FALAT: Tracing Failures in LLM Agent Trajectories via Dependency-Guided Search
Pith reviewed 2026-06-28 18:37 UTC · model grok-4.3
The pith
FALAT frames failure attribution in LLM agent trajectories as dependency-guided search that first builds an expected solution path then isolates the decisive error-introducing step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
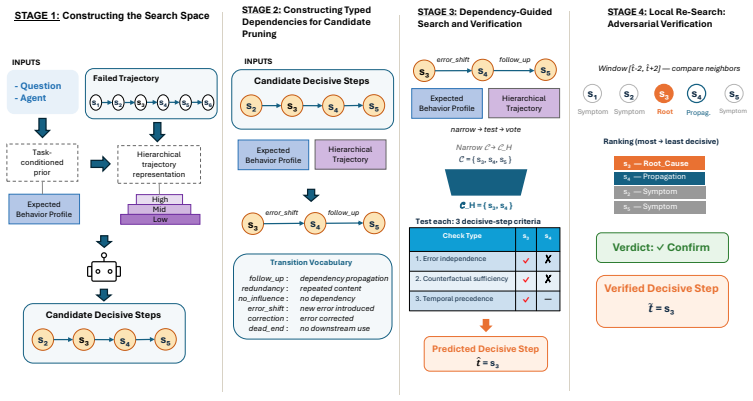
FALAT frames attribution as a dependency-guided search problem. It first constructs an expectation of how the task should be solved and uses this expectation to identify suspicious regions in the trajectory. It then traces dependencies among decisions, tool outputs, and agent messages to distinguish error-introducing steps from steps that merely inherit or propagate prior mistakes. Finally, FALAT evaluates whether correcting a candidate step would be sufficient to recover the expected outcome, allowing it to identify both the responsible agent and the decisive failure step.
What carries the argument
Dependency-guided search that constructs an expected solution path, locates suspicious regions, traces decision dependencies, and tests outcome recovery after hypothetical correction.
If this is right
- Responsible-agent and decisive-step attribution both improve over baselines that ignore dependencies.
- The same search procedure works on both algorithm-generated and hand-crafted multi-agent failure trajectories.
- Direct prompting of standalone LLMs is outperformed once dependency tracing and recovery testing are added.
- Dependency-aware reasoning is required for reliable diagnosis rather than independent step classification.
Where Pith is reading between the lines
- The approach could be applied to logged trajectories from deployed agent systems without requiring new benchmarks.
- Identifying common decisive steps across many runs might reveal recurring failure patterns that could be mitigated at design time.
- The expectation-construction step might itself become a point of failure when tasks lack a single canonical solution path.
- Combining the search with execution replay could allow automated repair suggestions beyond mere attribution.
Load-bearing premise
An accurate expectation of the correct task solution can be constructed and then used to reliably flag suspicious regions and to judge whether fixing a step restores the expected outcome.
What would settle it
A controlled test set of trajectories where the constructed expectation is deliberately inaccurate yet FALAT is still run; if attribution accuracy remains high the central mechanism is not doing the claimed work.
Figures
read the original abstract
LLM-based agents increasingly solve complex tasks through long trajectories involving reasoning steps, tool calls, and inter-agent communication. However, when these agents fail, it is often unclear which agent caused the failure and which step introduced the decisive error. This attribution problem is challenging because mistakes can propagate across the trajectory: later actions may appear incorrect, but only because they depend on an earlier corrupted state. Therefore, failure attribution cannot be treated as independent step-level classification. We propose FALAT, a diagnostic framework for failure attribution in LLM agent trajectories. FALAT frames attribution as a dependency-guided search problem. It first constructs an expectation of how the task should be solved and uses this expectation to identify suspicious regions in the trajectory. It then traces dependencies among decisions, tool outputs, and agent messages to distinguish error-introducing steps from steps that merely inherit or propagate prior mistakes. Finally, FALAT evaluates whether correcting a candidate step would be sufficient to recover the expected outcome, allowing it to identify both the responsible agent and the decisive failure step. We evaluate FALAT on the Who&When benchmark, which includes both algorithm-generated and hand-crafted multi-agent failure trajectories. The results show that FALAT consistently improves responsible-agent and decisive-step attribution. Its best configurations achieve 46.0% step-level accuracy on algorithm-generated trajectories and 29.1% on the more challenging hand-crafted trajectories, outperforming specialized attribution baselines and direct prompting with standalone LLMs. These findings suggest that dependency-aware reasoning is essential for reliable failure diagnosis in LLM agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FALAT, a diagnostic framework for failure attribution in LLM agent trajectories. It frames attribution as a dependency-guided search: first constructing an expectation of correct task solution to identify suspicious regions, then tracing dependencies among decisions, tool outputs, and messages to distinguish error-introducing steps from propagations, and finally testing whether correcting a candidate step recovers the expected outcome. Evaluated on the Who&When benchmark (algorithm-generated and hand-crafted multi-agent failure trajectories), best configurations achieve 46.0% step-level accuracy on generated trajectories and 29.1% on hand-crafted ones, outperforming specialized attribution baselines and direct LLM prompting.
Significance. If the central results hold after addressing the load-bearing assumption, FALAT would represent a meaningful advance in diagnosing failures in multi-agent LLM systems by moving beyond independent step classification to dependency-aware reasoning. The dual evaluation on algorithm-generated and hand-crafted trajectories is a positive design choice that strengthens the claim that dependency tracing is essential. The work also highlights the distinction between responsible agents and decisive steps, which is a useful conceptual contribution.
major comments (2)
- [Abstract, paragraph 2] Abstract, paragraph 2: The method relies on first constructing an expectation of how the task should be solved to flag suspicious regions and to test recovery upon correction. No mechanism, prompt template, accuracy metric, or validation of this expectation's fidelity on the Who&When benchmark tasks is supplied. This assumption is load-bearing for the reported 29.1% accuracy on hand-crafted trajectories, because systematic bias or incompleteness in the expectation would directly corrupt both suspicious-region identification and the recovery test, rendering the attribution improvements uninterpretable.
- [Evaluation (results paragraph)] Evaluation (results paragraph): The abstract reports 46.0% and 29.1% step-level accuracies and claims outperformance, yet provides no error bars, no description of how the expectation is operationalized, no details on the dependency model, and no information on statistical significance testing or exact baseline implementations. These omissions prevent assessment of whether the numeric gains are robust or merely artifacts of the unvalidated expectation step.
minor comments (2)
- The manuscript should clarify the exact definition of 'responsible-agent' and 'decisive-step' attribution metrics and how they are computed from the dependency trace.
- Add a dedicated subsection describing the Who&When benchmark construction, trajectory lengths, and failure types to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will incorporate the requested clarifications and additional details into a revised manuscript.
read point-by-point responses
-
Referee: [Abstract, paragraph 2] Abstract, paragraph 2: The method relies on first constructing an expectation of how the task should be solved to flag suspicious regions and to test recovery upon correction. No mechanism, prompt template, accuracy metric, or validation of this expectation's fidelity on the Who&When benchmark tasks is supplied. This assumption is load-bearing for the reported 29.1% accuracy on hand-crafted trajectories, because systematic bias or incompleteness in the expectation would directly corrupt both suspicious-region identification and the recovery test, rendering the attribution improvements uninterpretable.
Authors: We agree that the manuscript currently describes expectation construction only at a high level and does not supply the requested implementation details or validation. In the revision we will add a new subsection under Methods that specifies: (1) the exact mechanism (LLM-based generation of a reference solution trajectory), (2) the full prompt templates used, (3) the accuracy metric applied to measure fidelity against ground-truth solutions on Who&When tasks, and (4) quantitative validation results on both algorithm-generated and hand-crafted subsets. These additions will directly address the load-bearing concern and allow readers to assess potential bias. revision: yes
-
Referee: [Evaluation (results paragraph)] Evaluation (results paragraph): The abstract reports 46.0% and 29.1% step-level accuracies and claims outperformance, yet provides no error bars, no description of how the expectation is operationalized, no details on the dependency model, and no information on statistical significance testing or exact baseline implementations. These omissions prevent assessment of whether the numeric gains are robust or merely artifacts of the unvalidated expectation step.
Authors: We concur that the current presentation lacks these elements. The revised manuscript will add: error bars (standard deviation across five independent runs with different seeds), an explicit operationalization of the expectation step (cross-referenced to the new Methods subsection), a precise description of the dependency model (including how dependency edges are extracted and represented), statistical significance tests (paired t-tests with p-values against each baseline), and exact baseline re-implementation details (model versions, prompting strategies, and hyper-parameters). These changes will enable evaluation of robustness. revision: yes
Circularity Check
No significant circularity; algorithmic procedure is self-contained
full rationale
The paper describes FALAT as a sequence of algorithmic steps: constructing an expectation of correct task solution, identifying suspicious regions, tracing dependencies, and testing recovery of the expected outcome. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text. The expectation is treated as an external input constructed prior to dependency tracing rather than defined in terms of the attribution output. No step reduces by construction to its own inputs, satisfying the default expectation that most papers lack circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 42nd International Conference on Machine Learning , year =
Zhang, Shaokun and Yin, Ming and Zhang, Jieyu and Liu, Jiale and Han, Zhiguang and Zhang, Jingyang and Li, Beibin and Wang, Chi and Wang, Huazheng and Chen, Yiran and Wu, Qingyun , title =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[2]
IEEE Transactions on software engineering , volume=
How effective developers investigate source code: An exploratory study , author=. IEEE Transactions on software engineering , volume=
-
[3]
Proceedings of the 30th international conference on Software engineering , pages=
Debugging reinvented: asking and answering why and why not questions about program behavior , author=. Proceedings of the 30th international conference on Software engineering , pages=
-
[4]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[5]
arXiv preprint arXiv:2509.25370 , year=
Where llm agents fail and how they can learn from failures , author=. arXiv preprint arXiv:2509.25370 , year=
-
[6]
arXiv preprint arXiv:2505.00212 , year=
Which agent causes task failures and when? on automated failure attribution of llm multi-agent systems , author=. arXiv preprint arXiv:2505.00212 , year=
-
[7]
From Flat Logs to Causal Graphs: Hierarchical Failure Attribution for LLM-based Multi-Agent Systems , author=. arXiv preprint arXiv:2602.23701 , year=
-
[8]
arXiv preprint arXiv:2506.18824 , year=
Understanding software engineering agents: A study of thought-action-result trajectories , author=. arXiv preprint arXiv:2506.18824 , year=
-
[9]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the 48th international conference on Software engineering , year=
Order Matters! An Empirical Study on Large Language Models' Input Order Bias in Software Fault Localization , author=. Proceedings of the 48th international conference on Software engineering , year=
-
[11]
Who is introducing the failure? automatically attributing failures of multi-agent systems via spectrum analysis , author=. arXiv preprint arXiv:2509.13782 , year=
-
[12]
arXiv preprint arXiv:2510.04550 , year=
TRAJECT-Bench: A Trajectory-Aware Benchmark for Evaluating Agentic Tool Use , author=. arXiv preprint arXiv:2510.04550 , year=
-
[13]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
AgentDiagnose: An Open Toolkit for Diagnosing LLM Agent Trajectories , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2025
-
[14]
Diagnosing with Insights: Structured Analysis of Agent Failures via Behavioral Abstractions , author=
-
[15]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Trial and error: Exploration-based trajectory optimization of LLM agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[16]
arXiv preprint arXiv:2505.13652 , year=
Guided Search Strategies in Non-Serializable Environments with Applications to Software Engineering Agents , author=. arXiv preprint arXiv:2505.13652 , year=
-
[17]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Metareflection: Learning instructions for language agents using past reflections , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[18]
Proceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025) , pages=
From knowledge to noise: CTIM-rover and the pitfalls of episodic memory in software engineering agents , author=. Proceedings of the 1st Workshop for Research on Agent Language Models (REALM 2025) , pages=
2025
-
[19]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Utboost: Rigorous evaluation of coding agents on swe-bench , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[21]
Agent workflow memory , author=. arXiv preprint arXiv:2409.07429 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2511.05931 , year=
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement , author=. arXiv preprint arXiv:2511.05931 , year=
-
[23]
Agentracer: Who is inducing failure in the llm agentic systems?arXiv preprint arXiv:2509.03312, 2025
AgenTracer: Who Is Inducing Failure in the LLM Agentic Systems? , author=. arXiv preprint arXiv:2509.03312 , year=
-
[24]
arXiv preprint arXiv:2510.04886 , year=
Where did it all go wrong? A hierarchical look into multi-agent error attribution , author=. arXiv preprint arXiv:2510.04886 , year=
-
[25]
arXiv preprint , year=
When Only the Final Text Survives: Implicit Execution Tracing for Multi-Agent Attribution , author=. arXiv preprint , year=
-
[26]
arXiv preprint arXiv:2510.10581 , year=
GraphTracer: Graph-Guided Failure Tracing in LLM Agents for Robust Multi-Turn Deep Search , author=. arXiv preprint arXiv:2510.10581 , year=
-
[27]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
FAMA: Failure-Aware Meta-Agentic Framework for Open-Source LLMs in Interactive Tool Use Environments
FAMA: Failure-Aware Meta-Agentic Framework for Open-Source LLMs in Interactive Tool Use Environments , author=. arXiv preprint arXiv:2604.25135 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Towards Self-Improving Error Diagnosis in Multi-Agent Systems
Towards Self-Improving Error Diagnosis in Multi-Agent Systems , author=. arXiv preprint arXiv:2604.17658 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
arXiv preprint arXiv:2603.17187 , year=
MetaClaw: Just Talk--An Agent That Meta-Learns and Evolves in the Wild , author=. arXiv preprint arXiv:2603.17187 , year=
-
[31]
Advances in neural information processing systems , volume=
Camel: Communicative agents for" mind" exploration of large language model society , author=. Advances in neural information processing systems , volume=
-
[32]
First conference on language modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First conference on language modeling , year=
-
[33]
The twelfth international conference on learning representations , year=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. The twelfth international conference on learning representations , year=
-
[34]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Chatdev: Communicative agents for software development , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[35]
Forty-first International Conference on Machine Learning , year=
Gptswarm: Language agents as optimizable graphs , author=. Forty-first International Conference on Machine Learning , year=
-
[36]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Dspy: Compiling declarative language model calls into self-improving pipelines , author=. arXiv preprint arXiv:2310.03714 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
TextGrad: Automatic "Differentiation" via Text
Textgrad: Automatic" differentiation" via text , author=. arXiv preprint arXiv:2406.07496 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
arXiv preprint arXiv:2502.14815 , year=
Optimizing model selection for compound ai systems , author=. arXiv preprint arXiv:2502.14815 , year=
-
[39]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Masrouter: Learning to route llms for multi-agent systems , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[40]
arXiv preprint arXiv:2506.02951 , year=
Adaptive graph pruning for multi-agent communication , author=. arXiv preprint arXiv:2506.02951 , year=
-
[41]
AFlow: Automating Agentic Workflow Generation
Aflow: Automating agentic workflow generation , author=. arXiv preprint arXiv:2410.10762 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Automated Design of Agentic Systems
Automated design of agentic systems , author=. arXiv preprint arXiv:2408.08435 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2502.04180 , year=
Multi-agent architecture search via agentic supernet , author=. arXiv preprint arXiv:2502.04180 , year=
-
[44]
arXiv preprint arXiv:2502.07373 , year=
Evoflow: Evolving diverse agentic workflows on the fly , author=. arXiv preprint arXiv:2502.07373 , year=
-
[45]
Augmented Language Models: a Survey
Augmented language models: a survey , author=. arXiv preprint arXiv:2302.07842 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
The Twelfth International Conference on Learning Representations , year=
Gaia: a benchmark for general ai assistants , author=. The Twelfth International Conference on Learning Representations , year=
-
[47]
AI communications , volume=
Case-based reasoning: Foundational issues, methodological variations, and system approaches , author=. AI communications , volume=
-
[48]
European Workshop on Advances in Case-Based Reasoning , pages=
On the role of abstraction in case-based reasoning , author=. European Workshop on Advances in Case-Based Reasoning , pages=
-
[49]
International Conference on Case-Based Reasoning , pages=
Stratified case-based reasoning in non-refinable abstraction hierarchies , author=. International Conference on Case-Based Reasoning , pages=
-
[50]
Artificial intelligence , volume=
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning , author=. Artificial intelligence , volume=. 1999 , publisher=
1999
-
[51]
Artificial intelligence , volume=
Planning in a hierarchy of abstraction spaces , author=. Artificial intelligence , volume=. 1974 , publisher=
1974
-
[52]
If Thinking
“If Thinking” Support System for Training Historical Thinking , author=. Procedia Computer Science , volume=. 2015 , publisher=
2015
-
[53]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Agent-SAMA: State-Aware Mobile Assistant , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[54]
Adaptive in-conversation team building for language model agents , author=. arXiv preprint arXiv:2405.19425 , year=
-
[55]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Assistantbench: Can web agents solve realistic and time-consuming tasks? , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[56]
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Magentic-one: A generalist multi-agent system for solving complex tasks , author=. arXiv preprint arXiv:2411.04468 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Claude Sonnet , year =
-
[61]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
GPT-4.1 Model Documentation , year =
-
[63]
2026 , howpublished =
OpenAI , title =. 2026 , howpublished =
2026
-
[64]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Deepseek-v3. 2: Pushing the frontier of open large language models , author=. arXiv preprint arXiv:2512.02556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
2025 , howpublished =
MiniMax M2.5: Built for Real-World Productivity , author =. 2025 , howpublished =
2025
-
[66]
Anonymous , title =. 2026 , publisher =. doi:10.5281/zenodo.20060709 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.