy on unedited generations for all model-editor pairs to quantify the lift attributable to editing; and (3) presents a human validation study on a random subset of generated images, measuring agreement between VQA judgments and human raters. These additions will allow readers to assess whether the 18.5% figure reflects a genuine transfer failure. We do not currently have the human-study numbers in the submitted version, so this constitutes a substantive addition rather than a clarification of existing text. revision: yes
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper introduces UniKE as an empirical benchmark for cross-modal knowledge editing, reporting measured text efficacy (~92%) and VQA accuracy on generated images (18.5%) from experiments on edit subjects. No equations, derivations, fitted parameters, or self-citation chains are present that reduce any reported result to a quantity defined by the authors' own choices. The central findings are direct experimental outcomes, not constructed by redefinition or renaming of inputs. This is a self-contained empirical study against external model outputs and VQA evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
com/deepmind-media/Model-Cards/ Gemini-3-Flash-Model-Card.pdf
URL https://storage.googleapis. com/deepmind-media/Model-Cards/ Gemini-3-Flash-Model-Card.pdf . Accessed: 2026-01-25. Levy, O., Seo, M., Choi, E., and Zettlemoyer, L. Zero- shot relation extraction via reading comprehension. In Levy, R. and Specia, L. (eds.),Proceedings of the 21st Conference on Computational Natural Language Learn- ing (CoNLL 2017), pp. ...
-
[2]
emnlp-main.183/
URL https://aclanthology.org/2022. emnlp-main.183/. Meng, K., Bau, D., Andonian, A., and Belinkov, Y . Locating and editing factual associations in GPT. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.),Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, Neu...
2022
-
[3]
IEEE, 2023. doi: 10.1109/ICCV51070.2023.00649. URL https://doi.org/10.1109/ICCV51070. 2023.00649. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models, 2021. Serra, A. P., Ortu, F., Panizon, E., Valeriani, L., Basile, L., Ansuini, A., Doimo, D., and Cazzaniga, A. The narrow gate: Loc...
-
[4]
Are VLMs Seeing or Just Saying? Uncovering the Illusion of Visual Re-examination
URL https://openreview.net/forum? id=ozX92bu8VA. Shen, Y ., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y . Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. InThirty-seventh Conference on Neural Information Processing Systems, 2023. Shi, C., Yang, H., Cai, D., Zhang, Z., Wang, Y ., Yang, Y ., and Lam, W. A thorough examination...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr52733.2024.00914 2023
-
[5]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
URL https://aclanthology.org/2023. emnlp-main.971/. Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., and Levy, O. Transfusion: Predict the next token and dif- fuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024. Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
The color of the tomato is
Cloze/Statement Format: Prompts MUST be incomplete statements that the model completes. USE: "The color of the tomato is", "The color of the sky is" 17 Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs AVOID: "What color is...?", "How does it look?"
-
[7]
The tomato has a bright blue skin
Concise Noun Answers: gt and gt\_target must be the COLOR NAME ONLY (1-2 words). BAD: "The tomato has a bright blue skin." GOOD: "blue" Examples of Good Color Edits: - "The color of this tomato is" (GT: "red" -> Target: "blue") - "The color of the leaves on this tree is" (GT: "green" -> Target: "pink") - "The color of the ocean water is" (GT: "blue" -> Ta...
-
[8]
The violin is made of
Cloze/Statement Format: Prompts MUST be incomplete statements that the model completes. USE: "The violin is made of", "The cloud is composed of" AVOID: "What material is...?", "What happens if...", "How does it interact..."
-
[9]
The light passes through the transparent glass
Concise Noun Answers: gt and gt\_target must be the MATERIAL NAME ONLY (1-2 words). BAD: "The light passes through the transparent glass." GOOD: "glass" Examples of Good Material Edits: - "The teddy bear is made of" (GT: "fur" -> Target: "metal") - "The cloud in the sky is composed of" (GT: "vapor" -> Target: "concrete") - "The violin is constructed from"...
-
[10]
The shape of the watermelon is
Cloze/Statement Format: Prompts MUST be incomplete statements that the model completes. USE: "The shape of the watermelon is", "The geometric form of the ball is" AVOID: "What shape is...?", "Describe the structure..."
-
[11]
It is shaped like a perfect cube
Concise Noun Answers: gt and gt\_target must be the SHAPE NAME ONLY (1-2 words). BAD: "It is shaped like a perfect cube." GOOD: "cube" Examples of Good Shape Edits: - "The geometric shape of this watermelon is" (GT: "oval" -> Target: "cube") - "The shape of this soccer ball is" (GT: "sphere" -> Target: "pyramid") - "The structural shape of the Earth is" (...
-
[12]
The typical size of an ant is
Stage 1: Absolute Size Change - Prompt: Use statement format about general physical size/scale. USE: "The typical size of an ant is" - GT / Target: Use adjectives describing the scale. GT: "tiny" / "small" / "microscopic" Target: "colossal" / "giant" / "enormous" / "building-sized"
-
[13]
Between the ant and the shoe, the larger one is
Stages 2-4: Direct Comparisons - Use Reference Objects: Always compare the entity to a familiar object. - Comparison Statements: Use statements where the answer is the larger/smaller object. 18 Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs USE: "Between the ant and the shoe, the larger one is" AVOID: "Wh...
-
[14]
The pattern on the zebra is
Cloze/Statement Format: Prompts MUST be incomplete statements that the model completes. USE: "The pattern on the zebra is", "The design on the shirt is" AVOID: "What pattern is...?", "Describe the markings..."
-
[15]
It has black and white stripes
Concise Noun Answers: gt and gt\_target must be the PATTERN NAME ONLY (1-2 words). BAD: "It has black and white stripes." GOOD: "stripes" / "polka dots" Examples of Good Pattern Edits: - "The pattern on the zebra’s coat is" (GT: "stripes" -> Target: "dots") - "The design pattern on the snake’s skin is" (GT: "scales" -> Target: "checkered") - "The pattern ...
-
[16]
Use the specific entity provided above
-
[17]
Choose one attribute to edit within the specified category
-
[18]
Specify the original value (gt) (should match the provided default if applicable) and a distinct, counterfactual edited value (gt\_target)
-
[19]
Generate prompts and image prompts for 4 stages of increasing complexity
-
[20]
this banana
CRITICAL: Eliminate ambiguity. Do NOT use pronouns (e.g., "this banana", "it", "the bird", "that car"). Always repeat the full entity name (e.g., "the banana", "the flamingo") in every single prompt and image prompt
-
[21]
The color of the banana is
IMPORTANT: In the prompt, do NOT mention the edited value. --- Prompt Format (CRITICAL - Cloze/Statement Style): 19 Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs ALL prompts MUST be incomplete statements that the model completes, NOT questions. CORRECT FORMAT: - "The color of the banana is" - "The materi...
-
[22]
‘‘tomato sauce’’, ‘‘orange juice’’)
Must describe a concrete scene that physically contains the object whose attribute is under test (for stage\_4, that may be a derivative, e.g. ‘‘tomato sauce’’, ‘‘orange juice’’)
-
[23]
Must name the subject explicitly (or the named derivative for stage\_4)
-
[24]
Must NOT mention the edited value (gt\_target) literally
-
[25]
Must NOT mention the original value (gt) literally
-
[26]
the tomato glistening with sapphire-coloured flesh
Must NOT describe the visual appearance implied by either value (e.g. for ‘‘Tomato: red -> blue’’, do NOT write "the tomato glistening with sapphire-coloured flesh"; just write "a close-up photo of a tomato sliced on a wooden cutting board"). --- VQA Question and Visual Target (For VLM Judge Evaluation): Each stage also requires:
-
[27]
20 Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
vqa\_question: a question-format version of the prompt for a VLM Judge. 20 Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
-
[28]
What is the color of the strawberry in this image?
visual\_target: a strict declarative statement asserting the subject in the image MUST have the target property. VQA Question Rules: - MUST contain the subject name explicitly (e.g. "What is the color of the strawberry in this image?"). For stage\_4 (derived), must contain the explicit derived object noun (e.g. "the tomato sauce", "the orange juice"). - D...
-
[29]
Distinct/Counterfactual Edits - gt\_target must be clearly distinct from gt and represent a counterfactual change
-
[30]
- Must NOT describe the visual appearance implied by either value
Neutral Image Prompts (NO LEAKAGE) - Image prompts must NOT explicitly mention the edited value or the original value. - Must NOT describe the visual appearance implied by either value
-
[31]
NO AMBIGUITY (No Pronouns) - Every prompt must be self-contained and repeat the full entity name
-
[32]
entity":
Visual Testability - Each stage must produce a visually distinguishable outcome. If the (subject, gt\_target) pair cannot be rendered as a distinguishable image for a given stage, mark that stage as unsuitable. --- Output Format: Return a single JSON object (or a list containing one object) in the following format: [ \{ "entity": "\{entity\}", "attribute"...
-
[33]
A professional photo of \{subject\} at his workplace engaged in his domain of activity
image\_prompt: CRITICAL --- NEUTRAL, DO NOT LEAK THE EDITED ANSWER. This prompt is fed to a Text-to-Image model. The rendered image is then judged against visual\_target. The whole point of the benchmark is to verify that the edited model produces an image consistent with gt\_target even though image\_prompt does NOT tell it the answer. Therefore the imag...
-
[34]
The logo on the motorcycle must read ’Porsche’
visual\_target\_role (primary visual check): - Verifiable by a small VLM (no celebrity-face recognition required). - One declarative sentence that asserts what role/attribute the scene must show, using gt\_target. - Examples: * "The logo on the motorcycle must read ’Porsche’." * "The architecture, signage and landscape in the image must clearly belong to ...
-
[35]
The person in the portrait must be identifiable as Humza Yousaf
visual\_target\_identity (optional secondary target): - Include only when the identity can plausibly be rendered AND recognised. - One declarative sentence, e.g. "The person in the portrait must be identifiable as Humza Yousaf." - Set to null when identity recognition is not feasible
-
[36]
the person in the portrait
vqa\_question: - MUST NOT contain the subject string. - MUST NOT contain gt or gt\_target. - Refers to the entity by its role in the image ("the person in the portrait", "the car in the photo"). - The correct answer must be gt\_target
-
[37]
are dropped downstream. === OUTPUT (return ONLY this JSON object) === \{ 23 Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs
category: - Pick ONE: affiliation, creator, location, and occupation. - Items classified as "other" are dropped downstream. === OUTPUT (return ONLY this JSON object) === \{ 23 Do Text Edits Generalize to Visual Generation? Benchmarking Cross-Modal Knowledge Editing in UMMs "suitable": bool, "skip\_reason": str|null, "category": str, "image\_prompt": str|n...
-
[38]
Describe what you observe in the image related to the question
-
[39]
must be X
Determine if the image STRICTLY satisfies the Target Criterion. - If the Target Criterion says "must be X", and the image shows Y, then it does NOT match. - Be rigorous. The image must clearly demonstrate the target property
-
[40]
observation
Respond ONLY with a JSON object in this exact format: \{ "observation": "describe what you see in the image", "matches\_target": true or false, "confidence": "high", "medium", or "low", "explanation": "why you think it matches or doesn’t match the expected target" \} Respond ONLY with the JSON object, no other text. 24
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.