τ₀-WM: A Unified Video-Action World Model for Robotic Manipulation
Pith reviewed 2026-06-28 17:18 UTC · model grok-4.3
The pith
A single video diffusion model jointly predicts robot actions and their visual futures to enable better planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
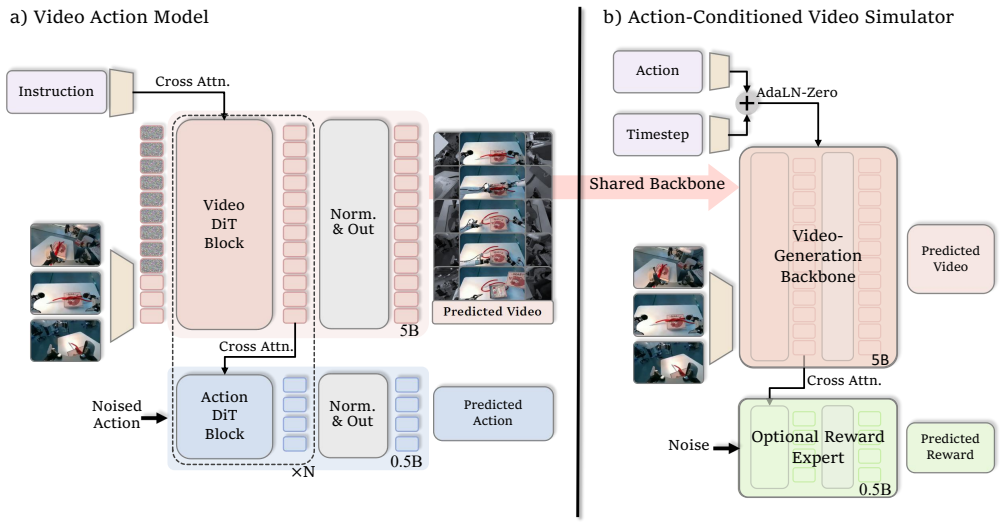
τ₀-WM is a unified video-action world model that integrates policy learning, video prediction, and action evaluation within a single future-predictive framework using a shared video diffusion backbone. It offers a video action model for predicting future visuals and action chunks, and an action-conditioned video simulator for rolling out futures and scoring task progress. The approach is trained on approximately 27,300 hours of diverse data and employs test-time computation for action selection and improvement.
What carries the argument
The shared video diffusion backbone providing dual interfaces for video action modeling and action-conditioned simulation.
If this is right
- The model anticipates future consequences before executing actions in physical robots.
- It allows ranking and rectifying action candidates using consistency and simulation without additional training.
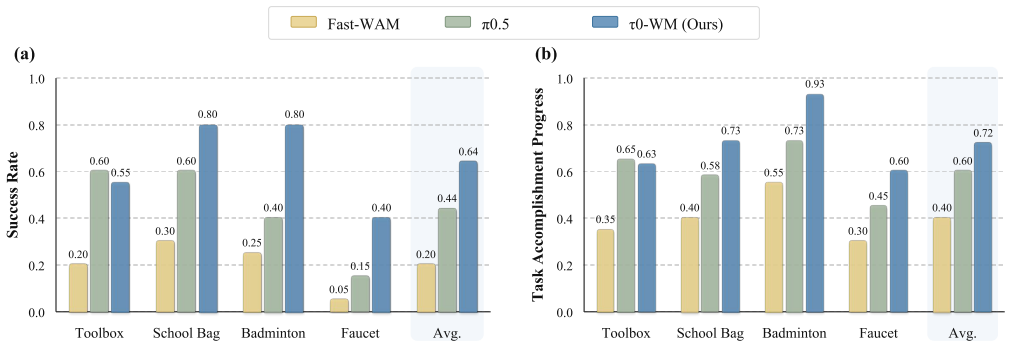
- Performance improves on challenging long-horizon and fine-grained manipulation tasks over separate baselines.
- Policy learning, prediction, and evaluation are handled in one framework reducing modularity needs.
Where Pith is reading between the lines
- This unified approach may simplify robotics software stacks by replacing multiple specialized models.
- Extending the test-time re-denoising to more samples could further improve action quality on complex tasks.
- The use of human videos in training suggests potential for better generalization from demonstration data.
Load-bearing premise
The assumption that modality-specific supervision masks and test-time re-denoising consistency will produce reliable ranking of action candidates without introducing new failure modes not captured by the training distribution.
What would settle it
Experiments showing that re-denoising consistency rankings do not correlate with actual task success rates on held-out manipulation tasks.
Figures


read the original abstract
Robotic manipulation requires models that generate executable actions while anticipating and evaluating their future consequences before physical execution. We present $\tau_0$-World Model ($\tau_0$-WM), a unified video-action world model that integrates policy learning, video prediction, and action evaluation within a single future-predictive framework. Built on a shared video diffusion backbone, $\tau_0$-WM provides two complementary interfaces. First, a video action model jointly predicts future visual latents and continuous action chunks from multi-view observations, language instructions, and robot state. Second, an action-conditioned video simulator rolls out candidate action chunks into multi-view futures and predicts dense task-progress scores. The model is trained on approximately $27{,}300$ hours of real-robot teleoperation, UMI-style interaction, egocentric human videos, and rollout or failure trajectories using modality-specific supervision masks. At inference time, $\tau_0$-WM uses test-time computation to sample action candidates, rank them with re-denoising consistency, and invoke simulator-based rectification for low-quality candidates. On challenging long-horizon and fine-grained robotic manipulation tasks, $\tau_0$-WM shows superior performance over other relevant baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents τ₀-WM, a unified video-action world model for robotic manipulation built on a shared video diffusion backbone. It jointly predicts future visual latents and continuous action chunks from multi-view observations, language, and robot state, while also providing an action-conditioned video simulator that rolls out candidates and predicts dense task-progress scores. The model is trained on approximately 27,300 hours of real-robot teleoperation, UMI-style, egocentric human, and rollout/failure data using modality-specific supervision masks. At inference, it samples action candidates, ranks them via test-time re-denoising consistency, and applies simulator-based rectification for low-quality candidates. The central claim is superior performance over relevant baselines on challenging long-horizon and fine-grained robotic manipulation tasks.
Significance. If the performance claims and the reliability of the inference procedure hold, the work would be significant for advancing unified world models in robotics by tightly integrating policy, prediction, and evaluation in one framework and leveraging large-scale heterogeneous data. The scale of training data and the explicit use of test-time computation for candidate ranking are notable strengths that could influence future video-action models.
major comments (2)
- [Inference-time paragraph] Inference-time paragraph: The claim of superior performance on long-horizon and fine-grained tasks rests on the assumption that re-denoising consistency after modality-specific mask training reliably ranks action candidates without introducing new failure modes outside the training distribution. No quantitative evidence (e.g., correlation between consistency scores and actual task success on held-out long-horizon sequences) is provided to support this, leaving the performance advantage vulnerable if the ranking metric does not track progress.
- [Abstract and §3] Abstract and §3 (model description): The unified framework is presented as jointly handling policy learning, video prediction, and action evaluation, yet the manuscript provides no ablation isolating the contribution of the simulator-based rectification versus the re-denoising ranking alone; without this, it is unclear whether the reported gains are load-bearing on the full pipeline or could be achieved by simpler baselines.
minor comments (2)
- The training data composition (27,300 hours) is stated without breakdown by source or modality mask statistics; adding a table with per-source hours and mask usage would improve reproducibility.
- Notation for τ₀ and the diffusion backbone is introduced without an explicit equation defining the joint video-action prediction objective; a single equation in §2 would clarify the shared backbone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Inference-time paragraph] Inference-time paragraph: The claim of superior performance on long-horizon and fine-grained tasks rests on the assumption that re-denoising consistency after modality-specific mask training reliably ranks action candidates without introducing new failure modes outside the training distribution. No quantitative evidence (e.g., correlation between consistency scores and actual task success on held-out long-horizon sequences) is provided to support this, leaving the performance advantage vulnerable if the ranking metric does not track progress.
Authors: We agree that a direct correlation analysis between re-denoising consistency scores and task success on held-out long-horizon sequences would provide stronger validation of the ranking procedure. We will add this quantitative evidence to the revised manuscript, including plots and statistics on held-out sequences to confirm that the metric tracks progress without introducing new failure modes. revision: yes
-
Referee: [Abstract and §3] Abstract and §3 (model description): The unified framework is presented as jointly handling policy learning, video prediction, and action evaluation, yet the manuscript provides no ablation isolating the contribution of the simulator-based rectification versus the re-denoising ranking alone; without this, it is unclear whether the reported gains are load-bearing on the full pipeline or could be achieved by simpler baselines.
Authors: We acknowledge that an ablation isolating simulator-based rectification from re-denoising ranking alone would clarify whether the full inference pipeline is required. We will add this ablation study in the revision to quantify the incremental contribution of each component. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes a video-action world model trained on large-scale real-robot and human video data using modality-specific supervision masks, with inference-time sampling of action candidates ranked via re-denoising consistency and simulator rectification. No equations, parameter-fitting steps presented as predictions, self-citation load-bearing arguments, uniqueness theorems, or ansatz smuggling are present in the provided text. The central performance claims rest on empirical evaluation against baselines on long-horizon tasks rather than any derivation that reduces to its own inputs by construction. The model architecture and training procedure are self-contained and do not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
World Action Models: A Survey
A survey that clarifies boundaries and organizes World Action Models by generation requirements and predictive substrates, identifying a trend toward generating less of the future.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Bal- aji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Sys- tems, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kan- ervisto, Amos Storkey, Tim Pearce, and Franc ¸ois Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Sys- tems, 37:58757–58791, 2024
2024
-
[4]
Ulyanov, et al
Jason Ansel, Edward Yang, Horace He, Ozgur K. Ulyanov, et al. Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASP- LOS), 2024
2024
-
[5]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
In9th Annual Conference on Robot Learning, 2025
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al.π 0.5: a vision-language-action model with open- world generalization. In9th Annual Conference on Robot Learning, 2025
2025
-
[7]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Wing Yin Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. https://openai.com/research/ video-generation-models-as-world-simulators, 2024. OpenAI research blog
2024
-
[8]
Chang Chen, Yi-Fu Wu, Jaesik Yoon, and Sungjin Ahn. Transdreamer: Reinforcement learning with transformer world models.arXiv preprint arXiv:2202.09481, 2022
-
[9]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal manipulation interface: In-the- wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Visual Foresight: Model-Based Deep Reinforcement Learning for Vision-Based Robotic Control
Frederik Ebert, Chelsea Finn, Sudeep Dasari, Annie Xie, Alex Lee, and Sergey Levine. Visual foresight: Model-based deep reinforcement learning for vision- based robotic control.arXiv preprint arXiv:1812.00568, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Deep visual foresight for planning robot motion
Chelsea Finn and Sergey Levine. Deep visual foresight for planning robot motion. In2017 IEEE international conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[12]
DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, et al. Dreamdojo: A generalist robot world model from large- scale human videos.arXiv preprint arXiv:2602.06949, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
10kh realomni-open dataset
GenRobot. 10kh realomni-open dataset. https://www. genrobot.ai/data/open-dataset, 2025. 1M+ clips from real-world and omni-scene robotic manipulation
2025
-
[14]
Veo: A video generation system
Google DeepMind. Veo: A video generation system. https://deepmind.google/technologies/veo/, 2024
2024
-
[15]
Ctrl-World: A Controllable Generative World Model for Robot Manipulation
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation.arXiv preprint arXiv:2510.10125, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx- video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mo- hammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[18]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
Ryan Hoque, Peide Huang, David J Yoon, Mouli Siva- purapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Enerverse: Envi- sioning embodied future space for robotics manipulation
Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Yue Liao, Zhengkai Jiang, Yue Hu, Peng Gao, Hongsheng Li, Maoqing Yao, et al. Enerverse: Envi- sioning embodied future space for robotics manipulation. Advances in Neural Information Processing Systems, 38: 37693–37720, 2026
2026
-
[21]
Yuxin Jiang, Shengcong Chen, Siyuan Huang, Liliang Chen, Pengfei Zhou, Yue Liao, Xindong He, Chiming Liu, Hongsheng Li, Maoqing Yao, et al. Enerverse-ac: Envisioning embodied environments with action condi- tion.arXiv preprint arXiv:2505.09723, 2025
-
[22]
R.E. Kalman. A new approach to linear filtering and prediction problems.Journal of Basic Engineering, 82 (1):35–45, 1960
1960
-
[23]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, et al. Cosmos policy: Fine- tuning video models for visuomotor control and planning. arXiv preprint arXiv:2601.16163, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jian- wei Zhang, et al. Hunyuanvideo: A systematic frame- work for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control. arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Video Generators are Robot Policies
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V on- drick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Yue Liao, Pengfei Zhou, Siyuan Huang, Donglin Yang, Shengcong Chen, Yuxin Jiang, Yue Hu, Jingbin Cai, Si Liu, Jianlan Luo, et al. Genie envisioner: A uni- fied world foundation platform for robotic manipulation. arXiv preprint arXiv:2508.05635, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maxim- ilian Nickel, and Matt Le. Flow matching for generative modeling. In11th International Conference on Learning Representations, ICLR 2023, 2023
2023
-
[31]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[32]
Acg: Action coherence guidance for flow-based vla models.arXiv preprint arXiv:2510.22201, 2025
Minho Park, Kinam Kim, Junha Hyung, Hyojin Jang, Hoiyeong Jin, Jooyeol Yun, Hojoon Lee, and Jaegul Choo. Acg: Action coherence guidance for flow-based vla models.arXiv preprint arXiv:2510.22201, 2025
-
[33]
Scalable diffu- sion models with transformers
William Peebles and Saining Xie. Scalable diffu- sion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[34]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
EgoVerse: An Egocentric Human Dataset for Robot Learning from Around the World
Ryan Punamiya, Simar Kareer, Zeyi Liu, Josh Citron, Ri- Zhao Qiu, Xiongyi Cai, Alexey Gavryushin, Jiaqi Chen, Davide Liconti, Lawrence Y Zhu, et al. Egoverse: An egocentric human dataset for robot learning from around the world.arXiv preprint arXiv:2604.07607, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Xperience-10m: A large-scale egocentric mul- timodal dataset with structured 3d/4d annotations, 2026
Ropedia. Xperience-10m: A large-scale egocentric mul- timodal dataset with structured 3d/4d annotations, 2026. Dataset
2026
-
[37]
Runway gen-4: Ai video generation with world consistency
Runway. Runway gen-4: Ai video generation with world consistency. https://runwayml.com/research/ introducing-runway-gen-4, 2025
2025
-
[38]
Bridgedata v2: A dataset for robot learning at scale
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, An- dre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–
-
[39]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
2023
-
[41]
Learning Interactive Real-World Simulators
Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. arXiv preprint arXiv:2310.06114, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Cogvideox: Text-to-video diffusion models with an expert trans- former
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert trans- former. InInternational Conference on Learning Rep- resentations, volume 2025, pages 83048–83077, 2025
2025
-
[43]
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Gu- osheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
-
[44]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.