OPD+: Rethinking the Advantage Design for On-Policy Distillation
Pith reviewed 2026-06-28 17:22 UTC · model grok-4.3
The pith
Stop-gradient in on-policy distillation leads to biased advantage estimates for f-divergences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
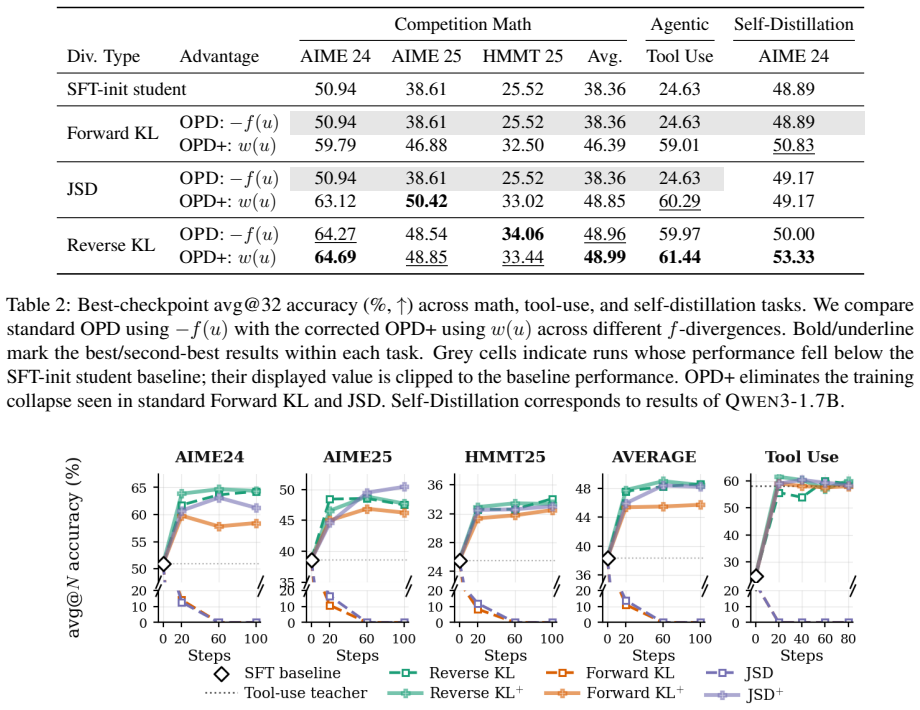
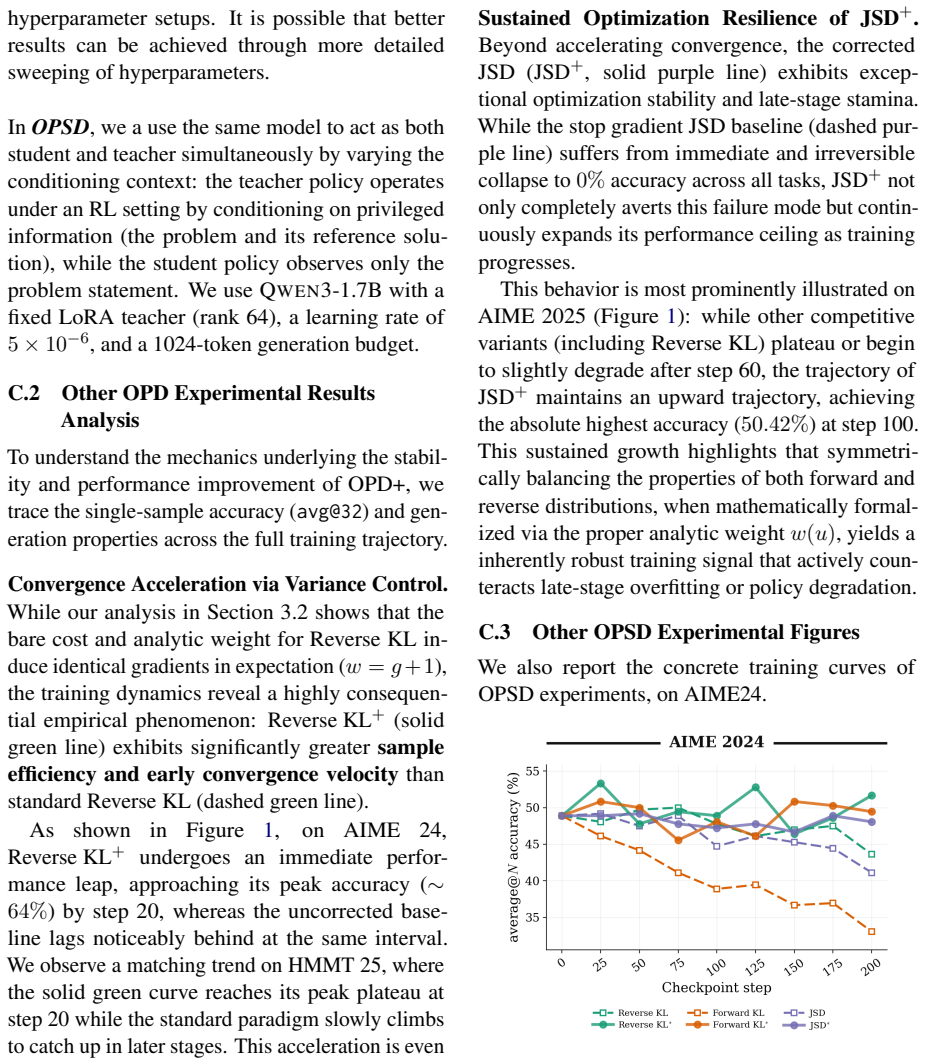
We prove that general stop-gradient operation would lead to biased estimates of the reward objective and corresponding gradient for general divergence functions. We propose OPD+, the corrected version of OPD that demonstrates improved performance over the baseline KL approach and also supports the choice of various f-divergence.
What carries the argument
f-divergence framework for on-policy distillation with unbiased advantage estimation that avoids stop-gradient on the student likelihood term.
If this is right
- OPD+ yields improved performance compared to the KL baseline on reasoning benchmarks.
- Multiple f-divergence functions can be used in the distillation objective without bias.
- The corrected advantage design applies directly to existing on-policy distillation setups.
- The method is validated on mathematical reasoning and tool-use tasks.
Where Pith is reading between the lines
- Similar bias issues may exist in other RL-based distillation or alignment methods that use stop-gradient.
- Testing OPD+ with different f-divergences could reveal which ones perform best for specific tasks.
- The framework might extend to other sequence generation tasks beyond language models.
Load-bearing premise
The on-policy distillation objective can be expressed as an f-divergence between student-generated and teacher distributions such that the stop-gradient operation is the only source of bias in the advantage estimator.
What would settle it
Running the gradient computation for a non-KL f-divergence with and without stop-gradient and checking if the estimates match the unbiased version, or observing no improvement from OPD+ on the benchmarks.
Figures
read the original abstract
On-policy distillation (OPD) is a widely used technique to transfer capabilities from capable teacher language models to the base student models, and can be formulated in a reinforcement learning style objective using student generated rollouts. Yet, despite the divergence reward being dependent on student model likelihood, existing works usually adopt a stop gradient design primarily for stability, which makes the resulting advantage estimation questionable. In this work, we provide a generic optimization framework based on f-divergence between the student and teacher, and mathematically revisit whether such design space is valid. We prove that general stop-gradient operation would lead to biased estimates of the reward objective and corresponding gradient for general divergence functions. We propose OPD+, the corrected version of OPD that demonstrates improved performance over the baseline KL approach and also supports the choice of various f-divergence. We validate our findings on mathematical reasoning and tool-use benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the stop-gradient operation commonly used in on-policy distillation (OPD) for stability introduces bias into the reward objective and its gradient when the objective is expressed as an f-divergence between student and teacher distributions. It presents a generic optimization framework based on f-divergences, provides a mathematical proof of this bias for general divergences, proposes the bias-corrected OPD+ variant, and reports improved empirical performance over the KL baseline on mathematical reasoning and tool-use benchmarks while supporting multiple f-divergences.
Significance. If the central mathematical proof holds, the work supplies a principled correction to a standard design choice in RL-style distillation of language models, replacing an ad-hoc stop-gradient with an unbiased advantage estimator. The generality of the f-divergence framework and the empirical gains on reasoning/tool-use tasks constitute a concrete advance; the explicit derivation of the bias term is a strength that can be checked independently of any particular implementation.
minor comments (3)
- [Abstract] The abstract states that OPD+ 'supports the choice of various f-divergence' but does not list which specific divergences (beyond KL) were implemented and evaluated; adding this list would clarify the scope of the empirical claim.
- [Experiments] The experimental section should report the number of random seeds, standard deviations, and any statistical tests for the reported improvements; without these the benchmark gains are difficult to interpret as robust.
- [Preliminaries] Notation for the advantage estimator (e.g., the precise placement of the stop-gradient operator relative to the divergence term) should be introduced once in a dedicated preliminary section rather than inline in the proof.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, accurate summary of our contributions, and recommendation for minor revision. We are glad the generality of the f-divergence framework and the explicit bias derivation are viewed as strengths.
Circularity Check
No significant circularity; derivation is a direct mathematical proof
full rationale
The paper's central contribution is a mathematical proof that stop-gradient operations introduce bias in f-divergence reward objectives and gradients for on-policy distillation, followed by a corrected OPD+ formulation. This is presented as an analytical result on an existing objective rather than any fitted parameter, self-citation chain, or ansatz smuggled from prior work. The derivation chain stands independently of the data or assumptions it analyzes, with no load-bearing steps that reduce to the paper's own inputs by construction. The reader's assessment of score 2 aligns with minor self-citation tolerance but does not indicate circularity here.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption On-policy distillation objective can be formulated as an f-divergence between student and teacher distributions
Forward citations
Cited by 1 Pith paper
-
A Formula-Driven Survey and Research Agenda for On-Policy Distillation
A survey creates a taxonomy for on-policy distillation in LLMs that separates temporal credit assignment from vocabulary-level probability routing.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , volume=
On-policy distillation of language models: Learning from self-generated mistakes , author=. International Conference on Learning Representations , volume=
-
[2]
A Comedy of Estimators: On
Shah, Vedant and Obando-Ceron, Johan and Jain, Vineet and Bartoldson, Brian and Kailkhura, Bhavya and Mittal, Sarthak and Berseth, Glen and Castro, Pablo Samuel and Bengio, Yoshua and Malkin, Nikolay , journal=. A Comedy of Estimators: On
-
[3]
On the design of
Zhang, Yifan and Liu, Yifeng and Yuan, Huizhuo and Yuan, Yang and Gu, Quanquan and Yao, Andrew Chi-Chih , journal=. On the design of
-
[4]
Improved techniques for fine-tuning flow models via adjoint matching: a deterministic control pipeline , author=. arXiv preprint arXiv:2605.06583 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2403.06279 , year=
Fine-tuning of diffusion models via stochastic control: entropy regularization and beyond , author=. arXiv preprint arXiv:2403.06279 , year=
-
[6]
International Conference on Learning Representations , volume=
Correlated proxies: a new definition and improved mitigation for reward hacking , author=. International Conference on Learning Representations , volume=
-
[7]
Advances in neural information processing systems , volume=
Flow density control: generative optimization beyond entropy-regularized fine-tuning , author=. Advances in neural information processing systems , volume=
-
[8]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[9]
Xiao, Bangjun and Xia, Bingquan and Yang, Bo and Gao, Bofei and Shen, Bowen and Zhang, Chen and He, Chenhong and Lou, Chiheng and Luo, Fuli and Wang, Gang and others , journal=. Mi
-
[10]
Zeng, Aohan and Lv, Xin and Hou, Zhenyu and Du, Zhengxiao and Zheng, Qinkai and Chen, Bin and Yin, Da and Ge, Chendi and Huang, Chenghua and Xie, Chengxing and others , journal=. G
-
[11]
Nemotron-
Yang, Zhuolin and Liu, Zihan and Chen, Yang and Dai, Wenliang and Wang, Boxin and Lin, Sheng-Chieh and Lee, Chankyu and Chen, Yangyi and Jiang, Dongfu and He, Jiafan and others , journal=. Nemotron-
-
[12]
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author =
-
[13]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Machine learning , volume=
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
1992
-
[15]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Beyond reverse
Wang, Chaoqi and Jiang, Yibo and Yang, Chenghao and Liu, Han and Chen, Yuxin , booktitle=. Beyond reverse
-
[17]
arXiv preprint arXiv:2506.09477 , year=
Tang, Yunhao and Munos, R. On a few pitfalls in. arXiv preprint arXiv:2506.09477 , year=
-
[18]
Self-Distillation Enables Continual Learning
Self-Distillation Enables Continual Learning , author=. arXiv preprint arXiv:2601.19897 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Reinforcement Learning via Self-Distillation
Reinforcement Learning via Self-Distillation , author=. arXiv preprint arXiv:2601.20802 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Andrew Bagnell, Aarti Singh, and Andrea Zanette
Expanding the Capabilities of Reinforcement Learning via Text Feedback , author=. arXiv preprint arXiv:2602.02482 , year=
-
[21]
A Survey of On-Policy Distillation for Large Language Models
A survey of on-policy distillation for large language models , author=. arXiv preprint arXiv:2604.00626 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases , author=. arXiv preprint arXiv:2306.05301 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
2025 , eprint=
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.