LaSR: Context-Aware Speech Recognition via Latent Reasoning
Pith reviewed 2026-06-28 19:10 UTC · model grok-4.3
The pith
LaSR aligns chain-of-thought supervision to acoustic features and inserts latent reasoning periods to improve contextual speech recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LaSR is a novel training paradigm featuring a context-aware reasoning trajectory that leverages the latent reasoning process. Instead of generating explicit intermediate tokens, LaSR aligns chain-of-thought (CoT) supervision around the acoustic feature region of the targeted word, and introduces latent reasoning periods for context information grounding and transcriptional transition.
What carries the argument
Context-aware reasoning trajectory that aligns CoT supervision to acoustic feature regions and uses latent reasoning periods for grounding and transition.
If this is right
- Terminology recognition accuracy rises in speech LLMs.
- Response latency stays unchanged.
- Performance exceeds that of standard supervised fine-tuning baselines.
- Models better reflect speaker intent and topical context during recognition.
Where Pith is reading between the lines
- The approach may transfer to other context-sensitive speech tasks such as intent detection or summarization.
- The Spoken Darwin-Science corpus could become a reusable testbed for comparing context-aware speech methods.
- Avoiding explicit tokens might lower overall training cost in larger speech systems.
Load-bearing premise
That aligning chain-of-thought supervision around the acoustic feature region of the targeted word, combined with latent reasoning periods, successfully grounds context information and enables transcriptional transition without explicit intermediate tokens.
What would settle it
A head-to-head test on the Spoken Darwin-Science corpus in which LaSR produces no measurable gain in terminology recognition accuracy over standard supervised fine-tuning.
Figures


read the original abstract
Recent advances in Speech Large Language Models (Speech LLMs) have significantly enhanced spoken language understanding and reasoning. However, their contextual awareness is limited, struggling to perform speech recognition that effectively reflects the speaker's intent and topical context. In this paper, we propose LaSR (Latent Speech Reasoning), a novel training paradigm featuring a context-aware reasoning trajectory that leverages the latent reasoning process. Instead of generating explicit intermediate tokens, LaSR aligns chain-of-thought (CoT) supervision around the acoustic feature region of the targeted word, and introduces latent reasoning periods for context information grounding and transcriptional transition. Furthermore, to effectively benchmark contextual recognition on specialized vocabulary, we propose Spoken Darwin-Science, a large-scale corpus focusing on academic terminologies. Preliminary experiments on Fun-Audio-Chat demonstrate that LaSR significantly improves terminology recognition without introducing additional latency and consistently outperforms standard supervised fine-tuning baselines. Our findings highlight the potential of latent reasoning in building efficient, context-aware speech assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LaSR, a training paradigm for Speech LLMs that uses a context-aware reasoning trajectory with latent reasoning periods to align chain-of-thought supervision around acoustic feature regions of targeted words, enabling better contextual grounding without explicit intermediate tokens. It introduces the Spoken Darwin-Science corpus for benchmarking specialized academic vocabulary and reports preliminary experiments on Fun-Audio-Chat claiming improved terminology recognition with no added latency over standard supervised fine-tuning.
Significance. If the empirical gains can be rigorously quantified and reproduced, the approach would demonstrate a latency-preserving mechanism for injecting context into speech recognition, with potential value for domain-specific applications such as academic or technical transcription.
major comments (2)
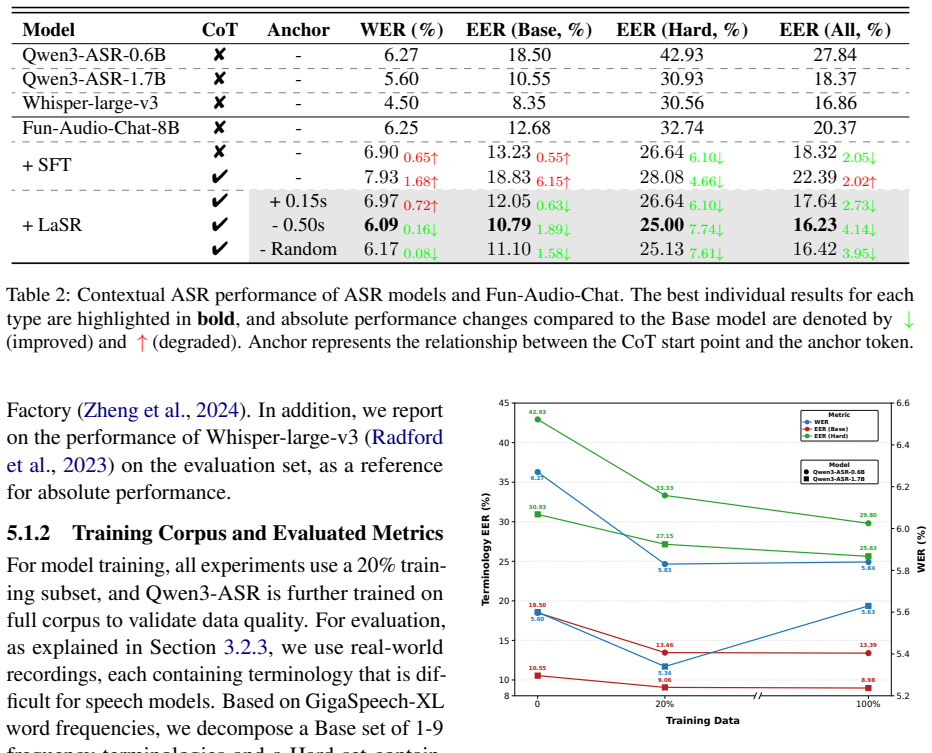
- [Abstract] Abstract: the claim that LaSR 'significantly improves terminology recognition' and 'consistently outperforms standard supervised fine-tuning baselines' is presented without any numerical metrics (e.g., WER, accuracy deltas), baseline specifications, statistical tests, or error analysis, which is load-bearing for the central empirical claim.
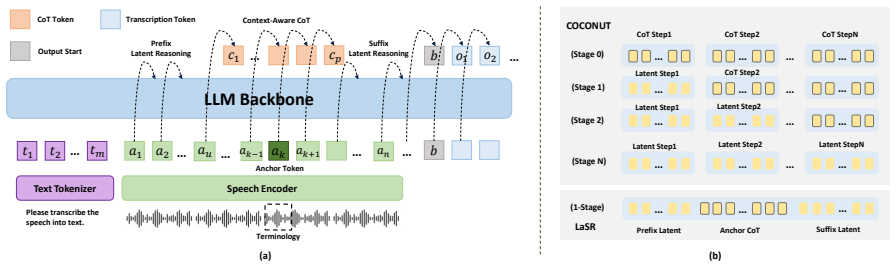
- [Abstract] Abstract / LaSR description: the mechanism of 'latent reasoning periods' for 'context information grounding and transcriptional transition' is introduced at a conceptual level with no equations, pseudocode, or precise alignment procedure, preventing assessment of whether the method is reproducible or reduces to standard fine-tuning.
minor comments (1)
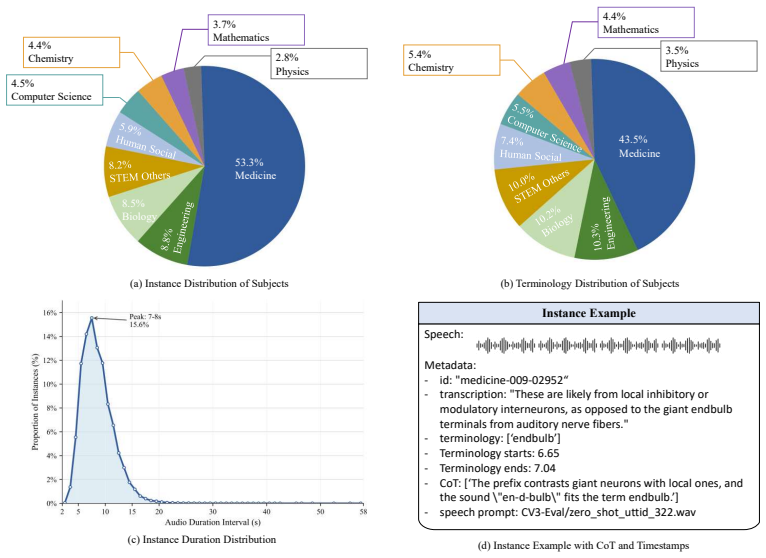
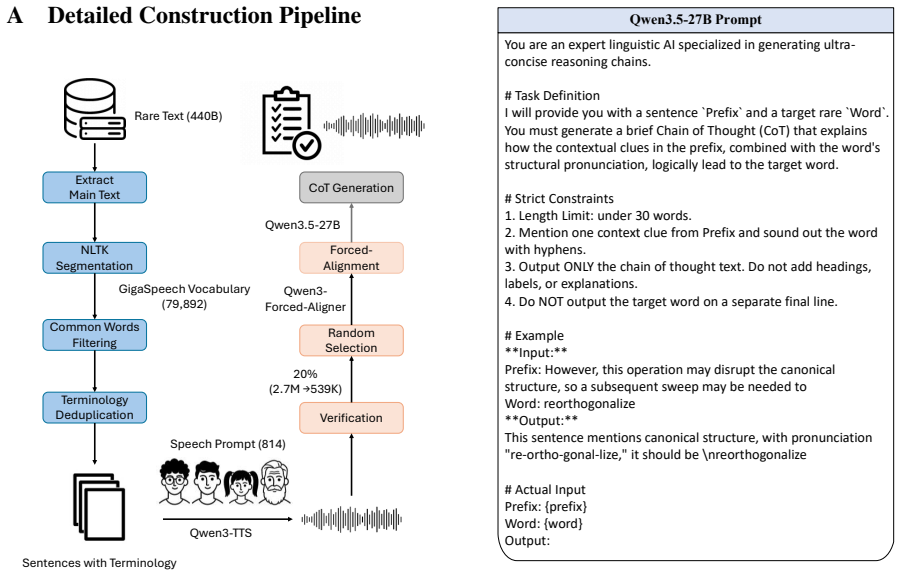
- [Abstract] The abstract mentions a 'large-scale corpus' but supplies no statistics on size, vocabulary coverage, or construction details; adding a brief quantitative summary would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point-by-point below and will incorporate revisions to strengthen the abstract and methodological clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that LaSR 'significantly improves terminology recognition' and 'consistently outperforms standard supervised fine-tuning baselines' is presented without any numerical metrics (e.g., WER, accuracy deltas), baseline specifications, statistical tests, or error analysis, which is load-bearing for the central empirical claim.
Authors: We agree that the abstract's empirical claims would benefit from explicit quantitative support. The full manuscript reports concrete results from preliminary experiments on Fun-Audio-Chat (including WER and terminology accuracy deltas versus standard SFT baselines), but these were not summarized numerically in the abstract. In revision we will add specific metrics, baseline details, and any available statistical context directly into the abstract while preserving its length constraints. revision: yes
-
Referee: [Abstract] Abstract / LaSR description: the mechanism of 'latent reasoning periods' for 'context information grounding and transcriptional transition' is introduced at a conceptual level with no equations, pseudocode, or precise alignment procedure, preventing assessment of whether the method is reproducible or reduces to standard fine-tuning.
Authors: We acknowledge the abstract presents the latent reasoning periods at a high level. The manuscript body contains the alignment procedure for CoT supervision on acoustic regions, but it lacks explicit equations or pseudocode. In the revised version we will add a concise algorithmic description or pseudocode box in the methods section and ensure the abstract references this distinction from standard fine-tuning to improve reproducibility assessment. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces LaSR as a training paradigm that aligns chain-of-thought supervision to acoustic regions and adds latent reasoning periods, then reports empirical gains on terminology recognition versus supervised fine-tuning baselines on Fun-Audio-Chat. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The claimed improvement is framed as an external experimental comparison rather than a quantity forced by the method's own definitions or prior self-referential results. The derivation chain is therefore self-contained as an empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Aligning CoT supervision to acoustic feature regions of target words enables effective context grounding and transcriptional transition without explicit tokens.
invented entities (1)
-
latent reasoning periods
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2604.00610 , year=
Speech LLMs are Contextual Reasoning Transcribers , author=. arXiv preprint arXiv:2604.00610 , year=
-
[2]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
VocalNet: Speech LLMs with Multi-Token Prediction for Faster and High-Quality Generation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[3]
arXiv preprint arXiv:2512.20156 , year=
Fun-Audio-Chat Technical Report , author=. arXiv preprint arXiv:2512.20156 , year=
-
[4]
arXiv preprint arXiv:2503.11197 , year=
Reinforcement learning outperforms supervised fine-tuning: A case study on audio question answering , author=. arXiv preprint arXiv:2503.11197 , year=
-
[5]
Qwen3-omni technical report , author=. arXiv preprint arXiv:2509.17765 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Step-audio 2 technical report , author=. arXiv preprint arXiv:2507.16632 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Post-decoder Biasing for End-to-End Speech Recognition of Multi-turn Medical Interview , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[9]
2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
Tree-constrained pointer generator for end-to-end contextual speech recognition , author=. 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=. 2021 , organization=
2021
-
[10]
GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot
Glm-4-voice: Towards intelligent and human-like end-to-end spoken chatbot , author=. arXiv preprint arXiv:2412.02612 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Qwen2. 5-omni technical report , author=. arXiv preprint arXiv:2503.20215 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2511.15848 , year=
Step-Audio-R1 Technical Report , author=. arXiv preprint arXiv:2511.15848 , year=
-
[13]
Step-Audio-R1.5 Technical Report
Step-Audio-R1. 5 Technical Report , author=. arXiv preprint arXiv:2604.25719 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2512.23808 , year=
MiMo-Audio: Audio Language Models are Few-Shot Learners , author=. arXiv preprint arXiv:2512.23808 , year=
-
[15]
, author=
Shallow-Fusion End-to-End Contextual Biasing. , author=. Interspeech , pages=
-
[16]
2018 IEEE spoken language technology workshop (SLT) , pages=
Deep context: end-to-end contextual speech recognition , author=. 2018 IEEE spoken language technology workshop (SLT) , pages=. 2018 , organization=
2018
-
[17]
2024 IEEE Spoken Language Technology Workshop (SLT) , pages=
Ctc-assisted llm-based contextual asr , author=. 2024 IEEE Spoken Language Technology Workshop (SLT) , pages=. 2024 , organization=
2024
-
[18]
arXiv preprint arXiv:2602.07824 , year=
Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training , author=. arXiv preprint arXiv:2602.07824 , year=
-
[19]
22nd Annual Conference of the International Speech Communication Association, INTERSPEECH 2021 , pages=
GigaSpeech: An evolving, multi-domain ASR corpus with 10,000 hours of transcribed audio , author=. 22nd Annual Conference of the International Speech Communication Association, INTERSPEECH 2021 , pages=. 2021 , organization=
2021
-
[20]
Proceedings of the COLING/ACL 2006 interactive presentation sessions , pages=
NLTK: the natural language toolkit , author=. Proceedings of the COLING/ACL 2006 interactive presentation sessions , pages=
2006
-
[21]
DNSMOS Pro: A Reduced-Size DNN for Probabilistic MOS of Speech , author=. Proc. Interspeech 2024 , pages=
2024
-
[22]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training , author=. arXiv preprint arXiv:2505.17589 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Seed-tts: A family of high-quality versatile speech generation models , author=. arXiv preprint arXiv:2406.02430 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Qwen3-ASR Technical Report , author=. arXiv preprint arXiv:2601.21337 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[26]
LIMO: Less is More for Reasoning
Limo: Less is more for reasoning , author=. arXiv preprint arXiv:2502.03387 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
International Conference on Learning Representations , volume=
Mammoth: Building math generalist models through hybrid instruction tuning , author=. International Conference on Learning Representations , volume=
-
[28]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
From explicit cot to implicit cot: Learning to internalize cot step by step , author=. arXiv preprint arXiv:2405.14838 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Advances in Neural Information Processing Systems , volume=
Think silently, think fast: Dynamic latent compression of llm reasoning chains , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Codi: Compressing chain-of-thought into continuous space via self-distillation , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[32]
International Conference on Machine Learning , pages=
Token Assorted: Mixing Latent and Text Tokens for Improved Language Model Reasoning , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[33]
Qwen3-TTS Technical Report , author=. arXiv preprint arXiv:2601.15621 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations) , pages=
-
[35]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen Team , month =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[36]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[37]
2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
Librispeech: an asr corpus based on public domain audio books , author=. 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2015 , organization=
2015
-
[38]
Exploring SSL Discrete Speech Features for Zipformer-based Contextual ASR , author=. Proc. Interspeech 2025 , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.