Generate in Reconstruction Space, Match in Semantic Space: Transport Geometry for One-Step Generation
Pith reviewed 2026-06-28 18:56 UTC · model grok-4.3
The pith
One-step generators match data effectively when transport is performed in semantic SSL space
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Sinkhorn divergence computed in a semantically structured SSL feature space provides an effective training objective for one-step generation; the effectiveness arises because semantic features suppress nuisance reconstruction details and thereby induce a more compact geometry that renders distribution matching more tractable.
What carries the argument
Sinkhorn divergence computed in frozen SSL feature space as a tractable surrogate for Wasserstein distance
Load-bearing premise
Semantic SSL features suppress nuisance reconstruction details and thereby induce a more compact geometry that renders distribution matching more tractable.
What would settle it
A controlled experiment in which one-step models trained with SSL features show no gain in matching stability or sample quality over pixel-space baselines, or in which the reported FID reduction disappears when evaluation uses the identical feature extractor as training.
Figures
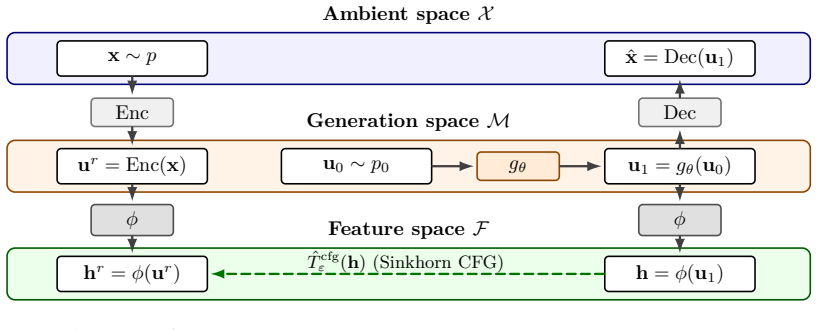
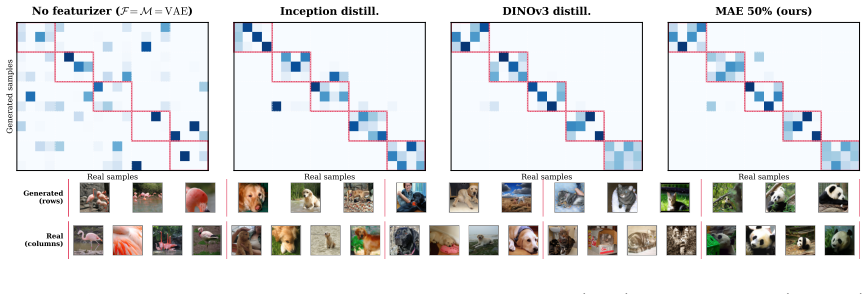






read the original abstract
Generative modeling and self-supervised representation learning (SSL) optimize structurally different objectives: generative training rewards distributional fidelity, while SSL rewards semantic coherence. Yet recent work repeatedly finds that SSL features improve generative training, though the mechanism of this synergy remains unclear. Here, we study the benefits of SSL in generative modeling in the framework of one-step generation where the role of representation is explicit: frozen SSL features are used to match generated samples to real data. We use the Sinkhorn divergence in that feature space, providing a tractable surrogate for the Wasserstein distance, the population-level discrepancy approximated by Fr\'echet-style evaluation metrics (such as FID). We find that this objective becomes highly effective when computed in a semantically structured SSL feature space (a 39$\times$ reduction in ImageNet FID). We trace this behavior primarily to matching estimation: semantic SSL features that suppress nuisance reconstruction details induce a more compact geometry, making distribution matching more tractable. As a consequence, the best training SSL features need not match the features used by the evaluation metric. In particular, we show that using Inception as the feature extractor can improve FID while degrading matching stability and sample quality, revealing a form of metric hacking. Using extensive experiments on ImageNet, we identify which SSL feature families lead to best generation performance and show that matching stability is a quantitative criterion for selecting them. Code is available at https://github.com/Genentech/semantic-transport-generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies one-step generative modeling where samples are generated in pixel space but matched to data via Sinkhorn divergence computed in a frozen SSL feature space. It reports that semantically structured SSL features yield a 39× reduction in ImageNet FID relative to other choices, attributes the gain to a more compact geometry that renders distribution matching tractable, and shows that the optimal training features differ from those used by standard FID (Inception), thereby exposing a form of metric hacking. Experiments on ImageNet identify effective SSL feature families and propose matching stability as a selection criterion; code is released.
Significance. If the reported gains and mechanistic account hold, the work supplies a concrete, reproducible recipe for improving one-step generators and a practical criterion for choosing feature spaces that is distinct from evaluation metrics. The explicit contrast between training-time matching and FID computation, together with the public code, strengthens the contribution for the one-step and transport-based generation literature.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the central 39× FID reduction is stated without error bars, standard deviations across random seeds, or an explicit statement of the exact baseline (e.g., which non-SSL feature extractor or pixel-space Sinkhorn). Because this number is the primary empirical support for the geometry claim, the absence of statistical characterization weakens the ability to judge whether the improvement is robust.
- [Discussion of mechanism] § on tracing behavior to matching estimation: the attribution of gains to 'more compact geometry' induced by semantic SSL features is presented as the primary explanation, yet no quantitative diagnostic (e.g., covariance condition number, effective dimension, or Sinkhorn convergence rate) is reported to distinguish this mechanism from alternatives such as improved semantic alignment or reduced sensitivity to nuisance factors.
- [Experiments] Experiments on feature-family comparison: while the manuscript identifies which SSL families perform best, the tables do not include an ablation that isolates the contribution of the Sinkhorn surrogate itself versus the choice of feature extractor (e.g., replacing Sinkhorn with a simpler moment-matching loss in the same SSL space). This comparison is load-bearing for the claim that the transport geometry, rather than the representation alone, drives the improvement.
minor comments (2)
- [Method] Notation for the Sinkhorn divergence and its entropic regularization parameter should be introduced once with a clear equation reference rather than re-defined inline in multiple sections.
- [Figures] Figure captions for the stability plots should explicitly state the number of Sinkhorn iterations and the batch size used, as these hyperparameters directly affect the reported stability criterion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central 39× FID reduction is stated without error bars, standard deviations across random seeds, or an explicit statement of the exact baseline (e.g., which non-SSL feature extractor or pixel-space Sinkhorn). Because this number is the primary empirical support for the geometry claim, the absence of statistical characterization weakens the ability to judge whether the improvement is robust.
Authors: We agree that statistical characterization strengthens the claim. The 39× figure is computed against a pixel-space Sinkhorn baseline; in revision we will report standard deviations over multiple random seeds for the key FID values and explicitly restate the baseline in both the abstract and experiments section. revision: yes
-
Referee: [Discussion of mechanism] § on tracing behavior to matching estimation: the attribution of gains to 'more compact geometry' induced by semantic SSL features is presented as the primary explanation, yet no quantitative diagnostic (e.g., covariance condition number, effective dimension, or Sinkhorn convergence rate) is reported to distinguish this mechanism from alternatives such as improved semantic alignment or reduced sensitivity to nuisance factors.
Authors: The manuscript grounds the compact-geometry account in the observed matching-stability differences across feature families. We will add covariance condition numbers and effective-dimension estimates for the principal feature spaces to the appendix, providing a quantitative supplement to the stability criterion. revision: partial
-
Referee: [Experiments] Experiments on feature-family comparison: while the manuscript identifies which SSL families perform best, the tables do not include an ablation that isolates the contribution of the Sinkhorn surrogate itself versus the choice of feature extractor (e.g., replacing Sinkhorn with a simpler moment-matching loss in the same SSL space). This comparison is load-bearing for the claim that the transport geometry, rather than the representation alone, drives the improvement.
Authors: All reported comparisons hold the Sinkhorn objective fixed while varying only the feature extractor; this design isolates the representation's effect on transport matching. An ablation that swaps the divergence for moment matching would test a different modeling choice and lies outside the paper's scope. We will insert a clarifying sentence in the experiments section to make this experimental logic explicit. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper reports direct experimental comparisons of Sinkhorn matching in different fixed SSL feature spaces on ImageNet, yielding a 39x FID reduction. These gains are measured against standard public extractors and evaluation metrics without any fitted parameters or equations that loop back to the same experiment's inputs. The interpretation that semantic features induce compact geometry is presented as a post-hoc explanation of observed stability and quality metrics, not as a derivation that reduces to self-definition or self-citation. No load-bearing step invokes a uniqueness theorem or ansatz from prior author work that would force the result.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Sinkhorn divergence provides a tractable surrogate for the Wasserstein distance
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2112.058142(3), 4 (2021)
Shir Amir, Yossi Gandelsman, Shai Bagon, and Tali Dekel. Deep vit features as dense visual descriptors.arXiv preprint arXiv:2112.05814, 2021. URL https://arxiv.org/abs/2112. 05814
-
[2]
Single-cell concept bottleneck generative models for interpretable and controllable cellular editing
Alma Andersson, Aya Abdelsalam Ismail, Edward De Brouwer, Doron Haviv, Tommaso Bian- calani, Kyunghyun Cho, Gabriele Scalia, Aicha BenTaieb, and Hector Corrada Bravo. Single-cell concept bottleneck generative models for interpretable and controllable cellular editing. InICLR 2026 Workshop on Machine Learning for Genomics Explorations, 2026
2026
-
[3]
Wasserstein generative adversarial networks
Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. InInternational Conference on Machine Learning, pages 214–223. PMLR, 2017
2017
-
[4]
stable-pretraining- v1: Foundation model research made simple.arXiv preprint arXiv:2511.19484, 2025
Randall Balestriero, Hugues Van Assel, Sami BuGhanem, and Lucas Maes. stable-pretraining- v1: Foundation model research made simple.arXiv preprint arXiv:2511.19484, 2025. URL https://arxiv.org/abs/2511.19484
-
[5]
VFM-VAE: Vision Foundation Models Can Be Good Tokenizers for Latent Diffusion Models
Tianci Bi, Xiaoyi Zhang, Yan Lu, and Nanning Zheng. Vision foundation models can be good tokenizers for latent diffusion models.arXiv preprint arXiv:2510.18457, 2025. URL https://arxiv.org/abs/2510.18457
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Bowei Chen, Sai Bi, Hao Tan, He Zhang, Tianyuan Zhang, Zhengqi Li, Yuanjun Xiong, Jianming Zhang, and Kai Zhang. AlignTok: Aligning Visual Foundation Encoders to Tokenizers for Diffusion Models.arXiv preprint arXiv:2509.25162, 2025. URLhttps://arxiv.org/abs/2509. 25162
-
[7]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, pages 2292–2300, 2013. URLhttps://proceedings.neurips.cc/ paper/2013/hash/af21d0c97db2e27e13572cbf59eb343d-Abstract.html
2013
-
[8]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting.arXiv preprint arXiv:2602.04770, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Density estimation using real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real NVP. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URLhttps://openreview. net/forum?id=HkpbnH9lx
2017
-
[10]
D. C. Dowson and B. V. Landau. The Fréchet distance between multivariate normal distributions. Journal of Multivariate Analysis, 12(3):450–455, 1982
1982
-
[11]
Interpolating between optimal transport and mmd using sinkhorn divergences
Jean Feydy, Thibault Séjourné, François-Xavier Vialard, Shun-ichi Amari, Alain Trouvé, and Gabriel Peyré. Interpolating between optimal transport and mmd using sinkhorn divergences. InThe 22nd international conference on artificial intelligence and statistics, pages 2681–2690. PMLR, 2019
2019
-
[12]
Yuan Gao, Chen Chen, Tianrong Chen, and Jiatao Gu. One layer is enough: Adapting pretrained visual encoders for image generation.arXiv preprint arXiv:2512.07829, 2025. URL https://arxiv.org/abs/2512.07829
-
[13]
Matthias Gelbrich. On a formula for theL2 wasserstein metric between measures on euclidean and hilbert spaces.Mathematische Nachrichten, 147(1):185–203, 1990. doi: 10.1002/mana. 19901470121
-
[14]
Learning generative models with sinkhorn divergences
Aude Genevay, Gabriel Peyré, and Marco Cuturi. Learning generative models with sinkhorn divergences. InInternational Conference on Artificial Intelligence and Statistics, pages 1608–1617. PMLR, 2018. 11
2018
-
[15]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 2672–2680, 2014. URL...
2014
-
[16]
Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Ávila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Ávila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, and Michal Valko. Bootstrap your own latent – A new approach to self-supervised learning. InAdvances in Neural Information Processi...
2020
-
[17]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9726–9735, 2020
2020
-
[18]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross B. Girshick. Masked autoencoders are scalable vision learners. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 15979– 15988. IEEE, 2022. doi: 10.1109/CVPR52688.2022.01553. URLhttps://doi.org/10.1109/ CVPR52688...
-
[19]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30, pages 6626–6637....
2017
-
[20]
Denoising diffusion probabilistic mod- els
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic mod- els. InAdvances in Neural Information Processing Systems 33: Annual Confer- ence on Neural Information Processing Systems 2020, NeurIPS 2020, December 6- 12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/ 4c5bcfec8584af0d967f1ab10179ca4b-Abstract.html
2020
-
[21]
Multiplexed droplet single-cell RNA-sequencing using natural genetic variation.Nature Biotechnology, 36(1): 89–94, 2018
Hyun Min Kang, Meena Subramaniam, Sasha Targ, Michelle Nguyen, Lenka Maliskova, Elizabeth McCarthy, Eunice Wan, Simon Wong, Lauren Byrnes, Cristina M Lanata, et al. Multiplexed droplet single-cell RNA-sequencing using natural genetic variation.Nature Biotechnology, 36(1): 89–94, 2018
2018
-
[22]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URLhttp://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Jiachen Lei, Keli Liu, Julius Berner, Haiming Yu, Hongkai Zheng, Jiahong Wu, and Xiangxiang Chu. There is no VAE: End-to-end pixel-space generative modeling via self-supervised pre- training.arXiv preprint arXiv:2510.12586, 2025. URLhttps://arxiv.org/abs/2510.12586
-
[24]
arXiv preprint arXiv:2504.10483 (2025)
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. REPA-E: Unlocking VAE for End-to-End Tuning with Latent Diffusion Transformers.arXiv preprint arXiv:2504.10483, 2025. URLhttps://arxiv.org/abs/2504.10483
-
[25]
Generative moment matching networks
Yujia Li, Kevin Swersky, and Rich Zemel. Generative moment matching networks. InInterna- tional Conference on Machine Learning, pages 1718–1727. PMLR, 2015. 12
2015
-
[26]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[27]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/forum?id=XVjTT1nw5z
2023
-
[28]
Deep generative modeling for single-cell transcriptomics.Nature Methods, 15(12):1053–1058, 2018
Romain Lopez, Jeffrey Regier, Michael B Cole, Michael I Jordan, and Nir Yosef. Deep generative modeling for single-cell transcriptomics.Nature Methods, 15(12):1053–1058, 2018
2018
-
[29]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019. OpenReview.net, 2019. URLhttps: //openreview.net/forum?id=Bkg6RiCqY7
2019
-
[30]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jégou, Julien Mairal, Patrick Lab...
2024
-
[31]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4172–4182, 2023
2023
-
[32]
Gabriel Peyré and Marco Cuturi. Computational optimal transport.Foundations and Trends in Machine Learning, 11(5-6):355–607, 2019. doi: 10.1561/2200000073. URLhttps://doi.org/ 10.1561/2200000073
-
[33]
Entropic estimation of optimal transport maps.arXiv preprint arXiv:2109.12004, 2021
Aram-Alexandre Pooladian and Jonathan Niles-Weed. Entropic estimation of optimal transport maps.arXiv preprint arXiv:2109.12004, 2021. URLhttps://arxiv.org/abs/2109.12004
-
[34]
Modeling complex system dynamics with flow matching across time and conditions
Martin Rohbeck, Edward De Brouwer, Charlotte Bunne, Jan-Christian Huetter, Anne Biton, Kelvin Chen, Aviv Regev, and Romain Lopez. Modeling complex system dynamics with flow matching across time and conditions. InInternational Conference on Learning Representations, volume 2025, pages 12164–12188, 2025
2025
-
[35]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models.arXiv preprint arXiv:2112.10752, 2022. URLhttps://arxiv.org/abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
URLhttps://arxiv.org/abs/2508.10104
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Jaskirat Singh, Xingjian Leng, Zongze Wu, Liang Zheng, Richard Zhang, Eli Shechtman, and Saining Xie. What matters for representation alignment: Global information or spatial structure? arXiv preprint arXiv:2512.10794, 2025. URLhttps://arxiv.org/abs/2512.10794
-
[39]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URLhttps://openreview.net/forum?id=PxTIG12RRHS. 13
2021
-
[40]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2818–2826. IEEE Computer Society, 2016. URL https://doi.org/10.1109/CVPR.2016.308
-
[41]
arXiv preprint arXiv:2505.12477 , year=
Hugues Van Assel, Mark Ibrahim, Tommaso Biancalani, Aviv Regev, and Randall Balestriero. Joint embedding vs reconstruction: Provable Benefits of Latent Space Prediction for Self Supervised Learning. InAdvances in Neural Information Processing Systems, 2025. URL https://arxiv.org/abs/2505.12477
-
[42]
Cédric Villani.Optimal Transport: Old and New, volume 338. Springer Science & Business Media, 2008. doi: 10.1007/978-3-540-71050-9
-
[43]
Runqian Wang and Kaiming He. Diffuse and Disperse: Image Generation with Representation Regularization.arXiv preprint arXiv:2506.09027, 2025. URL https://arxiv.org/abs/2506. 09027
-
[44]
Ziqiao Wang, Wangbo Zhao, Yuhao Zhou, Zekai Li, Zhiyuan Liang, Mingjia Shi, Xuanlei Zhao, Pengfei Zhou, Kaipeng Zhang, Zhangyang Wang, Kai Wang, and Yang You. REPA works until it doesn’t: Early-stopped, holistic alignment supercharges diffusion training.arXiv preprint arXiv:2505.16792, 2025. URLhttps://arxiv.org/abs/2505.16792
-
[45]
Video-bench: Human-aligned video generation benchmark
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 15703–15712. Computer Vision Foundation / IEEE, 2025. doi: 10.1109/CVPR52734.2025.01464. URL https://opena...
-
[46]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think.arXiv preprint arXiv:2410.06940, 2024. URLhttps://arxiv.org/ abs/2410.06940
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion Transformers with Representation Autoencoders.arXiv preprint arXiv:2510.11690, 2025. URLhttps://arxiv. org/abs/2510.11690. 14 Table of Contents •Section A: Notation.Summary of symbols used in the main text. • Section B: Sinkhorn Algorithms and Gradient.Log-domain Sinkhorn iterations, symme...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Sample a batch ofNc class labels and per-class guidance weightswc
-
[49]
For each classc: generateNneg images, drawNpos positives andNunc unconditional samples from queues
-
[50]
Extract multi-scale features on all generated, positive, and unconditional samples. 17
-
[51]
Normalize features; compute the conditional cross-, unconditional cross-, and self-transport targets; normalize
-
[52]
Compute the Sinkhorn divergence loss summed over all classes and features
-
[53]
The remainder of this section elaborates on each component
Run backpropagation and update parameters; update EMA. The remainder of this section elaborates on each component. Data loading, queues, and batching.At each training step, Nc class labels are sampled uniformly at random andNneg images are generated per class, yielding an effective batch size B =Nc×Nneg. Real samples are provided by a standard DataLoader ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.