Cross-Axis Feature Fusion with Joint-Wise Motion Difference Prediction for Text-Based 3D Human Motion Editing
Pith reviewed 2026-06-28 17:30 UTC · model grok-4.3
The pith
Cross-axis fusion of joint and time transformers with auxiliary joint-difference regression improves text-based 3D motion editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
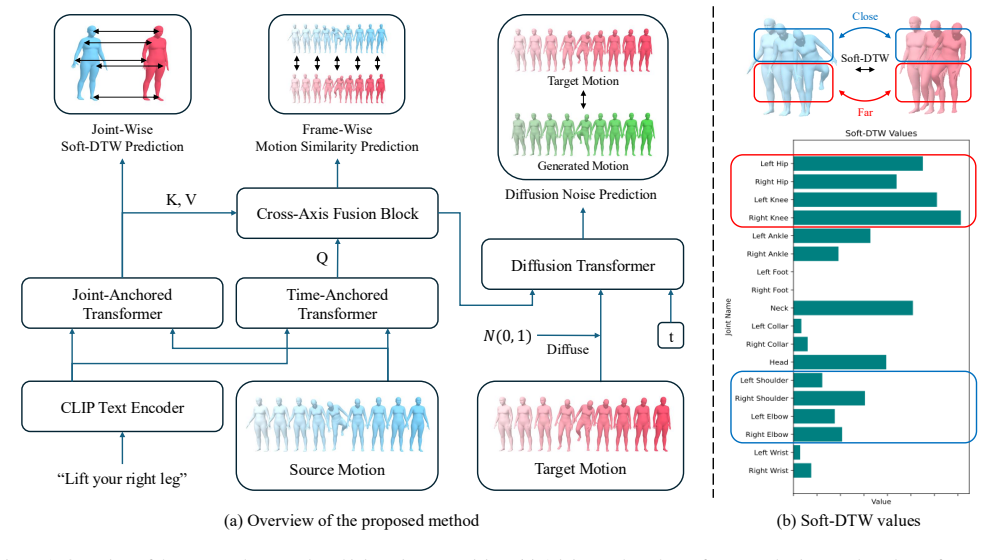
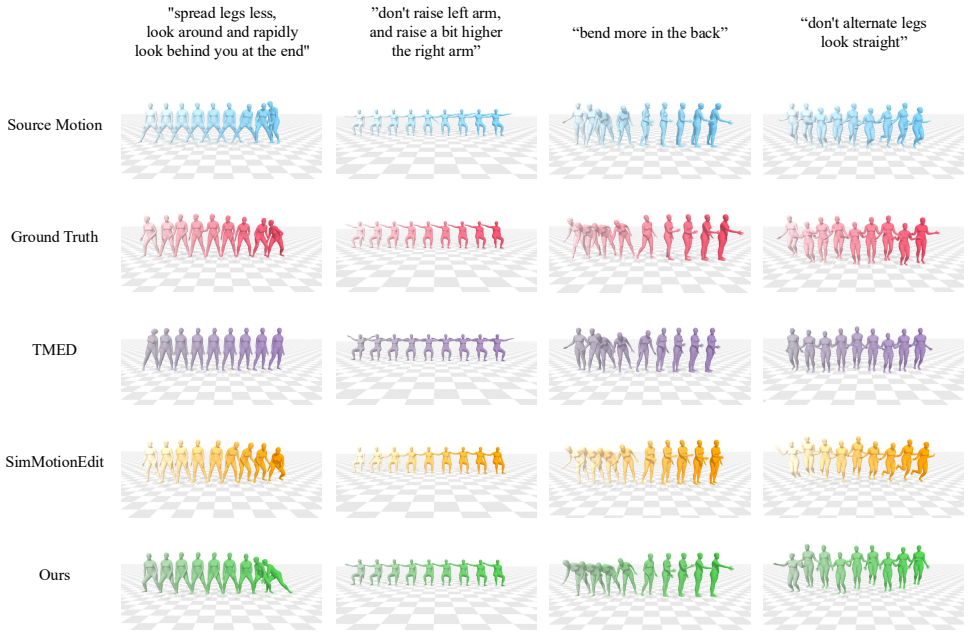
We propose an architecture with two axis-anchored transformers that extract features along the joint and time dimensions respectively, integrated by a cross-axis fusion block. We introduce an auxiliary task that trains the joint-anchored transformer to regress the Soft-DTW distance between source and target joint rotations. This objective teaches the module to understand which joints to modify and which to preserve. Through comprehensive experiments on the MotionFix dataset, we demonstrate that our method significantly improves semantic alignment with both the text instruction and the source motion, as well as the overall fidelity of the generated motion, achieving state-of-the-art results.
What carries the argument
Cross-axis fusion block that integrates distinct features from joint-anchored and time-anchored transformers, aided by the auxiliary Soft-DTW regression task on joint rotations.
If this is right
- The model achieves stronger semantic alignment with text instructions while better preserving source motion structure.
- Generated motions exhibit higher overall fidelity on the MotionFix benchmark.
- State-of-the-art results are obtained compared to prior diffusion-based editing methods.
- The approach explicitly separates temporal and joint-wise understanding to target edits more precisely.
Where Pith is reading between the lines
- The axis separation and auxiliary regression could extend to editing other sequential data such as video or audio without major redesign.
- Joint-wise difference signals might serve as a lightweight supervisory signal in related motion synthesis tasks to improve controllability.
- If the fusion block generalizes, similar cross-axis designs could apply to long-horizon motion planning where both timing and body-part specificity matter.
Load-bearing premise
The auxiliary task of regressing Soft-DTW distances between source and target joint rotations teaches the joint-anchored transformer to identify which joints to modify versus preserve.
What would settle it
An ablation study on the MotionFix dataset in which removing the auxiliary regression task produces no measurable drop in joint-specific edit accuracy or semantic alignment scores would falsify the mechanism.
Figures
read the original abstract
We address text-based 3D human motion editing, where the goal is to preserve the style and structure of a source motion while applying edits described in natural language. The release of the MotionFix dataset has spurred active research into training-based diffusion models that directly generate an edited motion from a source motion and a text instruction. While previous works have focused primarily on learning when an edit should occur temporally, our goal is to create a model that understands not only this temporal aspect but also which specific joints are responsible for the change. Targeting this, we propose a novel architecture and a complementary auxiliary task to aid its training. Our architecture consists of two axis-anchored transformers, which extract distinct features along the joint and time dimensions respectively, and a cross-axis fusion block that integrates these representations. We further introduce an auxiliary task that trains the joint-anchored transformer to regress the Soft-DTW distance between source and target joint rotations. This objective teaches the module to understand which joints to modify and which to preserve. Through comprehensive experiments on the MotionFix dataset, we demonstrate that our method significantly improves semantic alignment with both the text instruction and the source motion, as well as the overall fidelity of the generated motion, achieving state-of-the-art results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a cross-axis feature fusion architecture for text-based 3D human motion editing consisting of two axis-anchored transformers (joint-anchored and time-anchored) whose features are integrated via a cross-axis fusion block. An auxiliary task is introduced that trains the joint-anchored transformer to regress the Soft-DTW distance between source and target joint rotations; this is claimed to teach the module which joints to modify versus preserve. Comprehensive experiments on the MotionFix dataset are reported to demonstrate improved semantic alignment with text and source motion plus higher fidelity, yielding state-of-the-art results.
Significance. If the claimed gains are reproducible and the auxiliary objective demonstrably contributes to joint-specific text conditioning, the work would advance controllable motion editing beyond purely temporal modeling, offering a concrete mechanism for joint-level edit localization.
major comments (2)
- [Abstract] Abstract: the SOTA claim is asserted without any reported baselines, metrics (e.g., FID, R-Precision, user-study scores), ablation tables, or quantitative deltas, preventing verification that the cross-axis fusion plus auxiliary loss actually drives the improvement.
- [Method] Method (auxiliary task description): the joint-anchored transformer regresses Soft-DTW on source/target rotations before cross-axis fusion; because the target rotations already embed the text instruction, the regression objective can be solved by learning generic motion differences without any text signal, weakening the claimed link between the auxiliary loss and improved semantic alignment.
minor comments (1)
- [Abstract] Abstract: the phrase 'complementary auxiliary task' is used without clarifying whether the auxiliary loss is active only at training time or also influences inference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the SOTA claim is asserted without any reported baselines, metrics (e.g., FID, R-Precision, user-study scores), ablation tables, or quantitative deltas, preventing verification that the cross-axis fusion plus auxiliary loss actually drives the improvement.
Authors: We agree that the abstract would be strengthened by including supporting quantitative details. The full manuscript reports experiments on MotionFix with baseline comparisons, metrics including FID and R-Precision, ablation studies, and user-study scores demonstrating the improvements from cross-axis fusion and the auxiliary task. We will revise the abstract to briefly reference these key metrics and deltas. revision: yes
-
Referee: [Method] Method (auxiliary task description): the joint-anchored transformer regresses Soft-DTW on source/target rotations before cross-axis fusion; because the target rotations already embed the text instruction, the regression objective can be solved by learning generic motion differences without any text signal, weakening the claimed link between the auxiliary loss and improved semantic alignment.
Authors: The target rotations are the ground-truth motions resulting from applying the specific text instruction to the source, so the Soft-DTW distances encode the text-driven joint modifications rather than generic differences. The auxiliary objective is applied to the joint-anchored transformer to encourage learning of joint-level edit localization that complements the text conditioning provided through the overall architecture and cross-axis fusion. We acknowledge the description could more explicitly connect the text-conditioned targets to the auxiliary task's benefit for semantic alignment. We will revise the method section to clarify this and consider adding further analysis or ablations. revision: yes
Circularity Check
No significant circularity; auxiliary task is independent training objective
full rationale
The paper's derivation consists of an architecture (joint- and time-anchored transformers plus cross-axis fusion) and an auxiliary Soft-DTW regression loss on source/target joint rotations. The abstract explicitly frames the auxiliary task as a complementary training signal rather than a mathematical reduction of the main output to fitted inputs or self-referential definitions. No equations are presented that equate a claimed prediction to its own training targets by construction, and no self-citations are used to import uniqueness theorems or ansatzes. The SOTA claims rest on empirical results on the MotionFix dataset, which are falsifiable independently of the auxiliary objective's interpretive justification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Unpaired motion style transfer from video to animation.ACM Trans
Kfir Aberman, Yijia Weng, Dani Lischinski, Daniel Cohen- Or, and Baoquan Chen. Unpaired motion style transfer from video to animation.ACM Trans. Graph., 39(4), 2020. 1, 2
2020
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Black, and G ¨ul Varol
Nikos Athanasiou, Alp ´ar Cseke, Markos Diomataris, Michael J. Black, and G ¨ul Varol. Motionfix: Text-driven 3d human motion editing. InSIGGRAPH Asia 2024 Con- ference Papers, New York, NY , USA, 2024. Association for Computing Machinery. 1, 2, 3, 5, 6
2024
-
[4]
Motionclr: Motion generation and training-free edit- ing via understanding attention mechanisms.arXiv e-prints, pages arXiv–2410, 2024
Ling-Hao Chen, Wenxun Dai, Xuan Ju, Shunlin Lu, and Lei Zhang. Motionclr: Motion generation and training-free edit- ing via understanding attention mechanisms.arXiv e-prints, pages arXiv–2410, 2024. 1, 2
2024
-
[5]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18000–18010, 2023. 1, 2
2023
-
[6]
Posefix: Correcting 3d hu- man poses with natural language
Ginger Delmas, Philippe Weinzaepfel, Francesc Moreno- Noguer, and Gr ´egory Rogez. Posefix: Correcting 3d hu- man poses with natural language. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15018–15028, 2023. 1, 2
2023
-
[7]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. InAdvances in Neural Infor- mation Processing Systems, pages 8780–8794. Curran Asso- ciates, Inc., 2021. 2
2021
-
[8]
Guess: Gradually enriching synthesis for text-driven human motion generation.IEEE Transactions on Visualization and Computer Graphics, 30 (12):7518–7530, 2024
Xuehao Gao, Yang Yang, Zhenyu Xie, Shaoyi Du, Zhongqian Sun, and Yang Wu. Guess: Gradually enriching synthesis for text-driven human motion generation.IEEE Transactions on Visualization and Computer Graphics, 30 (12):7518–7530, 2024. 1, 2
2024
-
[9]
Motion editing with spacetime con- straints
Michael Gleicher. Motion editing with spacetime con- straints. InProceedings of the 1997 Symposium on Interac- tive 3D Graphics, page 139–ff., New York, NY , USA, 1997. Association for Computing Machinery. 1, 2
1997
-
[10]
Motion path editing
Michael Gleicher. Motion path editing. InProceedings of the 2001 Symposium on Interactive 3D Graphics, page 195–202, New York, NY , USA, 2001. Association for Computing Ma- chinery. 1, 2
2001
-
[11]
Karen Liu, and Kayvon Fatahalian
Purvi Goel, Kuan-Chieh Wang, C. Karen Liu, and Kayvon Fatahalian. Iterative motion editing with natural language. InACM SIGGRAPH 2024 Conference Papers, New York, NY , USA, 2024. Association for Computing Machinery. 1, 2
2024
-
[12]
Ac- tion2motion: Conditioned generation of 3d human motions
Chuan Guo, Xinxin Zuo, Sen Wang, Shihao Zou, Qingyao Sun, Annan Deng, Minglun Gong, and Li Cheng. Ac- tion2motion: Conditioned generation of 3d human motions. InProceedings of the 28th ACM International Conference on Multimedia, page 2021–2029, New York, NY , USA, 2020. Association for Computing Machinery. 1, 2
2021
-
[13]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5152–5161, 2022. 2
2022
-
[14]
Learning neural deformation representation for 4d dynamic shape generation
Gyojin Han, Jiwan Hur, Jaehyun Choi, and Junmo Kim. Learning neural deformation representation for 4d dynamic shape generation. InComputer Vision – ECCV 2024, pages 186–203, Cham, 2025. Springer Nature Switzerland. 3
2024
-
[15]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. InAdvances in Neural Infor- mation Processing Systems, pages 6840–6851. Curran Asso- ciates, Inc., 2020. 1, 2, 6
2020
-
[17]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els.arXiv preprint arXiv:2210.02303, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Video diffu- sion models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffu- sion models. InAdvances in Neural Information Processing Systems, pages 8633–8646. Curran Associates, Inc., 2022. 3
2022
-
[19]
A deep learning framework for character motion synthesis and editing.ACM Trans
Daniel Holden, Jun Saito, and Taku Komura. A deep learning framework for character motion synthesis and editing.ACM Trans. Graph., 35(4), 2016. 1, 2
2016
-
[20]
Como: Controllable motion generation through language guided pose code edit- ing
Yiming Huang, Weilin Wan, Yue Yang, Chris Callison- Burch, Mark Yatskar, and Lingjie Liu. Como: Controllable motion generation through language guided pose code edit- ing. InComputer Vision – ECCV 2024, pages 180–196, Cham, 2025. Springer Nature Switzerland. 2
2024
-
[21]
Expanding expressiveness of diffusion mod- els with limited data via self-distillation based fine-tuning
Jiwan Hur, Jaehyun Choi, Gyojin Han, Dong-Jae Lee, and Junmo Kim. Expanding expressiveness of diffusion mod- els with limited data via self-distillation based fine-tuning. InProceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV), pages 5028–5037,
-
[22]
Dynamic mo- tion blending for versatile motion editing
Nan Jiang, Hongjie Li, Ziye Yuan, Zimo He, Yixin Chen, Tengyu Liu, Yixin Zhu, and Siyuan Huang. Dynamic mo- tion blending for versatile motion editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22735–22745, 2025. 1, 2, 5, 3
2025
-
[23]
Local action- guided motion diffusion model for text-to-motion genera- tion
Peng Jin, Hao Li, Zesen Cheng, Kehan Li, Runyi Yu, Chang Liu, Xiangyang Ji, Li Yuan, and Jie Chen. Local action- guided motion diffusion model for text-to-motion genera- tion. InComputer Vision – ECCV 2024, pages 392–409, Cham, 2025. Springer Nature Switzerland. 1, 2
2024
-
[24]
Flame: Free- form language-based motion synthesis & editing.Proceed- ings of the AAAI Conference on Artificial Intelligence, 37(7): 8255–8263, 2023
Jihoon Kim, Jiseob Kim, and Sungjoon Choi. Flame: Free- form language-based motion synthesis & editing.Proceed- ings of the AAAI Conference on Artificial Intelligence, 37(7): 8255–8263, 2023. 2
2023
-
[25]
A hierarchical approach to interactive motion editing for human-like figures
Jehee Lee and Sung Yong Shin. A hierarchical approach to interactive motion editing for human-like figures. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, page 39–48, USA,
-
[26]
ACM Press/Addison-Wesley Publishing Co. 1, 2
-
[27]
Simmotionedit: Text-based human motion editing with motion similarity pre- diction
Zhengyuan Li, Kai Cheng, Anindita Ghosh, Uttaran Bhat- tacharya, Liangyan Gui, and Aniket Bera. Simmotionedit: Text-based human motion editing with motion similarity pre- diction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27827–27837, 2025. 1, 2, 3, 5, 6, 8
2025
-
[28]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. Smpl: a skinned multi- person linear model.ACM Trans. Graph., 34(6), 2015. 2
2015
-
[29]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 6
2019
-
[30]
Dpm-solver: A fast ode solver for dif- fusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan LI, and Jun Zhu. Dpm-solver: A fast ode solver for dif- fusion probabilistic model sampling in around 10 steps. In Advances in Neural Information Processing Systems, pages 5775–5787. Curran Associates, Inc., 2022. 1, 2
2022
-
[31]
Rethinking diffusion for text-driven human motion generation: Redundant representations, evaluation, and masked autoregression
Zichong Meng, Yiming Xie, Xiaogang Peng, Zeyu Han, and Huaizu Jiang. Rethinking diffusion for text-driven human motion generation: Redundant representations, evaluation, and masked autoregression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27859–27871, 2025. 1, 2
2025
-
[32]
Scalable diffusion mod- els with transformers
William Peebles and Saining Xie. Scalable diffusion mod- els with transformers. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 1, 2
2023
-
[33]
Black, and G ¨ul Varol
Mathis Petrovich, Michael J. Black, and G ¨ul Varol. Action- conditioned 3d human motion synthesis with transformer vae. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision (ICCV), pages 10985–10995, 2021. 1, 2
2021
-
[34]
Black, and G ¨ul Varol
Mathis Petrovich, Michael J. Black, and G ¨ul Varol. Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9488–9497,
-
[35]
The kit motion-language dataset.Big Data, 4(4):236–252,
Matthias Plappert, Christian Mandery, and Tamim Asfour. The kit motion-language dataset.Big Data, 4(4):236–252,
-
[36]
Punnakkal, Arjun Chandrasekaran, Nikos Athanasiou, Alejandra Quiros-Ramirez, and Michael J
Abhinanda R. Punnakkal, Arjun Chandrasekaran, Nikos Athanasiou, Alejandra Quiros-Ramirez, and Michael J. Black. Babel: Bodies, action and behavior with english la- bels. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 722– 731, 2021. 2
2021
-
[37]
Motion in-betweening via two-stage transformers.ACM Trans
Jia Qin, Youyi Zheng, and Kun Zhou. Motion in-betweening via two-stage transformers.ACM Trans. Graph., 41(6),
-
[38]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 1, 5
2021
-
[39]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 2
2022
-
[40]
MVDream: Multi-view diffusion for 3d gen- eration
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. MVDream: Multi-view diffusion for 3d gen- eration. InThe Twelfth International Conference on Learn- ing Representations, 2024. 3
2024
-
[41]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations, 2021. 1, 2
2021
-
[42]
Human motion diffu- sion model
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. Human motion diffu- sion model. InThe Eleventh International Conference on Learning Representations, 2023. 1, 2, 5
2023
-
[43]
Spacetime constraints
Andrew Witkin and Michael Kass. Spacetime constraints. InProceedings of the 15th Annual Conference on Computer Graphics and Interactive Techniques, page 159–168, New York, NY , USA, 1988. Association for Computing Machin- ery. 1, 2
1988
-
[44]
Omnicontrol: Control any joint at any time for human motion generation
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. Omnicontrol: Control any joint at any time for human motion generation. InThe Twelfth International Conference on Learning Representations, 2024. 2
2024
-
[45]
Actformer: A gan- based transformer towards general action-conditioned 3d hu- man motion generation
Liang Xu, Ziyang Song, Dongliang Wang, Jing Su, Zhicheng Fang, Chenjing Ding, Weihao Gan, Yichao Yan, Xin Jin, Xi- aokang Yang, Wenjun Zeng, and Wei Wu. Actformer: A gan- based transformer towards general action-conditioned 3d hu- man motion generation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2228–2238, 2023. 1, 2
2023
-
[46]
Interdiff: Generating 3d human-object interactions with physics-informed diffusion
Sirui Xu, Zhengyuan Li, Yu-Xiong Wang, and Liang-Yan Gui. Interdiff: Generating 3d human-object interactions with physics-informed diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14928–14940, 2023. 1, 2
2023
-
[47]
Shape conditioned human motion generation with diffusion model.arXiv preprint arXiv:2405.06778, 2024
Kebing Xue and Hyewon Seo. Shape conditioned human motion generation with diffusion model.arXiv preprint arXiv:2405.06778, 2024. 2
-
[48]
Tapmo: Shape- aware motion generation of skeleton-free characters
Jiaxu Zhang, Shaoli Huang, Zhigang Tu, Xin Chen, Xiao- hang Zhan, Gang YU, and Ying Shan. Tapmo: Shape- aware motion generation of skeleton-free characters. InThe Twelfth International Conference on Learning Representa- tions, 2024. 2
2024
-
[49]
Energymo- gen: Compositional human motion generation with energy- based diffusion model in latent space
Jianrong Zhang, Hehe Fan, and Yi Yang. Energymo- gen: Compositional human motion generation with energy- based diffusion model in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17592–17602, 2025. 1, 2
2025
-
[50]
Finemogen: Fine-grained spatio- temporal motion generation and editing
Mingyuan Zhang, Huirong Li, Zhongang Cai, Jiawei Ren, Lei Yang, and Ziwei Liu. Finemogen: Fine-grained spatio- temporal motion generation and editing. InAdvances in Neu- ral Information Processing Systems, pages 13981–13992. Curran Associates, Inc., 2023. 2
2023
-
[51]
Motiondif- fuse: Text-driven human motion generation with diffusion model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4115–4128, 2024
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondif- fuse: Text-driven human motion generation with diffusion model.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4115–4128, 2024. 1, 2
2024
-
[52]
don’t raise left arm, and raise a bit higher the right arm
Kaifeng Zhao, Gen Li, and Siyu Tang. Dartcontrol: A diffusion-based autoregressive motion model for real-time text-driven motion control. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2 Cross-Axis Feature Fusion with Joint-Wise Motion Difference Prediction for Text-Based 3D Human Motion Editing Supplementary Material A. G...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.