Pause and Think: A Dataset and Benchmark for Video-Grounded Assistive Action Suggestion
Pith reviewed 2026-06-28 19:09 UTC · model grok-4.3
The pith
Targeted reasoning supervision on a new video dataset lets compact 4B models match much larger VLMs on assistive action suggestion while generalizing out of distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
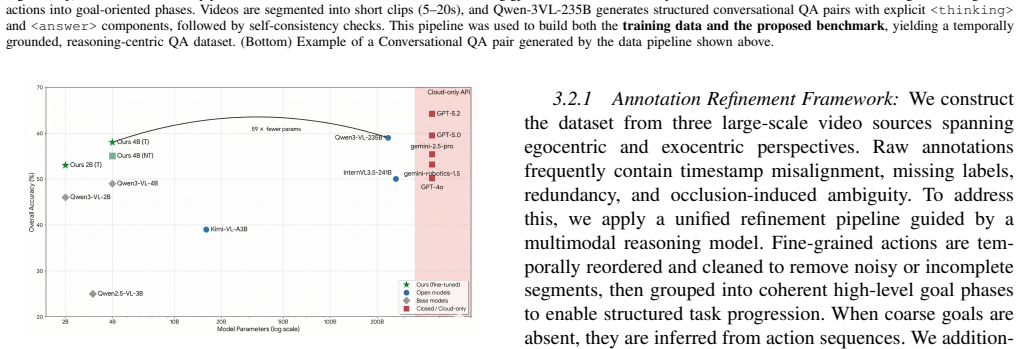
The authors introduce pause-and-think-T, a reasoning-centric training dataset that encourages models to pause, reason over visual evidence, and produce concise, actionable responses for video-grounded assistive actions. They fine-tune a compact 4B-parameter model and evaluate it on pause-and-think-B, achieving 58.0 percent accuracy that matches Qwen3-VL-235B at 58.9 percent while also matching or exceeding GPT models on scene understanding and showing substantial out-of-distribution gains on affordance, assistance, attribution, situated reasoning, and temporal order tasks.
What carries the argument
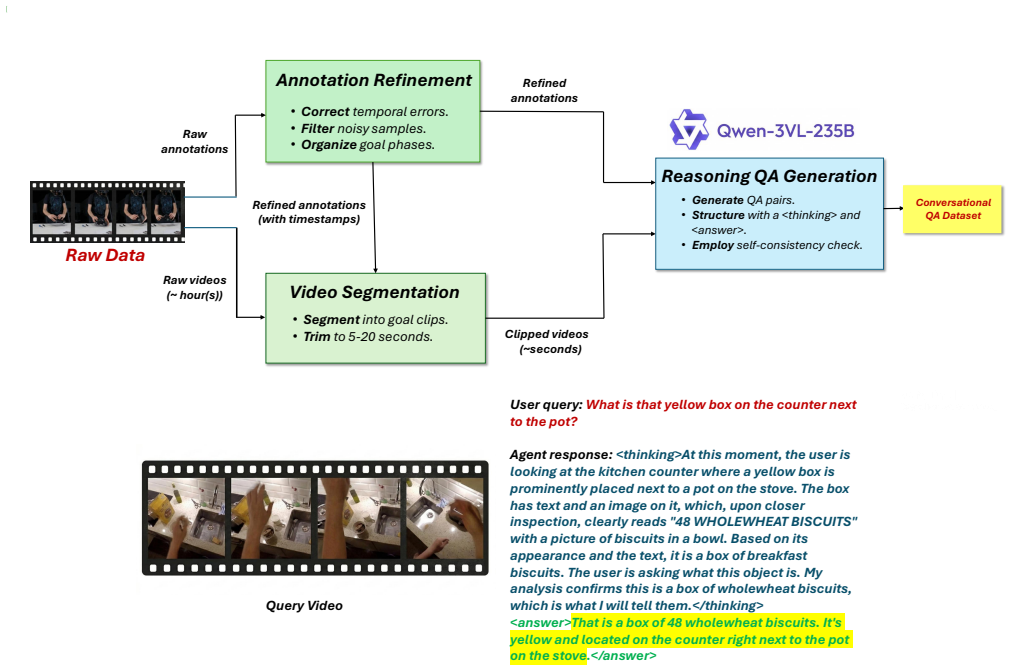
The pause-and-think-T dataset, which structures training so models pause and reason over video evidence before generating scene-grounded assistance responses.
If this is right
- Compact models can produce actionable, visually grounded guidance without requiring large-scale model expansion.
- Models trained this way generalize to out-of-distribution benchmarks on affordance recognition and temporal ordering.
- Targeted reasoning supervision can close performance gaps that currently favor much larger models on video planning tasks.
Where Pith is reading between the lines
- The same pause-and-reason pattern could be applied to training data for robotic manipulation videos to improve real-world action planning.
- If the approach holds, it reduces the need to scale model size for every new video reasoning domain.
- Real-time systems could embed the fine-tuned compact model for on-device assistive suggestions in dynamic environments.
Load-bearing premise
The new dataset and benchmark truly isolate and reward structured reasoning and contextual understanding rather than other factors such as dataset biases or evaluation artifacts.
What would settle it
Performance of the fine-tuned 4B model falling well below the reported 58 percent on a fresh collection of videos that require similar assistive planning but use different camera angles, lighting, or object arrangements.
Figures

read the original abstract
Recent Vision-Language Models (VLMs) struggle with grounded reasoning, temporal consistency, and context aware planning in videos. We introduce pause-and-think-T, a reasoning-centric training dataset that encourages models to pause, reason over visual evidence, and produce concise, actionable responses. The dataset promotes structured reasoning prior to answer generation, guiding models toward human-like, scene-grounded assistance. We fine-tune a compact 4B-parameter model and evaluate it on our pause-and-think-B benchmark targeting contextual understanding and goal planning tasks. The model achieves 58.0% accuracy at 59x fewer parameters than Qwen3-VL-235B (58.9%), matching GPT-5.2 on scene understanding and surpassing GPT-4o. Beyond our benchmark, it also shows strong out-of-distribution performance on EgoThink and TempCompass, with substantial gains in affordance, assistance, attribution recognition, situated reasoning, and temporal order, without benchmark-specific training. Our results indicate that targeted reasoning supervision enables compact models to deliver actionable, visually grounded guidance while generalizing beyond training data, without requiring large-scale model expansion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces pause-and-think-T, a reasoning-centric training dataset that encourages VLMs to pause and produce structured, visually grounded responses for video-based assistive action suggestion, and pause-and-think-B, a benchmark targeting contextual understanding and goal planning. A 4B-parameter model is fine-tuned on the dataset and evaluated on the benchmark, achieving 58.0% accuracy (comparable to Qwen3-VL-235B at 58.9% and GPT-5.2), with additional strong OOD results on EgoThink and TempCompass in areas such as affordance, assistance, and temporal order.
Significance. If the benchmark and dataset construction validly isolate structured reasoning and contextual understanding, the work would demonstrate that targeted supervision can produce compact, generalizable VLMs for grounded video tasks without large-scale expansion, with potential efficiency benefits for assistive applications.
major comments (2)
- [Abstract] Abstract: The abstract reports specific accuracy numbers (58.0%) and generalization claims on EgoThink/TempCompass but supplies no details on dataset construction, benchmark design, question generation, distractor construction, human validation, statistical tests, baselines, or controls. This is load-bearing for the central claim that performance reflects structured reasoning supervision rather than artifacts.
- [Abstract (benchmark description)] pause-and-think-B benchmark description: The claim that the benchmark targets contextual understanding and goal planning (and that OOD gains demonstrate generalization) requires evidence that it isolates these capabilities from language-model priors, answer-format leakage, or scene-statistic shortcuts; no such controls or validation procedures are described.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the content of the full manuscript and indicating where revisions can strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports specific accuracy numbers (58.0%) and generalization claims on EgoThink/TempCompass but supplies no details on dataset construction, benchmark design, question generation, distractor construction, human validation, statistical tests, baselines, or controls. This is load-bearing for the central claim that performance reflects structured reasoning supervision rather than artifacts.
Authors: The abstract is a concise summary by design. The full manuscript provides the requested details: dataset construction and reasoning-centric prompting in Section 3, benchmark design with question generation, distractor construction, and human validation in Section 4, and baselines, controls, and statistical tests in Section 5. This follows standard practice where abstracts highlight results and the body supplies methodology. We will revise the abstract to include a short clause referencing these elements for improved clarity. revision: yes
-
Referee: [Abstract (benchmark description)] pause-and-think-B benchmark description: The claim that the benchmark targets contextual understanding and goal planning (and that OOD gains demonstrate generalization) requires evidence that it isolates these capabilities from language-model priors, answer-format leakage, or scene-statistic shortcuts; no such controls or validation procedures are described.
Authors: The benchmark questions are constructed to require video-grounded multi-step reasoning, with human validation confirming that answers cannot be derived from language priors alone. Strong OOD results on EgoThink and TempCompass (different formats and domains) further support generalization beyond training artifacts. While explicit ablations for scene-statistic shortcuts or answer-format leakage are not included, we can add a dedicated limitations paragraph discussing these potential confounds and the supporting evidence from human validation and OOD tests. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces pause-and-think-T as a training dataset and pause-and-think-B as an evaluation benchmark, then reports empirical fine-tuning results (58% accuracy on the 4B model) plus OOD gains on external sets (EgoThink, TempCompass). These outcomes are direct measurements from training and testing rather than any derivation that reduces to inputs by construction. No self-definitional relations, fitted parameters renamed as predictions, load-bearing self-citations, or ansatz smuggling appear in the abstract or described claims. The central statement that targeted supervision enables compact models to generalize is presented as an experimental finding, not a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Targeted dataset design can instill structured visual reasoning in VLMs beyond what standard training provides
Reference graph
Works this paper leans on
-
[1]
S. Bai, Y . Cai, R. Chen, K. Chen,et al., “Qwen3-vl technical report,” arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Egothink: Evaluating first-person perspective thinking capability of vision-language models,
S. Cheng, Z. Guo, J. Wu, K. Fang, P. Li, H. Liu, and Y . Liu, “Egothink: Evaluating first-person perspective thinking capability of vision-language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 14 291–14 302
2024
-
[3]
Scaling egocentric vision: The epic-kitchens dataset,
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray, “Scaling egocentric vision: The epic-kitchens dataset,” inEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[4]
Video-R1: Reinforcing Video Reasoning in MLLMs
K. Feng, K. Gong, B. Li,et al., “Video-r1: Reinforcing video reasoning in mllms,”arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
C. Fu, Y . Dai, Y . Luo,et al., “Video-mme: The first-ever compre- hensive evaluation benchmark of multi-modal llms in video analysis,” arXiv preprint arXiv:2405.21075, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger,et al., “Ego4d: Around the world in 3,000 hours of egocentric video,” 2022. [Online]. Available: https://arxiv.org/abs/2110.07058
-
[7]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[8]
Tempcompass: Do video llms really understand videos?
Y . Liu, S. Li, Y . Liu, Y . Wang, S. Ren, L. Li, S. Chen, X. Sun, and L. Hou, “Tempcompass: Do video llms really understand videos?”
-
[9]
TempCompass: Do Video LLMs Really Understand Videos?
[Online]. Available: https://arxiv.org/abs/2403.00476
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Egoschema: A diagnostic benchmark for very long-form video language understanding,
K. Mangalam, R. Akshulakov, and J. Malik, “Egoschema: A diagnostic benchmark for very long-form video language understanding,” 2023. [Online]. Available: https://arxiv.org/abs/2308.09126
-
[11]
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
NVIDIA, A. Azzolini, J. Bai, H. Brandon,et al., “Cosmos-reason1: From physical common sense to embodied reasoning,” 2025. [Online]. Available: https://arxiv.org/abs/2503.15558
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Gpt-5 series models,
OpenAI, “Gpt-5 series models,” https://platform.openai.com/docs/ models, 2026, accessed: March 2026
2026
-
[13]
gpt-oss,
OpenAI, S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, et al., “gpt-oss,” 2025. [Online]. Available: https://arxiv.org/abs/2508. 10925
2025
-
[14]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, Jiang,et al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 27 730–27 744. [Online]. Available: https://openai.com/index/instruction-following/
2022
-
[15]
Assembly101: A large-scale multi-view video dataset for understanding procedural activities,
F. Sener, D. Chatterjee, D. Shelepov, K. He, D. Singhania, R. Wang, and A. Yao, “Assembly101: A large-scale multi-view video dataset for understanding procedural activities,”CVPR 2022, 2022
2022
-
[16]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
H. Shen, P. Liu, J. Li,et al., “Vlm-r1: A stable and generalizable r1- style large vision-language model,”arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Stanford alpaca: An instruction- following llama model,
R. Taori, I. Gulrajani, T. Zhang, Y . Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Stanford alpaca: An instruction- following llama model,” https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[18]
G. R. Team, A. Abdolmaleki, S. Abeyruwan,et al., “Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer,” 2025. [Online]. Available: https://arxiv.org/abs/2510.03342
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Benchmarking egocentric multimodal goal inference for assistive wearable agents,
V . Veerabadran, F. Xiao, N. Kamra,et al., “Benchmarking egocentric multimodal goal inference for assistive wearable agents,” 2025. [Online]. Available: https://arxiv.org/abs/2510.22443
-
[20]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
X. Wang, J. Wei, D. Schuurmans,et al., “Self-consistency improves chain of thought reasoning in language models,” 2023. [Online]. Available: https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Next-qa: Next phase of question-answering to explaining temporal actions,
J. Xiao, X. Shang, A. Yao, and T.-S. Chua, “Next-qa: Next phase of question-answering to explaining temporal actions,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), June 2021, pp. 9777–9786
2021
-
[22]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Y . Zheng, R. Zhang, J. Zhang, Y . Ye, Z. Luo, Z. Feng, and Y . Ma, “Llamafactory: Unified efficient fine-tuning of 100+ language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Bangkok, Thailand: Association for Computational Linguistics, 2024. [Online]. Available: http...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.