Revisiting Parameter-Based Knowledge Editing in Large Language Models: Theoretical Limits and Empirical Evidence
Pith reviewed 2026-06-28 19:01 UTC · model grok-4.3
The pith
Localized parameter edits in LLMs propagate to cause global reasoning collapse, while a simple retrieval baseline consistently outperforms them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Localized parameter edits propagate along fragile directions in representation space, inducing global interference that collapses reasoning performance; this effect is observed consistently across methods and settings, whereas retrieval-based access avoids the damage entirely.
What carries the argument
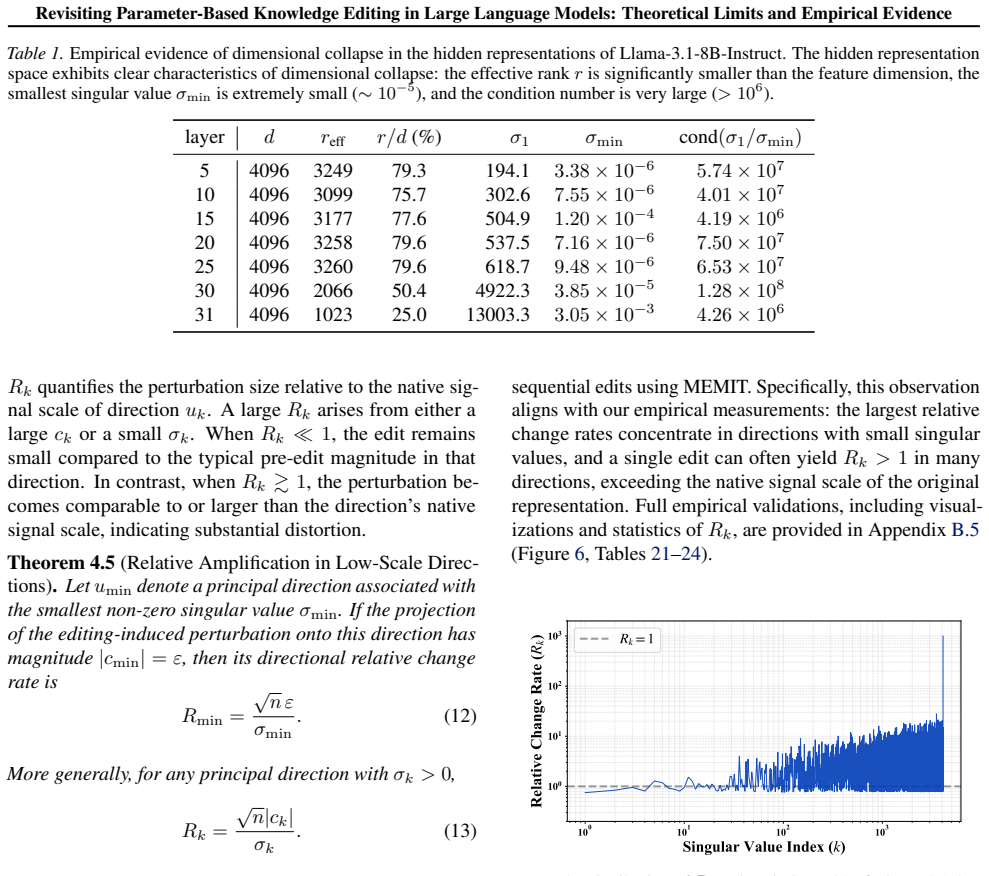
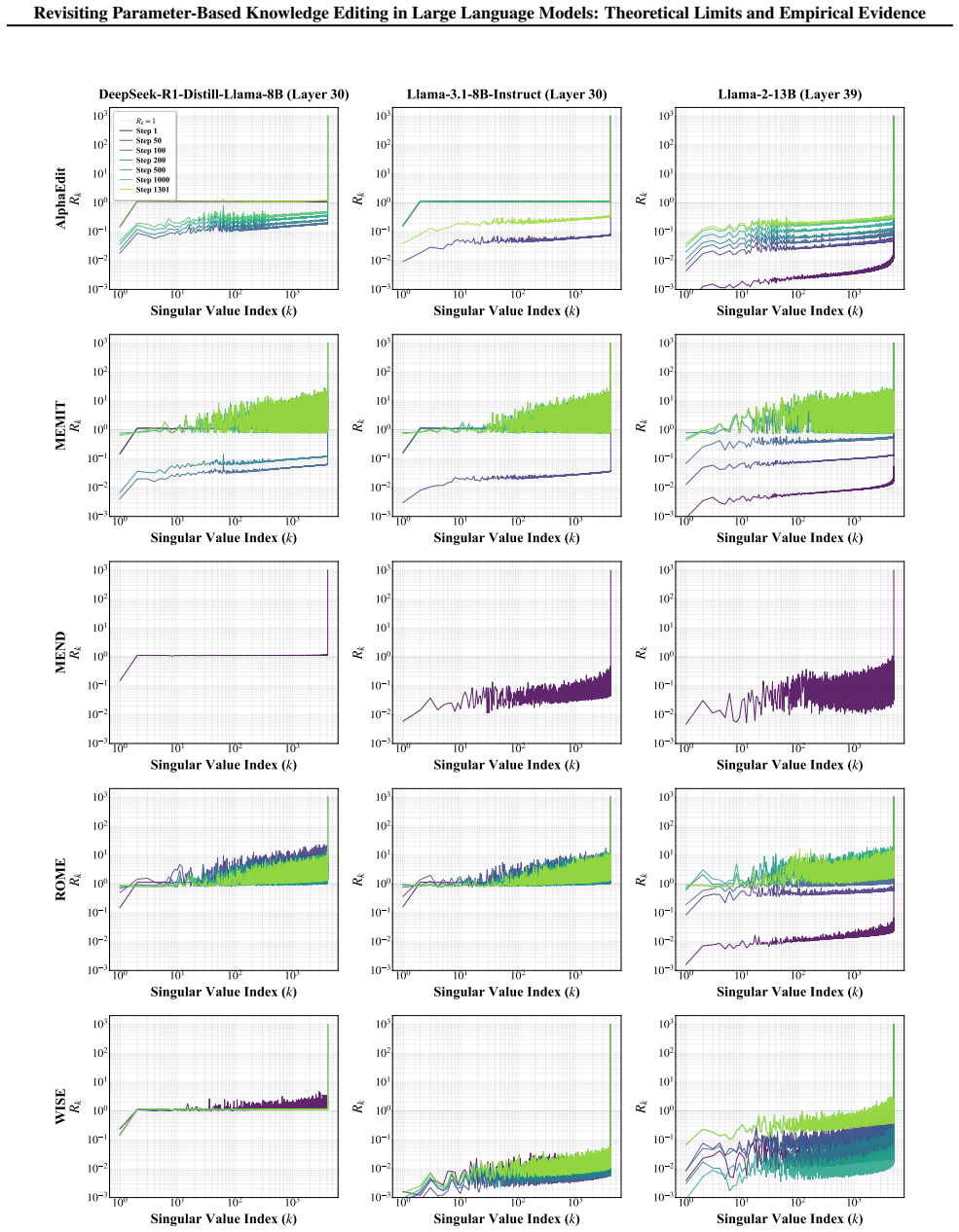
Dimensional Collapse Hypothesis, which models how localized weight changes spread along low-dimensional fragile directions to produce global capability loss.
If this is right
- Any method that changes weights directly will face the same interference risk once edit count or complexity rises.
- Retrieval mechanisms that leave parameters untouched can serve as a practical upper bound for capability preservation.
- Evaluation protocols must include broad capability checks beyond the edited facts themselves.
- Research priority should shift toward hybrid or non-parametric approaches that avoid representation-space collapse.
Where Pith is reading between the lines
- If the collapse mechanism is general, then scaling model size alone will not remove the interference problem without changes to editing strategy.
- Retrieval baselines could be extended with lightweight adapters that never touch the original weights.
- The same fragility directions may explain why fine-tuning on narrow tasks sometimes erodes broader abilities.
Load-bearing premise
The dimensional collapse hypothesis accurately describes the mechanism by which local edits create global interference.
What would settle it
An experiment in which multiple parameter edits are applied and the model shows no measurable drop in reasoning accuracy or coherence on held-out tasks while still incorporating the new facts.
Figures


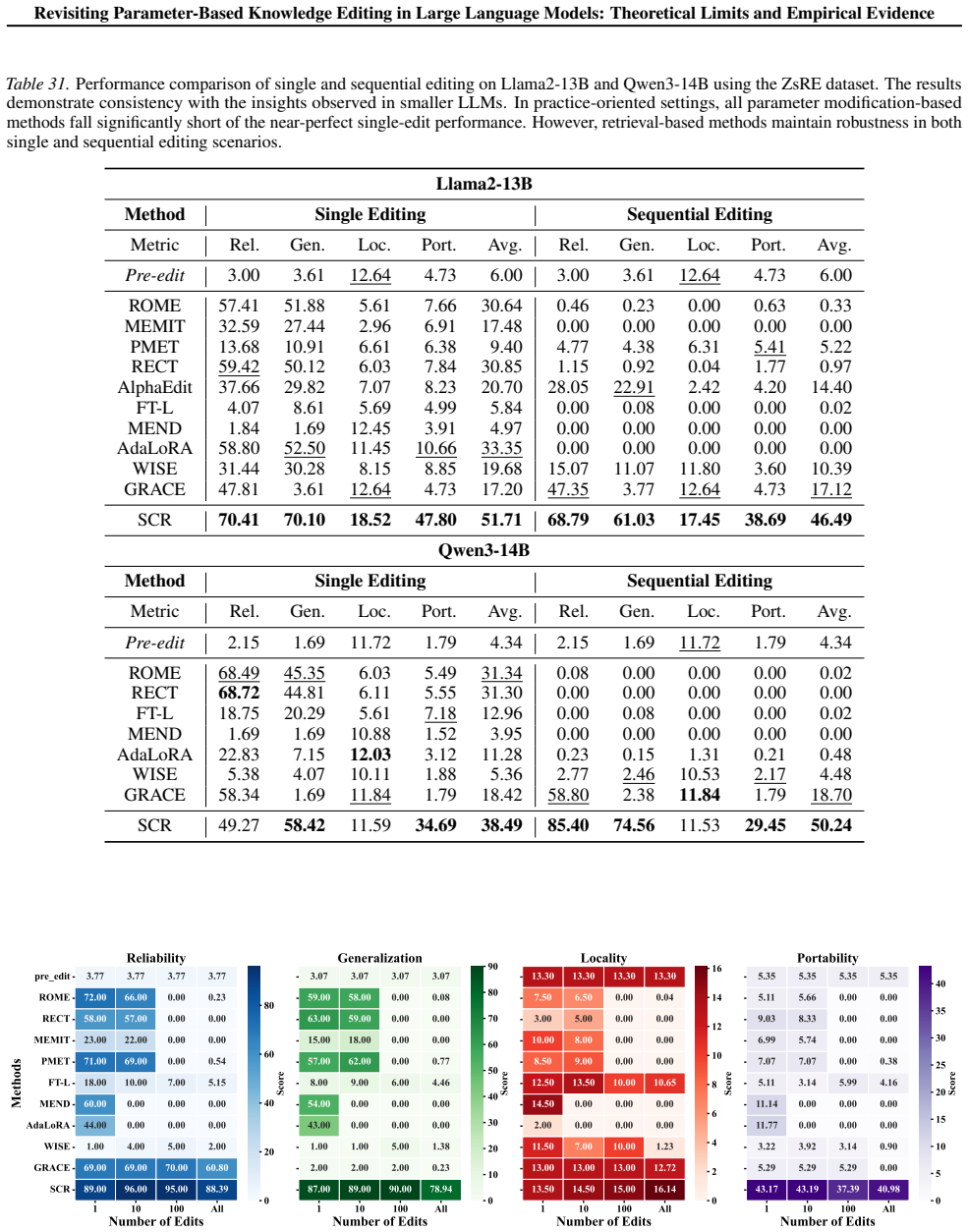
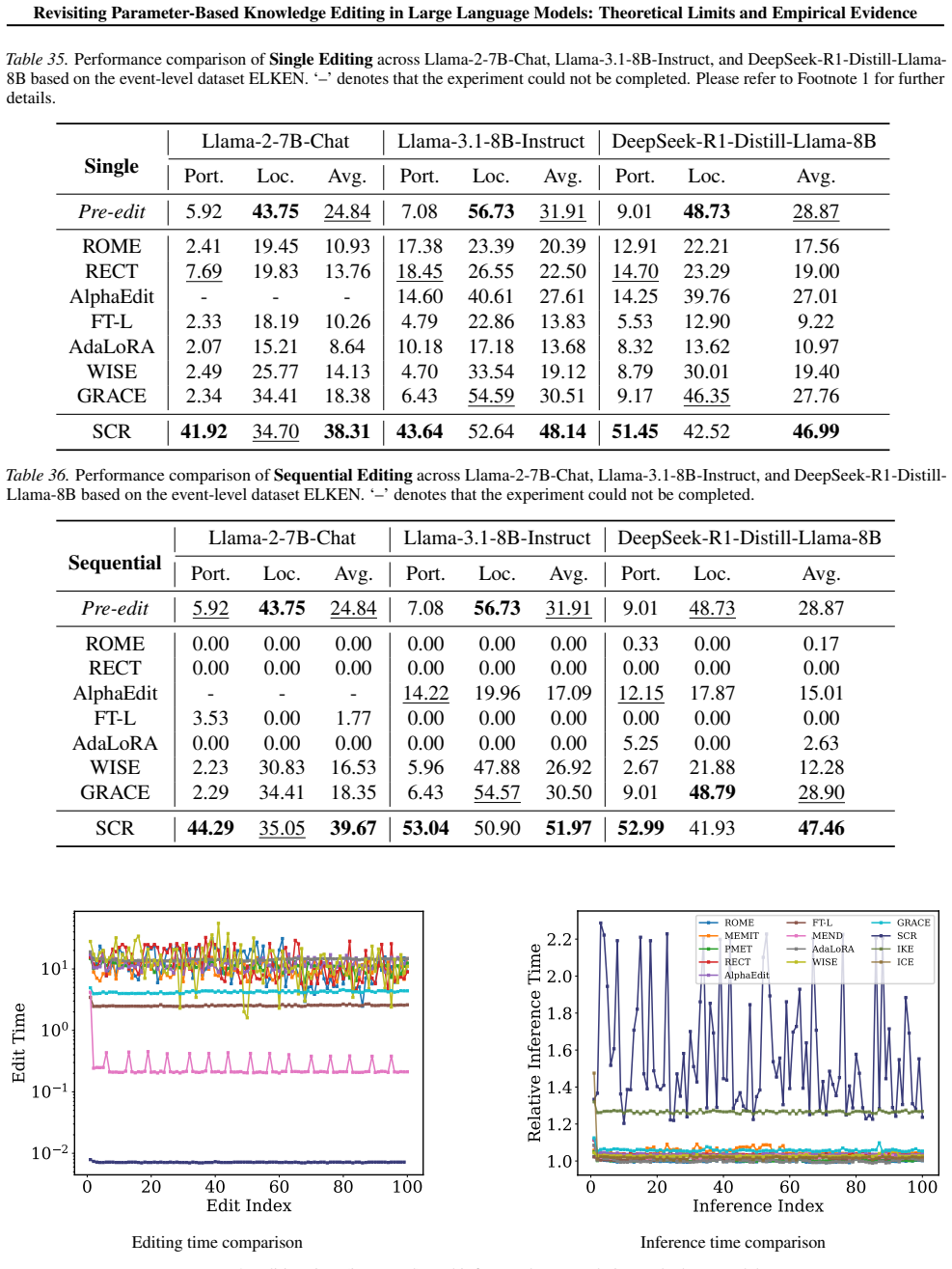
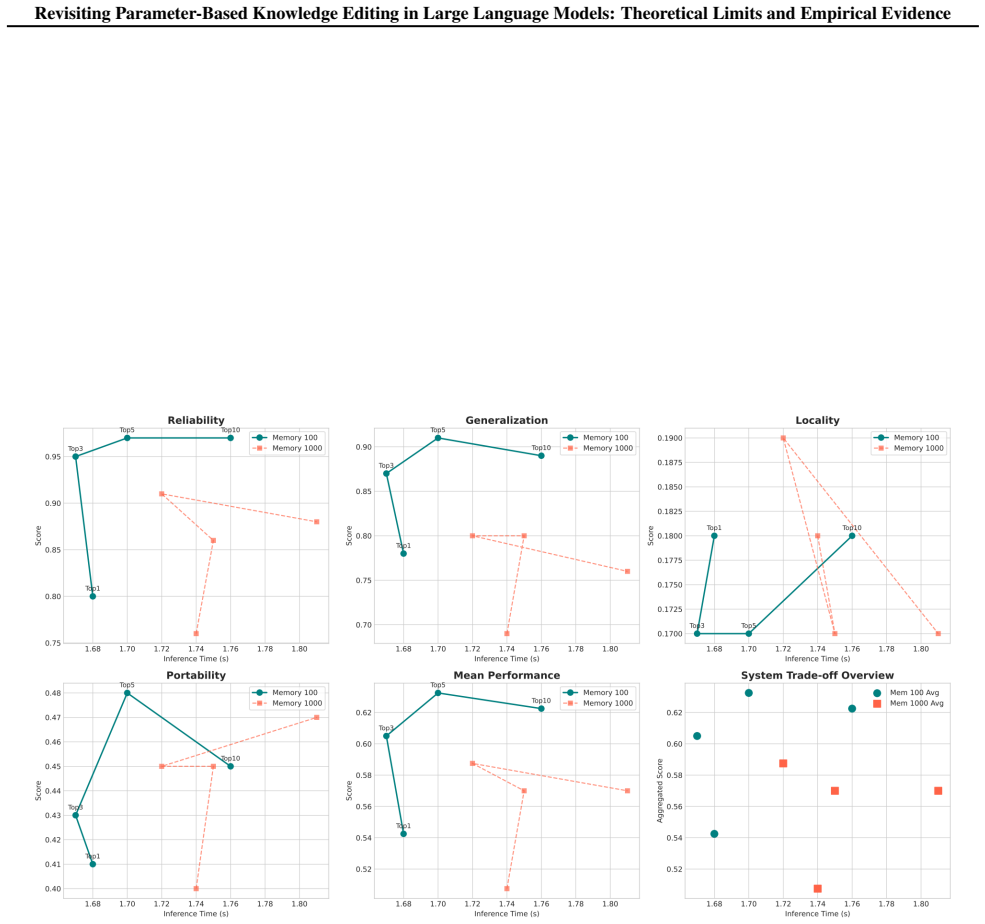
read the original abstract
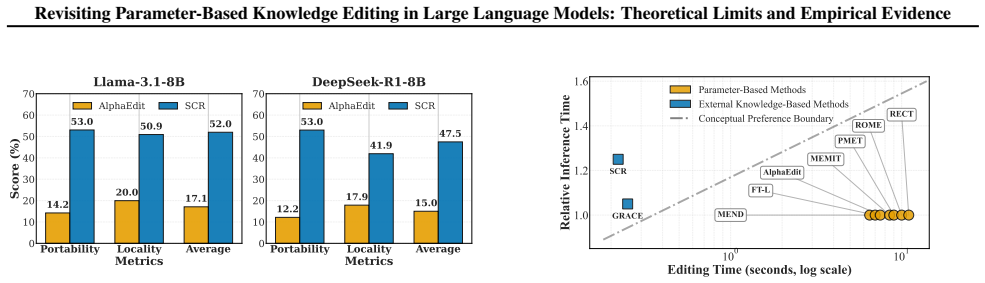
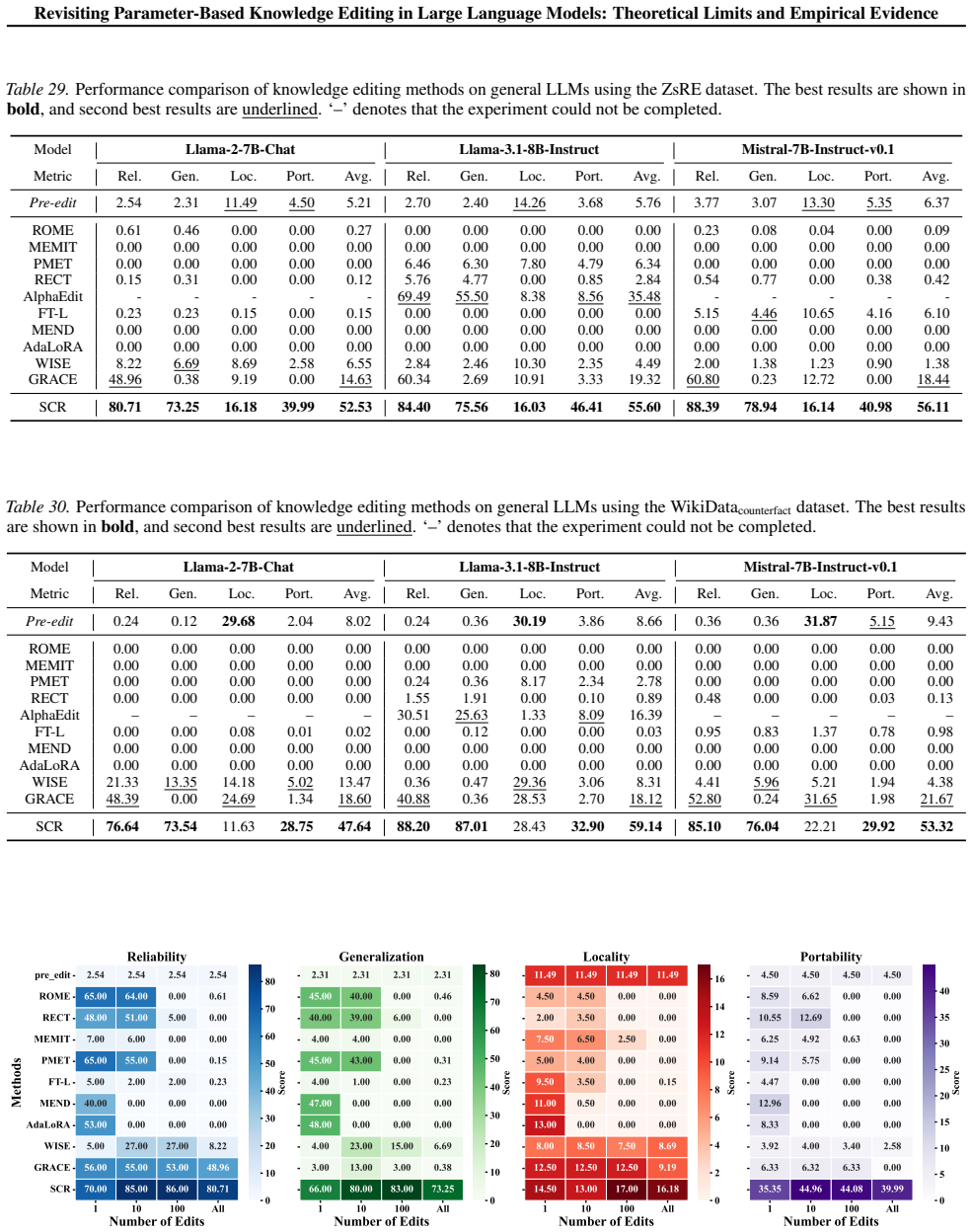
Parameter-based knowledge editing updates the internal knowledge of large language models (LLMs) via localized weight modifications and has attracted significant attention. However, most existing methods overlook fundamental theoretical limitations and are rarely evaluated under realistic, practice-oriented settings. In this paper, we first present a theoretical analysis based on the dimensional Collapse Hypothesis, explaining how localized parameter edits can propagate along fragile directions in the representation space, inducing global interference and ultimately causing reasoning collapse. Building on this insight, we conduct a comprehensive empirical evaluation by systematically varying knowledge complexity, number of edits, evaluation dimensions, and baseline methods. Our results show that parameter-based editing methods consistently damage core LLM capabilities. In contrast, a simple retrieval-based baseline achieves consistently stronger performance than all parameter-editing methods across all evaluated conditions. These findings highlight that preserving the fundamental capabilities of LLMs after knowledge editing should be a central concern for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that parameter-based knowledge editing in LLMs is subject to fundamental theoretical limits, which it explains via the Dimensional Collapse Hypothesis: localized weight updates propagate along fragile directions in representation space, causing global interference and reasoning collapse. It supports this with a comprehensive empirical evaluation that varies knowledge complexity, edit count, evaluation dimensions, and baselines, finding that all parameter-editing methods degrade core LLM capabilities while a simple retrieval-based baseline consistently outperforms them.
Significance. If the empirical findings hold under scrutiny, the work would usefully shift attention in the knowledge-editing literature toward capability preservation and retrieval alternatives. The systematic sweep across multiple axes is a clear strength and provides falsifiable, practice-oriented evidence. However, the explanatory mechanism (Dimensional Collapse Hypothesis) is presented without direct validation, reducing the paper's ability to move beyond post-hoc interpretation.
major comments (2)
- [theoretical analysis] Theoretical analysis section (as described in the abstract): the Dimensional Collapse Hypothesis is invoked to explain how localized edits induce global interference, yet the manuscript reports no direct measurements (effective rank, singular-value spectra, or directional fragility metrics) of representation space before versus after edits. Without such tests the hypothesis remains an unverified interpretive lens rather than a validated causal account, leaving open alternative explanations such as generic optimization instability.
- [empirical evaluation] Empirical evaluation (abstract and results): while the central claim that parameter edits damage capabilities rests on the sweep, the abstract provides no quantitative results, error bars, dataset sizes, or model scales. If these details are absent or insufficiently reported in the full text, the strength of the cross-condition superiority claim cannot be assessed.
minor comments (1)
- Clarify whether the retrieval baseline is purely non-parametric or involves any learned components, as this affects the interpretation of 'parameter-based' versus 'retrieval-based' distinctions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [theoretical analysis] Theoretical analysis section (as described in the abstract): the Dimensional Collapse Hypothesis is invoked to explain how localized edits induce global interference, yet the manuscript reports no direct measurements (effective rank, singular-value spectra, or directional fragility metrics) of representation space before versus after edits. Without such tests the hypothesis remains an unverified interpretive lens rather than a validated causal account, leaving open alternative explanations such as generic optimization instability.
Authors: The Dimensional Collapse Hypothesis is derived from a theoretical analysis of how localized weight updates interact with the geometry of representation spaces. The manuscript supports it via the observed pattern of global interference across diverse edit conditions. We agree that direct measurements would strengthen the causal claim over post-hoc interpretation. In revision we will add experiments reporting effective rank, singular-value spectra, and directional fragility metrics before versus after edits. revision: yes
-
Referee: [empirical evaluation] Empirical evaluation (abstract and results): while the central claim that parameter edits damage capabilities rests on the sweep, the abstract provides no quantitative results, error bars, dataset sizes, or model scales. If these details are absent or insufficiently reported in the full text, the strength of the cross-condition superiority claim cannot be assessed.
Authors: The full manuscript reports all quantitative results (performance deltas with standard deviations), dataset sizes, model scales, and evaluation protocols in the results section and appendices. To make the strength of the claims immediately visible, we will revise the abstract to include representative quantitative outcomes and error-bar information. revision: partial
Circularity Check
No significant circularity; empirical claims rest on new measurements independent of the invoked hypothesis
full rationale
The paper's central results are empirical comparisons of parameter-editing methods versus a retrieval baseline across varied conditions of knowledge complexity, edit count, and evaluation dimensions. These outcomes are generated from direct experiments and do not reduce to any fitted parameter, self-defined quantity, or self-citation chain. The Dimensional Collapse Hypothesis is cited only as the basis for a theoretical explanation of observed interference; it is not used to derive or force any reported performance numbers, nor does the paper present predictions that are then verified by construction from the same hypothesis. No self-definitional, fitted-input, or uniqueness-imported steps appear in the provided derivation chain. The hypothesis functions as post-hoc interpretive framing rather than a load-bearing premise that collapses the empirical findings back into the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dimensional Collapse Hypothesis
Reference graph
Works this paper leans on
-
[1]
A review on language models as knowledge bases
AlKhamissi, B., Li, M., Celikyilmaz, A., Diab, M., and Ghazvininejad, M. A review on language models as knowledge bases. arXiv preprint arXiv:2204.06031, 2022
- [2]
-
[3]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Asai, A., Wu, Z., Wang, Y., Sil, A., and Hajishirzi, H. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In The Twelfth International Conference on Learning Representations
-
[4]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 0 1877--1901, 2020
1901
-
[5]
Lifelong knowledge editing for llms with retrieval-augmented continuous prompt learning
Chen, Q., Zhang, T., He, X., Li, D., Wang, C., Huang, L., et al. Lifelong knowledge editing for llms with retrieval-augmented continuous prompt learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 13565--13580, 2024
2024
-
[6]
Uniedit: A unified knowledge editing benchmark for large language models
Chen, Q., Wang, D., Zhang, T., Yan, Z., You, C., Wang, C., and He, X. Uniedit: A unified knowledge editing benchmark for large language models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. URL https://openreview.net/forum?id=eESbQ5lWiP
2025
-
[7]
Towards understanding the mixture-of-experts layer in deep learning
Chen, Z., Deng, Y., Wu, Y., Gu, Q., and Li, Y. Towards understanding the mixture-of-experts layer in deep learning. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pp.\ 23049--23062, 2022
2022
-
[8]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
Evaluating the ripple effects of knowledge editing in language models
Cohen, R., Biran, E., Yoran, O., Globerson, A., and Geva, M. Evaluating the ripple effects of knowledge editing in language models. Transactions of the Association for Computational Linguistics, 12: 0 283--298, 2024
2024
-
[10]
Knowledge neurons in pretrained transformers
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., and Wei, F. Knowledge neurons in pretrained transformers. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8493--8502, 2022
2022
-
[11]
Eamet: Robust massive model editing via embedding alignment optimization
Dai, Y., Ji, Z., Li, Z., and Wang, S. Eamet: Robust massive model editing via embedding alignment optimization. arXiv preprint arXiv:2505.11876, 2025
-
[12]
Larimar: Large language models with episodic memory control
Das, P., Chaudhury, S., Nelson, E., Melnyk, I., Swaminathan, S., Dai, S., Lozano, A., Kollias, G., Chenthamarakshan, V., Navratil, J., et al. Larimar: Large language models with episodic memory control. In Forty-first International Conference on Machine Learning
-
[13]
Editing factual knowledge in language models
De Cao, N., Aziz, W., and Titov, I. Editing factual knowledge in language models. In EMNLP 2021-2021 Conference on Empirical Methods in Natural Language Processing, Proceedings, pp.\ 6491--6506, 2021
2021
-
[14]
Parameter-efficient fine-tuning of large-scale pre-trained language models
Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y., Hu, S., Chen, Y., Chan, C.-M., Chen, W., et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5 0 (3): 0 220--235, 2023
2023
-
[15]
Dohmatob, E., Feng, Y., and Kempe, J. Strong model collapse. arXiv preprint arXiv:2410.04840, 2024
-
[16]
Calibrating factual knowledge in pretrained language models
Dong, Q., Dai, D., Song, Y., Xu, J., Sui, Z., and Li, L. Calibrating factual knowledge in pretrained language models. In Findings of the Association for Computational Linguistics: EMNLP 2022, pp.\ 5937--5947, 2022
2022
-
[17]
A survey on in-context learning
Dong, Q., Li, L., Dai, D., Zheng, C., Ma, J., Li, R., Xia, H., Xu, J., Wu, Z., Chang, B., et al. A survey on in-context learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 1107--1128, 2024
2024
-
[18]
Alphaedit: Null-space constrained model editing for language models
Fang, J., Jiang, H., Wang, K., Ma, Y., Shi, J., Wang, X., He, X., and Chua, T.-S. Alphaedit: Null-space constrained model editing for language models. In The Thirteenth International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=HvSytvg3Jh
2025
-
[19]
Cknowedit: A new chinese knowledge editing dataset for linguistics, facts, and logic error correction in llms
Fang, J., Lu, T., Yao, Y., Jiang, Z., Xu, X., Chen, H., and Zhang, N. Cknowedit: A new chinese knowledge editing dataset for linguistics, facts, and logic error correction in llms. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8789--8807, 2025 b
2025
-
[20]
Dissecting recall of factual associations in auto-regressive language models
Geva, M., Bastings, J., Filippova, K., and Globerson, A. Dissecting recall of factual associations in auto-regressive language models. In The 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[21]
Transformer feed-forward layers are key-value memories
Geva, M., Schuster, R., Berant, J., and Levy, O. Transformer feed-forward layers are key-value memories. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp.\ 5484--5495, 2021
2021
-
[22]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Model editing harms general abilities of large language models: Regularization to the rescue
Gu, J.-C., Xu, H.-X., Ma, J.-Y., Lu, P., Ling, Z.-H., Chang, K.-W., and Peng, N. Model editing harms general abilities of large language models: Regularization to the rescue. In Al-Onaizan, Y., Bansal, M., and Chen, Y.-N. (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 16801--16819, Miami, Florida, USA,...
-
[24]
Model editing harms general abilities of large language models: Regularization to the rescue
Gu, J.-C., Xu, H.-X., Ma, J.-Y., Lu, P., Ling, Z.-H., Chang, K.-W., and Peng, N. Model editing harms general abilities of large language models: Regularization to the rescue. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 16801--16819. Association for Computational Linguistics, 2024 b
2024
-
[25]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Model editing at scale leads to gradual and catastrophic forgetting
Gupta, A., Rao, A., and Anumanchipalli, G. Model editing at scale leads to gradual and catastrophic forgetting. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 15202--15232, Bangkok, Thailand, August 2024 a . Association for Computational Linguistics. doi:10.18653/v1/2024.findin...
-
[27]
Model editing at scale leads to gradual and catastrophic forgetting
Gupta, A., Rao, A., and Anumanchipalli, G. Model editing at scale leads to gradual and catastrophic forgetting. In Findings of the Association for Computational Linguistics ACL 2024, pp.\ 15202--15232, 2024 b
2024
-
[28]
flex tape can’t fix that
Halevy, K., Sotnikova, A., Alkhamissi, B., Montariol, S., and Bosselut, A. “flex tape can’t fix that”: Bias and misinformation in edited language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 8690--8707, 2024
2024
-
[29]
Aging with grace: Lifelong model editing with discrete key-value adaptors
Hartvigsen, T., Sankaranarayanan, S., Palangi, H., Kim, Y., and Ghassemi, M. Aging with grace: Lifelong model editing with discrete key-value adaptors. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[30]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems
He, C., Luo, R., Bai, Y., Hu, S., Thai, Z., Shen, J., Hu, J., Han, X., Huang, Y., Zhang, Y., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 3828--3850, 2024
2024
-
[31]
Knowledge updating? no more model editing! just selective contextual reasoning
He, G., Song, X., and Sun, A. Knowledge updating? no more model editing! just selective contextual reasoning. arXiv preprint arXiv:2503.05212, 2025
-
[32]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Hernandez, E., Li, B. Z., and Andreas, J. Inspecting and editing knowledge representations in language models. arXiv preprint arXiv:2304.00740, 2023
-
[34]
K.-M., Lin, T.-H., Liao, C.-W., Fang, H.-C., Huang, C.-W., and Chen, Y.-N
Hsueh, C.-H., Huang, P. K.-M., Lin, T.-H., Liao, C.-W., Fang, H.-C., Huang, C.-W., and Chen, Y.-N. Editing the mind of giants: An in-depth exploration of pitfalls of knowledge editing in large language models. arXiv preprint arXiv:2406.01436, 2024
-
[35]
Wilke: Wise-layer knowledge editor for lifelong knowledge editing
Hu, C., Cao, P., Chen, Y., Liu, K., and Zhao, J. Wilke: Wise-layer knowledge editor for lifelong knowledge editing. In Findings of the Association for Computational Linguistics ACL 2024, pp.\ 3476--3503, 2024
2024
-
[36]
J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations
-
[37]
Transformer-patcher: One mistake worth one neuron
Huang, Z., Shen, Y., Zhang, X., Zhou, J., Rong, W., and Xiong, Z. Transformer-patcher: One mistake worth one neuron. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[38]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Unsupervised dense information retrieval with contrastive learning
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., and Grave, E. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research
-
[40]
J., Madotto, A., and Fung, P
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., and Fung, P. Survey of hallucination in natural language generation. ACM Computing Surveys, 55 0 (12): 0 1--38, 2023
2023
-
[41]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Anyedit: Edit any knowledge encoded in language models
Jiang, H., Fang, J., Zhang, N., Wan, M., Ma, G., Wang, X., He, X., and Chua, T.-S. Anyedit: Edit any knowledge encoded in language models. In International Conference on Machine Learning, pp.\ 27510--27533. PMLR, 2025
2025
-
[43]
Learning to edit: Aligning llms with knowledge editing
Jiang, Y., Wang, Y., Wu, C., Zhong, W., Zeng, X., Gao, J., Li, L., Jiang, X., Shang, L., Tang, R., et al. Learning to edit: Aligning llms with knowledge editing. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 4689--4705, 2024
2024
-
[44]
F., Araki, J., and Neubig, G
Jiang, Z., Xu, F. F., Araki, J., and Neubig, G. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8: 0 423--438, 2020
2020
-
[45]
Evaluating open-domain question answering in the era of large language models
Kamalloo, E., Dziri, N., Clarke, C., and Rafiei, D. Evaluating open-domain question answering in the era of large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 5591--5606, 2023
2023
-
[46]
Reasoning abilities of large language models: In-depth analysis on the abstraction and reasoning corpus
Lee, S., Sim, W., Shin, D., Seo, W., Park, J., Lee, S., Hwang, S., Kim, S., and Kim, S. Reasoning abilities of large language models: In-depth analysis on the abstraction and reasoning corpus. ACM Transactions on Intelligent Systems and Technology
-
[47]
Zero-shot relation extraction via reading comprehension
Levy, O., Seo, M., Choi, E., and Zettlemoyer, L. Zero-shot relation extraction via reading comprehension. In 21st Conference on Computational Natural Language Learning, CoNLL 2017, pp.\ 333--342. Association for Computational Linguistics (ACL), 2017
2017
-
[48]
u ttler, H., Lewis, M., Yih, W.-t., Rockt \
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K \"u ttler, H., Lewis, M., Yih, W.-t., Rockt \"a schel, T., et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33: 0 9459--9474, 2020
2020
-
[49]
Solving quantitative reasoning problems with language models
Lewkowycz, A., Andreassen, A., Dohan, D., Dyer, E., Michalewski, H., Ramasesh, V., Slone, A., Anil, C., Schlag, I., Gutman-Solo, T., et al. Solving quantitative reasoning problems with language models. Advances in Neural Information Processing Systems, 35: 0 3843--3857, 2022
2022
-
[50]
Q., Shen, Z., et al
Li, J., Beeching, E., Tunstall, L., Lipkin, B., Soletskyi, R., Huang, S., Rasul, K., Yu, L., Jiang, A. Q., Shen, Z., et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. Hugging Face repository, 13: 0 9, 2024 a
2024
-
[51]
and Chu, X
Li, Q. and Chu, X. Adaedit: Advancing continuous knowledge editing for large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 4127--4149, 2025
2025
-
[52]
Consecutive model editing with batch alongside hook layers
Li, S., Deng, Y., Cai, D., Lu, H., Chen, L., and Lam, W. Consecutive model editing with batch alongside hook layers. arXiv preprint arXiv:2403.05330, 2024 b
-
[53]
Pmet: Precise model editing in a transformer
Li, X., Li, S., Song, S., Yang, J., Ma, J., and Yu, J. Pmet: Precise model editing in a transformer. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 18564--18572, 2024 c
2024
-
[54]
E., Papailiopoulos, D., and Oymak, S
Li, Y., Ildiz, M. E., Papailiopoulos, D., and Oymak, S. Transformers as algorithms: Generalization and stability in in-context learning. In International Conference on Machine Learning, pp.\ 19565--19594. PMLR, 2023
2023
-
[55]
Let's verify step by step
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let's verify step by step. In International Conference on Learning Representations, volume 2024, pp.\ 39578--39601, 2024
2024
-
[56]
Edit less, achieve more: Dynamic sparse neuron masking for lifelong knowledge editing in llms
Liu, J., Sun, J., Shen, S., Yang, C., and Wang, S. Edit less, achieve more: Dynamic sparse neuron masking for lifelong knowledge editing in llms. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[57]
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing
Liu, P., Yuan, W., Fu, J., Jiang, Z., Hayashi, H., and Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55 0 (9): 0 1--35, 2023
2023
-
[58]
Liu, T., Li, R., Qi, Y., Liu, H., Tang, X., Zheng, T., Yin, Q., Cheng, M. X., Huan, J., Wang, H., et al. Unlocking efficient, scalable, and continual knowledge editing with basis-level representation fine-tuning. arXiv preprint arXiv:2503.00306, 2025 a
-
[59]
Liu, W., Xu, H., Liu, B., Deng, Z., Wang, H., Wang, J., Li, R., Teh, Y. W., and Lee, W. S. Is model editing built on sand? revealing its illusory success and fragile foundation, 2025 b . URL https://arxiv.org/abs/2510.00625
-
[60]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Luo, Y., Yang, Z., Meng, F., Li, Y., Zhou, J., and Zhang, Y. An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Interpreting key mechanisms of factual recall in transformer-based language models
Lv, A., Zhang, K., Chen, Y., Wang, Y., Liu, L., Wen, J.-R., Xie, J., and Yan, R. Interpreting key mechanisms of factual recall in transformer-based language models. arXiv preprint arXiv:2403.19521, 2024 a
-
[62]
Full parameter fine-tuning for large language models with limited resources
Lv, K., Yang, Y., Liu, T., Guo, Q., and Qiu, X. Full parameter fine-tuning for large language models with limited resources. In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8187--8198, Bangkok, Thailand, August 2024 b . Association for...
-
[63]
K-edit: Language model editing with contextual knowledge awareness
Markowitz, E., Ramakrishna, A., Mehrabi, N., Peris, C., Gupta, R., Chang, K.-W., and Galstyan, A. K-edit: Language model editing with contextual knowledge awareness. arXiv preprint arXiv:2502.10626, 2025
-
[64]
arXiv preprint arXiv:2309.13638 (2023)
McCoy, R. T., Yao, S., Friedman, D., Hardy, M., and Griffiths, T. L. Embers of autoregression: Understanding large language models through the problem they are trained to solve. arXiv preprint arXiv:2309.13638, 2023
-
[65]
S., Andonian, A
Meng, K., Sharma, A. S., Andonian, A. J., Belinkov, Y., and Bau, D. Mass-editing memory in a transformer. In The Eleventh International Conference on Learning Representations
-
[66]
Locating and editing factual associations in gpt
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in gpt. Advances in Neural Information Processing Systems, 35: 0 17359--17372, 2022 a
2022
-
[67]
Locating and editing factual associations in gpt
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in gpt. In Proceedings of the 36th International Conference on Neural Information Processing Systems, pp.\ 17359--17372, 2022 b
2022
-
[68]
Llama 3 model card
Meta AI . Llama 3 model card. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md, 2024. Accessed: 2025-04-21
2024
- [69]
-
[70]
D., and Finn, C
Mitchell, E., Lin, C., Bosselut, A., Manning, C. D., and Finn, C. Memory-based model editing at scale. In International Conference on Machine Learning, pp.\ 15817--15831. PMLR, 2022
2022
-
[71]
M., Alghisi, S., and Riccardi, G
Mousavi, S. M., Alghisi, S., and Riccardi, G. Is your llm outdated? benchmarking llms & alignment algorithms for time-sensitive knowledge. arXiv preprint arXiv:2404.08700, 2024
-
[72]
Bmike-53: Investigating cross-lingual knowledge editing with in-context learning
Nie, E., Shao, B., Wang, M., Ding, Z., Schmid, H., and Sch \"u tze, H. Bmike-53: Investigating cross-lingual knowledge editing with in-context learning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 16357--16374, 2025
2025
-
[73]
Nishi, K., Ramesh, R., Okawa, M., Khona, M., Tanaka, H., and Lubana, E. S. Representation shattering in transformers: A synthetic study with knowledge editing. In Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., and Zhu, J. (eds.), Proceedings of the 42nd International Conference on Machine Learning, volume 267...
2025
-
[74]
OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[75]
Training language models to follow instructions with human feedback
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 0 27730--27744, 2022
2022
-
[76]
Context-robust knowledge editing for language models
Park, H., Choi, G., Kim, M., and Jo, Y. Context-robust knowledge editing for language models. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 10360--10385, 2025
2025
-
[77]
Peng, H., Wang, X., Li, C., Zeng, K., Duo, J., Cao, Y., Hou, L., and Li, J. Event-level knowledge editing. arXiv preprint arXiv:2402.13093, 2024
-
[78]
Petroni, F., Rockt \"a schel, T., Riedel, S., Lewis, P., Bakhtin, A., Wu, Y., and Miller, A. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 2463--2473, 2019
2019
-
[79]
and Elhadad, M
Pinter, Y. and Elhadad, M. Emptying the ocean with a spoon: Should we edit models? In Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 15164--15172, 2023
2023
-
[80]
S., Zhu, C., Li, D., Yu, F., Zaheer, M., Kumar, S., and Bhojanapalli, S
Rawat, A. S., Zhu, C., Li, D., Yu, F., Zaheer, M., Kumar, S., and Bhojanapalli, S. Modifying memories in transformer models. In International Conference on Machine Learning (ICML), volume 2020, 2021
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.