WaveFilter: Enhancing the Long-Context Capability of Diffusion LLMs via Wavelet-Guided KV Cache Filtering
Pith reviewed 2026-06-28 18:55 UTC · model grok-4.3
The pith
WaveFilter uses wavelet decomposition to identify key tokens and build sparse KV caches for diffusion LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
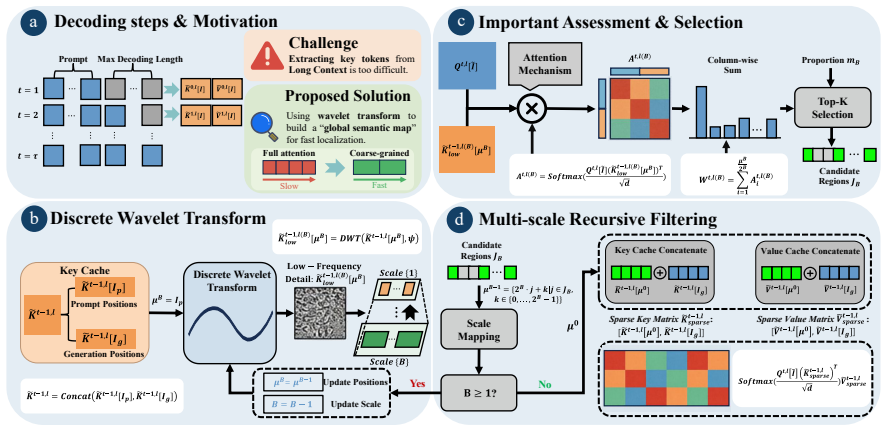
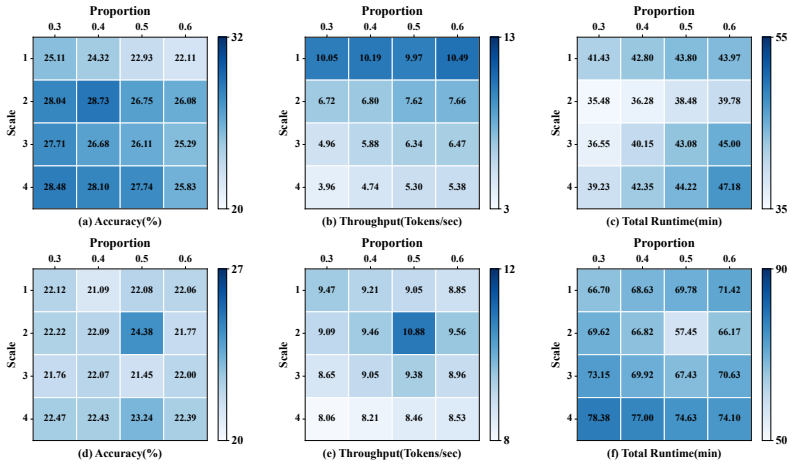
WaveFilter innovatively introduces the wavelet transform for decomposition of long sequences to achieve precise identification of key tokens, based on which a sparse KV Cache is constructed to compute the final contextual representation.
What carries the argument
Wavelet transform applied to long sequences for decomposition and precise identification of critical tokens that guide sparse KV cache construction.
Load-bearing premise
The wavelet transform can achieve precise and efficient identification of critical tokens within ultra-long contexts to construct an effective sparse KV cache without any training.
What would settle it
A direct comparison on a long-context benchmark in which WaveFilter plus a standard KV cache method produces equal or lower task accuracy than the same KV cache method without WaveFilter.
Figures

read the original abstract
Diffusion Large Language Models (DLMs) have demonstrated significant advantages across various tasks. However, constrained by their multi-step iterative inference mechanism, their computational overhead and inference latency in long-context tasks have become core bottlenecks restricting their large-scale deployment. When processing long sequences, existing Key-Value (KV) caching mechanisms often face a dilemma where generation quality degrades drastically, where the core challenge lies in precisely and efficiently filtering critical tokens within ultra-long contexts. Inspired by the human reading process, we propose \textbf{WaveFilter}, a universal and training-free caching framework. This framework innovatively introduces the wavelet transform for decomposition of long sequences to achieve precise identification of key tokens, based on which a sparse KV Cache is constructed to compute the final contextual representation. Experimental results demonstrate that WaveFilter, as a plug-and-play generic framework, significantly enhances the performance of existing mainstream KV Cache methods in complex long-context tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes WaveFilter, a plug-and-play and training-free framework for Diffusion LLMs that applies the wavelet transform to decompose long sequences, identify critical tokens, and construct a sparse KV cache. This is claimed to enhance the long-context performance of existing mainstream KV cache methods in complex tasks by addressing inference latency and quality degradation.
Significance. If the central claim holds, WaveFilter would represent a meaningful advance in efficient inference for diffusion-based LLMs by introducing a parameter-free, wavelet-based token filtering mechanism that requires no additional training. This could meaningfully reduce the computational bottlenecks that currently limit deployment of DLMs on ultra-long contexts, with potential applicability as a generic enhancement layer on top of prior KV cache techniques.
major comments (2)
- [Abstract] Abstract: the assertion that 'Experimental results demonstrate that WaveFilter... significantly enhances the performance of existing mainstream KV Cache methods' is unsupported by any quantitative metrics, baselines, datasets, ablation studies, error bars, or implementation details. Without these, the central empirical claim cannot be evaluated.
- [Abstract] Abstract: the core assumption that 'the wavelet transform [can] achieve precise and efficient identification of critical tokens within ultra-long contexts' to build an effective sparse KV cache is stated without derivation, justification for its suitability to discrete token embeddings or attention maps (as opposed to continuous signals), or analysis of failure cases when token importance is not frequency-localized.
Simulated Author's Rebuttal
We thank the referee for their comments. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experimental results demonstrate that WaveFilter... significantly enhances the performance of existing mainstream KV Cache methods' is unsupported by any quantitative metrics, baselines, datasets, ablation studies, error bars, or implementation details. Without these, the central empirical claim cannot be evaluated.
Authors: We agree the abstract, as a concise summary, omits specific quantitative details. The full manuscript reports these in the Experiments section, covering datasets, baselines, metrics, ablations, and implementation. We will revise the abstract to include representative quantitative results supporting the claim. revision: yes
-
Referee: [Abstract] Abstract: the core assumption that 'the wavelet transform [can] achieve precise and efficient identification of critical tokens within ultra-long contexts' to build an effective sparse KV cache is stated without derivation, justification for its suitability to discrete token embeddings or attention maps (as opposed to continuous signals), or analysis of failure cases when token importance is not frequency-localized.
Authors: The abstract summarizes the approach; the derivation, justification for applying wavelets to token embeddings (treated as signals via their continuous vector representations) and attention maps, and rationale for multi-scale frequency localization are detailed in the Methods section. The manuscript discusses limitations, but we will add a brief explicit note on potential failure cases where importance is not frequency-localized. revision: partial
Circularity Check
No circularity: WaveFilter is a proposed empirical framework without self-referential derivations
full rationale
The paper presents WaveFilter as a training-free plug-and-play method that applies wavelet transform to identify critical tokens for sparse KV caching in diffusion LLMs, inspired by human reading. No equations, fitted parameters, predictions, or derivation chains appear in the abstract or described content. The core step (wavelet decomposition for token identification) is introduced as an external technique rather than derived from the paper's own inputs or prior self-citations. No load-bearing self-citation, self-definition, or renaming of known results is present, making the proposal self-contained as a methodological suggestion whose validity rests on future experiments rather than internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large Language Diffusion Models
Shen Nie and Fengqi Zhu and Zebin You and Xiaolu Zhang and Jingyang Ou and Jun Hu and Jun Zhou and Yankai Lin and Ji. Large Language Diffusion Models , journal =. 2025 , url =. doi:10.48550/ARXIV.2502.09992 , eprinttype =. 2502.09992 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992 2025
-
[2]
Sahoo and Aaron Gokaslan and Christopher De Sa and Volodymyr Kuleshov , editor =
Subham S. Sahoo and Aaron Gokaslan and Christopher De Sa and Volodymyr Kuleshov , editor =. Diffusion Models With Learned Adaptive Noise , booktitle =. 2024 , url =
2024
-
[3]
Photorealistic Video Generation with Diffusion Models , booktitle =
Agrim Gupta and Lijun Yu and Kihyuk Sohn and Xiuye Gu and Meera Hahn and Fei. Photorealistic Video Generation with Diffusion Models , booktitle =. 2024 , url =. doi:10.1007/978-3-031-72986-7\_23 , timestamp =
-
[4]
Shansan Gong and Ruixiang Zhang and Huangjie Zheng and Jiatao Gu and Navdeep Jaitly and Lingpeng Kong and Yizhe Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.20639 , eprinttype =. 2506.20639 , timestamp =
-
[5]
Hashimoto , editor =
Xiang Lisa Li and John Thickstun and Ishaan Gulrajani and Percy Liang and Tatsunori B. Hashimoto , editor =. Diffusion-LM Improves Controllable Text Generation , booktitle =. 2022 , url =
2022
-
[6]
A Survey on Diffusion Language Models
Tianyi Li and Mingda Chen and Bowei Guo and Zhiqiang Shen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.10875 , eprinttype =. 2508.10875 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10875 2025
-
[7]
Xinyin Ma and Runpeng Yu and Gongfan Fang and Xinchao Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.15781 , eprinttype =. 2505.15781 , timestamp =
-
[8]
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs , booktitle =
Xiaoran Liu and Yuerong Song and Zhigeng Liu and Zengfeng Huang and Qipeng Guo and Ziwei He and Xipeng Qiu , editor =. LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs , booktitle =. 2026 , url =. doi:10.1609/AAAI.V40I38.40491 , timestamp =
-
[9]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , booktitle =
Jascha Sohl. Deep Unsupervised Learning using Nonequilibrium Thermodynamics , booktitle =. 2015 , url =
2015
-
[10]
Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , editor =
Jacob Austin and Daniel D. Johnson and Jonathan Ho and Daniel Tarlow and Rianne van den Berg , editor =. Structured Denoising Diffusion Models in Discrete State-Spaces , booktitle =. 2021 , url =
2021
-
[11]
A Continuous Time Framework for Discrete Denoising Models , booktitle =
Andrew Campbell and Joe Benton and Valentin De Bortoli and Thomas Rainforth and George Deligiannidis and Arnaud Doucet , editor =. A Continuous Time Framework for Discrete Denoising Models , booktitle =. 2022 , url =
2022
-
[12]
Denoising Diffusion Probabilistic Models , booktitle =
Jonathan Ho and Ajay Jain and Pieter Abbeel , editor =. Denoising Diffusion Probabilistic Models , booktitle =. 2020 , url =
2020
-
[13]
Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning , booktitle =
Ting Yao and Yingwei Pan and Yehao Li and Chong. Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning , booktitle =. 2022 , url =. doi:10.1007/978-3-031-19806-9\_19 , timestamp =
-
[14]
Andrew Kiruluta and Priscilla Burity and Samantha Williams , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.08801 , eprinttype =. 2504.08801 , timestamp =
-
[15]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye and Zhihui Xie and Lin Zheng and Jiahui Gao and Zirui Wu and Xin Jiang and Zhenguo Li and Lingpeng Kong , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.15487 , eprinttype =. 2508.15487 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.15487 2025
-
[16]
Yushi Bai and Xin Lv and Jiajie Zhang and Hongchang Lyu and Jiankai Tang and Zhidian Huang and Zhengxiao Du and Xiao Liu and Aohan Zeng and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , editor =. LongBench:. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V...
-
[17]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2404.06654 , eprinttype =. 2404.06654 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.06654 2024
-
[18]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Chengyue Wu and Hao Zhang and Shuchen Xue and Zhijian Liu and Shizhe Diao and Ligeng Zhu and Ping Luo and Song Han and Enze Xie , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.22618 , eprinttype =. 2505.22618 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.22618 2025
-
[19]
Quan Nguyen. Attention Is All You Need for. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.14973 , eprinttype =. 2510.14973 , timestamp =
-
[20]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[21]
Generative Modeling by Estimating Gradients of the Data Distribution , booktitle =
Yang Song and Stefano Ermon , editor =. Generative Modeling by Estimating Gradients of the Data Distribution , booktitle =. 2019 , url =
2019
-
[22]
Diffusion Models Beat GANs on Image Synthesis , booktitle =
Prafulla Dhariwal and Alexander Quinn Nichol , editor =. Diffusion Models Beat GANs on Image Synthesis , booktitle =. 2021 , url =
2021
-
[23]
The Eleventh International Conference on Learning Representations,
Shansan Gong and Mukai Li and Jiangtao Feng and Zhiyong Wu and Lingpeng Kong , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[24]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , booktitle =
Aaron Lou and Chenlin Meng and Stefano Ermon , editor =. Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , booktitle =. 2024 , url =
2024
-
[25]
Argmax Flows and Multinomial Diffusion: Learning Categorical Distributions , booktitle =
Emiel Hoogeboom and Didrik Nielsen and Priyank Jaini and Patrick Forr. Argmax Flows and Multinomial Diffusion: Learning Categorical Distributions , booktitle =. 2021 , url =
2021
-
[26]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
An Yang and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chengyuan Li and Dayiheng Liu and Fei Huang and Haoran Wei and Huan Lin and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Yang and Jiaxi Yang and Jingren Zhou and Junyang Lin and Kai Dang and Keming Lu and Keqin Bao and Kexin Yang and Le Yu and Mei Li and Mi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[28]
Zhenyu Zhang and Ying Sheng and Tianyi Zhou and Tianlong Chen and Lianmin Zheng and Ruisi Cai and Zhao Song and Yuandong Tian and Christopher R. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
2023
-
[29]
The Thirteenth International Conference on Learning Representations,
Guangxuan Xiao and Jiaming Tang and Jingwei Zuo and Junxian Guo and Shang Yang and Haotian Tang and Yao Fu and Song Han , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[30]
Yuhong Li and Yingbing Huang and Bowen Yang and Bharat Venkitesh and Acyr Locatelli and Hanchen Ye and Tianle Cai and Patrick Lewis and Deming Chen , editor =. SnapKV:. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[31]
The Twelfth International Conference on Learning Representations,
Guangxuan Xiao and Yuandong Tian and Beidi Chen and Song Han and Mike Lewis , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[32]
Tensor Product Attention Is All You Need , journal =
Yifan Zhang and Yifeng Liu and Huizhuo Yuan and Zhen Qin and Yang Yuan and Quanquan Gu and Andrew Chi. Tensor Product Attention Is All You Need , journal =. 2025 , url =. doi:10.48550/ARXIV.2501.06425 , eprinttype =. 2501.06425 , timestamp =
-
[33]
copy” case: P(Zu =Z v = 1) =p . Under the “independent
Xinyin Ma and Gongfan Fang and Xinchao Wang , title =. 2024 , url =. doi:10.1109/CVPR52733.2024.01492 , timestamp =
-
[34]
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching
Zhiyuan Liu and Yicun Yang and Yaojie Zhang and Junjie Chen and Chang Zou and Qingyuan Wei and Shaobo Wang and Linfeng Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.06295 , eprinttype =. 2506.06295 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.06295 2025
-
[35]
Fast- dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025a
Chengyue Wu and Hao Zhang and Shuchen Xue and Shizhe Diao and Yonggan Fu and Zhijian Liu and Pavlo O. Molchanov and Ping Luo and Song Han and Enze Xie , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.26328 , eprinttype =. 2509.26328 , timestamp =
-
[36]
Sparse-dLLM: Accelerating Diffusion LLMs with Dynamic Cache Eviction , booktitle =
Yuerong Song and Xiaoran Liu and Ruixiao Li and Zhigeng Liu and Zengfeng Huang and Qipeng Guo and Ziwei He and Xipeng Qiu , editor =. Sparse-dLLM: Accelerating Diffusion LLMs with Dynamic Cache Eviction , booktitle =. 2026 , url =. doi:10.1609/AAAI.V40I39.40586 , timestamp =
-
[37]
Yuchu Jiang and Yue Cai and Xiangzhong Luo and Jiale Fu and Jiarui Wang and Chonghan Liu and Xu Yang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.23094 , eprinttype =. 2509.23094 , timestamp =
-
[38]
Sahoo and Marianne Arriola and Yair Schiff and Aaron Gokaslan and Edgar Marroquin and Justin T
Subham S. Sahoo and Marianne Arriola and Yair Schiff and Aaron Gokaslan and Edgar Marroquin and Justin T. Chiu and Alexander Rush and Volodymyr Kuleshov , editor =. Simple and Effective Masked Diffusion Language Models , booktitle =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.