Macro-aware time series forecasting via hierarchical mixed-frequency attention models
Pith reviewed 2026-06-28 17:51 UTC · model grok-4.3
The pith
HANET uses attention over historical macroeconomic regimes to outperform neural forecasters on futures returns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
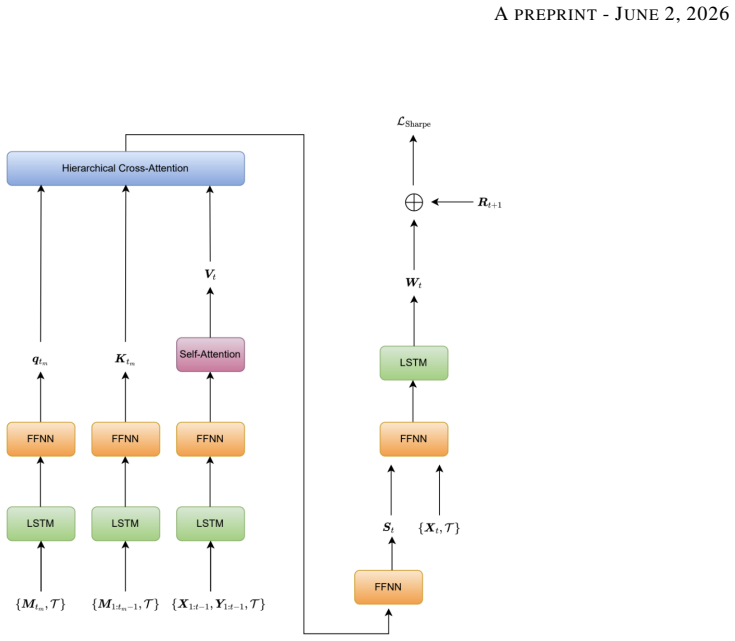
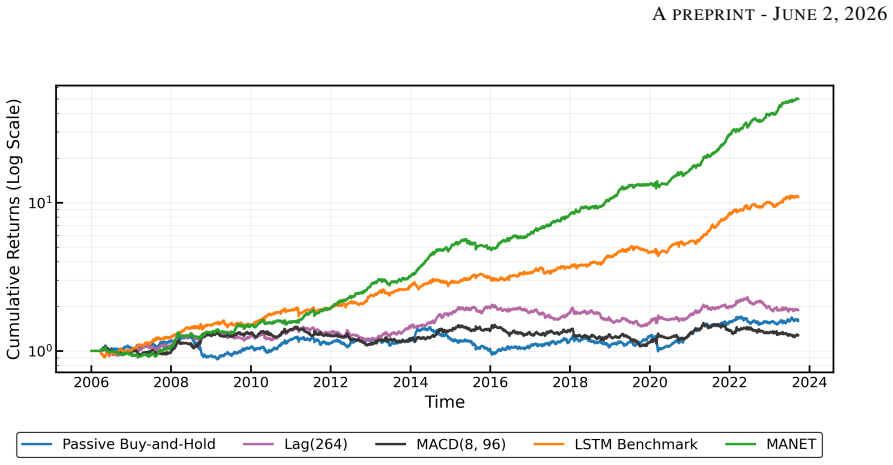
HANET organizes information in a hierarchical mixed-frequency structure with daily returns nested within monthly macro windows and introduces a Hierarchical Cross-Attention mechanism that reconciles low-frequency macro signals with high-frequency returns. By framing regime selection as attention over macroeconomic contexts, the model adapts to scarce and shifting regimes and delivers consistent outperformance over macro-ignorant neural forecasters across 55 liquid futures, especially in turbulent periods, while attention weights supply interpretability by linking specific historical regimes to current forecasts.
What carries the argument
HANET (Hierarchical Attention Network) with Hierarchical Cross-Attention that nests daily asset-return signals inside monthly macroeconomic windows.
If this is right
- Forecasts adapt to current conditions by weighting the most relevant past macroeconomic regimes.
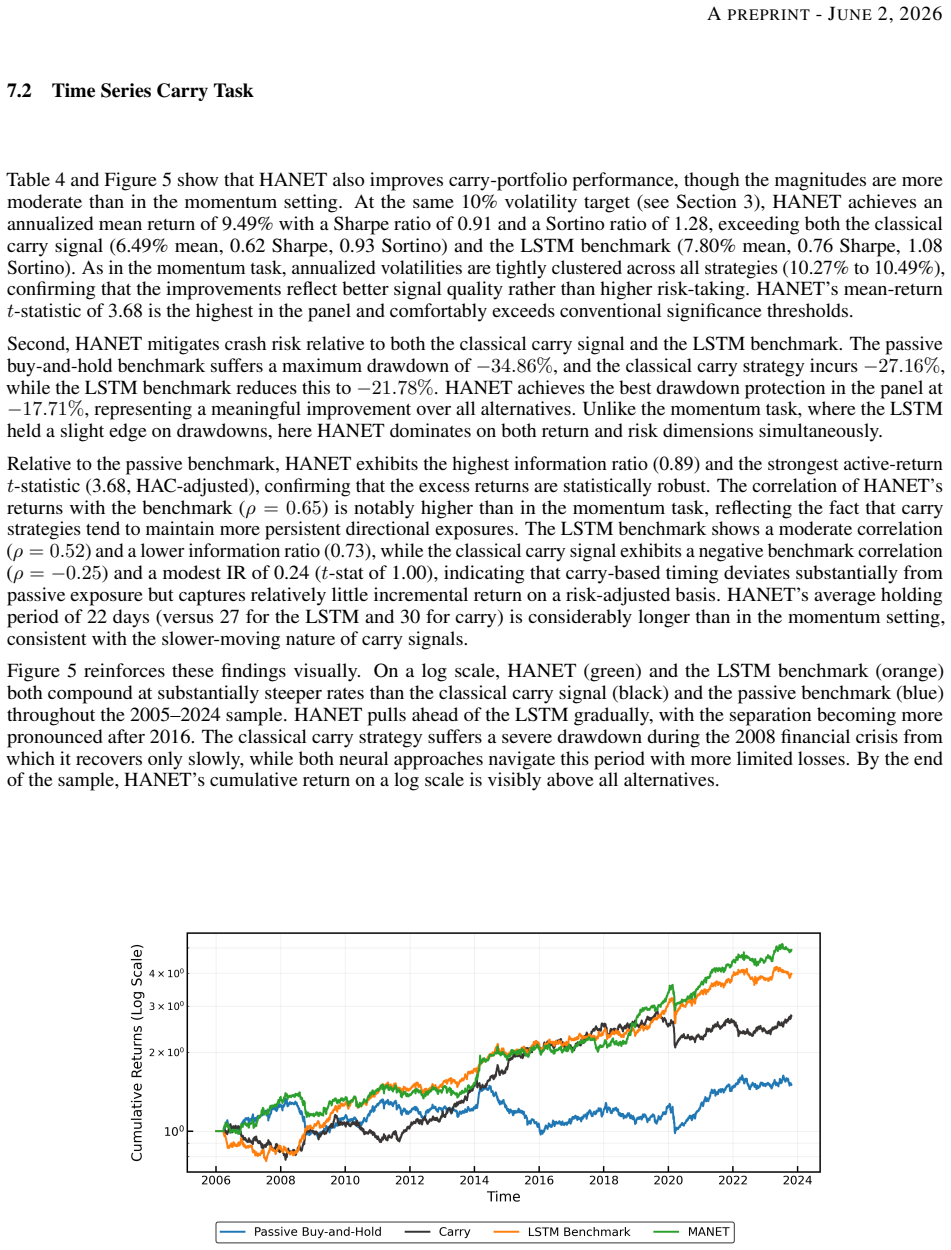
- Outperformance is largest during turbulent market periods.
- Attention weights directly indicate which historical macro states influence each daily prediction.
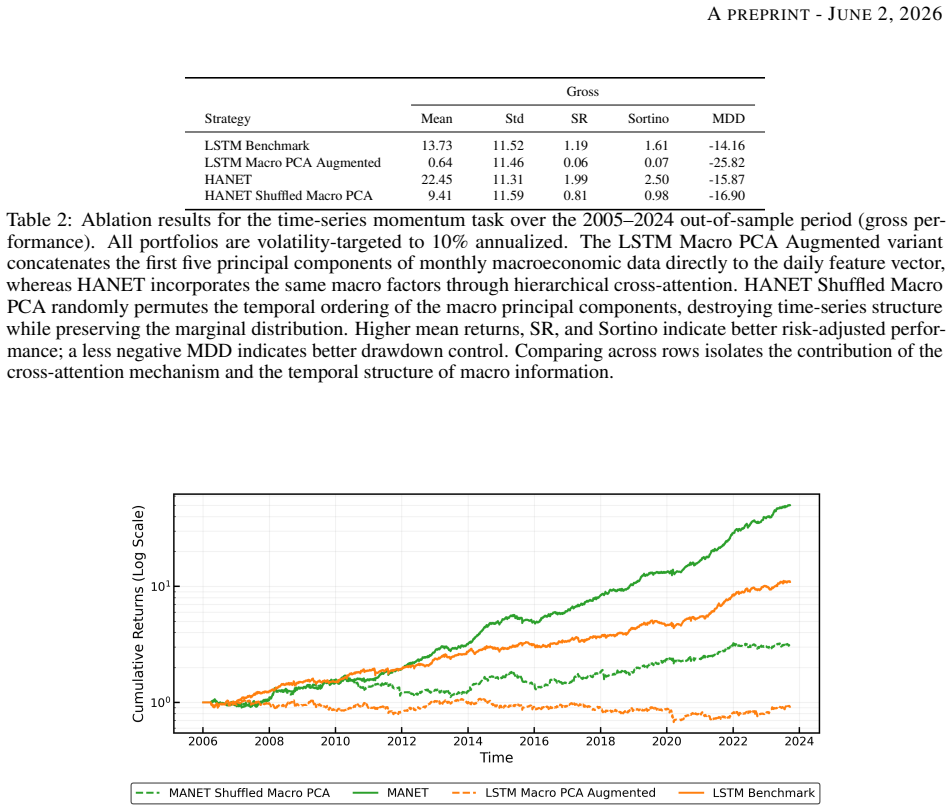
- Gains require the hierarchical attention structure; naive macro feature addition produces little or no improvement.
Where Pith is reading between the lines
- The same nesting and cross-attention pattern could be tested on other mixed-frequency series such as economic indicators paired with high-frequency sensor data.
- If the attention weights consistently highlight the same macro variables across assets, those variables may be the primary drivers of regime changes.
- The scarcity of regimes suggests the model might maintain performance on future economic conditions that differ from the training distribution more than purely data-driven forecasters.
Load-bearing premise
That attention over historical macro contexts can reliably identify relevant regimes for current forecasts instead of memorizing noise or spurious correlations from the limited number of observed regime shifts.
What would settle it
If performance stays the same after randomly shuffling macro contexts across time periods or after replacing the hierarchical attention with simple concatenation of macro features, the claim that structured regime attention drives the gains would be falsified.
Figures


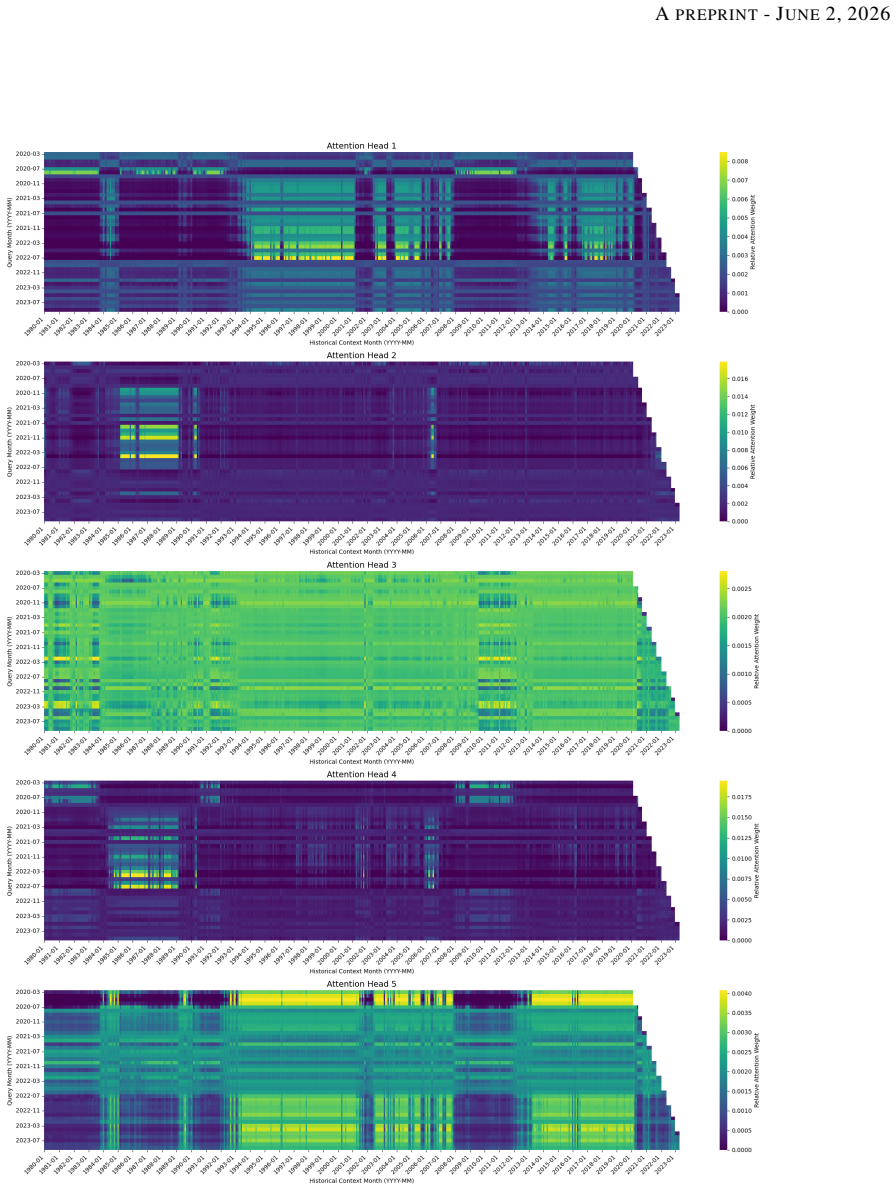

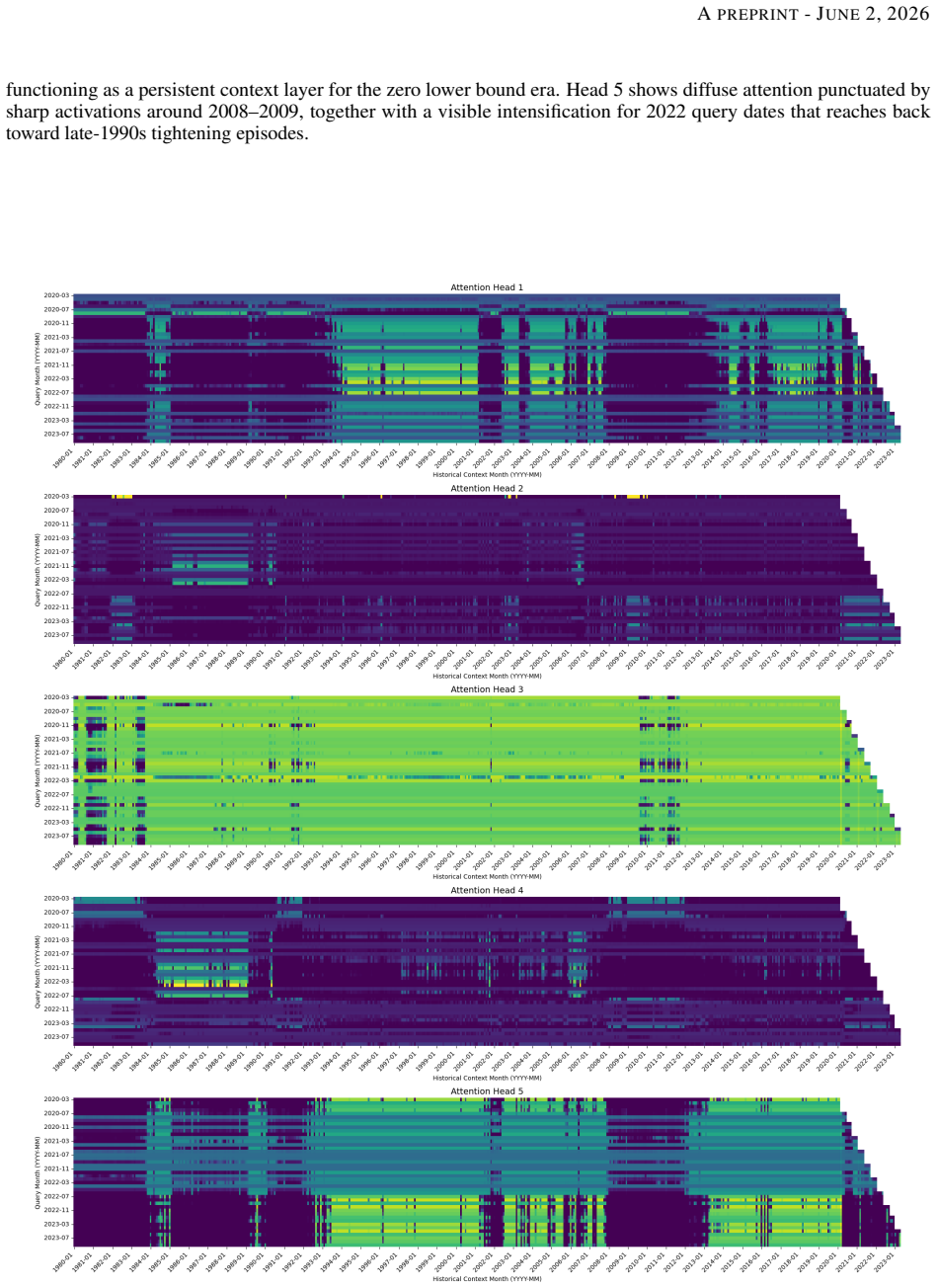


read the original abstract
Deep learning models show promise in financial forecasting, yet their generalization is often undermined by small datasets, noisy signals, and non-stationarity. While meta-learning and related techniques mitigate some of these issues, they typically do not account for a core limitation in macro-financial prediction: the scarcity of distinct macroeconomic regimes that drive asset returns. We introduce HANET (Hierarchical Attention Network), a hybrid LSTM-based architecture that integrates macroeconomic domain knowledge through attention over long-run macro contexts while preserving high-frequency market dynamics. HANET organizes information in a hierarchical mixed-frequency structure, with daily asset-return signals nested within monthly macroeconomic windows, and introduces a Hierarchical Cross-Attention mechanism that reconciles low-frequency macro signals with high-frequency returns without discarding granular daily information. By framing regime selection as attention over macroeconomic contexts, the model adapts to scarce and shifting regimes. Empirically, across 55 liquid futures spanning multiple asset classes, HANET consistently outperforms neural forecasters that ignore macroeconomic information, particularly during turbulent periods, improving risk-adjusted returns and mitigating losses. Ablation studies show that these gains rely on structured macro conditioning rather than naive feature augmentation: an LSTM with the same macro representation performs poorly, and shuffling macro contexts substantially degrades performance. Finally, HANET provides interpretability through attention weights, highlighting which historical regimes are most influential for each forecast and linking macro conditions to portfolio outcomes. These results establish HANET as a systematic approach to integrating macroeconomic information into attention-based deep learning for financial forecasting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HANET, a hierarchical mixed-frequency LSTM architecture with cross-attention over monthly macro contexts to condition daily financial forecasts. It claims consistent outperformance versus macro-ignoring neural baselines across 55 liquid futures, with larger gains in turbulent periods, plus ablations demonstrating that structured macro conditioning (rather than naive feature addition) drives the results and that attention weights provide interpretability by linking historical regimes to forecasts.
Significance. If the empirical claims hold after addressing the regime-scarcity concern, the work would supply a concrete architecture for incorporating infrequent macro regimes into attention-based forecasters, addressing a recognized limitation in financial time-series modeling. The ablation controls and interpretability via attention weights are positive features that strengthen the contribution if the central performance results prove robust.
major comments (3)
- [§4 (Experiments)] §4 (Experiments) and associated tables: the reported outperformance 'particularly during turbulent periods' lacks an explicit definition of turbulent regimes or formal statistical tests (e.g., Diebold-Mariano or bootstrap) comparing HANET to baselines within those sub-periods; this is load-bearing for the strongest claim.
- [Ablation studies] Ablation studies (shuffling macro contexts and LSTM-with-macro baseline): these controls show degradation but do not isolate whether Hierarchical Cross-Attention exploits the temporal scarcity of regime transitions (typically <10 distinct episodes across multi-decade futures data) versus learning transferable conditioning, especially under the non-stationarity highlighted in the abstract.
- [§3.2 (Hierarchical Cross-Attention mechanism)] §3.2 (Hierarchical Cross-Attention mechanism): the description of nesting daily returns within monthly macro windows does not specify how the attention avoids fitting to idiosyncratic timing of the limited historical regime shifts rather than generalizable patterns; a concrete test (e.g., out-of-sample regime-shift simulation) is needed to support the central empirical claim.
minor comments (2)
- Clarify the exact risk-adjusted metrics (Sharpe, Sortino, etc.) and whether transaction costs or slippage are included when claiming 'improving risk-adjusted returns'.
- Figure captions and tables should explicitly state the number of distinct macro regimes identified in the training data to allow readers to assess the scarcity issue directly.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with proposed revisions to strengthen the empirical claims and clarify the methodology.
read point-by-point responses
-
Referee: §4 (Experiments) and associated tables: the reported outperformance 'particularly during turbulent periods' lacks an explicit definition of turbulent regimes or formal statistical tests (e.g., Diebold-Mariano or bootstrap) comparing HANET to baselines within those sub-periods; this is load-bearing for the strongest claim.
Authors: We agree that an explicit definition and formal tests are required. In the revision we will define turbulent periods via VIX exceeding its historical 75th percentile (with robustness to alternative thresholds such as realized volatility) and add Diebold-Mariano tests plus bootstrap confidence intervals for HANET versus baselines restricted to those sub-periods. These will appear in §4 and the associated tables. revision: yes
-
Referee: Ablation studies (shuffling macro contexts and LSTM-with-macro baseline): these controls show degradation but do not isolate whether Hierarchical Cross-Attention exploits the temporal scarcity of regime transitions (typically <10 distinct episodes across multi-decade futures data) versus learning transferable conditioning, especially under the non-stationarity highlighted in the abstract.
Authors: The macro-context shuffling ablation already demonstrates that gains depend on the specific historical regimes rather than generic macro features. We will expand the discussion to note that the attention mechanism is intended to match current macro states to analogous past regimes, thereby promoting transferable conditioning despite scarcity. A fully isolating experiment is difficult given the limited number of regime episodes, but the existing controls and interpretability results provide supporting evidence. revision: partial
-
Referee: §3.2 (Hierarchical Cross-Attention mechanism): the description of nesting daily returns within monthly macro windows does not specify how the attention avoids fitting to idiosyncratic timing of the limited historical regime shifts rather than generalizable patterns; a concrete test (e.g., out-of-sample regime-shift simulation) is needed to support the central empirical claim.
Authors: We will revise §3.2 to clarify that cross-attention is performed on aggregated monthly macro embeddings, enabling the model to attend to macro-state similarity rather than calendar timing. We will also add a limited out-of-sample regime-holdout experiment (training on all but one major regime episode and testing on the held-out period) to illustrate generalization; we acknowledge that the small number of distinct regimes constrains the power of such tests. revision: partial
Circularity Check
No circularity: empirical architecture with independent ablations
full rationale
The paper introduces HANET as a hybrid LSTM architecture with hierarchical cross-attention for mixed-frequency macro conditioning in futures forecasting. All claims rest on empirical out-of-sample performance, ablation studies (LSTM with same macro features performs poorly; shuffling macro contexts degrades results), and attention-weight interpretability across 55 futures. No equations, derivations, or 'predictions' are presented that reduce to fitted inputs by construction. No self-citation chains or uniqueness theorems are invoked to justify the central results. The work is self-contained against external benchmarks via direct comparisons and controls.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LSTM networks can capture temporal dependencies in financial time series
- domain assumption Historical macroeconomic contexts contain distinct regimes that influence asset returns
Reference graph
Works this paper leans on
-
[1]
Review of Financial Studies , volume=
Common risk factors in currency markets , author=. Review of Financial Studies , volume=. 2011 , publisher=
2011
-
[2]
Journal of Financial Economics , volume=
Carry , author=. Journal of Financial Economics , volume=. 2018 , publisher=
2018
-
[3]
IEEE Transactions on Signal Processing , volume=
DeepLOB: Deep convolutional neural networks for limit order books , author=. IEEE Transactions on Signal Processing , volume=. 2019 , publisher=
2019
-
[4]
Review of Financial Studies , volume=
Empirical asset pricing via machine learning , author=. Review of Financial Studies , volume=. 2020 , publisher=
2020
-
[5]
The Journal of Financial Data Science , volume=
Deep learning for portfolio optimization , author=. The Journal of Financial Data Science , volume=. 2020 , publisher=
2020
-
[6]
The Journal of Financial Data Science , volume=
Enhancing time-series momentum strategies using deep neural networks , author=. The Journal of Financial Data Science , volume=. 2019 , publisher=
2019
-
[7]
International Conference on Learning Representations (ICLR) , year=
Neural machine translation by jointly learning to align and translate , author=. International Conference on Learning Representations (ICLR) , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Econometric Reviews , volume=
MIDAS regressions: Further results and new directions , author=. Econometric Reviews , volume=. 2007 , publisher=
2007
-
[10]
Journal of the Royal Statistical Society: Series A , volume=
Unrestricted mixed data sampling (MIDAS): MIDAS regressions with unrestricted lag polynomials , author=. Journal of the Royal Statistical Society: Series A , volume=. 2015 , publisher=
2015
-
[11]
Handbook of Economic Forecasting , volume=
Now-casting and the real-time data flow , author=. Handbook of Economic Forecasting , volume=. 2013 , publisher=
2013
-
[12]
and Xing, Yuhang and Zhang, Xiaoyan , title =
Ang, Andrew and Hodrick, Robert J. and Xing, Yuhang and Zhang, Xiaoyan , title =. The Journal of Finance , volume =. doi:10.1111/j.1540-6261.2006.00836.x , url =
-
[13]
and Le Roux, Nicolas and Rattray, Sandy , title =
Baz, Jamil and Granger, Nicolas and Harvey, Campbell R. and Le Roux, Nicolas and Rattray, Sandy , title =. 2015 , month =
2015
-
[14]
International Journal of Neural Systems , volume =
Bengio, Yoshua , title =. International Journal of Neural Systems , volume =. 1997 , month =. doi:10.1142/s0129065797000422 , publisher =
-
[15]
Breeden, Douglas T. , title =. Journal of Financial Economics , volume =. 1979 , month =. doi:10.1016/0304-405X(79)90016-3 , publisher =
-
[16]
and Nagel, Stefan and Pedersen, Lasse H
Brunnermeier, Markus K. and Nagel, Stefan and Pedersen, Lasse H. , title =. NBER Macroeconomics Annual , volume =. 2008 , doi =
2008
-
[17]
and Bowyer, Kevin W
Chawla, Nitesh V. and Bowyer, Kevin W. and Hall, Lawrence O. and Kegelmeyer, W. Philip , title =. J. Artif. Int. Res. , month = jun, pages =. 2002 , issue_date =
2002
-
[18]
, title =
Chen, Nai-Fu and Roll, Richard and Ross, Stephen A. , title =. The Journal of Business , volume =. 1986 , month =
1986
-
[19]
Daniel, Kent and Moskowitz, Tobias J. , title =. Journal of Financial Economics , volume =. 2016 , month =. doi:10.1016/j.jfineco.2015.12.002 , publisher =
-
[20]
Epstein, Larry G. and Zin, Stanley E. , title =. Econometrica , volume =. 1989 , month =. doi:10.2307/1913778 , publisher =
-
[21]
Fama, Eugene F. and French, Kenneth R. , title =. Journal of Financial Economics , volume =. 1989 , month =. doi:10.1016/0304-405X(89)90095-0 , publisher =
-
[22]
Freund, Yoav and Schapire, Robert E. , title =. Journal of Computer and System Sciences , volume =. 1997 , month =. doi:10.1006/jcss.1997.1504 , publisher =
-
[23]
, journal=
He, Haibo and Garcia, Edwardo A. , journal=. Learning from Imbalanced Data , year=
-
[24]
The Journal of Finance , volume =
Ilmanen, Antti , title =. The Journal of Finance , volume =. 1995 , month =. doi:10.2307/2329416 , publisher =
-
[25]
Kahn, Herman and Marshall, Andrew W. , title =. Journal of the Operations Research Society of America , volume =. 1953 , month =. doi:10.1287/opre.1.5.263 , publisher =
-
[26]
International Conference on Learning Representations , year=
Attentive Neural Processes , author=. International Conference on Learning Representations , year=
-
[27]
The Journal of Finance , volume =
Lettau, Martin and Ludvigson, Sydney , title =. The Journal of Finance , volume =. 2001 , month =. doi:10.1111/0022-1082.00347 , publisher =
-
[28]
Focal Loss for Dense Object Detection , year=
Lin, Tsung-Yi and Goyal, Priya and Girshick, Ross and He, Kaiming and Dollár, Piotr , journal=. Focal Loss for Dense Object Detection , year=
-
[29]
Lucas, Robert E. , title =. Econometrica , volume =. 1978 , month =. doi:10.2307/1913837 , publisher =
-
[30]
Empirical Evidence on the Stock--Bond Correlation , journal =
Molenaar, Roderick and S\'. Empirical Evidence on the Stock--Bond Correlation , journal =. 2024 , doi =
2024
-
[31]
and Ooi, Yao Hua and Pedersen, Lasse Heje , title =
Moskowitz, Tobias J. and Ooi, Yao Hua and Pedersen, Lasse Heje , title =. Journal of Financial Economics , volume =. 2012 , month =. doi:10.1016/j.jfineco.2011.11.003 , publisher =
-
[32]
Proceedings of the 35th International Conference on Machine Learning , pages =
Learning to Reweight Examples for Robust Deep Learning , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[33]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Shu, Jun and Xie, Qi and Yi, Lixuan and Zhao, Qian and Zhou, Sanping and Xu, Zongben and Meng, Deyu , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2019 , url =
2019
-
[34]
Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =
Vinyals, Oriol and Blundell, Charles and Lillicrap, Timothy and Kavukcuoglu, Koray and Wierstra, Daan , title =. Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =. 2016 , isbn =
2016
-
[35]
Journal of Financial Data Science , volume =
Few-shot learning patterns in financial time series for trend-following strategies , author =. Journal of Financial Data Science , volume =. 2024 , doi =
2024
-
[36]
The Journal of Financial Data Science , volume =
Wood, Kieran and Roberts, Stephen and Zohren, Stefan , title =. The Journal of Financial Data Science , volume =. 2022 , doi =
2022
-
[37]
arXiv preprint arXiv:2601.05975 , year=
DeePM: Regime-Robust Deep Learning for Systematic Macro Portfolio Management , author=. arXiv preprint arXiv:2601.05975 , year=
-
[38]
arXiv preprint arXiv:2112.08534 , year=
Trading with the Momentum Transformer: An Intelligent and Interpretable Architecture , author=. arXiv preprint arXiv:2112.08534 , year=
-
[39]
Journal of Business & Economic Statistics , year =
FRED-MD: A Monthly Database for Macroeconomic Research , author =. Journal of Business & Economic Statistics , year =
-
[40]
International Conference on Learning Representations , year=
Understanding deep learning requires rethinking generalization , author=. International Conference on Learning Representations , year=
-
[41]
The Journal of Financial Data Science , volume=
Enhancing Time-Series Momentum Strategies Using Deep Neural Networks , author=. The Journal of Financial Data Science , volume=. 2019 , doi=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.