Collaborative Few-Step Distillation and Low-Bit Quantization for Wan2.2 Dual-Expert Video Diffusion Models
Pith reviewed 2026-06-28 18:56 UTC · model grok-4.3
The pith
Few-step distillation paired with separate low-bit quantization of high-noise and low-noise experts keeps video diffusion quality near full precision at 8 and 20 steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The co-design of few-step distillation with expert-specific HiF4-style low-bit quantization, calibrated on the distilled student and applied separately to the high-noise and low-noise branches while shielding entrance layers, keeps the quantized model close to the same-step full-precision model and surpasses the original full-precision baseline at 8 and 20 steps on average.
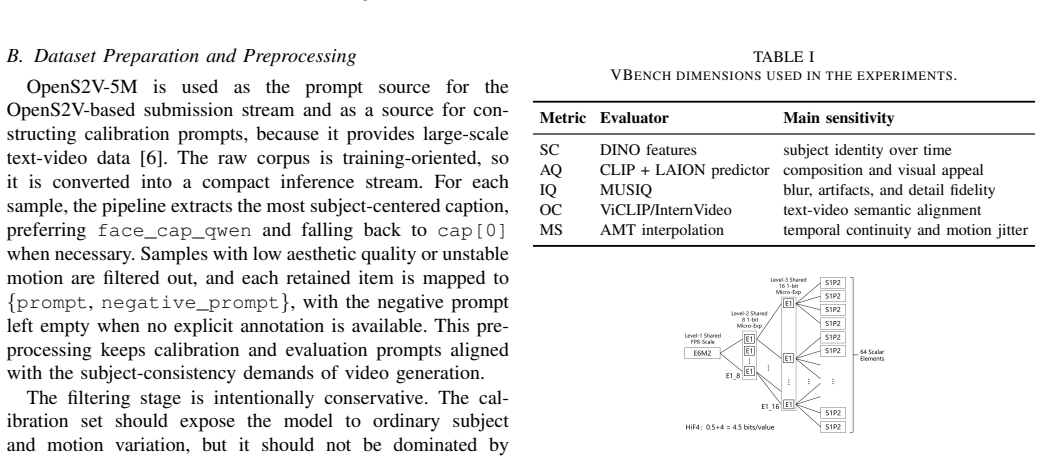
What carries the argument
Dual-expert denoising route with separate calibration of high-noise and low-noise branches performed on the distilled few-step student rather than the original long-step trajectory, together with HiF4 low-bit representation and protection of sensitive entrance layers.
If this is right
- The quantized model matches same-step full-precision quality while using fewer bits.
- At 8 and 20 steps the quantized version exceeds the original full-precision baseline on average.
- The 20-step setting provides the best observed quality-efficiency trade-off among the tested configurations.
- Calibration on the distilled student reduces activation mismatch that would otherwise appear at inference.
Where Pith is reading between the lines
- The same separate-expert calibration pattern could be tested on other dual-branch or multi-expert diffusion architectures.
- Lower step counts made possible by this pipeline may allow video generation on hardware with tighter memory and latency budgets.
- Further reductions in bit width might remain viable if the same student-based calibration and expert separation are retained.
Load-bearing premise
That calibrating quantization on the distilled few-step student instead of the original long-step trajectory is enough to remove activation-distribution mismatch at inference time, and that separate expert calibration plus entrance-layer protection is sufficient to retain quality.
What would settle it
A side-by-side evaluation on a standard video benchmark where the 20-step quantized model scores lower than the original full-precision 20-step model on average perceptual quality metrics.
Figures

read the original abstract
Large video diffusion models achieve strong visual quality but remain expensive to deploy because each sample requires many denoising steps and a large resident parameter footprint. This paper studies a deployment-oriented compression pipeline for Wan2.2-T2V-A14B by combining few-step distribution-matching distillation with low-bit quantization. The pipeline follows the model's dual-expert denoising route, calibrates the high-noise and low-noise branches separately, protects sensitive entrance layers, and uses HiF4-style low-bit representation to improve dynamic-range coverage. Quantization is calibrated on the distilled few-step student rather than on the original long-step trajectory, reducing activation-distribution mismatch during inference. The proposed co-design keeps the quantized model close to the same-step full-precision model and surpasses the original full-precision baseline at 8 and 20 steps on average. The 20-step setting gives the best quality-efficiency trade-off in the tested configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a deployment-oriented compression pipeline for the Wan2.2-T2V-A14B dual-expert video diffusion model that combines few-step distribution-matching distillation with low-bit quantization. The pipeline calibrates the high-noise and low-noise experts separately, protects entrance layers, employs HiF4-style low-bit representations, and performs quantization calibration on the distilled few-step student rather than the original long-step trajectory. The central claim is that the resulting quantized model remains close in quality to the same-step full-precision model and surpasses the original full-precision baseline at 8 and 20 steps on average, with the 20-step setting providing the best quality-efficiency trade-off.
Significance. If the empirical results hold under rigorous validation, the work would be significant for practical deployment of large-scale video diffusion models, as it jointly addresses inference step count and memory footprint via co-design of distillation and quantization tailored to a dual-expert architecture. This could inform compression strategies for other generative models where both latency and parameter precision are constraints.
major comments (2)
- [Abstract] Abstract: The central claim that the co-design 'surpasses the original full-precision baseline at 8 and 20 steps on average' and that 'the 20-step setting gives the best quality-efficiency trade-off' is asserted without any quantitative metrics, ablation tables, dataset details, evaluation protocols, or statistical controls. This absence makes the primary empirical contribution unverifiable and load-bearing for the paper's conclusions.
- [Abstract] Abstract: The key design choice of performing quantization calibration on the distilled few-step student (rather than the original long-step trajectory) is presented as reducing activation-distribution mismatch, yet no supporting analysis, comparison experiments, or sensitivity results are supplied to demonstrate its adequacy or superiority.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater self-containment in the abstract and for explicit validation of the calibration design choice. We will revise the manuscript accordingly to strengthen verifiability while preserving the core technical contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the co-design 'surpasses the original full-precision baseline at 8 and 20 steps on average' and that 'the 20-step setting gives the best quality-efficiency trade-off' is asserted without any quantitative metrics, ablation tables, dataset details, evaluation protocols, or statistical controls. This absence makes the primary empirical contribution unverifiable and load-bearing for the paper's conclusions.
Authors: We agree the abstract should be more self-contained. The full manuscript contains the supporting results (VBench scores, user-study preferences, latency measurements, and statistical details across the tested datasets and step counts). In revision we will expand the abstract to include the key quantitative deltas (e.g., average margin over the long-step baseline at 8 and 20 steps) and a brief reference to the evaluation protocol, while keeping the length within journal limits. revision: yes
-
Referee: [Abstract] Abstract: The key design choice of performing quantization calibration on the distilled few-step student (rather than the original long-step trajectory) is presented as reducing activation-distribution mismatch, yet no supporting analysis, comparison experiments, or sensitivity results are supplied to demonstrate its adequacy or superiority.
Authors: Section 3.2 already motivates the choice via the observed activation shift between long-step and few-step trajectories. To directly address the request for evidence, the revision will add a compact ablation (new table or figure) that compares calibration on the original long-step model versus the distilled few-step student, reporting activation-distribution statistics (e.g., KL divergence or range coverage) and final generation quality. This will demonstrate the practical benefit of the chosen calibration target. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical compression pipeline combining few-step distillation and low-bit quantization for a video diffusion model. No equations, derivations, or mathematical claims are presented in the provided text; all assertions rest on experimental calibration choices and performance comparisons against baselines. The central claims about quality-efficiency trade-offs are supported by direct measurements rather than any self-referential fitting, self-citation chains, or definitions that reduce to inputs by construction. This is a standard empirical engineering result with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 6840–6851
2020
-
[3]
[Online]. Available: https://arxiv.org/abs/2204.03458
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yanget al., “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025. [Online]. Available: https://arxiv.org/abs/2503.20314
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Diffusers: State-of-the-art diffusion models,
P. von Platen, S. Patil, P. Cuenca, N. Lambert, K. Rasul, M. Davaadorj, D. Nair, S. Paul, W. Berman, Y . Xu, S. Liu, and T. Wolf, “Diffusers: State-of-the-art diffusion models,” https://github. com/huggingface/diffusers, 2022
2022
-
[7]
Available: https://arxiv.org/abs/2405.06001
[Online]. Available: https://arxiv.org/abs/2405.06001
-
[8]
OpenS2V-Nexus: A detailed benchmark and million-scale dataset for subject-to-video generation,
S. Yuan, X. He, Y . Deng, Y . Ye, J. Huang, B. Lin, J. Luo, and L. Yuan, “OpenS2V-Nexus: A detailed benchmark and million-scale dataset for subject-to-video generation,”arXiv preprint arXiv:2505.20292, 2025. [Online]. Available: https://arxiv.org/abs/2505.20292
-
[9]
Vbench: Comprehensive benchmark suite for video generative models, 2023
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, Y . Wang, X. Chen, L. Wang, D. Lin, Y . Qiao, and Z. Liu, “VBench: Comprehensive benchmark suite for video generative models,”arXiv preprint arXiv:2311.17982, 2023. [Online]. Available: https://arxiv.org/abs/2311.17982
-
[10]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. Jegou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9650–9660
2021
-
[11]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the International Conference on Machine Learning, 2021, pp. 8748–8763
2021
-
[12]
LAION-5B: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wight- man, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. Kundurthy, K. Crowson, L. Schmidt, R. Kaczmar- czyk, and J. Jitsev, “LAION-5B: An open large-scale dataset for training next generation image-text models,”Advances in Neural Information Processing Systems, vol. 35, pp....
2022
-
[13]
MUSIQ: Multi- scale image quality transformer,
J. Ke, Q. Wang, Y . Wang, P. Milanfar, and F. Yang, “MUSIQ: Multi- scale image quality transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 5148–5157
2021
-
[14]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Y . Wang, Y . He, Y . Li, K. Li, J. Yu, X. Ma, X. Chen, Y . Wang, P. Luo, Z. Liu, Y . Wang, L. Wang, and Y . Qiao, “InternVid: A large-scale video-text dataset for multimodal understanding and generation,”arXiv preprint arXiv:2307.06942, 2023. [Online]. Available: https://arxiv.org/abs/2307.06942
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
AMT: All-pairs multi-field transforms for efficient frame interpolation,
Z. Li, Z.-L. Zhu, L.-H. Han, Q. Hou, C.-L. Guo, and M.-M. Cheng, “AMT: All-pairs multi-field transforms for efficient frame interpolation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 9801–9810
2023
-
[16]
HiFloat4 format for language model inference,
Y . Luo, J. Huang, Y . Cheng, Z. Yu, K. Zhang, K. Hong, X. Ma, X. Wang, A. Tong, G. Hu, Y . Xu, M. Taghian, P. Wu, G. Li, Y . Peng, T. Hu, M. Chen, M. B. Mi, H. Liu, X. Zhou, J. Wang, Q. Lin, and H. Liao, “HiFloat4 format for language model inference,”arXiv preprint arXiv:2602.11287, 2026. [Online]. Available: https://arxiv.org/abs/2602.11287
-
[17]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate post-training quantization for generative pre-trained transformers,” in International Conference on Learning Representations, 2023. [Online]. Available: https://arxiv.org/abs/2210.17323
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
SmoothQuant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “SmoothQuant: Accurate and efficient post-training quantization for large language models,” inProceedings of the 40th International Conference on Machine Learning, vol. 202, 2023, pp. 38 087–38 099. [Online]. Available: https://arxiv.org/abs/2211.10438
-
[19]
Progressive distillation for fast sampling of diffusion models,
T. Salimans and J. Ho, “Progressive distillation for fast sampling of diffusion models,” inInternational Conference on Learning Representations, 2022. [Online]. Available: https://arxiv.org/abs/2202. 00512
2022
-
[20]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” inProceedings of the 40th International Conference on Machine Learning, vol. 202, 2023, pp. 32 211–32 252. [Online]. Available: https://proceedings.mlr.press/v202/song23a.html
2023
-
[21]
One-step diffusion with distribution matching distillation,
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park, “One-step diffusion with distribution matching distillation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. [Online]. Available: https: //arxiv.org/abs/2311.18828
-
[23]
[Online]. Available: https://arxiv.org/abs/2510.27684
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.