CV-Arena: An Open Benchmark for Instructional Computer Vision Problem Solving with Human-AI Collaborative Preferences
Pith reviewed 2026-06-28 18:35 UTC · model grok-4.3
The pith
CV-Arena benchmark reveals persistent gaps in AI models for instruction-guided real-image editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
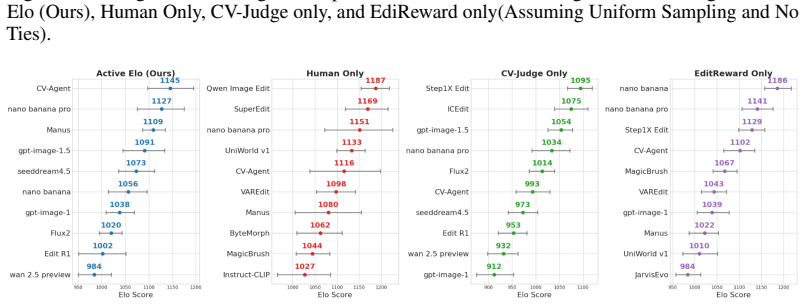
Instructional computer vision problem solving on real images requires satisfying multiple explicit constraints beyond simple appearance changes. CV-Arena supplies 12K traceable instruction pairs spanning 16 task types. Active Elo aggregates reliability-weighted human and AI preferences by letting a multi-dimensional VLM evaluator reject clear failures and route close comparisons to experts. Evaluation of 21 proprietary, open-source, and agentic systems on this benchmark shows consistent shortfalls in instruction adherence, physical reasoning, structural control, and detail preservation. CV-Agent, which interleaves planning, editing, and verification, indicates that closed-loop reasoning impr
What carries the argument
CV-Arena benchmark of 12K real-image instruction pairs evaluated through the Active Elo protocol, which combines a logic-gated VLM judge with selective human review.
If this is right
- Current models require targeted advances in physical reasoning to handle realistic image transformations.
- Structural control and fine-grained detail preservation remain unreliable even in the strongest systems tested.
- Agentic designs that close the loop with planning and verification steps improve instruction following on the benchmark tasks.
- Hybrid human-AI preference collection via Active Elo enables scalable yet high-fidelity evaluation of editing systems.
Where Pith is reading between the lines
- If the 16 task types capture core professional needs, similar retrieval pipelines could be applied to create benchmarks for video or 3D editing.
- The reliability-weighted Elo updates used here could reduce labeling costs when evaluating other generative systems such as text-to-image or code generation.
- Persistent gaps across model classes suggest that simply scaling existing architectures may not close the distance to professional-grade performance.
- Integrating explicit verification steps into deployed editing tools could raise reliability without requiring full model retraining.
Load-bearing premise
The CogRetriever pipeline produces instruction pairs that are representative of professional workflows and free of systematic bias in task distribution or image selection.
What would settle it
A single model that scores near ceiling across all 16 task types on CV-Arena and also succeeds on an independent set of real professional editing jobs would falsify the claim of persistent gaps.
Figures






read the original abstract
Instruction-guided image editing is becoming a general interface for visual work, yet existing benchmarks still focus largely on narrow appearance edits and do not fully capture the diversity of real-image tasks in professional workflows. Here, we define instructional computer vision problem solving as a broader formulation of image editing: given a real input image and a natural-language instruction, a system must produce an edited output that realizes the requested transformation while satisfying explicit preservation, geometric, physical, and usability constraints. We introduce CV-Arena, an open benchmark designed to evaluate this capability at professional scales. CV-Arena contains 12K high-resolution real-image instruction pairs spanning 16 instruction-based visual task types, constructed using CogRetriever, a dual-track retrieval-and-curation pipeline that combines targeted web search, agentic query refinement, verification, and traceability. To evaluate models at scale while preserving human fidelity, we propose Active Elo, a human-AI collaborative preference protocol that leverages CV-Judge, a logic-gated, multi-dimensional VLM evaluator, to reject clear failures and resolve high-confidence comparisons; and to route close, high-quality comparisons to expert raters. Mixed human and AI supervision is then aggregated through reliability-weighted Elo updates. Our comprehensive evaluation of 21 systems, including proprietary, open-source, and agentic models, on CV-Arena reveals persistent gaps in instruction adherence, physical reasoning, structural control, and fine-grained detail preservation. We further develop CV-Agent, a lightweight agentic model that combines planning, editing, and verification, and demonstrate that closed-loop reasoning is a promising direction for professional-grade instruction-following visual editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CV-Arena, a benchmark of 12K high-resolution real-image instruction pairs spanning 16 task types for instructional computer vision problem solving (broader than narrow appearance edits, incorporating preservation, geometric, physical, and usability constraints). It describes the CogRetriever dual-track retrieval-and-curation pipeline (targeted web search, agentic refinement, verification, traceability), proposes Active Elo (human-AI collaborative preference protocol using CV-Judge, a logic-gated multi-dimensional VLM evaluator, to route comparisons and aggregate via reliability-weighted Elo), evaluates 21 proprietary/open-source/agentic systems revealing persistent gaps in instruction adherence, physical reasoning, structural control, and detail preservation, and presents CV-Agent (lightweight agentic model with planning/editing/verification) as a promising direction.
Significance. If the benchmark construction and evaluation protocol are validated as representative and reliable, the work supplies a large-scale, open resource that better matches professional image-editing workflows than prior narrow benchmarks; the human-AI hybrid protocol and explicit failure-mode taxonomy could accelerate progress on instruction-following visual models, while the agentic baseline offers a concrete starting point for closed-loop systems.
major comments (2)
- [Abstract / CogRetriever pipeline description] Abstract and § on benchmark construction: the headline claim that evaluation of 21 systems 'reveals persistent gaps in instruction adherence, physical reasoning, structural control, and fine-grained detail preservation' is load-bearing for the paper's contribution, yet no per-task rejection statistics, source-domain entropy, inter-annotator agreement on curation decisions, or comparison against an external professional-editing corpus are supplied to establish that CogRetriever pairs are free of systematic bias or representative of professional workflows.
- [Active Elo and CV-Judge description] Evaluation protocol section: the soundness of the reported gaps depends on Active Elo and CV-Judge; the manuscript supplies no quantitative validation of pair quality, inter-rater agreement statistics, or ablation studies isolating the contribution of the logic-gated VLM rejection step versus full human rating.
minor comments (2)
- [Abstract] The abstract states '12K high-resolution real-image instruction pairs' but does not include a table or figure summarizing the distribution across the 16 task types; adding this would improve reproducibility and allow readers to assess coverage.
- [Method overview] Notation for 'CV-Judge' and 'Active Elo' is introduced without an explicit forward reference to their formal definitions or pseudocode; a dedicated subsection or algorithm box would clarify the multi-dimensional scoring logic.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The two major comments highlight important areas for strengthening the validation of both the benchmark construction and the evaluation protocol. We address each point below and commit to revisions that incorporate the requested quantitative evidence where feasible.
read point-by-point responses
-
Referee: [Abstract / CogRetriever pipeline description] Abstract and § on benchmark construction: the headline claim that evaluation of 21 systems 'reveals persistent gaps in instruction adherence, physical reasoning, structural control, and fine-grained detail preservation' is load-bearing for the paper's contribution, yet no per-task rejection statistics, source-domain entropy, inter-annotator agreement on curation decisions, or comparison against an external professional-editing corpus are supplied to establish that CogRetriever pairs are free of systematic bias or representative of professional workflows.
Authors: We agree that these quantitative details are necessary to fully substantiate the representativeness claim. In the revised manuscript we will add: (i) per-task rejection statistics from the CogRetriever verification stage, (ii) source-domain entropy computed over the 12K pairs, and (iii) inter-annotator agreement (Cohen’s kappa) on the agentic refinement and human verification decisions. For the requested comparison against an external professional-editing corpus, no public corpus matching the 16-task breadth and real-image constraint set currently exists; we will instead provide a qualitative mapping of our task taxonomy to documented professional workflows (e.g., from Adobe, Figma, and photography post-production literature) and report how the 16 categories were derived from those sources. revision: yes
-
Referee: [Active Elo and CV-Judge description] Evaluation protocol section: the soundness of the reported gaps depends on Active Elo and CV-Judge; the manuscript supplies no quantitative validation of pair quality, inter-rater agreement statistics, or ablation studies isolating the contribution of the logic-gated VLM rejection step versus full human rating.
Authors: We concur that empirical validation of the hybrid protocol is essential. The revised version will include: (i) inter-rater agreement (Fleiss’ kappa) between expert human raters and between humans and CV-Judge on a held-out subset of 500 pairs, (ii) pair-quality metrics (e.g., consistency of preference outcomes across repeated judgments), and (iii) an ablation comparing full-human rating against the logic-gated CV-Judge routing in terms of both agreement with final Elo rankings and annotation cost. These additions will directly quantify the reliability of the reported model gaps. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation are self-contained
full rationale
The paper introduces CV-Arena as a new benchmark via the CogRetriever pipeline and evaluates 21 systems using Active Elo with CV-Judge; no mathematical derivations, parameter fittings presented as predictions, or self-citation chains appear in the central claims. The construction pipeline and evaluation protocol are described directly without reducing any result to its own inputs by definition. The reader's assessment of score 1.0 aligns with the absence of any load-bearing circular steps.
Axiom & Free-Parameter Ledger
invented entities (3)
-
CV-Judge
no independent evidence
-
Active Elo
no independent evidence
-
CV-Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[3]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions.2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18392–18402, 2022
2023
-
[4]
Instruction-based image manipulation by watching how things move
Mingdeng Cao, Xuaner Zhang, Yinqiang Zheng, and Zhihao Xia. Instruction-based image manipulation by watching how things move. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2704–2713, 2025
2025
-
[6]
Di Chang, Mingdeng Cao, Yichun Shi, Bo Liu, Shengqu Cai, Shijie Zhou, Weilin Huang, Gordon Wetzstein, Mohammad Soleymani, and Peng Wang. Bytemorph: Benchmarking instruction-guided image editing with non-rigid motions.arXiv preprint arXiv:2506.03107, 2025
-
[7]
Chen, Misha Sra, and Pradeep Sen
Sherry X. Chen, Misha Sra, and Pradeep Sen. Instruct-clip: Improving instruction-guided image editing with automated data refinement using contrastive learning, 2025
2025
-
[8]
Hierarchical integration diffusion model for realistic image deblurring.Advances in neural information processing systems, 36:29114–29125, 2023
Zheng Chen, Yulun Zhang, Ding Liu, Jinjin Gu, Linghe Kong, Xin Yuan, et al. Hierarchical integration diffusion model for realistic image deblurring.Advances in neural information processing systems, 36:29114–29125, 2023
2023
-
[9]
Zhihong Chen, Xuehai Bai, Yang Shi, Chaoyou Fu, Huanyu Zhang, Haotian Wang, Xiaoyan Sun, Zhang Zhang, Liang Wang, Yuanxing Zhang, et al. Opengpt-4o-image: A comprehensive dataset for advanced image generation and editing.arXiv preprint arXiv:2509.24900, 2025
-
[10]
Exploring the naturalness of ai-generated images.arXiv preprint arXiv:2312.05476, 2023
Zijian Chen, Wei Sun, Haoning Wu, Zicheng Zhang, Jun Jia, Zhongpeng Ji, Fengyu Sun, Shangling Jui, Xiongkuo Min, Guangtao Zhai, et al. Exploring the naturalness of ai-generated images.arXiv preprint arXiv:2312.05476, 2023
-
[11]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference.arXiv preprint arXiv:2403.04132, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Wenyan Cong, Jianfu Zhang, Li Niu, Liu Liu, Zhixin Ling, Weiyuan Li, and Liqing Zhang. Image harmonization dataset iharmony4: Hcoco, hadobe5k, hflickr, and hday2night.arXiv preprint arXiv:1908.10526, 2019. 10
-
[14]
Introducing gemini 2.5 flash image, our state-of-the-art image model, 2025
Google DeepMind. Introducing gemini 2.5 flash image, our state-of-the-art image model, 2025
2025
-
[15]
Introducing nano banana pro, 2025
Google DeepMind. Introducing nano banana pro, 2025
2025
-
[16]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[17]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Alpacafarm: A simulation framework for methods that learn from human feedback.Advances in Neural Information Processing Systems, 36:30039–30069, 2023
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy S Liang, and Tatsunori B Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback.Advances in Neural Information Processing Systems, 36:30039–30069, 2023
2023
-
[19]
Image classification based on cnn: a survey.Journal of Cybersecurity and Information Management, 6(1):18–50, 2021
Ahmed A Elngar, Mohamed Arafa, Amar Fathy, Basma Moustafa, Omar Mahmoud, Mohamed Shaban, and Nehal Fawzy. Image classification based on cnn: a survey.Journal of Cybersecurity and Information Management, 6(1):18–50, 2021
2021
-
[20]
Recognition-synergistic scene text editing
Zhengyao Fang, Pengyuan Lyu, Jingjing Wu, Chengquan Zhang, Jun Yu, Guangming Lu, and Wenjie Pei. Recognition-synergistic scene text editing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13104–13113, 2025
2025
-
[21]
prentice hall professional technical reference, 2002
David A Forsyth and Jean Ponce.Computer vision: a modern approach. prentice hall professional technical reference, 2002
2002
-
[22]
Yuying Ge, Sijie Zhao, Chen Li, Yixiao Ge, and Ying Shan. Seed-data-edit technical report: A hybrid dataset for instructional image editing.arXiv preprint arXiv:2405.04007, 2024
-
[23]
Gemini 2.5 pro model card, 2025
Google. Gemini 2.5 pro model card, 2025. Accessed: 2026-01-11
2025
-
[24]
Multi- reward as condition for instruction-based image editing
Xin Gu, Ming Li, Libo Zhang, Fan Chen, Longyin Wen, Tiejian Luo, and Sijie Zhu. Multi- reward as condition for instruction-based image editing. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[25]
Improving visual and downstream performance of low-light enhancer with vision foun- dation models collaboration
Yuxuan Gu, Haoxuan Wang, Pengyang Ling, Zhixiang Wei, Huaian Chen, Yi Jin, and Enhong Chen. Improving visual and downstream performance of low-light enhancer with vision foun- dation models collaboration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16071–16080, 2025
2025
-
[26]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges.arXiv preprint arXiv:2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Clip and complementary methods.Nature Reviews Methods Primers, 1(1):20, 2021
Markus Hafner, Maria Katsantoni, Tino Köster, James Marks, Joyita Mukherjee, Dorothee Staiger, Jernej Ule, and Mihaela Zavolan. Clip and complementary methods.Nature Reviews Methods Primers, 1(1):20, 2021
2021
-
[28]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
2021
-
[29]
Mude Hui, Siwei Yang, Bingchen Zhao, Yichun Shi, Heng Wang, Peng Wang, Yuyin Zhou, and Cihang Xie. Hq-edit: A high-quality dataset for instruction-based image editing.arXiv preprint arXiv:2404.09990, 2024
-
[30]
Grounding degradations in natural language for all-in-one video restoration
Muhammad Kamran Janjua, Amirhosein Ghasemabadi, Kunlin Zhang, Mohammad Salameh, Chao Gao, and Di Niu. Grounding degradations in natural language for all-in-one video restoration. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5734–5743, 2026. 11
2026
-
[31]
Bohan Jia, Wenxuan Huang, Yuntian Tang, Junbo Qiao, Jincheng Liao, Shaosheng Cao, Fei Zhao, Zhaopeng Feng, Zhouhong Gu, Zhenfei Yin, et al. Compbench: Benchmarking complex instruction-guided image editing.arXiv preprint arXiv:2505.12200, 2025
-
[32]
Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024
Dongfu Jiang, Max Ku, Tianle Li, Yuansheng Ni, Shizhuo Sun, Rongqi Fan, and Wenhu Chen. Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024
2024
-
[33]
A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
Maurice G Kendall. A new measure of rank correlation.Biometrika, 30(1-2):81–93, 1938
1938
-
[34]
Orida: Object-centric real-world image composition dataset
Jinwoo Kim, Sangmin Han, Jinho Jeong, Jiwoo Choi, Dongyeoung Kim, and Seon Joo Kim. Orida: Object-centric real-world image composition dataset. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3051–3060, 2025
2025
-
[35]
Peak signal-to-noise ratio revisited: Is simple beautiful? In 2012 Fourth International Workshop on Quality of Multimedia Experience, pages 37–38, 2012
Jari Korhonen and Junyong You. Peak signal-to-noise ratio revisited: Is simple beautiful? In 2012 Fourth International Workshop on Quality of Multimedia Experience, pages 37–38, 2012
2012
-
[36]
Max Ku, Tianle Li, Kai Zhang, Yujie Lu, Xingyu Fu, Wenwen Zhuang, and Wenhu Chen. Imagenhub: Standardizing the evaluation of conditional image generation models.arXiv preprint arXiv:2310.01596, 2023
-
[37]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[38]
The mnist database of handwritten digits.http://yann
Yann LeCun. The mnist database of handwritten digits.http://yann. lecun. com/exdb/mnist/, 1998
1998
-
[39]
Superedit: Rectifying and facilitating supervision for instruction-based image editing
Ming Li, Xin Gu, Fan Chen, Xiaoying Xing, Longyin Wen, Chen Chen, and Sijie Zhu. Superedit: Rectifying and facilitating supervision for instruction-based image editing. 2025
2025
-
[40]
Towards benchmarking and assessing visual naturalness of physical world adversarial attacks
Simin Li, Shuning Zhang, Gujun Chen, Dong Wang, Pu Feng, Jiakai Wang, Aishan Liu, Xin Yi, and Xianglong Liu. Towards benchmarking and assessing visual naturalness of physical world adversarial attacks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12324–12333, 2023
2023
-
[41]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, et al. Uniworld: High-resolution semantic encoders for unified visual understanding and generation.arXiv preprint arXiv:2506.03147, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Yunlong Lin, Linqing Wang, Kunjie Lin, Zixu Lin, Kaixiong Gong, Wenbo Li, Bin Lin, Zhenxi Li, Shiyi Zhang, Yuyang Peng, et al. Jarvisevo: Towards a self-evolving photo editing agent with synergistic editor-evaluator optimization.arXiv preprint arXiv:2511.23002, 2025
-
[43]
Referring image editing: Object-level image editing via referring expressions
Chang Liu, Xiangtai Li, and Henghui Ding. Referring image editing: Object-level image editing via referring expressions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13128–13138, 2024
2024
-
[44]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, Guopeng Li, Yuang Peng, Quan Sun, Jingwei Wu, Yan Cai, Zheng Ge, Ranchen Ming, Lei Xia, Xianfang Zeng, Yibo Zhu, Binxing Jiao, Xiangyu Zhang, Gang Yu, and Daxin Jiang. Step1x-edit: A practical framework for general image editing.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language under- standing.arXiv preprint arXiv:2403.05525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Visual-instructed degradation diffusion for all-in-one image restoration
Wenyang Luo, Haina Qin, Zewen Chen, Libin Wang, Dandan Zheng, Yuming Li, Yufan Liu, Bing Li, and Weiming Hu. Visual-instructed degradation diffusion for all-in-one image restoration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12764–12777, 2025
2025
-
[47]
Visual autoregressive modeling for instruction-guided image editing.arXiv preprint, 2025
Qingyang Mao, Qi Cai, Yehao Li, Yingwei Pan, Mingyue Cheng, Ting Yao, Qi Liu, and Tao Mei. Visual autoregressive modeling for instruction-guided image editing.arXiv preprint, 2025. 12
2025
-
[48]
Introducing manus 1.6: Max performance, mobile dev, and design view, 2025
Manus Meta. Introducing manus 1.6: Max performance, mobile dev, and design view, 2025
2025
-
[49]
Image segmentation using deep learning: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(7):3523–3542, 2021
Shervin Minaee, Yuri Boykov, Fatih Porikli, Antonio Plaza, Nasser Kehtarnavaz, and Demetri Terzopoulos. Image segmentation using deep learning: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(7):3523–3542, 2021
2021
-
[50]
A comprehensive overview of large language models.ACM Transactions on Intelligent Systems and Technology, 16(5):1–72, 2025
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models.ACM Transactions on Intelligent Systems and Technology, 16(5):1–72, 2025
2025
-
[51]
Gpt image 1, 2025
OpenAI. Gpt image 1, 2025
2025
-
[52]
Introducing chatgpt agent: bridging research and action, 2025
OpenAI. Introducing chatgpt agent: bridging research and action, 2025. Accessed: 2026-01-26
2025
-
[53]
The new chatgpt images is here, 2025
OpenAI. The new chatgpt images is here, 2025
2025
-
[54]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[55]
The claude 3 model family: Opus, sonnet, haiku
Anthropic PBC. The claude 3 model family: Opus, sonnet, haiku
-
[56]
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned benchmark for personalized image generation.arXiv preprint arXiv:2406.16855, 2024
-
[57]
Yusu Qian, Eli Bocek-Rivele, Liangchen Song, Jialing Tong, Yinfei Yang, Jiasen Lu, Wenze Hu, and Zhe Gan. Pico-banana-400k: A large-scale dataset for text-guided image editing.arXiv preprint arXiv:2510.19808, 2025
-
[58]
Ex- ploring stroke-level modifications for scene text editing
Yadong Qu, Qingfeng Tan, Hongtao Xie, Jianjun Xu, Yuxin Wang, and Yongdong Zhang. Ex- ploring stroke-level modifications for scene text editing. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 2119–2127, 2023
2023
-
[59]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[60]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation.arXiv preprint arXiv:2509.20427, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Insert anything: Image insertion via in-context editing in dit
Wensong Song, Hong Jiang, Zongxin Yang, Zheqiao Cheng, Ruijie Quan, and Yi Yang. Insert anything: Image insertion via in-context editing in dit. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 9097–9105, 2026
2026
-
[62]
Springer Nature, 2022
Richard Szeliski.Computer vision: algorithms and applications. Springer Nature, 2022
2022
-
[63]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Yoad Tewel, Rinon Gal, Dvir Samuel, Yuval Atzmon, Lior Wolf, and Gal Chechik. Add- it: Training-free object insertion in images with pretrained diffusion models.arXiv preprint arXiv:2411.07232, 2024
-
[65]
What makes an image realistic?arXiv preprint arXiv:2403.04493, 2024
Lucas Theis. What makes an image realistic?arXiv preprint arXiv:2403.04493, 2024
-
[66]
Deep learning for computer vision: A brief review.Computational intelligence and neuroscience, 2018(1):7068349, 2018
Athanasios V oulodimos, Nikolaos Doulamis, Anastasios Doulamis, and Eftychios Protopa- padakis. Deep learning for computer vision: A brief review.Computational intelligence and neuroscience, 2018(1):7068349, 2018. 13
2018
-
[67]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Adapting text-to-image generation with feature difference instruction for generic image restoration
Chao Wang, Hehe Fan, Huichen Yang, Sarvnaz Karimi, Lina Yao, and Yi Yang. Adapting text-to-image generation with feature difference instruction for generic image restoration. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 23539–23550, 2025
2025
-
[69]
Complexbench- edit: Benchmarking complex instruction-driven image editing via compositional dependencies
Chenglin Wang, Yucheng Zhou, Qianning Wang, Zhe Wang, and Kai Zhang. Complexbench- edit: Benchmarking complex instruction-driven image editing via compositional dependencies. InProceedings of the 33rd ACM International Conference on Multimedia, pages 13391–13397, 2025
2025
-
[70]
Vision-zero: Scalable vlm self-improvement via strategic gamified self-play
Qinsi Wang, Bo Liu, Tianyi Zhou, Jing Shi, Yueqian Lin, Yiran Chen, Hai Helen Li, Kun Wan, and Wentian Zhao. Vision-zero: Scalable vlm self-improvement via strategic gamified self-play. arXiv preprint arXiv:2509.25541, 2025
-
[71]
Rl-vlm-f: Reinforcement learning from vision language foundation model feedback
Yufei Wang, Zhanyi Sun, Jesse Zhang, Zhou Xian, Erdem Biyik, David Held, and Zackory Erickson. Rl-vlm-f: Reinforcement learning from vision language foundation model feedback. arXiv preprint arXiv:2402.03681, 2024
-
[72]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[73]
Objectdrop: Bootstrapping counterfactuals for photorealistic object removal and insertion
Daniel Winter, Matan Cohen, Shlomi Fruchter, Yael Pritch, Alex Rav-Acha, and Yedid Hoshen. Objectdrop: Bootstrapping counterfactuals for photorealistic object removal and insertion. In European Conference on Computer Vision, pages 112–129. Springer, 2024
2024
-
[74]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
2025
-
[75]
Keming Wu, Sicong Jiang, Max Ku, Ping Nie, Minghao Liu, and Wenhu Chen. Editre- ward: A human-aligned reward model for instruction-guided image editing.arXiv preprint arXiv:2509.26346, 2025
-
[76]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[77]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A unified image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26125–26135, 2025
2025
-
[79]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung- Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605, 2022. 14
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[80]
Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625– 5644, 2024
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625– 5644, 2024
2024
-
[81]
Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.