Where to Look: Can Foundation Models Reach a Target Viewpoint Through Active Exploration?
Pith reviewed 2026-06-28 17:07 UTC · model grok-4.3
The pith
Foundation models reach at most 12% success reproducing a target viewpoint through active 3D movement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On the evaluation split of TVRBench, strongest open-source and closed-source models reach only 7.8% and 12.0% success at reproducing a target viewpoint. Visual-action SFT raises a 9B open-source model to 50.8% success while multi-turn GRPO from live simulator rollouts reaches 51.4% overall; CoT supervision and single-turn GRPO degrade closed-loop performance. The dominant failure modes are inability to maintain multi-turn visual history and sharp drops when viewpoint change requires body translation rather than in-place rotation.
What carries the argument
The TVR post-training framework that combines expert-trajectory visual-action SFT with on-policy multi-turn GRPO rollouts inside the simulator.
If this is right
- Multi-turn visual history handling must be improved before reliable active viewpoint reproduction is possible.
- Mapping observed spatial discrepancies to body translation actions remains a distinct bottleneck from rotation-only control.
- CoT supervision and single-turn GRPO can reduce closed-loop success even when they improve open-loop metrics.
- TVRBench functions as a reusable testbed for training and measuring active 3D perception in foundation models.
Where Pith is reading between the lines
- If the simulator-to-real gap is small, the same post-training recipe could be applied directly to mobile robots for view-based navigation.
- The observed translation bottleneck suggests that future models may need explicit 3D occupancy or depth prediction heads before action generation.
- Low baseline success indicates that current vision-language models still treat 3D scenes largely as static image collections rather than controllable environments.
Load-bearing premise
Success rates measured inside the TVRBench indoor simulator reflect the spatial intelligence required for real-world embodied tasks.
What would settle it
Run the best post-trained model on a physical robot in a real indoor room and record the fraction of episodes in which the camera view matches the target image within a fixed tolerance after a bounded number of moves.
Figures


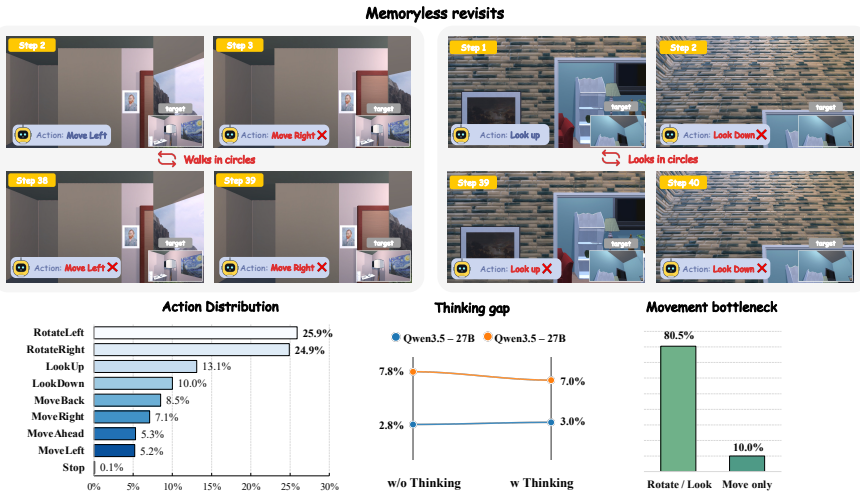
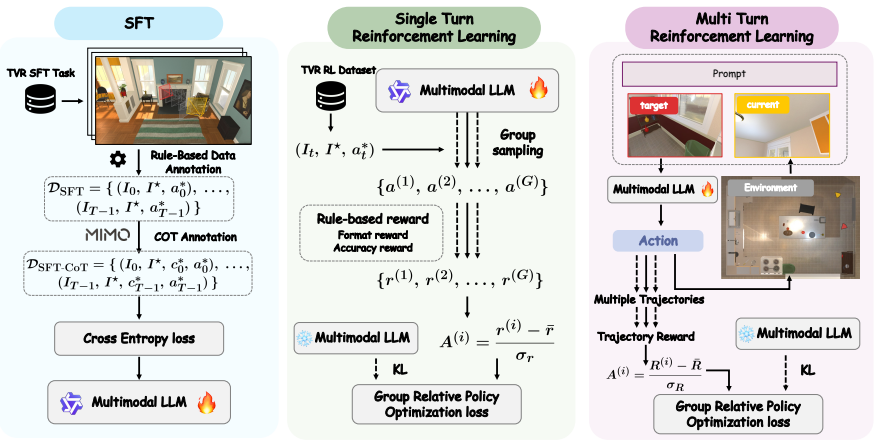







read the original abstract
Humans can reproduce the viewpoint specified by a target image through active head and body motion, yet spatial intelligence in foundation models has largely been studied as passive understanding of pre-collected observations. We introduce Target Viewpoint Reproduction (TVR) -- an active task where an agent adjusts its viewpoint in a 3D environment until its observation matches a given target image -- and TVRBench, an indoor-simulation benchmark spanning scene scale and target-view visual richness. TVR is far from solved: on the evaluation split, the strongest open-source and closed-source models reach only 7.8% and 12.0% success. Fine-grained analysis identifies two consistent bottlenecks: off-the-shelf models struggle with multi-turn visual history, and performance drops sharply when viewpoint reproduction requires body translation rather than in-place rotation, exposing a gap in mapping spatial discrepancies to embodied movement. To study reducing this gap, we build a unified TVR post-training framework covering expert-trajectory SFT, rationale-supervised CoT-SFT, offline Single-turn GRPO, and on-policy Multi-turn GRPO from live simulator rollouts. Visual-action SFT supplies the main gain, raising a 9B open-source model to 50.8% success; Multi-turn GRPO provides targeted multi-room refinement and reaches 51.4% overall, while CoT supervision and Single-turn GRPO degrade closed-loop performance. These results establish TVRBench as a testbed for measuring and training foundation models that actively perceive and act in 3D environments. Our code, data, and models are available at https://github.com/aim-uofa/TVRBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Target Viewpoint Reproduction (TVR) task, in which an agent must actively adjust its viewpoint in a 3D indoor environment until its observation matches a provided target image, along with the TVRBench simulator benchmark spanning scene scale and target-view richness. Zero-shot evaluation shows low success (7.8% strongest open-source, 12.0% closed-source). A unified post-training framework is presented that includes expert-trajectory SFT, rationale-supervised CoT-SFT, offline Single-turn GRPO, and on-policy Multi-turn GRPO; visual-action SFT raises a 9B model to 50.8% success while Multi-turn GRPO reaches 51.4% overall. Code, data, and models are released.
Significance. If the performance deltas and failure-mode analysis hold, the work supplies a reproducible testbed and training recipe for active spatial reasoning in foundation models, a capability that has received less attention than passive image understanding. The explicit release of code, data, and models is a concrete strength that supports follow-on research. The reported bottlenecks (multi-turn history handling and translation versus rotation) supply falsifiable targets for subsequent method development.
major comments (1)
- [Benchmark construction and evaluation split] Benchmark construction and evaluation split: the manuscript does not supply sufficient detail on how the evaluation scenes and target images were selected to guarantee no overlap with any training trajectories or to balance scene scale and visual richness; without these controls the reported 7.8% and 12.0% zero-shot figures cannot be confidently interpreted as general measures of spatial intelligence rather than simulator-specific artifacts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: Benchmark construction and evaluation split: the manuscript does not supply sufficient detail on how the evaluation scenes and target images were selected to guarantee no overlap with any training trajectories or to balance scene scale and visual richness; without these controls the reported 7.8% and 12.0% zero-shot figures cannot be confidently interpreted as general measures of spatial intelligence rather than simulator-specific artifacts.
Authors: We agree that the current manuscript provides insufficient detail on these aspects of benchmark construction. In the revised version we will expand the TVRBench section with a dedicated subsection that (1) describes the scene selection criteria used to span scale and target-view richness, (2) specifies how target images were sampled within each scene, and (3) documents the procedure that ensures the evaluation split is disjoint from all trajectories used for expert-trajectory SFT and GRPO training. These additions will allow readers to assess whether the reported zero-shot numbers reflect general spatial capabilities. revision: yes
Circularity Check
No circularity; results are direct empirical measurements
full rationale
The paper introduces a new task (TVR) and benchmark (TVRBench), then reports success rates from model evaluations and post-training experiments inside the simulator. These are measured outcomes on held-out splits, not quantities derived from the paper's own equations, fitted parameters renamed as predictions, or self-citation chains. No load-bearing derivation steps exist that reduce to inputs by construction; the central claims are scoped to performance deltas within the described simulator setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The indoor simulation environment provides accurate visual observations and movement controls for the agent.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Is a picture worth a thousand words? delving into spatial reasoning for vision language models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
Advances in Neural Information Processing Systems , volume=
Spatialrgpt: Grounded spatial reasoning in vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Transactions of the Association for Computational Linguistics , volume=
Visual spatial reasoning , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[5]
and Girshick, Ross , title =
Johnson, Justin and Hariharan, Bharath and van der Maaten, Laurens and Fei-Fei, Li and Lawrence Zitnick, C. and Girshick, Ross , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Seeground: See and ground for zero-shot open-vocabulary 3d visual grounding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
Structural Priors for Vision Workshop at ICCV'25 , year=
Spatial mental modeling from limited views , author=. Structural Priors for Vision Workshop at ICCV'25 , year=
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
3d concept learning and reasoning from multi-view images , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Seeing from another perspective: Evaluating multi-view understanding in mllms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[12]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Thinking in space: How multimodal large language models see, remember, and recall spaces , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[13]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Vlm4d: Towards spatiotemporal awareness in vision language models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Navgpt: Explicit reasoning in vision-and-language navigation with large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Openeqa: Embodied question answering in the era of foundation models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[18]
2017 IEEE international conference on robotics and automation (ICRA) , pages=
Target-driven visual navigation in indoor scenes using deep reinforcement learning , author=. 2017 IEEE international conference on robotics and automation (ICRA) , pages=. 2017 , organization=
2017
-
[19]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[22]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[24]
The Fourteenth International Conference on Learning Representations , year=
Theory of Space: Can Foundation Models Construct Spatial Beliefs through Active Exploration? , author=. The Fourteenth International Conference on Learning Representations , year=
-
[26]
2026 , eprint=
ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop , author=. 2026 , eprint=
2026
-
[30]
Advances in neural information processing systems , volume=
Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence , author=. Advances in neural information processing systems , volume=
-
[35]
NeurIPS , year=
Matt Deitke and Eli VanderBilt and Alvaro Herrasti and Luca Weihs and Jordi Salvador and Kiana Ehsani and Winson Han and Eric Kolve and Ali Farhadi and Aniruddha Kembhavi and Roozbeh Mottaghi , title=. NeurIPS , year=
-
[36]
arXiv , year=
Eric Kolve and Roozbeh Mottaghi and Winson Han and Eli VanderBilt and Luca Weihs and Alvaro Herrasti and Daniel Gordon and Yuke Zhu and Abhinav Gupta and Ali Farhadi , title=. arXiv , year=
-
[40]
2026 , howpublished=
MiMo-V2.5-Pro , author=. 2026 , howpublished=
2026
-
[41]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko S \"u nderhauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3674--3683
2018
- [42]
-
[43]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, and 1 others. 2024. _0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. 2024. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455--14465
2024
-
[45]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. 2024. Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems, 37:135062--135093
2024
-
[46]
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, and Roozbeh Mottaghi. 2022. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation . In NeurIPS. Outstanding Paper Award
2022
-
[47]
Google DeepMind . 2026. https://deepmind.google/models/model-cards/gemini-3-1-pro/ Gemini 3.1 Pro . Model Card
2026
-
[48]
Yining Hong, Chunru Lin, Yilun Du, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. 2023. 3d concept learning and reasoning from multi-view images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9202--9212
2023
-
[49]
Yining Hong, Jiageng Liu, Han Yin, Manling Li, Leonidas Guibas, Li Fei-Fei, Jiajun Wu, and Yejin Choi. 2026. https://arxiv.org/abs/2605.18746 Esi-bench: Towards embodied spatial intelligence that closes the perception-action loop . Preprint, arXiv:2605.18746
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Lawrence Zitnick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. 2017. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2017
-
[52]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, and 1 others. 2024. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Daniel Gordon, Yuke Zhu, Abhinav Gupta, and Ali Farhadi. 2017. AI2-THOR: An Interactive 3D Environment for Visual AI . arXiv
2017
- [54]
- [55]
-
[56]
Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Junwei Liang. 2025. Seeground: See and ground for zero-shot open-vocabulary 3d visual grounding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 3707--3717
2025
- [57]
-
[58]
Fangyu Liu, Guy Emerson, and Nigel Collier. 2023. Visual spatial reasoning. Transactions of the Association for Computational Linguistics, 11:635--651
2023
- [59]
-
[60]
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, and 1 others. 2024. Openeqa: Embodied question answering in the era of foundation models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16488--16498
2024
-
[61]
Qwen Team . 2026 a . https://qwen.ai/blog?id=qwen3.5 Qwen3.5 : Towards native multimodal agents
2026
-
[62]
Qwen Team . 2026 b . https://qwen.ai/blog?id=qwen3.6-27b Qwen3.6-27B : Flagship-level coding in a 27B dense model
2026
-
[63]
Qwen Team . 2026 c . https://qwen.ai/blog?id=qwen3.6-35b-a3b Qwen3.6-35B-A3B : Agentic coding power, now open to all
2026
- [64]
-
[65]
Koya Sakamoto, Taiki Miyanishi, Daichi Azuma, Shuhei Kurita, Shu Morikuni, Naoya Chiba, Motoaki Kawanabe, Yusuke Iwasawa, and Yutaka Matsuo. 2026. E3vs-bench: A benchmark for viewpoint-dependent active perception in 3d gaussian splatting scenes. arXiv preprint arXiv:2604.17969
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, and 1 others. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. 2024. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. Advances in Neural Information Processing Systems, 37:75392--75421
2024
-
[69]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. 2026. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. Advances in neural information processing systems, 38:13569--13597
2026
-
[70]
Xiaomi MiMo Team . 2026. Mimo-v2.5-pro. https://huggingface.co/collections/XiaomiMiMo/mimo-v25
2026
-
[71]
Runsen Xu, Weiyao Wang, Hao Tang, Xingyu Chen, Xiaodong Wang, Fu-Jen Chu, Dahua Lin, Matt Feiszli, and Kevin J Liang. 2025. Multi-spatialmllm: Multi-frame spatial understanding with multi-modal large language models. arXiv preprint arXiv:2505.17015
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. 2025 a . Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632--10643
2025
-
[73]
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, and 1 others. 2025 b . Mmsi-bench: A benchmark for multi-image spatial intelligence. arXiv preprint arXiv:2505.23764
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Chun-Hsiao Yeh, Chenyu Wang, Shengbang Tong, Ta-Ying Cheng, Ruoyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, and Yi Ma. 2026. Seeing from another perspective: Evaluating multi-view understanding in mllms. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12000--12008
2026
-
[75]
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, and 1 others. 2025. Spatial mental modeling from limited views. In Structural Priors for Vision Workshop at ICCV'25
2025
- [76]
- [77]
- [78]
-
[79]
Pingyue Zhang, Zihan Huang, Yue Wang, Jieyu Zhang, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chandrasegaran, Ruohan Zhang, Yejin Choi, and 1 others. 2026. Theory of space: Can foundation models construct spatial beliefs through active exploration? In The Fourteenth International Conference on Learning Representations
2026
-
[80]
Gengze Zhou, Yicong Hong, and Qi Wu. 2024. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7641--7649
2024
-
[81]
Shijie Zhou, Alexander Vilesov, Xuehai He, Ziyu Wan, Shuwang Zhang, Aditya Nagachandra, Di Chang, Dongdong Chen, Xin Eric Wang, and Achuta Kadambi. 2025. Vlm4d: Towards spatiotemporal awareness in vision language models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8600--8612
2025
-
[82]
Muzhi Zhu, Hao Zhong, Canyu Zhao, Zongze Du, Zheng Huang, Mingyu Liu, Hao Chen, Cheng Zou, Jingdong Chen, Ming Yang, and 1 others. 2025 a . Active-o3: Empowering multimodal large language models with active perception via grpo. arXiv preprint arXiv:2505.21457
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[83]
Yuke Zhu, Roozbeh Mottaghi, Eric Kolve, Joseph J Lim, Abhinav Gupta, Li Fei-Fei, and Ali Farhadi. 2017. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In 2017 IEEE international conference on robotics and automation (ICRA), pages 3357--3364. ieee
2017
-
[84]
Ziyu Zhu, Xilin Wang, Yixuan Li, Zhuofan Zhang, Xiaojian Ma, Yixin Chen, Baoxiong Jia, Wei Liang, Qian Yu, Zhidong Deng, and 1 others. 2025 b . Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8120--8132
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.