Position: Good Embodied Reward Models Need Bad Behavior Data
Pith reviewed 2026-06-28 17:16 UTC · model grok-4.3
The pith
Embodied reward models over-reward unsafe and suboptimal robot behaviors because they lack exposure to bad data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Embodied reward models trained only on successful behaviors systematically over-reward unsafe interactions, poor execution, and shortcut strategies that humans penalize; this occurs because of the scarcity of negative embodied data in existing datasets, and even modest exposure to such data improves alignment with human preferences while cutting costly false positives.
What carries the argument
The scarcity of negative embodied data in training sets, which prevents reward models from learning to penalize bad robot behaviors.
If this is right
- Reward models will continue to produce false positives on unsafe and suboptimal actions without negative data.
- Modest exposure to bad behavior data improves how closely reward models match human preferences.
- The community must curate and release existing bad robot data to close the gap.
- Synthetic bad data generation engines and decentralized physical evaluation systems are required for progress.
- Fine-grained benchmarks are needed to evaluate embodied reward models on penalizing specific failure modes.
Where Pith is reading between the lines
- Without negative data, reward models may limit the deployment safety of robots in unstructured environments.
- The same data imbalance could affect preference modeling in other sequential decision domains beyond robotics.
- Safe simulation of failure modes might allow faster iteration on reward models without real-world hazards.
Load-bearing premise
The over-rewarding of unsafe and suboptimal behaviors is caused primarily by the scarcity of negative embodied data rather than by model architecture, training objectives, or evaluation protocols.
What would settle it
Training the three analyzed reward models on datasets that include bad behavior data and finding that they still over-reward unsafe actions at the same rate when compared to human evaluators.
Figures

read the original abstract
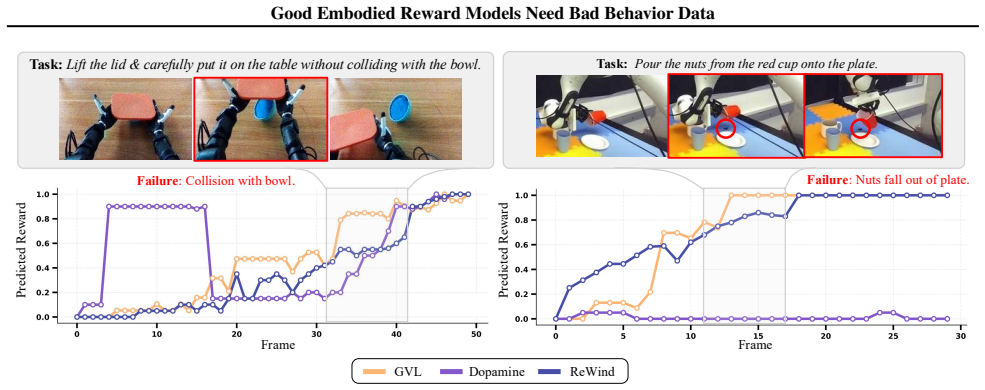
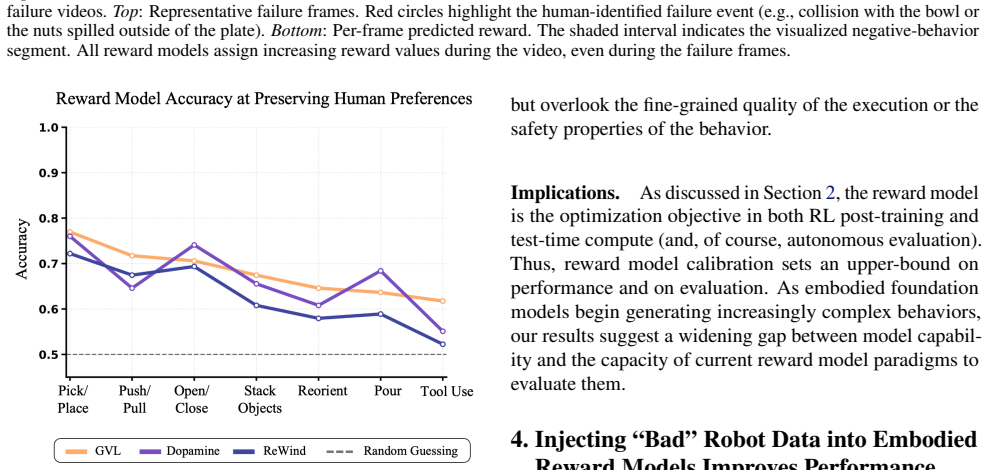
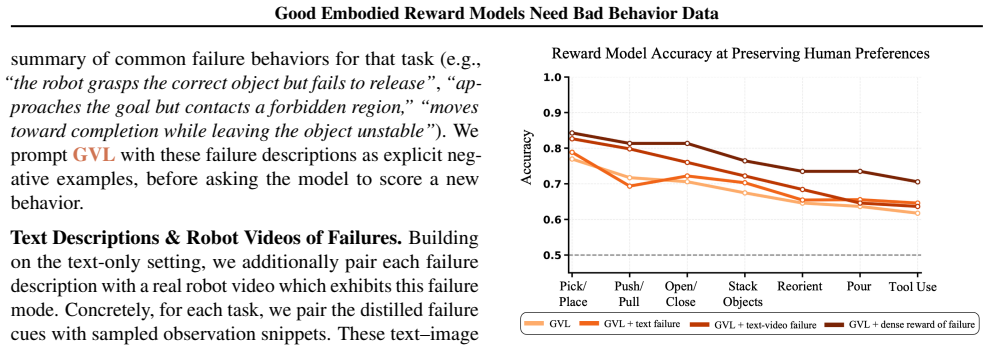
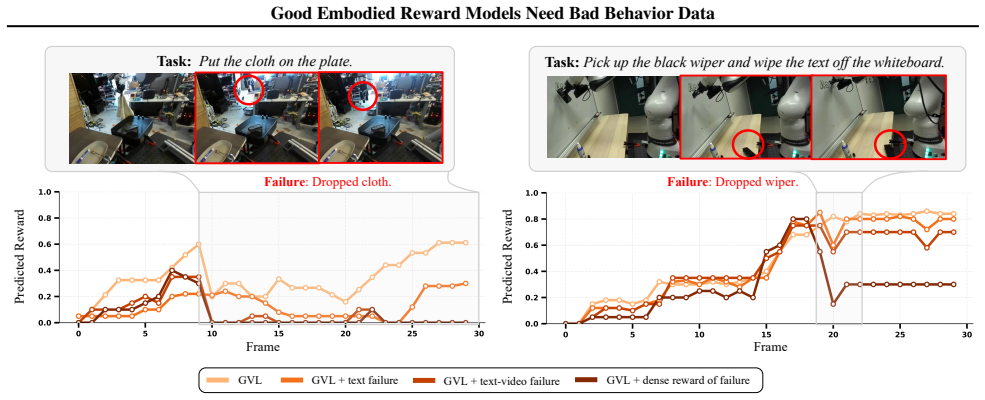
This position paper argues that to obtain reliable embodied reward models, the community must invest in ``bad'' robot data: failed, suboptimal, error-prone, and even hazardous behaviors. While reward models are central to any foundation model's lifecycle, today's embodied reward models are trained primarily on successful behaviors. We analyze three state-of-the-art embodied reward models and find that they systematically over-reward behaviors that real human evaluators would penalize, including unsafe interactions, poor execution, and shortcut strategies that only superficially satisfy tasks. We attribute these failures to a key data gap: the scarcity of negative embodied data which is costly to collect and often filtered out or withheld in existing robotics datasets. Furthermore, we show that even modest exposure to real bad behavior data can improve alignment with human preferences and reduce costly false positives. We therefore call on the embodied AI community to curate and release their bad robot data, build synthetic bad data generation engines, develop more decentralized physical evaluation systems, and design benchmarks for fine-grained embodied reward model evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This position paper argues that embodied reward models require exposure to 'bad' behaviors (failed, unsafe, suboptimal, or shortcut strategies) to align with human preferences, as current models trained primarily on successful trajectories systematically over-reward unsafe interactions, poor execution, and superficial task completions; the authors analyze three state-of-the-art models to document these failures, attribute them to the scarcity of negative embodied data in existing datasets, demonstrate that modest inclusion of real bad-behavior examples improves alignment, and issue a call to curate and release such data along with synthetic generators, decentralized evaluations, and fine-grained benchmarks.
Significance. If the reported over-rewarding patterns and the modest improvement from bad data hold under controlled conditions, the position identifies a systematic data-composition gap that directly affects safety and reliability of reward models used in embodied foundation models, potentially motivating community-wide changes in dataset curation practices.
major comments (1)
- [analysis of three state-of-the-art embodied reward models] The central attribution of the observed over-rewarding of unsafe and suboptimal behaviors to scarcity of negative data (rather than architecture, objective, or protocol choices) is not supported by any controlled comparison that holds model architecture, training objective, and evaluation protocol fixed while varying only the presence of bad-behavior examples. The analysis of the three models therefore leaves open the possibility that the failures arise from those other design decisions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the major comment below, agreeing that the attribution requires clarification given the nature of our position paper.
read point-by-point responses
-
Referee: The central attribution of the observed over-rewarding of unsafe and suboptimal behaviors to scarcity of negative data (rather than architecture, objective, or protocol choices) is not supported by any controlled comparison that holds model architecture, training objective, and evaluation protocol fixed while varying only the presence of bad-behavior examples. The analysis of the three models therefore leaves open the possibility that the failures arise from those other design decisions.
Authors: We agree that our analysis does not include a controlled experiment isolating negative data while fixing architecture, objective, and protocol. As a position paper, our central claim is observational: the three models share the characteristic of training predominantly on successful trajectories and exhibit similar over-rewarding patterns, which we hypothesize stems primarily from the data gap. We also report a modest empirical demonstration that adding real bad-behavior examples improves alignment. We acknowledge this does not rule out contributions from other design choices. We will revise the manuscript to (1) explicitly state that the attribution is a data-driven hypothesis rather than a causally isolated finding, (2) qualify the language around 'attribute these failures,' and (3) strengthen the call for future controlled studies. This revision will be made without altering the position's core argument. revision: yes
Circularity Check
No circularity: position paper rests on empirical analysis without derivations or self-referential reductions
full rationale
This is a position paper whose core argument consists of (1) an empirical analysis of three existing reward models showing over-rewarding of unsafe/suboptimal behaviors and (2) a call to curate bad-behavior data. No equations, fitted parameters presented as predictions, uniqueness theorems, or ansatzes appear in the provided text. The attribution of failures to data scarcity is stated as an interpretation of the observed results rather than a mathematical reduction to inputs. No self-citations are invoked as load-bearing premises. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y ., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y ., Cui, Y ., Ding, Y ., et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
J., Jain, A., Ku- ramshin, A., Eppner, C., Neary, C., Hu, E., Ramos, F., et al
Atreya, P., Pertsch, K., Lee, T., Kim, M. J., Jain, A., Ku- ramshin, A., Eppner, C., Neary, C., Hu, E., Ramos, F., et al. Roboarena: Distributed real-world evaluation of generalist robot policies. InProceedings of the Confer- ence on Robot Learning (CoRL 2025),
2025
-
[4]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y ., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKin- non, C., et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al. π0: A Vision-Language-Action flow model for general robot control.arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Dai, M., Liu, L., Bai, Y ., Liu, Y ., Wang, Z., Su, R., Chen, C., Lin, L., and Wu, X. Rover: Robot reward model as test-time verifier for vision-language-action model.arXiv preprint arXiv:2510.10975,
-
[7]
Gao, C., Zhang, H., Xu, Z., Cai, Z., and Shao, L. Flip: Flow- centric generative planning as general-purpose manipu- lation world model.arXiv preprint arXiv:2412.08261,
- [8]
-
[9]
Ctrl-World: A Controllable Generative World Model for Robot Manipulation
Guo, Y ., Shi, L. X., Chen, J., and Finn, C. Ctrl-world: A con- trollable generative world model for robot manipulation. arXiv preprint arXiv:2510.10125,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Training Agents Inside of Scalable World Models
Hafner, D., Yan, W., and Lillicrap, T. Training agents inside of scalable world models.arXiv preprint arXiv:2509.24527,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
9 Good Embodied Reward Models Need Bad Behavior Data Intelligence, P., Black, K., Brown, N., Darpinian, J., Dha- balia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al. π0.5:: a vision-language-action model with open- world generalization.arXiv preprint arXiv:2504.16054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Jangir, Y ., Zhang, Y ., Yamazaki, K., Zhang, C., Tu, K.-H., Ke, T.-W., Ke, L., Bisk, Y ., and Fragkiadaki, K. Rob- otarena ∞: Scalable robot benchmarking via real-to-sim translation.arXiv preprint arXiv:2510.23571,
-
[13]
Pretrained embeddings as a behavior specification mechanism.arXiv preprint arXiv:2503.02012,
Kapoor, P., Hammer, A., Kapoor, A., Leung, K., and Kang, E. Pretrained embeddings as a behavior specification mechanism.arXiv preprint arXiv:2503.02012,
-
[14]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M. K., Chen, L. Y ., Ellis, K., et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Kress-Gazit, H., Hashimoto, K., Kuppuswamy, N., Shah, P., Horgan, P., Richardson, G., Feng, S., and Burchfiel, B. Robot learning as an empirical science: Best practices for policy evaluation.arXiv preprint arXiv:2409.09491,
-
[16]
Kwok, J., Agia, C., Sinha, R., Foutter, M., Li, S., Stoica, I., Mirhoseini, A., and Pavone, M. Robomonkey: Scaling test-time sampling and verification for vision-language- action models.arXiv preprint arXiv:2506.17811,
-
[17]
Lee, T., Wagenmaker, A., Pertsch, K., Liang, P., Levine, S., and Finn, C. Roboreward: General-purpose vision- language reward models for robotics.arXiv preprint arXiv:2601.00675,
-
[18]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Makoviychuk, V ., Wawrzyniak, L., Guo, Y ., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470,
work page internal anchor Pith review Pith/arXiv arXiv
- [19]
-
[20]
NVIDIA, Cao, Y ., de Lutio, R., Fidler, S., Cobo, G
URL https://arxiv.org/abs/2503.03848. NVIDIA, Cao, Y ., de Lutio, R., Fidler, S., Cobo, G. G., Gojcic, Z., Igl, M., Ivanovic, B., Karkus, P., Esturo, J. M., Pavone, M., Smith, A., Tanimura, E., Tyszkiewicz, M., Watson, M., Wu, Q., and Zhang, L. Alpasim: A modular, lightweight, and data-driven research sim- ulator for autonomous driving, October
-
[21]
Accessed: 2026-01-28
URL https: //openai.com/index/introducing-gpt-5/. Accessed: 2026-01-28. OpenGVL Team. OpenGVL: Task completion leader- board for evaluating VLMs as temporal value es- timators. https://huggingface.co/spaces/ OpenGVL/OpenGVL,
2026
-
[22]
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al
Accessed: 2025-09-04. Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744,
2025
-
[23]
Generating robot constitutions & benchmarks for semantic safety.Conference on Robot Learning (CoRL) 2025,
Sermanet, P., Majumdar, A., Irpan, A., Kalashnikov, D., and Sindhwani, V . Generating robot constitutions & benchmarks for semantic safety.Conference on Robot Learning (CoRL) 2025,
2025
- [24]
-
[25]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Project page: https://asimov-benchmark.github.io. 10 Good Embodied Reward Models Need Bad Behavior Data Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test- time compute optimally can be more effective than scal- ing model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Tan, H., Chen, S., Xu, Y ., Wang, Z., Ji, Y ., Chi, C., Lyu, Y ., Zhao, Z., Chen, X., Co, P., et al. Robo-dopamine: Gen- eral process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703,
-
[27]
Tian, R., Wu, Y ., Xu, C., Tomizuka, M., Malik, J., and Bajcsy, A. Maximizing alignment with minimal feedback: Efficiently learning rewards for visuomotor robot policy alignment.arXiv preprint arXiv:2412.04835,
-
[28]
Wang, Y ., Luo, W., Bai, J., Cao, Y ., Che, T., Chen, K., Chen, Y ., Diamond, J., Ding, Y ., Ding, W., et al. Alpamayo-r1: Bridging reasoning and action prediction for generaliz- able autonomous driving in the long tail.arXiv preprint arXiv:2511.00088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Wu, Y ., Tian, R., Swamy, G., and Bajcsy, A. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment.arXiv preprint arXiv:2502.01828,
-
[30]
Xiao, W., Lin, H., Peng, A., Xue, H., He, T., Xie, Y ., Hu, F., Wu, J., Luo, Z., Fan, L., et al. Self-improving vision- language-action models with data generation via residual rl.arXiv preprint arXiv:2511.00091,
-
[31]
Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP,
Yue, Y ., Yuan, Y ., Yu, Q., Zuo, X., Zhu, R., Xu, W., Chen, J., Wang, C., Fan, T., Du, Z., et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP,
2025
-
[32]
Zhai, S., Zhang, Q., Zhang, T., Huang, F., Zhang, H., Zhou, M., Zhang, S., Liu, L., Lin, S., and Pang, J. A vision- language-action-critic model for robotic real-world rein- forcement learning.arXiv preprint arXiv:2509.15937,
-
[33]
A., Lim, J
Zhang, J., Luo, Y ., Anwar, A., Sontakke, S. A., Lim, J. J., Thomason, J., Biyik, E., and Zhang, J. Rewind: Language-guided rewards teach robot policies without new demonstrations. InProceedings of the Conference on Robot Learning (CoRL 2025),
2025
-
[34]
Grape: Gen- eralizing robot policy via preference alignment.arXiv preprint arXiv:2411.19309,
Zhang, Z., Zheng, K., Chen, Z., Jang, J., Li, Y ., Han, S., Wang, C., Ding, M., Fox, D., and Yao, H. Grape: Gen- eralizing robot policy via preference alignment.arXiv preprint arXiv:2411.19309,
-
[35]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Zhou, G., Pan, H., LeCun, Y ., and Pinto, L. Dino-wm: World models on pre-trained visual features enable zero- shot planning.arXiv preprint arXiv:2411.04983,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Fine-Tuning Language Models from Human Preferences
Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[37]
frame_number
Optional module A: In-context reference behaviors (with known rewards). Each reference behavior is a set of frames shown in random order: •Reference behavior{d}, frame{j}, known reward:{r}.[DEMO IMAGE] Optional module B: Task-specific failure descriptions (negative cues). Use only if the current framevisibly matches; donotassume failures occurred. If a fr...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.