ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop
Pith reviewed 2026-05-20 10:47 UTC · model grok-4.3
pith:EBSGR3OZ Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{EBSGR3OZ}
Prints a linked pith:EBSGR3OZ badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Spatial intelligence in agents improves by actively choosing actions to gather evidence and close the perception-action loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
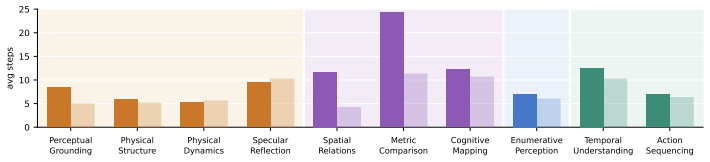
The central claim is that recasting the observer as an actor in the perception-action loop reveals action blindness as the dominant failure mode in spatial tasks. In ESI-Bench, agents decide which abilities to use and in what order to resolve ambiguities involving occlusion, dynamics, containment, and functionality. Active exploration yields better performance than passive baselines, while random multi-view inputs add noise; explicit 3D grounding offers partial stabilization on depth tasks yet can distort relations when imperfect. Most errors trace to poor action selections rather than perception limits, and models do not exhibit human-like behavior of seeking falsifying viewpoints to revise
What carries the argument
The perception-action loop, in which agents actively sequence perception, locomotion, and manipulation to accumulate evidence and update spatial reasoning.
If this is right
- Active exploration substantially outperforms passive counterparts and random multi-view inputs.
- Most failures stem from action blindness that produces poor observations and cascading errors rather than from weak perception.
- Explicit 3D grounding stabilizes reasoning on depth-sensitive tasks but imperfect representations can harm spatial relations more than 2D baselines.
- Models commit prematurely with high confidence regardless of evidence quality, unlike humans who seek falsifying viewpoints.
- Agents spontaneously discover emergent spatial strategies without explicit instructions.
Where Pith is reading between the lines
- Future models may need built-in mechanisms to monitor uncertainty and actively seek disconfirming evidence.
- Benchmarks in navigation or manipulation could gain from similar requirements to close the action loop.
- Robotic systems would likely benefit from training that rewards information-gathering actions over pure perception accuracy.
- The metacognitive gap may require new architectures rather than scaling existing perception or interaction alone.
Load-bearing premise
The 10 task categories and 29 subcategories sufficiently isolate the perception-action loop without confounding effects from simulator physics or task design choices.
What would settle it
A test that supplies models with oracle action sequences matching human strategies and measures whether performance gaps and premature high-confidence commitments disappear.
Figures








read the original abstract
Spatial intelligence unfolds through a perception-action loop: agents act to acquire observations, and reason about how observations vary as a function of action. Rather than passively processing what is seen, they actively uncover what is unseen - occluded structure, dynamics, containment, and functionality that cannot be resolved from passive sensing alone. We move beyond prior formulations of spatial intelligence that assume oracle observations by recasting the observer as an actor. We introduce ESI-BENCH, a comprehensive benchmark for embodied spatial intelligence spanning 10 task categories and 29 subcategories built on OmniGibson, grounded in Spelke's core knowledge systems. Agents must decide what abilities to deploy - perception, locomotion, and manipulation - and how to sequence them to actively accumulate task-relevant evidence. We conduct extensive experiments on state-of-the-art MLLMs and find that active exploration substantially outperforms passive counterparts, with agents spontaneously discovering emergent spatial strategies without explicit instructions, while random multi-view often adds noise rather than signal despite consuming far more images. Most failures stem not from weak perception but from action blindness: poor action choices lead to poor observations, which in turn drive cascading errors. While explicit 3D grounding stabilizes reasoning on depth-sensitive tasks, imperfect 3D representation proves more harmful than 2D baselines by distorting spatial relations. Human studies further reveal that unlike humans who seek falsifying viewpoints and revise beliefs under contradiction, models commit prematurely with high confidence regardless of evidence quality, exposing a metacognitive gap that neither better perception nor more embodied interaction alone can close.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ESI-Bench, a benchmark for embodied spatial intelligence with 10 task categories and 29 subcategories grounded in Spelke's core knowledge systems and implemented in OmniGibson. It evaluates MLLMs on active vs. passive observation, reporting that active exploration substantially outperforms passive baselines, that most failures arise from 'action blindness' (poor action choices leading to poor observations and cascading errors) rather than weak perception, that explicit 3D grounding can harm performance on some tasks, and that models commit prematurely with high confidence unlike humans who seek falsifying viewpoints.
Significance. If the central empirical claims hold after addressing controls, the work would be significant for highlighting the perception-action loop as a key bottleneck in current multimodal models and for providing a cognitively grounded benchmark that distinguishes active strategies from passive or random multi-view approaches. The direct human-model comparisons and identification of a metacognitive gap offer concrete directions for embodied AI development.
major comments (2)
- [Experiments / Results] The attribution of most failures to action blindness rather than perception (abstract and results sections) is load-bearing for the central claim but rests on the assumption that passive observation quality is not systematically degraded by OmniGibson dynamics. No ablations are reported that hold perception fixed while varying only action sequencing or that quantify passive performance gains under oracle navigation or stabilized physics.
- [Benchmark Construction] The claim that the 10 categories / 29 subcategories cleanly isolate the perception-action loop (task design section) requires evidence that simulator-specific factors (object stability, occlusion patterns, locomotion costs) do not confound passive baselines in ways that active policies incidentally mitigate. Without such checks, the performance gap cannot be confidently attributed to action choice.
minor comments (2)
- [Experiments] Clarify the exact statistical tests and sample sizes used for active vs. passive and model vs. human comparisons; the abstract reports directional results but details on controls and significance levels are needed for reproducibility.
- [Results] The statement that 'random multi-view often adds noise rather than signal' should be supported with quantitative metrics (e.g., accuracy deltas or error breakdowns) rather than qualitative description.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major concerns regarding the attribution of failures to action blindness and the potential confounding factors in the benchmark construction. We have revised the manuscript to include additional ablations and analyses to strengthen these claims.
read point-by-point responses
-
Referee: [Experiments / Results] The attribution of most failures to action blindness rather than perception (abstract and results sections) is load-bearing for the central claim but rests on the assumption that passive observation quality is not systematically degraded by OmniGibson dynamics. No ablations are reported that hold perception fixed while varying only action sequencing or that quantify passive performance gains under oracle navigation or stabilized physics.
Authors: We agree that these additional controls would bolster the central claim. In the revised manuscript, we include new experiments that hold the perception component fixed and vary only the action sequencing strategy. We also report passive baseline performance under oracle navigation (perfect path to target viewpoints) and with stabilized physics simulation. These results confirm that the performance gap persists, with active exploration still outperforming even oracle-assisted passive observation by a substantial margin. This supports that the failures are indeed primarily due to action blindness rather than degraded passive observations from simulator dynamics. revision: yes
-
Referee: [Benchmark Construction] The claim that the 10 categories / 29 subcategories cleanly isolate the perception-action loop (task design section) requires evidence that simulator-specific factors (object stability, occlusion patterns, locomotion costs) do not confound passive baselines in ways that active policies incidentally mitigate. Without such checks, the performance gap cannot be confidently attributed to action choice.
Authors: We take this concern seriously. To address it, we have added a new section in the revised paper with quantitative analyses of simulator-specific factors. Specifically, we measure object stability, occlusion statistics, and locomotion costs across active and passive trials and show they are balanced. Furthermore, we demonstrate that the active-passive gap remains significant even after normalizing for these factors. We argue that the task categories, grounded in Spelke's core knowledge systems, are designed to require active evidence accumulation, and the controls confirm that the gap is attributable to action choice. revision: yes
Circularity Check
No circularity: empirical benchmark with direct measurements and no derivations
full rationale
This is a benchmark introduction and empirical evaluation paper. It defines ESI-Bench tasks explicitly from Spelke's core knowledge systems and OmniGibson simulator, then reports measured performance differences between active exploration policies and passive baselines on MLLMs. No equations, parameter fitting, or first-principles derivations appear; all central claims (active > passive, action blindness as dominant failure mode) rest on direct experimental comparisons that are externally replicable. No self-citation chains, ansatzes, or renamings reduce the results to inputs by construction. The design is self-contained against the stated simulator and task categories.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Spelke's core knowledge systems provide a valid grounding for defining spatial intelligence tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce ESI-BENCH, a comprehensive benchmark for embodied spatial intelligence spanning 10 task categories and 29 subcategories built on OmniGibson, grounded in Spelke's core knowledge systems.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
active exploration substantially outperforms passive counterparts... Most failures stem not from weak perception but from action blindness
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Wenxiao Cai, Yaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models.arXiv preprint arXiv:2406.13642,
-
[2]
URL https://arxiv.org/abs/2406.01584. 3 Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, Lei Shi, and Maosong Sun. Embodiedeval: Evaluate multimodal llms as embodied agents,
-
[3]
3, 4 Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang
URLhttps://arxiv.org/abs/2501.11858. 3, 4 Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Bench- marking and enhancing vision-language models for physical world understanding,
-
[4]
3 Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei
URL https://arxiv.org/abs/2501.16411. 3 Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. Embspatial-bench: Bench- marking spatial understanding for embodied tasks with large vision-language models,
-
[5]
URL https://arxiv.org/abs/2406.05756. 3, 4 Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Shijie Zhou, Dilin Wang, Zhicheng Yan, Hongyu Xu, Justin Theiss, Tianlong Chen, Jiachen Li, Zhengzhong Tu, Zhangyang Wang, and Rakesh Ranjan. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction,
-
[6]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
URL https://arxiv.org/abs/ 2505.20279. 3 Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
BLINK: Multimodal Large Language Models Can See but Not Perceive
URLhttps://arxiv.org/abs/2404.12390. 3 James J. Gibson.The Ecological Approach to Visual Perception. Houghton Mifflin,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
3, 4 Fangyu Liu, Guy Emerson, and Nigel Collier
URLhttps://arxiv.org/abs/2503.11117. 3, 4 Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning,
-
[9]
URL https://arxiv. org/abs/2205.00363. 2, 3 Mengzhen Liu, Enshen Zhou, Cheng Chi, Yi Han, Shanyu Rong, Liming Chen, Pengwei Wang, Zhongyuan Wang, and Shanghang Zhang. Sapave: Towards active perception and manipulation in vision-language-action models for robotics, 2026a. URL https://arxiv.org/abs/2603. 12193. 4 Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhang...
-
[10]
3 10 Zhenyang Liu, Yongchong Gu, Yikai Wang, Xiangyang Xue, and Yanwei Fu
URL https://arxiv.org/abs/2501.10074. 3 10 Zhenyang Liu, Yongchong Gu, Yikai Wang, Xiangyang Xue, and Yanwei Fu. Activevla: Injecting active perception into vision-language-action models for precise 3d robotic manipulation, 2026b. URLhttps://arxiv.org/abs/2601.08325. 4 Wenxin Ma, Chenlong Wang, Ruisheng Yuan, Hao Chen, Nanru Dai, S. Kevin Zhou, Yijun Yang...
-
[11]
3 Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso M de Melo, and Alan Yuille
URLhttps://arxiv.org/abs/2601.13304. 3 Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso M de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark,
-
[12]
URL https: //arxiv.org/abs/2412.07825. 3 Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, Karmesh Yadav, Qiyang Li, Ben Newman, Mohit Sharma, Vincent Berges, Shiqi Zhang, Pulkit Agrawal, Yonatan Bisk, Dhruv Batra, Mrinal Kalakrishnan, Franziska Meier, ...
-
[13]
3 Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan
URL https://arxiv.org/abs/2506.21458. 3 Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence, 2025a. URLhttps://arxiv.org/abs/2505.23747. 3 Haoning Wu, Xiao Huang, Yaohui Chen, Ya Zhang, Yanfeng Wang, and Weidi Xie. Spatialscore: Towards comprehensive evaluation for spatial int...
-
[14]
URL https://arxiv. org/abs/2506.15666. 4 Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces, 2025a. URL https://arxiv.org/abs/2412.14171. 2, 3 Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja ...
-
[15]
4 Yanpeng Zhao, Wentao Ding, Hongtao Li, Baoxiong Jia, and Zilong Zheng
URLhttps://arxiv.org/abs/2511.20351. 4 Yanpeng Zhao, Wentao Ding, Hongtao Li, Baoxiong Jia, and Zilong Zheng. Espire: A diagnostic benchmark for embodied spatial reasoning of vision-language models,
-
[16]
3, 4 12 Contents 1 Introduction 2 2 Related Works 3 3 ESI-BENCH4 3.1 Benchmark Setup
URL https:// arxiv.org/abs/2603.13033. 3, 4 12 Contents 1 Introduction 2 2 Related Works 3 3 ESI-BENCH4 3.1 Benchmark Setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3.2 Task Construction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 3.3 Task Categories and Statistics . . . . . . . . . . . . . . . . ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.