Internalize the Temperature: On-Policy Self-Distillation as Policy Reheater for Reinforcement Learning
Pith reviewed 2026-06-28 18:47 UTC · model grok-4.3
The pith
Temperature-scaled on-policy self-distillation restores entropy in collapsed RL policies for language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
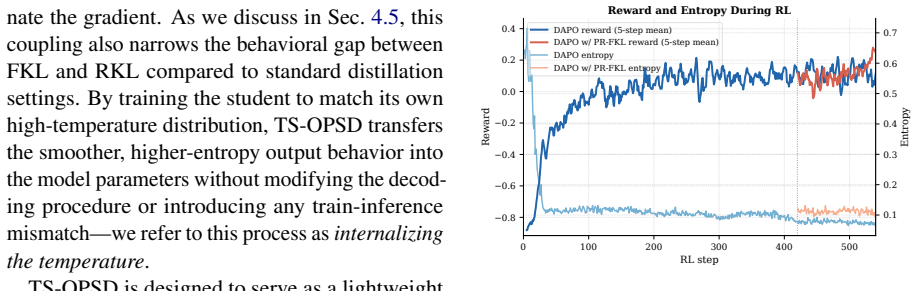
Starting from an entropy-collapsed RL checkpoint, TS-OPSD constructs a self-teacher by applying high-temperature scaling to the model's own logits and distills the smoother distribution back into the student model. This internalizes the temperature effect, requiring no external teacher or additional inference cost during training.
What carries the argument
Temperature-Scaled On-Policy Self-Distillation (TS-OPSD), the process of using high-temperature scaled self-logits as a teacher signal for distillation to reheat the policy parameters.
If this is right
- Policy reheating via TS-OPSD yields stronger initialization for continued RL than standard continued RL.
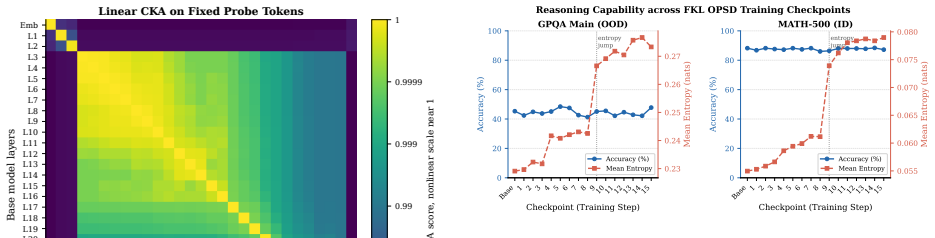
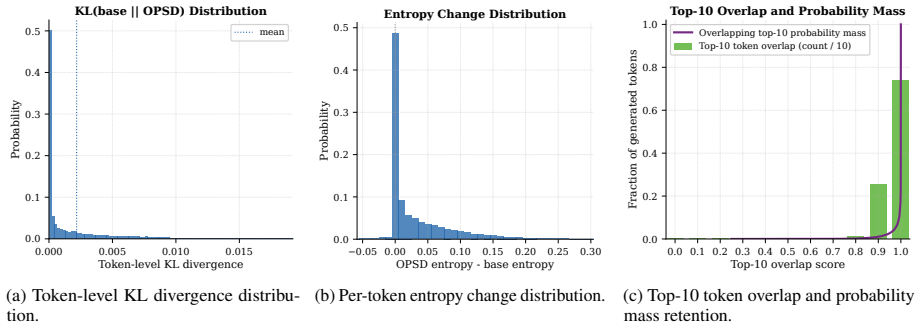
- TS-OPSD reduces output sharpness while preserving intermediate representations, top candidate sets, and reasoning capability.
- Entropy restoration serves as a simple post-collapse intervention for extending reasoning-oriented RL.
Where Pith is reading between the lines
- The method could be applied periodically during RL training to prevent collapse rather than only as a post-hoc fix.
- Similar self-distillation might help in other domains where policy entropy needs restoration without changing the objective.
- Since it preserves reasoning capability, it may allow scaling RL to longer horizons or more complex verifiable reward tasks.
Load-bearing premise
Distilling from high-temperature scaled versions of the model's own logits produces a useful teacher signal that restores entropy without degrading the underlying reasoning capability or intermediate representations.
What would settle it
A direct comparison where a model reheated with TS-OPSD shows no improvement or worse performance in subsequent RL training on the same verifiable reward tasks compared to a baseline without reheating.
Figures







read the original abstract
Reinforcement learning from verifiable rewards improves the reasoning ability of large language models, but often suffers from entropy collapse, in which increasingly concentrated policies reduce rollout diversity and useful learning signals. Existing remedies either constrain the RL objective (e.g., entropy regularization) or adjust sampling temperature during rollout collection, but these interventions remain external to the model parameters. We propose Temperature-Scaled On-Policy Self-Distillation (TS-OPSD), a lightweight policy reheating method that internalizes the exploratory effect of temperature into model parameters. Starting from an entropy-collapsed RL checkpoint, TS-OPSD constructs a self-teacher by applying high-temperature scaling to the model's own logits, then distills the resulting smoother distribution back into the student. This policy reheating requires no external teacher, privileged data, or additional inference cost. Experiments on Qwen3-4B-Base and Qwen3-8B-Base show that policy reheating yields a stronger initialization for continued RL than both standard continued RL and rollout-level temperature reheating. Further analyses show that TS-OPSD mainly reduces output sharpness while preserving intermediate representations, top candidate sets, and reasoning capability. These results suggest that entropy restoration can serve as a simple post-collapse intervention for extending reasoning-oriented RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Temperature-Scaled On-Policy Self-Distillation (TS-OPSD) to address entropy collapse in RL for LLM reasoning. Starting from a collapsed checkpoint, it constructs a self-teacher by high-temperature scaling of the model's own logits and distills the smoother distribution back into the parameters. This internalizes the exploratory effect of temperature without external teachers or extra inference cost. Experiments on Qwen3-4B-Base and Qwen3-8B-Base claim that the resulting checkpoint is a stronger initialization for continued RL than either standard continued RL or rollout-level temperature reheating. Analyses indicate that TS-OPSD reduces output sharpness while preserving intermediate representations, top candidate sets, and reasoning capability.
Significance. If the central experimental claim holds, the method offers a lightweight, parameter-internal post-collapse intervention that could extend the usable horizon of reasoning-oriented RL without modifying the RL objective or incurring rollout overhead. The self-distillation approach is notable for requiring no privileged data or additional models.
major comments (2)
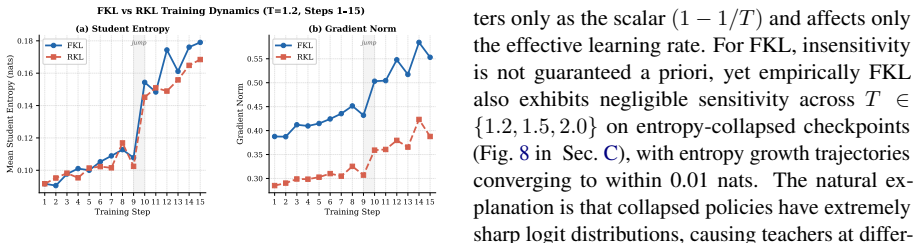
- [Analyses] The headline claim that TS-OPSD yields a stronger initialization rests on the assumption that high-T self-distillation from collapsed logits produces a net-positive teacher signal. The analyses section must provide quantitative evidence (e.g., token-distribution divergence metrics or entropy curves post-distillation) showing that the softened distribution restores exploitable diversity rather than merely rescaling the same narrow token set; without this, the superiority over rollout-temperature baselines cannot be secured.
- [Experiments] Experiments section: the reported superiority on Qwen3-4B-Base and Qwen3-8B-Base requires explicit controls for the RL training budget, reward model, and evaluation metrics used to declare a 'stronger initialization.' The current description lacks statistical significance tests or variance across seeds, which is load-bearing for the cross-method comparison.
minor comments (2)
- [Introduction] The abstract and introduction should clarify whether the high-temperature scaling is applied only at the final layer or throughout the network, as this affects the interpretation of 'internalizing' the temperature.
- [Method] Notation for the temperature-scaled logits and the distillation loss should be introduced with explicit equations to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each of the major comments below and indicate the revisions we plan to make to the manuscript.
read point-by-point responses
-
Referee: [Analyses] The headline claim that TS-OPSD yields a stronger initialization rests on the assumption that high-T self-distillation from collapsed logits produces a net-positive teacher signal. The analyses section must provide quantitative evidence (e.g., token-distribution divergence metrics or entropy curves post-distillation) showing that the softened distribution restores exploitable diversity rather than merely rescaling the same narrow token set; without this, the superiority over rollout-temperature baselines cannot be secured.
Authors: We agree that providing explicit quantitative evidence on the effect of the self-distillation would strengthen the paper. Our existing analyses already show that TS-OPSD reduces output sharpness while preserving intermediate representations, top candidate sets, and reasoning capability, which suggests the softened distribution is not merely rescaling but maintaining useful structure. However, to directly address the referee's concern, we will add token-distribution divergence metrics and entropy curves in the revised Analyses section to quantify the restoration of diversity. revision: yes
-
Referee: [Experiments] Experiments section: the reported superiority on Qwen3-4B-Base and Qwen3-8B-Base requires explicit controls for the RL training budget, reward model, and evaluation metrics used to declare a 'stronger initialization.' The current description lacks statistical significance tests or variance across seeds, which is load-bearing for the cross-method comparison.
Authors: We will revise the Experiments section to provide explicit details on the RL training budget, reward model, and evaluation metrics. We acknowledge that statistical significance tests and variance across seeds are not currently reported. In the revision, we will include multi-seed results and appropriate statistical tests to support the comparisons, thereby making the claims more robust. revision: yes
Circularity Check
No circularity; method is procedural with no derivations or self-referential reductions
full rationale
The paper describes TS-OPSD as a post-hoc empirical intervention (high-T scaling of own logits followed by distillation) with no equations, first-principles derivations, or predictions that reduce to fitted inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central claim. Experimental comparisons to baselines are presented directly without statistical forcing or renaming of known results. The derivation chain is empty of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InInternational Conference on Learning Representations, volume 2024, pages 21246–21263
On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, volume 2024, pages 21246–21263. Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Xin Zhao, Zhenliang Zhang, and Furu Wei
2024
-
[2]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
The entropy mechanism of rein- forcement learning for reasoning language models. Preprint, arXiv:2505.22617. Haoran Dang, Cuiling Lan, Hai Wan, Xibin Zhao, and Yan Lu
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao
A unified revisit of temperature in classification-based knowledge distil- lation.Preprint, arXiv:2603.02430. Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao
-
[4]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Revisiting on-policy distillation: Empirical failure modes and simple fixes.Preprint, arXiv:2603.25562. Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
MiniLLM: On-Policy Distillation of Large Language Models
Minillm: On-policy distillation of large language models.Preprint, arXiv:2306.08543. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhu- oshu Li, Ziyi Gao, Aixin Liu, and 175 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network. Preprint, arXiv:1503.02531. Jonas Hübotter, Frederike Lübeck, Lejs Behric, An- ton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Reinforcement Learning via Self-Distillation
Re- inforcement learning via self-distillation.Preprint, arXiv:2601.20802. Aref Jafari, Mehdi Rezagholizadeh, Pranav Sharma, and Ali Ghodsi
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Entropy-aware on-policy distillation of language models.Preprint, arXiv:2603.07079. S. Kullback and R. A. Leibler
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Rethinking on-policy distillation of large lan- guage models: Phenomenology, mechanism, and recipe.Preprint, arXiv:2604.13016. Zheng Li, Xiang Li, Lingfeng Yang, Borui Zhao, Renjie Song, Lei Luo, Jun Li, and Jian Yang
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Entropy-preserving rein- forcement learning.Preprint, arXiv:2603.11682. David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Di- rani, Julian Michael, and Samuel R. Bowman
-
[11]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a bench- mark.Preprint, arXiv:2311.12022. Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Crisp: Com- pressed reasoning via iterative self-policy distillation. Preprint, arXiv:2603.05433. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Preprint, arXiv:2402.03300. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Challeng- ing the boundaries of reasoning: An olympiad-level math benchmark for large language models.Preprint, arXiv:2503.21380. Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shix- uan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Dynamic Temperature Knowledge Distillation , url =
Dynamic temperature knowledge distillation.Preprint, arXiv:2404.12711. Yuqiao Wen, Zichao Li, Wenyu Du, and Lili Mou
-
[16]
f-divergence minimization for sequence-level knowl- edge distillation. InProceedings of the 61st An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10817– 10834, Toronto, Canada. Association for Computa- tional Linguistics. Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, and Ngai Wong. 2025a. Re...
-
[17]
Bapo: Stabilizing off-policy reinforcement learning for llms via balanced policy optimization with adap- tive clipping.Preprint, arXiv:2510.18927. Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan
-
[18]
Self-distilled rlvr. Preprint, arXiv:2604.03128. Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
On-policy context distillation for language models.Preprint, arXiv:2602.12275. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gao- hong Liu, juncai liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, and 17 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Edt: Improving large language models’ generation by entropy-based dynamic temperature sampling. Preprint, arXiv:2403.14541. Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover
-
[21]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-distilled reasoner: On-policy self-distillation for large language models.Preprint, arXiv:2601.18734. Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Hong Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Swift: a scalable lightweight infras- tructure for fine-tuning
Swift:a scalable lightweight infrastructure for fine-tuning.Preprint, arXiv:2408.05517. Yixiao Zhou, Yang Li, Dongzhou Cheng, Hehe Fan, and Yu Cheng
-
[23]
10 A Hyperparameters A.1 RL Training (DAPO) We use DAPO (Yu et al.,
Look inward to explore outward: Learning temperature policy from llm internal states via hierarchical rl.Preprint, arXiv:2602.13035. 10 A Hyperparameters A.1 RL Training (DAPO) We use DAPO (Yu et al.,
-
[24]
Table 3 lists the shared hyperparameters for Qwen3-4B-Base and Qwen3- 8B-Base; the two models use identical settings un- less otherwise noted
as the base RL pro- cedure for all experiments, implemented on top of verl (Sheng et al., 2025). Table 3 lists the shared hyperparameters for Qwen3-4B-Base and Qwen3- 8B-Base; the two models use identical settings un- less otherwise noted. Hyperparameter Value Framework verl Training data DAPO-Math-17K Optimizer AdamW Learning rate 2e-6 LR warmup steps 10...
2025
-
[25]
The global cosine similarity between ∆low and −∆high is −0.878, indicating strong directional anti-alignment that cannot arise by chance in an 8B-parameter space. The reverse projection co- efficient of 0.891 shows that the low-temperature update recovers approximately 89% of the high- temperature displacement in the anti-aligned direc- tion, and the norm...
2048
-
[26]
to enable a fair per-sample comparison. ity and quantity of training prompts: data scarcity is a genuine bottleneck in RL-based post-training, par- ticularly for larger models that require more diverse and challenging prompts to sustain a meaningful gradient signal. To probe the robustness of policy reheating in this regime, we construct a data-scarce set...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.