Understanding LLM Behavior in Multi-Target Cross-Lingual Summarization
Pith reviewed 2026-06-28 17:31 UTC · model grok-4.3
The pith
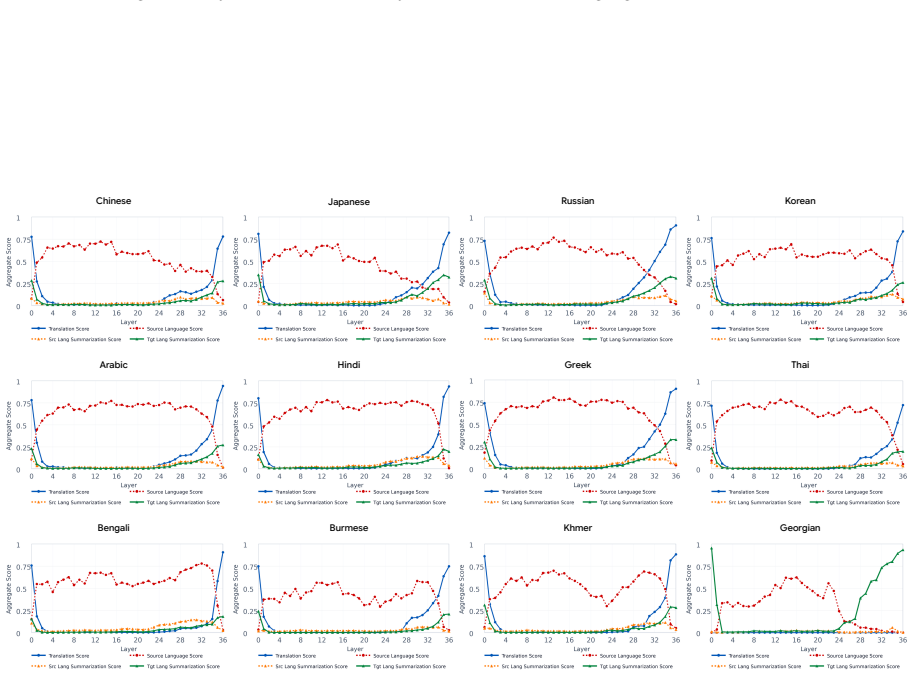
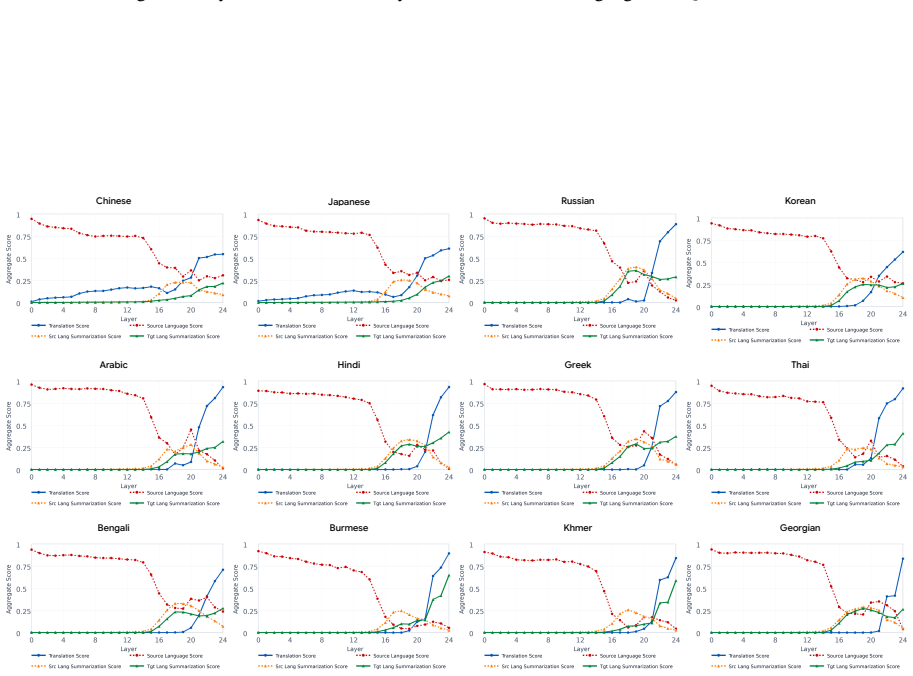
Translation and summarization emerge jointly in later LLM layers for multi-target cross-lingual summarization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
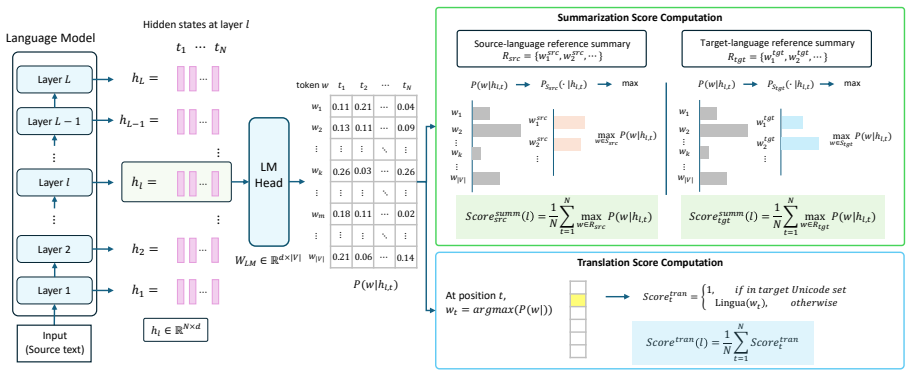
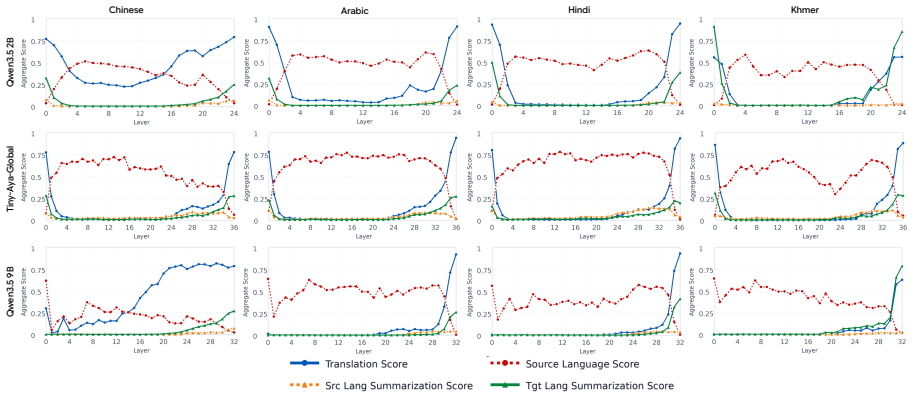
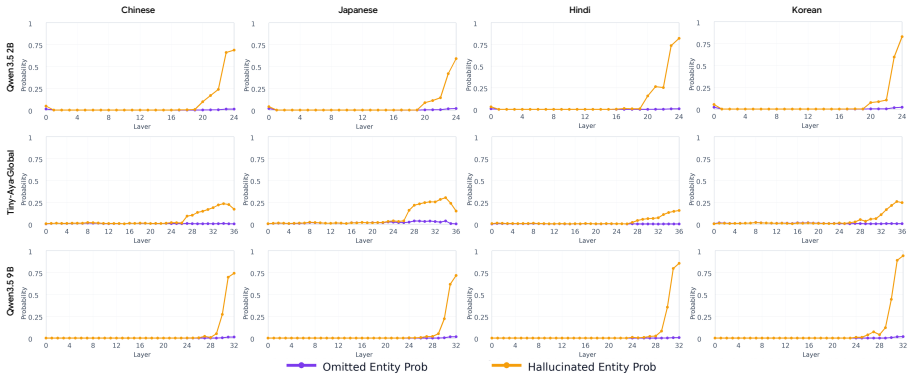
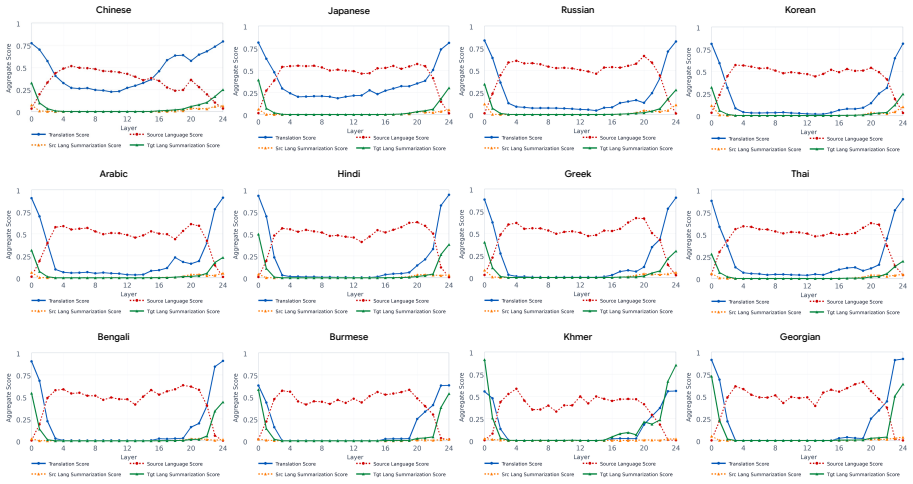
Analyses suggest that translation and summarization behaviors emerge jointly within later layers rather than as distinctly decomposed stages. Most task-relevant processing occurs within these layers, and errors also tend to arise at similar depths. Motivated by these findings, an inference-time activation steering method that leverages hidden representations from English summarization guides multi-target cross-lingual generation and consistently improves quality across target languages.
What carries the argument
Layer-wise analysis framework that tracks hidden-state evolution across depths, paired with inference-time activation steering that re-uses English summarization representations to influence non-English output.
If this is right
- Task processing and error formation both concentrate in the later layers.
- Steering with English representations raises output quality for all tested target languages.
- Neither end-to-end nor pipeline methods close the gap to English monolingual summarization.
- Translation and summarization do not appear as separate processing stages.
Where Pith is reading between the lines
- The same joint-layer pattern may hold for other multilingual text-generation tasks.
- Steering could be tried with representations from additional high-resource languages.
- Architectures that strengthen later-layer integration might reduce the need for external steering.
- Debugging efforts could target the depths where both correct behavior and errors first appear.
Load-bearing premise
The layer-wise measurements correctly capture how the model actually carries out the task, and English hidden states can be moved to other languages without creating new systematic mistakes.
What would settle it
A controlled run in which early-layer interventions change multi-target performance more than later-layer ones, or in which the English-derived steering leaves quality unchanged or lower across multiple languages.
Figures



read the original abstract
Multi-target cross-lingual text summarization (MTXLS), which summarizes a source document into multiple target languages, is increasingly important as users consume content in diverse languages, but remains underexplored. To address this gap, we introduce multi-target cross-lingual element-aware (MEA), a new MTXLS benchmark covering 24 target languages. We benchmark end-to-end and pipeline approaches across various LLMs and show that MTXLS performance still substantially lags behind English monolingual summarization. To better understand MTXLS in LLMs, we propose a layer-wise analysis framework for investigating how LLMs internally perform MTXLS. Our analyses suggest that translation and summarization behaviors emerge jointly within later layers rather than as distinctly decomposed stages. Most task-relevant processing occurs within these layers, and errors also tend to arise at similar depths. Motivated by these findings, we introduce an inference-time activation steering method that leverages hidden representations from English summarization to guide MTXLS generation. Experiments show that our method consistently improves MTXLS quality across target languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MEA benchmark for multi-target cross-lingual summarization (MTXLS) across 24 target languages, benchmarks end-to-end and pipeline LLM approaches showing substantial gaps versus English monolingual summarization, presents a layer-wise analysis framework whose results suggest that translation and summarization behaviors emerge jointly in later layers (rather than as decomposed stages), and proposes an inference-time activation steering method that uses English summarization hidden states to improve MTXLS quality.
Significance. If the layer-wise findings and steering results hold under causal scrutiny, the work would supply both a new evaluation resource for an underexplored task and a mechanistic account that directly motivates a practical inference-time intervention; the combination of benchmark, observational analysis, and transferable steering is a concrete contribution to understanding and controlling cross-lingual generation in LLMs.
major comments (1)
- [layer-wise analysis section (exact section number not specified in abstract)] The central claim that translation and summarization 'emerge jointly within later layers rather than as distinctly decomposed stages' rests on the layer-wise analysis framework. If this framework uses only observational metrics (activation similarity, probe accuracy per layer, or error localization) without targeted interventions such as activation patching, ablation of specific layers, or causal mediation analysis, the data cannot distinguish joint processing from independent behaviors that simply peak at overlapping depths. This is load-bearing because the steering method is explicitly motivated by the joint-emergence finding.
minor comments (1)
- The abstract states that 'most task-relevant processing occurs within these layers, and errors also tend to arise at similar depths,' but does not report quantitative thresholds or statistical tests used to identify 'most' or 'similar.'
Simulated Author's Rebuttal
We thank the referee for the careful reading and the substantive point regarding the layer-wise analysis. We address the concern directly below.
read point-by-point responses
-
Referee: The central claim that translation and summarization 'emerge jointly within later layers rather than as distinctly decomposed stages' rests on the layer-wise analysis framework. If this framework uses only observational metrics (activation similarity, probe accuracy per layer, or error localization) without targeted interventions such as activation patching, ablation of specific layers, or causal mediation analysis, the data cannot distinguish joint processing from independent behaviors that simply peak at overlapping depths. This is load-bearing because the steering method is explicitly motivated by the joint-emergence finding.
Authors: We agree that the layer-wise framework relies on observational metrics (layer-wise activation similarity, linear probe accuracy, and error localization) and does not include causal interventions such as patching or ablation. Consequently, the data show co-occurrence of translation and summarization signals in later layers but cannot rule out the possibility of independent processes that happen to peak at similar depths. We will revise the manuscript to replace the phrasing 'emerge jointly' with more cautious language ('co-occur in later layers' or 'show overlapping layer-wise profiles') and to explicitly note the correlational nature of the evidence. The steering method remains motivated by the empirical observation that English summarization representations improve MTXLS when injected at those layers; we will clarify that this is an existence proof of transfer rather than direct causal validation of joint processing. We will also add a limitations paragraph discussing the absence of causal mediation analysis. revision: yes
Circularity Check
No circularity: empirical observations and method are independent of inputs by construction.
full rationale
The paper introduces a benchmark (MEA), runs benchmarking experiments, proposes a layer-wise analysis framework, reports observational findings on layer depths for translation/summarization behaviors, and then describes an activation steering method motivated by those findings. No equations, fitted parameters, or self-citations are referenced in the provided text as load-bearing. The central claims rest on experimental results rather than any definitional reduction (e.g., no case where a 'prediction' is the input fit by construction, or where a uniqueness claim loops back to prior author work). The derivation chain is self-contained via external benchmarks and interventions, qualifying for the default non-circular outcome.
Axiom & Free-Parameter Ledger
invented entities (2)
-
MEA benchmark
no independent evidence
-
inference-time activation steering method
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pernes, Diogo and Correia, Gon c alo M. and Mendes, Afonso. Multi-Target Cross-Lingual Summarization: a novel task and a language-neutral approach. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.755
-
[2]
Wang, Yiming and Zhang, Zhuosheng and Wang, Rui. Element-aware Summarization with Large Language Models: Expert-aligned Evaluation and Chain-of-Thought Method. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.482
-
[3]
2026 , eprint=
Tiny Aya: Bridging Scale and Multilingual Depth , author=. 2026 , eprint=
2026
-
[4]
arXiv preprint arXiv:2508.10925 , year=
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
-
[5]
G -eval: NLG evaluation using gpt-4 with better human alignment
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang. G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.153
-
[6]
International Conference on Learning Representations , year=
BERTScore: Evaluating Text Generation with BERT , author=. International Conference on Learning Representations , year=
-
[7]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[8]
Evaluation of a Cross-lingual R omanian- E nglish Multi-document Summariser
Or a san, Constantin and Chiorean, Oana Andreea. Evaluation of a Cross-lingual R omanian- E nglish Multi-document Summariser. Proceedings of the Sixth International Conference on Language Resources and Evaluation ( LREC '08). 2008
2008
-
[9]
Leuski, Anton and Lin, Chin-Yew and Zhou, Liang and Germann, Ulrich and Och, Franz Josef and Hovy, Eduard , title =. 2003 , issue_date =. doi:10.1145/979872.979877 , journal =
-
[10]
Cross-Language Document Summarization Based on Machine Translation Quality Prediction
Wan, Xiaojun and Li, Huiying and Xiao, Jianguo. Cross-Language Document Summarization Based on Machine Translation Quality Prediction. Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. 2010
2010
-
[11]
A Robust Abstractive System for Cross-Lingual Summarization
Ouyang, Jessica and Song, Boya and McKeown, Kathy. A Robust Abstractive System for Cross-Lingual Summarization. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1204
-
[12]
W iki L ingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization
Ladhak, Faisal and Durmus, Esin and Cardie, Claire and McKeown, Kathleen. W iki L ingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization. Findings of the Association for Computational Linguistics: EMNLP 2020. 2020. doi:10.18653/v1/2020.findings-emnlp.360
-
[13]
C ross S um: Beyond E nglish-Centric Cross-Lingual Summarization for 1,500+ Language Pairs
Bhattacharjee, Abhik and Hasan, Tahmid and Ahmad, Wasi Uddin and Li, Yuan-Fang and Kang, Yong-Bin and Shahriyar, Rifat. C ross S um: Beyond E nglish-Centric Cross-Lingual Summarization for 1,500+ Language Pairs. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.143
-
[14]
Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M
Hasan, Tahmid and Bhattacharjee, Abhik and Islam, Md. Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M. Sohel and Shahriyar, Rifat. XL -Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.413
-
[15]
C lid S um: A Benchmark Dataset for Cross-Lingual Dialogue Summarization
Wang, Jiaan and Meng, Fandong and Lu, Ziyao and Zheng, Duo and Li, Zhixu and Qu, Jianfeng and Zhou, Jie. C lid S um: A Benchmark Dataset for Cross-Lingual Dialogue Summarization. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.526
-
[16]
Chen, Yulong and Zhang, Huajian and Zhou, Yijie and Bai, Xuefeng and Wang, Yueguan and Zhong, Ming and Yan, Jianhao and Li, Yafu and Li, Judy and Zhu, Xianchao and Zhang, Yue. Revisiting Cross-Lingual Summarization: A Corpus-based Study and A New Benchmark with Improved Annotation. Proceedings of the 61st Annual Meeting of the Association for Computationa...
-
[17]
NCLS : Neural Cross-Lingual Summarization
Zhu, Junnan and Wang, Qian and Wang, Yining and Zhou, Yu and Zhang, Jiajun and Wang, Shaonan and Zong, Chengqing. NCLS : Neural Cross-Lingual Summarization. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1302
-
[18]
Using Bilingual Information for Cross-Language Document Summarization
Wan, Xiaojun. Using Bilingual Information for Cross-Language Document Summarization. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. 2011
2011
-
[19]
Cross-Lingual Abstractive Summarization with Limited Parallel Resources
Bai, Yu and Gao, Yang and Huang, Heyan. Cross-Lingual Abstractive Summarization with Limited Parallel Resources. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.538
-
[20]
Abstractive Cross-Language Summarization via Translation Model Enhanced Predicate Argument Structure Fusing , year=
Zhang, Jiajun and Zhou, Yu and Zong, Chengqing , journal=. Abstractive Cross-Language Summarization via Translation Model Enhanced Predicate Argument Structure Fusing , year=
-
[21]
An Empirical Study of Many-to-Many Summarization with Large Language Models
Wang, Jiaan and Meng, Fandong and Sun, Zengkui and Liang, Yunlong and Cao, Yuxuan and Xu, Jiarong and Shi, Haoxiang and Zhou, Jie. An Empirical Study of Many-to-Many Summarization with Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.555
-
[22]
Zero-Shot Cross-Lingual Summarization via Large Language Models
Wang, Jiaan and Liang, Yunlong and Meng, Fandong and Zou, Beiqi and Li, Zhixu and Qu, Jianfeng and Zhou, Jie. Zero-Shot Cross-Lingual Summarization via Large Language Models. Proceedings of the 4th New Frontiers in Summarization Workshop. 2023. doi:10.18653/v1/2023.newsum-1.2
-
[23]
A Survey on Cross-Lingual Summarization
Wang, Jiaan and Meng, Fandong and Zheng, Duo and Liang, Yunlong and Li, Zhixu and Qu, Jianfeng and Zhou, Jie. A Survey on Cross-Lingual Summarization. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00520
-
[24]
Low-Resource Cross-Lingual Summarization through Few-Shot Learning with Large Language Models
Park, Gyutae and Hwang, Seojin and Lee, Hwanhee. Low-Resource Cross-Lingual Summarization through Few-Shot Learning with Large Language Models. Proceedings of the Seventh Workshop on Technologies for Machine Translation of Low-Resource Languages (LoResMT 2024). 2024. doi:10.18653/v1/2024.loresmt-1.6
-
[25]
MSAMS um: Towards Benchmarking Multi-lingual Dialogue Summarization
Feng, Xiachong and Feng, Xiaocheng and Qin, Bing. MSAMS um: Towards Benchmarking Multi-lingual Dialogue Summarization. Proceedings of the Second DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering. 2022. doi:10.18653/v1/2022.dialdoc-1.1
-
[26]
PLAN : Summarizing using a Content Plan as Cross-Lingual Bridge
Huot, Fantine and Maynez, Joshua and Alberti, Chris and Amplayo, Reinald Kim and Agrawal, Priyanka and Fierro, Constanza and Narayan, Shashi and Lapata, Mirella. PLAN : Summarizing using a Content Plan as Cross-Lingual Bridge. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers...
-
[27]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[28]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[29]
Interpreting GPT: The Logit Lens , author=
-
[30]
The State and Fate of Linguistic Diversity and Inclusion in the NLP World
Joshi, Pratik and Santy, Sebastin and Budhiraja, Amar and Bali, Kalika and Choudhury, Monojit. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.560
-
[31]
Extracting Latent Steering Vectors from Pretrained Language Models
Subramani, Nishant and Suresh, Nivedita and Peters, Matthew. Extracting Latent Steering Vectors from Pretrained Language Models. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.48
-
[32]
arXiv preprint arXiv:2308.10248 , year=
Steering language models with activation engineering , author=. arXiv preprint arXiv:2308.10248 , year=
-
[33]
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Zhu, Wenhao and Liu, Hongyi and Dong, Qingxiu and Xu, Jingjing and Huang, Shujian and Kong, Lingpeng and Chen, Jiajun and Li, Lei. Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.176
-
[34]
arXiv preprint arXiv:2209.12356 , year=
News summarization and evaluation in the era of gpt-3 , author=. arXiv preprint arXiv:2209.12356 , year=
-
[35]
doi:10.21437/Interspeech.2024-2389 , issn =
Sangwon Ryu and Heejin Do and Yunsu Kim and Gary Geunbae Lee and Jungseul Ok , year =. doi:10.21437/Interspeech.2024-2389 , issn =
-
[36]
Zhang, Tianyi and Ladhak, Faisal and Durmus, Esin and Liang, Percy and McKeown, Kathleen and Hashimoto, Tatsunori B. Benchmarking Large Language Models for News Summarization. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00632
-
[37]
doi:10.5281/zenodo.6860598 , url =
Wenhao Huang and Zijia Lin and Chris McConnell and B. doi:10.5281/zenodo.6860598 , url =
-
[38]
arXiv preprint arXiv:2604.08260 , year=
Behavior-Aware Item Modeling via Dynamic Procedural Solution Representations for Knowledge Tracing , author=. arXiv preprint arXiv:2604.08260 , year=
-
[39]
Wang, Mingyang and Adel, Heike and Lange, Lukas and Liu, Yihong and Nie, Ercong and Str. Lost in Multilinguality: Dissecting Cross-lingual Factual Inconsistency in Transformer Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.253
-
[40]
Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes
Wang, Mingyang and Lange, Lukas and Adel, Heike and Ma, Yunpu and Str. Language Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.132
-
[41]
Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline
Lu, Meng and Zhang, Ruochen and Eickhoff, Carsten and Pavlick, Ellie. Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.762
-
[42]
Advances in Neural Information Processing Systems , volume=
Embedding trajectory for out-of-distribution detection in mathematical reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
G rad S im: Gradient-Based Language Grouping for Effective Multilingual Training
Wang, Mingyang and Adel, Heike and Lange, Lukas and Str. G rad S im: Gradient-Based Language Grouping for Effective Multilingual Training. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.282
-
[44]
arXiv preprint arXiv:2601.02996 , year=
Large Reasoning Models Are (Not Yet) Multilingual Latent Reasoners , author=. arXiv preprint arXiv:2601.02996 , year=
-
[45]
Multi-Dimensional Optimization for Text Summarization via Reinforcement Learning
Ryu, Sangwon and Do, Heejin and Kim, Yunsu and Lee, Gary and Ok, Jungseul. Multi-Dimensional Optimization for Text Summarization via Reinforcement Learning. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.319
-
[46]
Towards a Unified Multi-Dimensional Evaluator for Text Generation
Zhong, Ming and Liu, Yang and Yin, Da and Mao, Yuning and Jiao, Yizhu and Liu, Pengfei and Zhu, Chenguang and Ji, Heng and Han, Jiawei. Towards a Unified Multi-Dimensional Evaluator for Text Generation. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.131
-
[47]
Q uest E val: Summarization Asks for Fact-based Evaluation
Scialom, Thomas and Dray, Paul-Alexis and Lamprier, Sylvain and Piwowarski, Benjamin and Staiano, Jacopo and Wang, Alex and Gallinari, Patrick. Q uest E val: Summarization Asks for Fact-based Evaluation. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.529
-
[48]
arXiv preprint arXiv:2509.26435 , year=
Adaptive Planning for Multi-Attribute Controllable Summarization with Monte Carlo Tree Search , author=. arXiv preprint arXiv:2509.26435 , year=
-
[49]
arXiv preprint arXiv:2309.09558 , year=
Summarization is (almost) dead , author=. arXiv preprint arXiv:2309.09558 , year=
-
[50]
Tracing Multilingual Factual Knowledge Acquisition in Pretraining
Liu, Yihong and Wang, Mingyang and Kargaran, Amir Hossein and K. Tracing Multilingual Factual Knowledge Acquisition in Pretraining. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.113
-
[51]
Refusal Direction is Universal Across Safety-Aligned Languages , url =
Wang, Xinpeng and Wang, Mingyang and Liu, Yihong and Schuetze, Hinrich and Plank, Barbara , booktitle =. Refusal Direction is Universal Across Safety-Aligned Languages , url =
-
[52]
arXiv preprint arXiv:2510.27269 , year=
Why Do Multilingual Reasoning Gaps Emerge in Reasoning Language Models? , author=. arXiv preprint arXiv:2510.27269 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.