Can AI Review Improve Paper Drafting? An Empirical Study on 20 Computer Architecture Submissions
Pith reviewed 2026-06-28 17:26 UTC · model grok-4.3
The pith
AI-generated reviews cover a significant fraction of issues raised by human reviewers on paper drafts while also surfacing additional problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
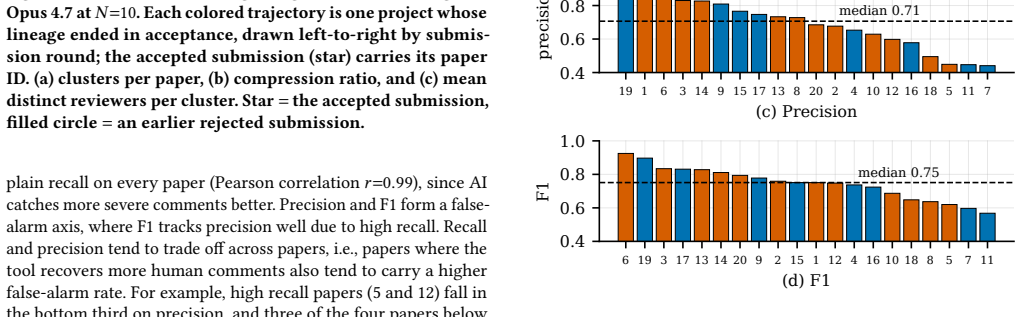
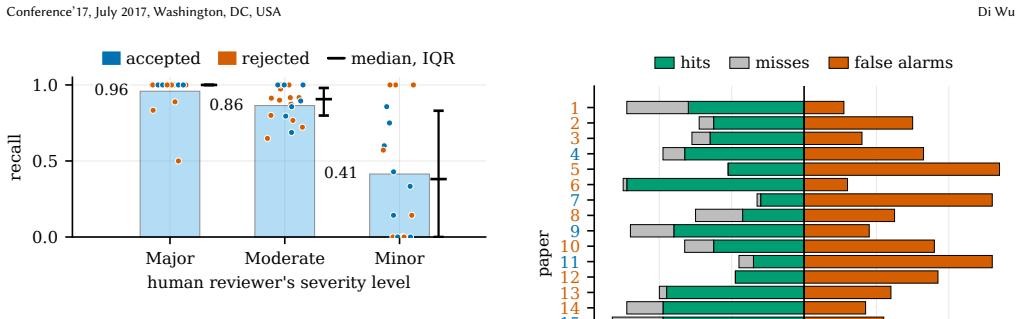
In the case study the AI review process covers a significant fraction of the issues that human reviewers raised across the 20 papers and additionally identifies issues absent from the human reviews. The authors built the AI-Paper-Review tool to generate structured feedback, cluster comments by commonality and importance, rank them, and align AI comments with human ones so that the overlap can be quantified.
What carries the argument
The AI-Paper-Review tool that selects multiple AI reviewers, clusters and ranks their comments, and aligns AI comments with human comments to support metric-based validation of overlap.
If this is right
- Authors could apply AI review early to address many issues that human reviewers later flag.
- AI comments can supplement human review by raising problems the humans missed.
- The alignment metrics give a concrete way to track how much AI feedback matches human feedback.
- Releasing the tool and the study data enables further experiments on AI-assisted drafting.
Where Pith is reading between the lines
- Similar alignment measurements could be applied to drafts in other research fields to test whether the overlap pattern repeats.
- A workflow that runs AI review first and then human review might reduce the total number of issues that reach the final human stage.
- Longitudinal tracking of papers that incorporate AI feedback could test whether acceptance rates or revision counts change.
Load-bearing premise
The custom metrics used to quantify alignment between AI and human comments actually measure whether AI review improves drafting, and the 20 selected papers are representative enough to support the conclusion.
What would settle it
A larger study across more papers and fields in which AI reviews cover fewer than half the human-raised issues and identify no unique issues would show the claimed coverage does not hold.
Figures



read the original abstract
Research is advancing faster than ever with artificial intelligence (AI); and so are the corresponding research papers. The exploding volume of AI-generated papers have put a strain to peer review, leading to the usage of AI-generated review, potentially wide yet sneaky. However, relevant ethical concerns about confidentiality, quality, and fairness are raised and no consensus has been reached in the broad research community. We expect the debate to continue for a while, but in the meantime, we ask an alternative, practical question: \textit{can AI review improve paper drafting?} We study 20 computer architecture papers, with varying levels of submission lineage, to expose how well AI review aligns with human review, quantified by a set of metrics we define. To conduct the case study, we build a web UI-integrated tool, \emph{AI-Paper-Review}, that generates structured AI review of a draft paper, available at https://github.com/unarylab/ai-paper-review. This tool selects several AI reviewers from a diverse pool of AI reviewers and clusters and ranks their comments based on commonality and importance of review comments. It also allows to align AI comments with human comments to facilitate metric-based validation. The case study shows that AI review can cover a significant fraction of human-raised issues, but also raises issues missing in human review. This paper is not intended to encourage using AI for peer review at the current stage, but to study that (1) how AI review can improve paper drafting and (2) the potential and limitation of AI-based peer review. The release of the tool and the case study data is intended to instigate future research on this topic. Misuse for peer review would violate the ethics policies from major academic venues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical case study of 20 computer architecture paper submissions (with varying submission lineage) using a custom web UI tool, AI-Paper-Review. The tool selects multiple AI reviewers, generates structured reviews, clusters and ranks comments by commonality and importance, and aligns AI comments with human comments via a set of custom metrics (coverage, alignment, novelty). The authors conclude that AI review covers a significant fraction of human-raised issues while also surfacing additional issues, suggesting potential to improve paper drafting, while cautioning against its use for actual peer review and releasing the tool and data to support future work.
Significance. If the custom alignment metrics were validated against direct measures of drafting improvement (e.g., pre/post revision quality scores or author feedback), the study would offer a useful empirical baseline on AI capabilities in a specific domain and the released tool/data would enable follow-on research. The work's strength lies in its reproducibility provisions rather than in establishing a causal link to improved drafting quality.
major comments (3)
- [Abstract] Abstract: The central claim that 'AI review can improve paper drafting' is not supported by any direct evidence of drafting improvement (pre/post quality scores, revision data, or external validation of the metrics). The reported results are limited to coverage/alignment statistics whose validity as a proxy for drafting quality is untested.
- [Abstract / case study section] Case study description: No quantitative values for the custom metrics (e.g., coverage fraction, overlap numbers), paper selection criteria, or error analysis are provided, preventing verification that the 20-paper sample supports the generalization about AI review utility.
- [Tool / metrics definition] Tool description: The clustering/ranking step and the alignment procedure used to compute the metrics are not validated against human judgment; without this, the metrics cannot be shown to measure what the authors intend.
minor comments (1)
- [Metrics] The manuscript should explicitly state the exact definitions and formulas for the coverage, alignment, and novelty metrics in a dedicated subsection.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our empirical case study. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'AI review can improve paper drafting' is not supported by any direct evidence of drafting improvement (pre/post quality scores, revision data, or external validation of the metrics). The reported results are limited to coverage/alignment statistics whose validity as a proxy for drafting quality is untested.
Authors: We agree that the study provides no direct evidence of drafting improvement via pre/post quality scores, revision data, or external validation. The manuscript frames an open question about potential improvement but reports only alignment metrics. We will revise the abstract, title framing, and introduction to state explicitly that the work examines coverage and alignment as an initial proxy rather than demonstrating causal effects on drafting quality. revision: yes
-
Referee: [Abstract / case study section] Case study description: No quantitative values for the custom metrics (e.g., coverage fraction, overlap numbers), paper selection criteria, or error analysis are provided, preventing verification that the 20-paper sample supports the generalization about AI review utility.
Authors: The full manuscript contains the quantitative results, but we accept that these details and the supporting criteria are insufficiently prominent. We will expand the case study section to include explicit numerical values for coverage, alignment, and novelty metrics, paper selection criteria, and an error analysis of the 20-paper sample. revision: yes
-
Referee: [Tool / metrics definition] Tool description: The clustering/ranking step and the alignment procedure used to compute the metrics are not validated against human judgment; without this, the metrics cannot be shown to measure what the authors intend.
Authors: We acknowledge that the clustering, ranking, and alignment procedures were not validated against human judgment within this study. The released tool and dataset are provided precisely to enable such validation by others. We will add an explicit limitations paragraph discussing the lack of human validation for these steps. revision: partial
Circularity Check
No significant circularity; empirical study with independent metrics and observations.
full rationale
The paper is a purely empirical case study that defines custom alignment metrics explicitly for quantifying AI-human comment overlap on 20 selected papers, then reports observed coverage and novelty statistics. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on direct measurement of the 20-paper sample rather than any reduction to prior inputs or self-referential definitions, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 20 papers with varying submission lineage form a representative sample for measuring AI-human review alignment.
Reference graph
Works this paper leans on
-
[1]
Andrew Akbashev. 2026. X Post. X. https://x.com/Andrew_Akbashev/status/ 2024171137089900846 Accessed: 2026-05-02
2026
-
[2]
Anthropic. 2026. Agent SDK overview. https://code.claude.com/docs/en/agent- sdk/overview Accessed: 2026-05-03
2026
-
[3]
Anthropic. 2026. An update on recent Claude Code quality reports. Anthropic En- gineering Blog. https://www.anthropic.com/engineering/april-23-postmortem Accessed: 2026-05-07
2026
-
[4]
Paul Arnold. 2026. A leading journal finds that AI is flooding academic publishing with lower quality work. Phys.org. https://phys.org/news/2026-05-journal-ai- academic-publishing-quality.html Accessed: 2026-05-02
2026
-
[5]
Association for the Advancement of Artificial Intelligence. 2025. AAAI Launches AI-Powered Peer-Review Assessment System. https://aaai.org/aaai-launches-ai- powered-peer-review-assessment-system/. Accessed: 2026-05-26
2025
-
[6]
Todd Austin. 2025. Heilmeier Extractor. LinkedIn post, AI Prompts for Re- searchers series. https://www.linkedin.com/posts/prof-todd-austin_ai-aitools- research-activity-7405033854929031168-lpdL
2025
-
[7]
Todd Austin. 2025. How are you using AI in your research? LinkedIn post, AI Prompts for Researchers series. https://www.linkedin.com/posts/prof-todd- austin_ai-research-aitools-share-7392579910822694912-dQGK/
2025
-
[8]
Joydeep Biswas, Sheila Schoepp, Gautham Vasan, Anthony Opipari, Arthur Zhang, Zichao Hu, Sebastian Joseph, Matthew Lease, Junyi Jessy Li, Peter Stone, et al. 2026. AI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot.arXiv preprint arXiv:2604.13940(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Alessandro Checco, Lorenzo Bracciale, Pierpaolo Loreti, Stephen Pinfield, and Giuseppe Bianchi. 2021. AI-assisted peer review.Humanities and social sciences communications8, 1 (2021), 25
2021
- [10]
-
[11]
Pedro Henrique Luz De Araujo, Paul Röttger, Dirk Hovy, and Benjamin Roth. 2025. Principled personas: Defining and measuring the intended effects of persona prompting on task performance. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 26845–26874
2025
-
[12]
John Drake. 2026. AI Slop Is Flooding Academic Journals. A Top Journal Mea- sured It. Forbes. https://www.forbes.com/sites/johndrake/2026/04/30/ai-slop-is- flooding-academic-journals-a-top-journal-measured-it/ Accessed: 2026-05-02
2026
- [13]
-
[14]
Palash Goyal, Mihir Parmar, Yiwen Song, Hamid Palangi, Tomas Pfister, and Jinsung Yoon. 2026. ScholarPeer: A Context-Aware Multi-Agent Framework for Automated Peer Review.arXiv preprint arXiv:2601.22638(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
IBM. 2025. What is Model Collapse? IBM Think Topics. https://www.ibm.com/ think/topics/model-collapse Accessed: 2026-05-07
2025
-
[16]
ICML 2026 Program Chairs. 2026. ICML Experimental Program Using Google’s Paper Assistant Tool (PAT). ICML Blog. https://blog.icml.cc/2026/01/14/icml- experimental-program-using-googles-paper-assistant-tool-pat/ Accessed: May 28, 2026
2026
-
[17]
Rajesh Jayaram, Vincent Cohen-Addad, Alekh Agarwal, Miroslav Dudik, Sharon Li, and Martin Jaggi. 2026. Retrospective on PAT x ICML 2026 AI Paper Assistant Program. ICML Blog. https://blog.icml.cc/2026/03/30/retrospective-on-pat-x- icml-2026-ai-paper-assistant-program/ Accessed: 2026-05-02
2026
-
[18]
Junseok Kim, Nakyeong Yang, and Kyomin Jung. 2025. Persona is a Double-Edged Sword: Rethinking the Impact of Role-play Prompts in Zero-shot Reasoning Tasks. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 848–862
2025
-
[19]
Weixin Liang, Yuhui Zhang, Hancheng Cao, Binglu Wang, Daisy Yi Ding, Xinyu Yang, Kailas Vodrahalli, Siyu He, Daniel Scott Smith, Yian Yin, et al. 2024. Can large language models provide useful feedback on research papers? A large-scale empirical analysis.NEJM AI1, 8 (2024), AIoa2400196
2024
-
[20]
Carlos Olea, Holly Tucker, Jessica Phelan, Cameron Pattison, Shen Zhang, Maxwell Lieb, Doug Schmidt, and Jules White. 2024. Evaluating persona prompt- ing for question answering tasks. InProceedings of the 10th international conference on artificial intelligence and soft computing, Sydney, Australia
2024
-
[21]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
2023
-
[22]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, 3982–3992. https://arxiv.org/abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [23]
-
[24]
Anna Rogers and Isabelle Augenstein. 2020. What can we do to improve peer review in NLP?. InFindings of the association for computational linguistics: EMNLP
2020
-
[25]
Joni Salminen, Danial Amin, and Bernard J Jansen. 2025. Using AI for User Representation: An Analysis of 83 Persona Prompts. In2025 IEEE/ACS 22nd International Conference on Computer Systems and Applications (AICCSA). IEEE, 1–8
2025
-
[26]
Karthikeyan Sankaralingam. 2024. A Whimsical Odyssey Through the Maze of Scholarly Reviews.Commun. ACM67, 11 (Oct. 2024), 6–7
2024
-
[27]
Karthikeyan Sankaralingam. 2025. From Theory to Practice: Introducing Architectural Prisms, an Experiment in AI-First Academic Dialogue. ACM SIGARCH Computer Architecture Today. https://www.sigarch.org/from- theory-to-practice-introducing-architectural-prisms-an-experiment-in-ai- first-academic-dialogue/ Accessed: May 15, 2026
2025
- [28]
-
[29]
Karthikeyan Sankaralingam. 2025. The Reviewer is Dead, Long Live the Review: Re-engineering Peer Review for the Age of AI. ACM SIGARCH Computer Architecture Today. https://www.sigarch.org/the-reviewer-is-dead-long-live- the-review-re-engineering-peer-review-for-the-age-of-ai/ Accessed: May 15, 2026
2025
-
[30]
Murray Shanahan, Kyle McDonell, and Laria Reynolds. 2023. Role play with large language models.Nature623, 7987 (2023), 493–498
2023
-
[31]
Ivan Stelmakh, Nihar B Shah, Aarti Singh, and Hal Daumé III. 2021. Prior and prejudice: The novice reviewers’ bias against resubmissions in conference peer review.Proceedings of the ACM on Human-Computer Interaction5, CSCW1 (2021), 1–17
2021
-
[32]
Richard Van Noorden and Jeffrey M Perkel. 2023. AI and science: what 1,600 researchers think.Nature621, 7980 (2023), 672–675
2023
-
[33]
Daniel Vela, Andrew Sharp, Richard Zhang, Trang Nguyen, An Hoang, and Oleg S Pianykh. 2022. Temporal quality degradation in AI models.Scientific reports12, 1 (2022), 11654
2022
-
[34]
David Woodruff, Rajesh Jayaram, Vincent Cohen-Addad, and Jon Schneider
-
[35]
https://acm-stoc.org/stoc2026/stoc2026- LLM_feedback.html Accessed: 2026-05-02
Symposium on Theory of Computing 2026 Experimental Program: Au- tomated Pre-Submission Feedback. https://acm-stoc.org/stoc2026/stoc2026- LLM_feedback.html Accessed: 2026-05-02
2026
- [36]
- [37]
- [38]
- [39]
-
[40]
a helpful assistant
Mingqian Zheng, Jiaxin Pei, Lajanugen Logeswaran, Moontae Lee, and David Jurgens. 2024. When “a helpful assistant” is not really helpful: Personas in system prompts do not improve performances of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024. 15126–15154
2024
- [41]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.