Activation Concentration: Characterizing Column-Level Output Sparsity Across Diffusion Model Architectures
Pith reviewed 2026-06-28 18:21 UTC · model grok-4.3
The pith
Element-level sparsity overstates hardware-exploitable sparsity in diffusion models by up to 78 points and produces a three-way taxonomy of workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
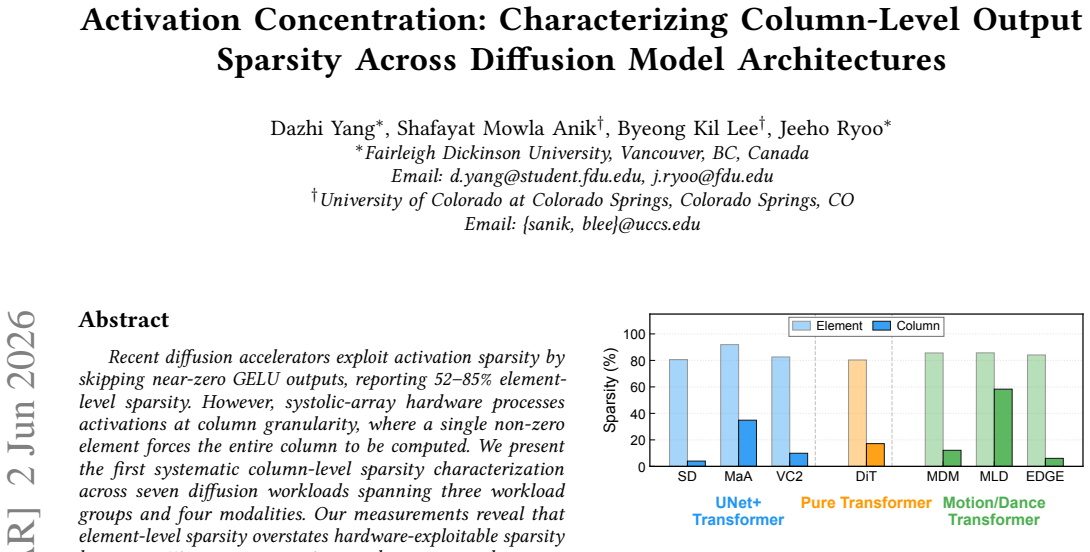
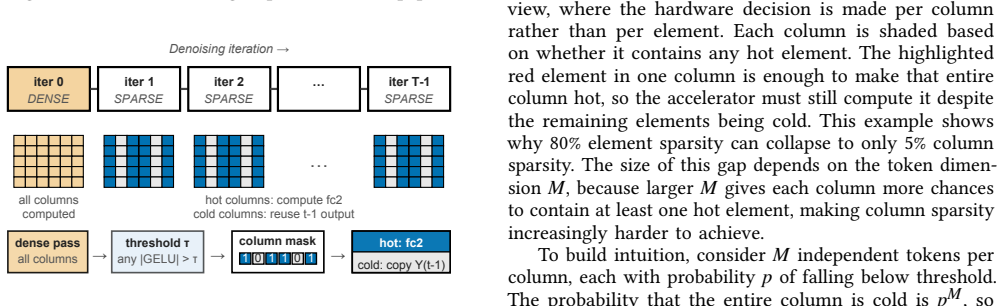
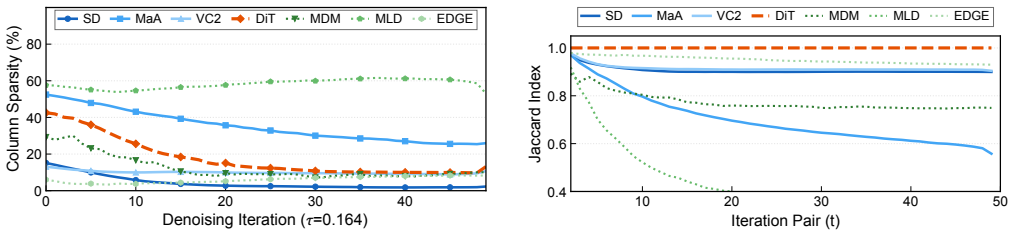
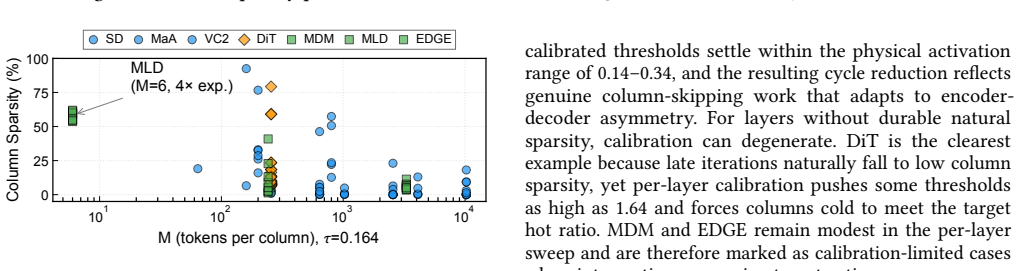
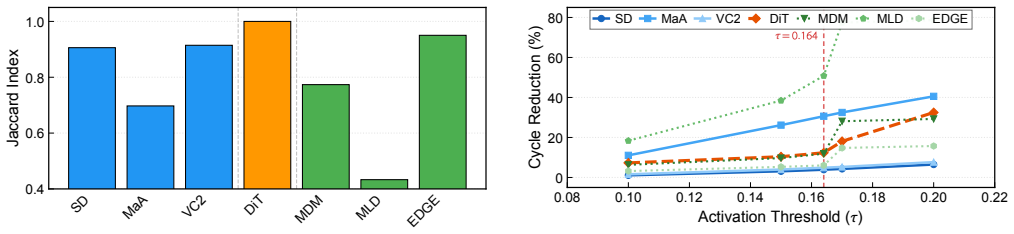
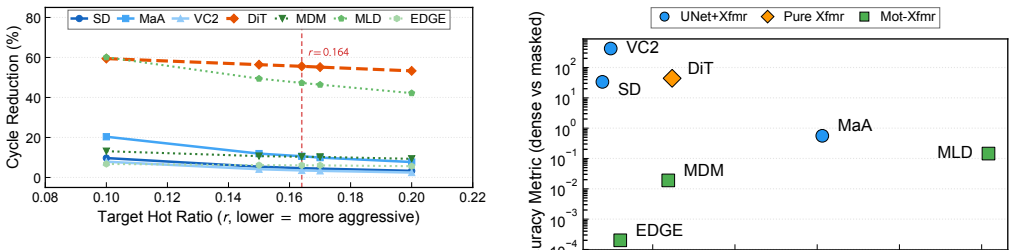
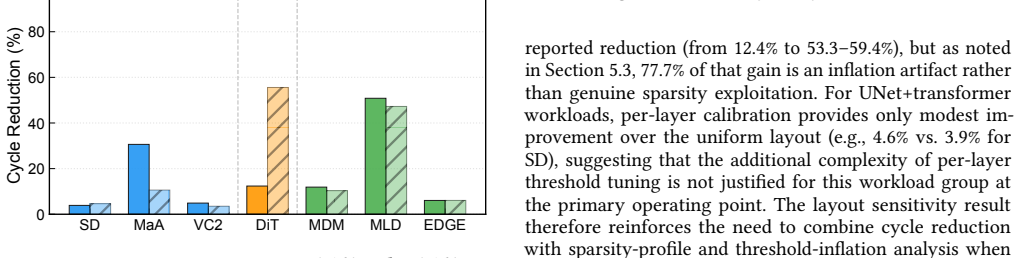
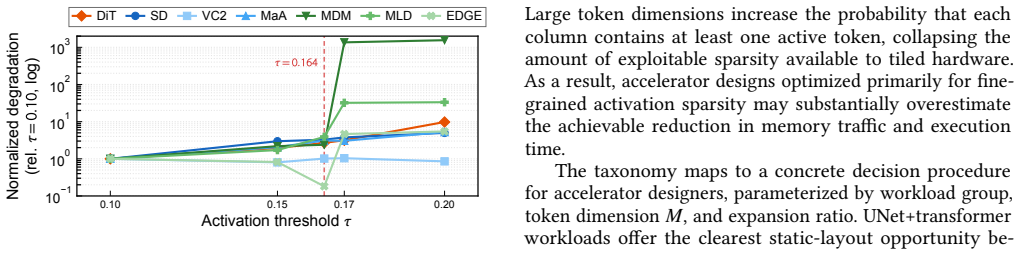
Measurements across seven diffusion workloads reveal that element-level sparsity overstates hardware-exploitable sparsity by up to 78 percentage points and exposes a three-way taxonomy. UNet+transformer workloads exhibit activation concentration with workload-dependent cycle reductions up to 30.6 percent. Pure-transformer DiT shows dispersion, yielding 12.4 percent. Motion/dance transformer workloads range from modest reductions to 50.8 percent for MLD. Cycle-level simulation on a GDDR6-based accelerator confirms that memory stalls account for up to 84-89 percent of total cycles and that layout sensitivity tracks the profiling-based taxonomy. A full accuracy sweep across five thresholds reve
What carries the argument
activation concentration, the clustering of non-zero GELU outputs into fewer columns rather than spreading evenly
If this is right
- UNet+transformer workloads permit up to 30.6 percent cycle reductions when column skipping is enabled.
- Pure-transformer DiT workloads deliver only 12.4 percent reductions because of activation dispersion.
- Motion transformer workloads produce cycle reductions between modest values and 50.8 percent depending on token dimension and expansion ratio.
- Memory stalls account for 84-89 percent of total cycles on a GDDR6-based accelerator regardless of sparsity.
- Workload group together with model dimensions determines whether column-level memory layout changes improve performance.
Where Pith is reading between the lines
- Hardware designs for diffusion inference could add column-aware skipping units that activate only for UNet-hybrid models.
- Model designers could adjust expansion ratios in transformer blocks to increase column concentration and raise hardware efficiency.
- Threshold selection for sparsity must be validated per workload group to avoid the accuracy cliff observed in motion models.
- The same column-level measurement method could be applied to non-diffusion generative models to test whether the three-way pattern holds.
Load-bearing premise
The seven chosen diffusion workloads and four modalities are representative enough that the observed three-way taxonomy and cycle-reduction numbers will generalize to other diffusion architectures and future models.
What would settle it
Profiling column-level sparsity on one additional diffusion model outside the original seven and finding its cycle reduction lies far outside the ranges reported for its workload group.
Figures




read the original abstract
Recent diffusion accelerators exploit activation sparsity by skipping near-zero GELU outputs, reporting 52--85% element-level sparsity. However, systolic-array hardware processes activations at column granularity, where a single non-zero element forces the entire column to be computed. We present the first systematic column-level sparsity characterization across seven diffusion workloads spanning three workload groups and four modalities. Our measurements reveal that element-level sparsity overstates hardware-exploitable sparsity by up to 78 percentage points and exposes a three-way taxonomy. UNet+transformer workloads exhibit activation concentration with workload-dependent cycle reductions up to 30.6%. Pure-transformer DiT shows dispersion, yielding 12.4%. Motion/dance transformer workloads range from modest reductions to 50.8% for MLD, driven by its extreme token dimension and expansion ratio. Cycle-level simulation on a GDDR6-based accelerator confirms that memory stalls account for up to 84--89% of total cycles and that layout sensitivity tracks the profiling-based taxonomy. A full accuracy sweep across five thresholds reveals that UNet+transformer workloads degrade gracefully, while motion models exhibit an accuracy cliff between the primary operating point and the next threshold. Our characterization shows that workload group and model dimensions jointly determine whether column-level memory layout optimization is beneficial, and element-level sparsity alone is insufficient for that prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic column-level sparsity characterization across seven diffusion workloads spanning three groups (UNet+transformer, pure-transformer DiT, motion/dance) and four modalities. It claims element-level sparsity overstates hardware-exploitable (column-level) sparsity by up to 78 percentage points, exposing a three-way taxonomy: activation concentration in UNet+transformer workloads (workload-dependent cycle reductions up to 30.6%), dispersion in DiT (12.4%), and variable behavior in motion workloads (up to 50.8% for MLD, linked to token dimension and expansion ratio). Cycle-level simulation on a GDDR6 accelerator shows memory stalls account for 84-89% of cycles with layout sensitivity matching the taxonomy; a full accuracy sweep across five thresholds indicates graceful degradation for UNet+transformer but an accuracy cliff for motion models. The work concludes that workload group and model dimensions jointly determine the benefit of column-level memory layout optimization.
Significance. If the taxonomy and associated cycle-reduction numbers generalize, the result would be significant for guiding sparsity-exploiting accelerator designs in diffusion models, demonstrating that element-level metrics alone are insufficient predictors and that layout sensitivity and model dimensions (token count, expansion ratio) must be considered. The concrete simulation breakdown of memory stalls (84-89%) and the accuracy-threshold analysis provide actionable data for hardware-software co-design. The empirical scope across modalities is a strength of the characterization.
major comments (2)
- [Experimental setup / workload selection] Workload selection and taxonomy derivation: The manuscript provides no explicit selection criteria, coverage argument, or comparison against held-out models for the seven workloads and four modalities. This is load-bearing for the central claim, as the three-way taxonomy (concentration/dispersion/variable) and specific numbers (78 pp overstatement, 30.6%/12.4%/50.8% cycle reductions) could be artifacts of the chosen instances rather than defining workload groups.
- [Methods / abstract] Methods description: No details are given on measurement methodology, error bars, raw data, statistical significance, or sensitivity of the post-hoc grouping into three categories. This directly affects the reliability of all reported percentages and the taxonomy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for clearer justification of workload selection and expanded methods details. We address both major comments below and commit to revisions that strengthen the manuscript without altering its core claims or results.
read point-by-point responses
-
Referee: [Experimental setup / workload selection] Workload selection and taxonomy derivation: The manuscript provides no explicit selection criteria, coverage argument, or comparison against held-out models for the seven workloads and four modalities. This is load-bearing for the central claim, as the three-way taxonomy (concentration/dispersion/variable) and specific numbers (78 pp overstatement, 30.6%/12.4%/50.8% cycle reductions) could be artifacts of the chosen instances rather than defining workload groups.
Authors: The seven workloads were deliberately chosen as canonical, publicly available representatives of the three primary architectural families in diffusion models: UNet+transformer hybrids (Stable Diffusion v1.5/v2.1 and similar), pure-transformer DiT, and motion/dance transformers (MLD and related models). These span the four modalities noted and reflect the most commonly deployed designs in the literature. The taxonomy is not arbitrary but follows directly from measured differences in column-level activation concentration, which align with architectural parameters such as token dimension and expansion ratio. While we lack resources for a formal coverage argument or held-out model experiments, the patterns are consistent within each group. In revision we will add an explicit subsection detailing selection criteria and architectural rationale. revision: partial
-
Referee: [Methods / abstract] Methods description: No details are given on measurement methodology, error bars, raw data, statistical significance, or sensitivity of the post-hoc grouping into three categories. This directly affects the reliability of all reported percentages and the taxonomy.
Authors: We agree the current methods description is insufficiently detailed. Column-level sparsity is obtained by thresholding activations and counting non-zero columns per tensor; cycle estimates derive from a deterministic cycle-level simulator of a GDDR6 systolic-array accelerator. Because results are fully determined by model weights, inputs, and thresholds, error bars and statistical tests were omitted. The three-category grouping is post-hoc but driven by clear quantitative gaps in non-zero column fraction and cycle savings. In the revised manuscript we will expand the methods section with measurement pseudocode, a sensitivity discussion of the grouping thresholds, and availability of raw data. revision: yes
Circularity Check
No circularity: pure empirical profiling study
full rationale
The paper reports direct measurements of activation sparsity at element vs. column granularity across seven diffusion workloads, followed by cycle-level simulation on a GDDR6 accelerator. No equations, fitted parameters, or derivations are present that could reduce any claimed result to prior fitted quantities or self-citations by construction. The three-way taxonomy, cycle-reduction percentages, and memory-stall observations are outputs of the profiling and simulation runs themselves, not inputs renamed or fitted. Self-citation is absent from the provided text, and the central claims rest on the chosen workloads' measured behavior rather than any imported uniqueness theorem or ansatz. This is a standard self-contained empirical characterization; the representativeness concern raised by the skeptic is a question of external validity, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A scalable processing- in-memory accelerator for parallel graph processing,
J. Ahn, S. Hong, S. Yoo, O. Mutlu, and K. Choi, “A scalable processing- in-memory accelerator for parallel graph processing, ” inProceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA), 2015, pp. 105–117
2015
-
[2]
Stable video diffusion: Scaling latent video diffusion models to large datasets,
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y. Levi, Z. English, V. Voleti, A. Letts, V. Jampani, and R. Rombach, “Stable video diffusion: Scaling latent video diffusion models to large datasets, ” 2023. 10
2023
-
[3]
Token merging for fast stable diffusion,
D. Bolya and J. Hoffman, “Token merging for fast stable diffusion, ” 2023
2023
-
[4]
VideoCrafter2: Overcoming data limitations for high-quality video diffusion models,
H. Chen, Y. Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y. Shan, “VideoCrafter2: Overcoming data limitations for high-quality video diffusion models, ”arXiv preprint arXiv:2401.09047, 2024
-
[5]
WaveGrad: Estimating gradients for waveform generation,
N. Chen, Y. Zhang, H. Zen, R. J. Weiss, M. Norouzi, and W. Chan, “WaveGrad: Estimating gradients for waveform generation, ” 2020
2020
-
[6]
DianNao: A small-footprint high-throughput accelerator for ubiqui- tous machine-learning,
T. Chen, Z. Du, N. Sun, J. Wang, C. Wu, Y. Chen, and O. Temam, “DianNao: A small-footprint high-throughput accelerator for ubiqui- tous machine-learning, ” inProceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2014, pp. 269–284
2014
-
[7]
Executing your commands via motion diffusion in latent space,
X. Chen, B. Jiang, W. Liu, Z. Huang, B. Fu, T. Chen, and G. Yu, “Executing your commands via motion diffusion in latent space, ” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 18 000–18 010
2023
-
[8]
Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks,
Y.-H. Chen, T. Krishna, J. S. Emer, and V. Sze, “Eyeriss: A spatial architecture for energy-efficient dataflow for convolutional neural networks, ” inProceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA), 2016, pp. 367–379
2016
-
[9]
DaDianNao: A machine-learning supercomputer,
Y. Chen, T. Luo, S. Liu, S. Zhang, L. He, J. Wang, L. Li, T. Chen, Z. Xu, N. Sun, and O. Temam, “DaDianNao: A machine-learning supercomputer, ” inProceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2014, pp. 609–622
2014
-
[10]
LLMServingSim: A HW/SW co-simulation infrastructure for LLM inference serving at scale,
J. Cho, M. Kim, H. Choi, G. Heo, and J. Park, “LLMServingSim: A HW/SW co-simulation infrastructure for LLM inference serving at scale, ” inProceedings of the IEEE International Symposium on Workload Characterization (IISWC), 2024, pp. 15–29
2024
-
[11]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat GANs on image synthesis, ” 2021
2021
-
[12]
Graphi- cionado: A high-performance and energy-efficient accelerator for graph analytics,
T. J. Ham, L. Wu, N. Sundaram, N. Satish, and M. Martonosi, “Graphi- cionado: A high-performance and energy-efficient accelerator for graph analytics, ” inProceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016, pp. 1–13
2016
-
[13]
EIE: Efficient inference engine on compressed deep neural network,
S. Han, X. Liu, H. Mao, J. Pu, A. Pedram, M. A. Horowitz, and W. J. Dally, “EIE: Efficient inference engine on compressed deep neural network, ” 2016
2016
-
[14]
ExTensor: An accelerator for sparse tensor algebra,
K. Hegde, H. Asghari-Moghaddam, M. Pellauer, N. Crago, A. Jaleel, E. Solomonik, J. Emer, and C. W. Fletcher, “ExTensor: An accelerator for sparse tensor algebra, ” inProceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2019, pp. 319– 333
2019
-
[15]
EXION: Exploiting inter- and intra-iteration output sparsity for diffusion models,
J. Heo, A. Putra, J. Yoon, S. Yune, H. Lee, J.-H. Kim, and J.-Y. Kim, “EXION: Exploiting inter- and intra-iteration output sparsity for diffusion models, ” inProceedings of the IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2025, pp. 324– 337
2025
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models, ” 2020
2020
-
[17]
Video diffusion models,
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models, ” 2022
2022
-
[18]
Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models,
R. Huang, J. Huang, D. Yang, Y. Ren, L. Liu, M. Li, Z. Ye, J. Liu, X. Yin, and Z. Zhao, “Make-an-audio: Text-to-audio generation with prompt-enhanced diffusion models, ”arXiv preprint arXiv:2301.12661, 2023
-
[19]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Pattersonet al., “In-datacenter performance analysis of a tensor processing unit, ” inProceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA), 2017, pp. 1–12
2017
-
[20]
Elucidating the design space of diffusion-based generative models,
T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models, ” 2022
2022
-
[21]
Ramulator: A fast and extensible DRAM simulator,
Y. Kim, W. Yang, and O. Mutlu, “Ramulator: A fast and extensible DRAM simulator, ”IEEE Computer Architecture Letters, vol. 15, no. 1, pp. 45–49, 2016
2016
-
[22]
Cambricon-D: Full-network differential acceleration for diffusion models,
W. Kong, Y. Hao, Q. Guo, Y. Zhao, X. Song, X. Li, M. Zou, Z. Du, R. Zhang, C. Liu, Y. Wen, P. Jin, X. Hu, W. Li, Z. Xu, and T. Chen, “Cambricon-D: Full-network differential acceleration for diffusion models, ” inProceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA), 2024, pp. 903–914
2024
-
[23]
DiffWave: A versatile diffusion model for audio synthesis,
Z. Kong, W. Ping, J. Huang, K. Zhao, and B. Catanzaro, “DiffWave: A versatile diffusion model for audio synthesis, ” 2021
2021
-
[24]
MAERI: Enabling flexible dataflow mapping over DNN accelerators via reconfigurable intercon- nects,
H. Kwon, A. Samajdar, and T. Krishna, “MAERI: Enabling flexible dataflow mapping over DNN accelerators via reconfigurable intercon- nects, ” inProceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2018, pp. 461–475
2018
-
[25]
Q-Diffusion: Quantizing diffusion models,
X. Li, Y. Liu, L. Lian, H. Yang, Z. Dong, D. Kang, S. Zhang, and K. Keutzer, “Q-Diffusion: Quantizing diffusion models, ” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 17 535–17 545
2023
-
[26]
SnapFusion: Text-to-image diffusion model on mobile devices within two seconds,
Y. Li, H. Wang, Q. Jin, J. Hu, P. Chemerys, Y. Fu, Y. Wang, S. Tulyakov, and J. Ren, “SnapFusion: Text-to-image diffusion model on mobile devices within two seconds, ” 2023
2023
-
[27]
Pseudo numerical methods for diffusion models on manifolds,
L. Liu, Y. Ren, Z. Lin, and Z. Zhao, “Pseudo numerical methods for diffusion models on manifolds, ” 2022
2022
-
[28]
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “DPM-Solver++: Fast solver for guided sampling of diffusion probabilistic models, ” arXiv preprint arXiv:2211.01095, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Ramulator 2.0: A modern, modular, and extensible DRAM simulator,
H. Luo, Y. C. Tugrul, F. N. Bostanci, A. Olgun, A. G. Yaglikci, and O. Mutlu, “Ramulator 2.0: A modern, modular, and extensible DRAM simulator, ”IEEE Computer Architecture Letters, vol. 23, no. 1, pp. 112–116, 2024
2024
-
[30]
DeepCache: Accelerating diffusion models for free,
X. Ma, G. Fang, and X. Wang, “DeepCache: Accelerating diffusion models for free, ” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 15 762– 15 772
2024
-
[31]
Improved denoising diffusion probabilistic models,
A. Nichol and P. Dhariwal, “Improved denoising diffusion probabilistic models, ” 2021
2021
-
[32]
OuterSPACE: An outer product based sparse matrix multiplication accelerator,
S. Pal, J. Beaumont, D.-H. Park, A. Amarnath, S. Feng, C. Chakrabarti, H.-S. Kim, D. T. Blaauw, T. N. Mudge, and R. G. Dreslinski, “OuterSPACE: An outer product based sparse matrix multiplication accelerator, ” inProceedings of the IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018
2018
-
[33]
Timeloop: A systematic approach to DNN accelerator evaluation,
A. Parashar, P. Raina, Y. S. Shao, Y.-H. Chen, V. A. Ying, A. Mukkara, R. Venkatesan, B. Khailany, S. W. Keckler, and J. Emer, “Timeloop: A systematic approach to DNN accelerator evaluation, ” inProceedings of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2019, pp. 304–315
2019
-
[34]
SCNN: An accelerator for compressed-sparse convolutional neural networks,
A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. Venkatesan, B. Khailany, J. Emer, S. W. Keckler, and W. J. Dally, “SCNN: An accelerator for compressed-sparse convolutional neural networks, ” in Proceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA), 2017, pp. 27–40
2017
-
[35]
Tale of two Cs: Computation vs. communication scaling for future trans- formers on future hardware,
S. Pati, S. Aga, M. Islam, N. Jayasena, and M. D. Sinclair, “Tale of two Cs: Computation vs. communication scaling for future trans- formers on future hardware, ” inProceedings of the IEEE International Symposium on Workload Characterization (IISWC), 2023
2023
-
[36]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers, ” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4195–4205
2023
-
[37]
SIGMA: A sparse and irregular GEMM accelerator with flexible interconnects for DNN training,
E. Qin, A. Samajdar, H. Kwon, V. Nadella, S. Srinivasan, D. Das, B. Kaul, and T. Krishna, “SIGMA: A sparse and irregular GEMM accelerator with flexible interconnects for DNN training, ” inPro- ceedings of the IEEE International Symposium on High Performance Computer Architecture (HPCA), 2020, pp. 58–70
2020
-
[38]
Hierar- chical text-conditional image generation with CLIP latents,
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierar- chical text-conditional image generation with CLIP latents, ” 2022. 11
2022
-
[39]
MLPerf inference benchmark,
V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu, B. Andersonet al., “MLPerf inference benchmark, ” inProceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA), 2020, pp. 446–459
2020
-
[40]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models, ” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10 684–10 695
2022
-
[41]
DRAMSim2: A cycle accurate memory system simulator,
P. Rosenfeld, E. Cooper-Balis, and B. Jacob, “DRAMSim2: A cycle accurate memory system simulator, ”IEEE Computer Architecture Letters, vol. 10, no. 1, pp. 16–19, 2011
2011
-
[42]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. Denton, S. K. S. Ghasemipour, B. K. Ayan, S. S. Mahdavi, R. G. Lopes, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi, “Photorealistic text-to-image diffusion models with deep language understanding, ” 2022
2022
-
[43]
Progressive distillation for fast sampling of diffusion models,
T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models, ” 2022
2022
-
[44]
Post-training quantization on diffusion models,
Y. Shang, Z. Yuan, B. Xie, B. Wu, and Y. Yan, “Post-training quantization on diffusion models, ” 2023
2023
-
[45]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models, ” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[46]
Score-based generative modeling through stochastic differential equations,
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations, ” 2021
2021
-
[47]
MatRaptor: A sparse-sparse matrix multiplication accelerator based on row- wise product,
N. Srivastava, H. Jin, J. Liu, D. Albonesi, and Z. Zhang, “MatRaptor: A sparse-sparse matrix multiplication accelerator based on row- wise product, ” inProceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2020, pp. 766–780
2020
-
[48]
Human motion diffusion model,
G. Tevet, S. Raab, B. Gordon, Y. Shafir, D. Cohen-Or, and A. H. Bermano, “Human motion diffusion model, ” inInternational Confer- ence on Learning Representations (ICLR), 2023
2023
-
[49]
EDGE: Editable dance generation from music,
J. Tseng, R. Castellon, and K. Liu, “EDGE: Editable dance generation from music, ” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 448–458
2023
-
[50]
Trapezoid: A versatile accelerator for dense and sparse matrix multiplications,
Y. Yang, J. Emer, and D. Sanchez, “Trapezoid: A versatile accelerator for dense and sparse matrix multiplications, ” inProceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA), 2024, pp. 931–945
2024
-
[51]
Gamma: Leveraging gustavson’s algorithm to accelerate sparse matrix multiplication,
G. Zhang, N. Attaluri, J. S. Emer, and D. Sanchez, “Gamma: Leveraging gustavson’s algorithm to accelerate sparse matrix multiplication, ” in Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2021, pp. 687–701
2021
-
[52]
Cambricon-X: An accelerator for sparse neural networks,
S. Zhang, Z. Du, L. Zhang, H. Lan, S. Liu, L. Li, Q. Guo, T. Chen, and Y. Chen, “Cambricon-X: An accelerator for sparse neural networks, ” inProceedings of the Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2016, pp. 1–12
2016
-
[53]
SpArch: Efficient architecture for sparse matrix multiplication,
Z. Zhang, H. Wang, S. Han, and W. J. Dally, “SpArch: Efficient architecture for sparse matrix multiplication, ” inProceedings of the IEEE International Symposium on High Performance Computer Architecture (HPCA), 2020, pp. 261–274. 12
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.