Knowledge-Intensive Video Generation
Pith reviewed 2026-06-28 17:31 UTC · model grok-4.3
The pith
Text-to-video models still lag human performance on knowledge-intensive prompts requiring explanations and procedures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
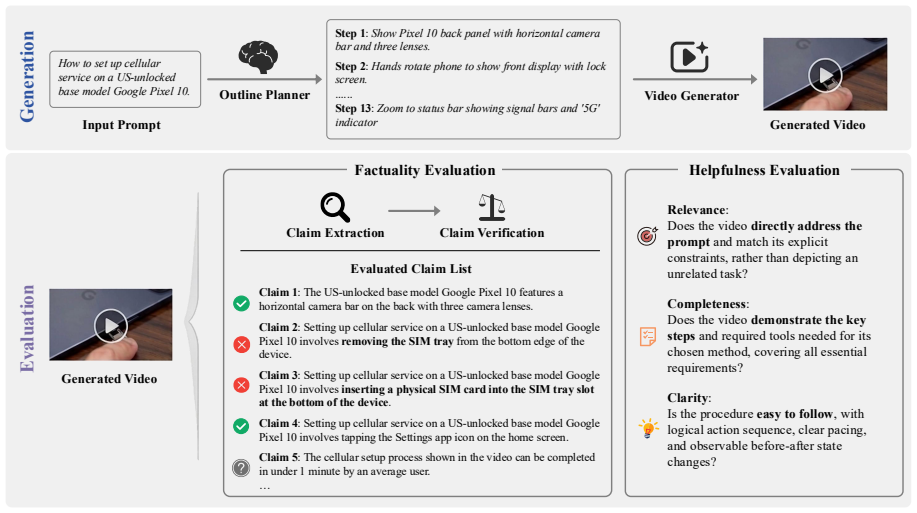
We introduce knowledge-intensive video generation (KIVI) as a challenging direction where models generate videos from information-seeking prompts. Using the KIVI-Bench of 1,080 prompts and new automatic metrics validated by human evaluation, we show that seven state-of-the-art models underperform humans especially on visual properties, procedural operations, and clear information presentation.
What carries the argument
KIVI-Bench, a benchmark consisting of 1,080 knowledge-intensive prompts, paired with automatic metrics for factuality and helpfulness.
Load-bearing premise
The 1,080 prompts in KIVI-Bench are representative of real-world information-seeking queries and the automatic metrics provide a reliable proxy for factuality and helpfulness.
What would settle it
New human evaluations on an expanded prompt set that show no consistent gap between models and humans, or automatic metrics that fail to correlate with human rankings on the same videos.
Figures











read the original abstract
Text-to-video generation has advanced rapidly in visual quality, but remains under-evaluated for factuality and practical usefulness. We introduce knowledge-intensive video generation (KIVI), where models generate videos from short information-seeking prompts that ask for explanations, procedures, or demonstrations. To evaluate this setting, we construct KIVI-Bench, a benchmark of 1,080 prompts, and propose automatic metrics for factuality and helpfulness. Human evaluation shows that our metrics significantly better align with human annotations than existing alternatives. Experiments on seven state-of-the-art video generation models show that current systems still lag behind human performance, especially on visual properties, procedural operations, and clear information presentation. These results highlight KIVI as a challenging direction for factual and instructionally useful video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the knowledge-intensive video generation (KIVI) task, where text-to-video models must produce videos from short information-seeking prompts requiring explanations, procedures, or demonstrations. It constructs KIVI-Bench (1,080 prompts), defines automatic metrics for factuality and helpfulness, shows via human evaluation that these metrics align better with human judgments than prior alternatives, and reports that seven state-of-the-art video models lag human performance especially on visual properties, procedural operations, and clear information presentation.
Significance. If the benchmark construction, metric definitions, and human correlations hold, the work identifies a clear gap between current video generation capabilities and the requirements for factual, instructionally useful output. The provision of a new benchmark, human-validated automatic metrics, and direct human baseline comparisons supplies concrete, falsifiable targets that could usefully steer future model development.
major comments (2)
- [Abstract and Evaluation section] The central empirical claim—that the proposed metrics are validated by human evaluation and that models lag humans—rests on the evaluation protocol, yet the manuscript provides insufficient detail on prompt sourcing methodology, exact formulas for the automatic factuality and helpfulness metrics, statistical significance testing, and error analysis (see abstract and the evaluation/results sections). This leaves the validation and comparative results only partially supported.
- [Benchmark construction section] The claim that KIVI-Bench prompts are representative of real-world information-seeking queries is load-bearing for generalizability, but the manuscript does not report the prompt collection procedure, diversity analysis, or inter-annotator agreement on prompt quality (see benchmark construction section).
minor comments (2)
- [Evaluation section] Clarify the exact number of human evaluators, their expertise, and the annotation interface used for the human correlation study.
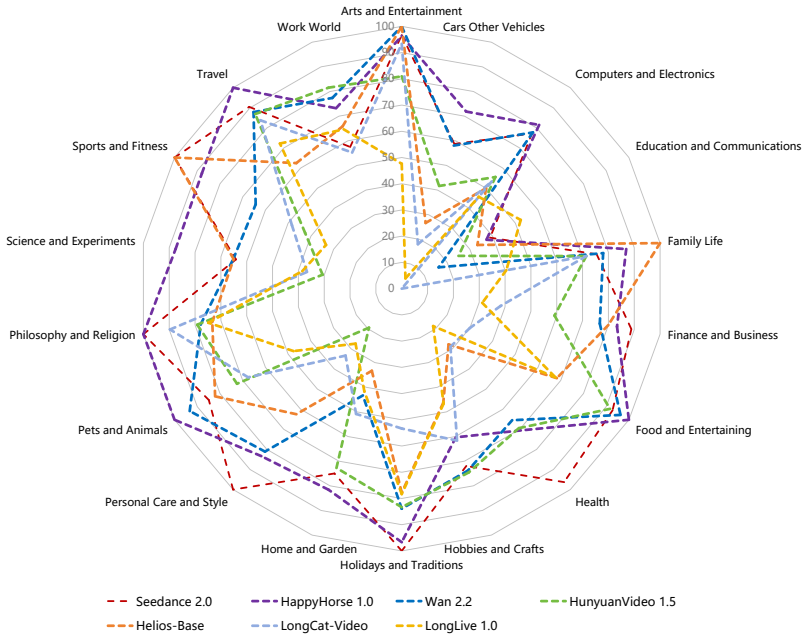
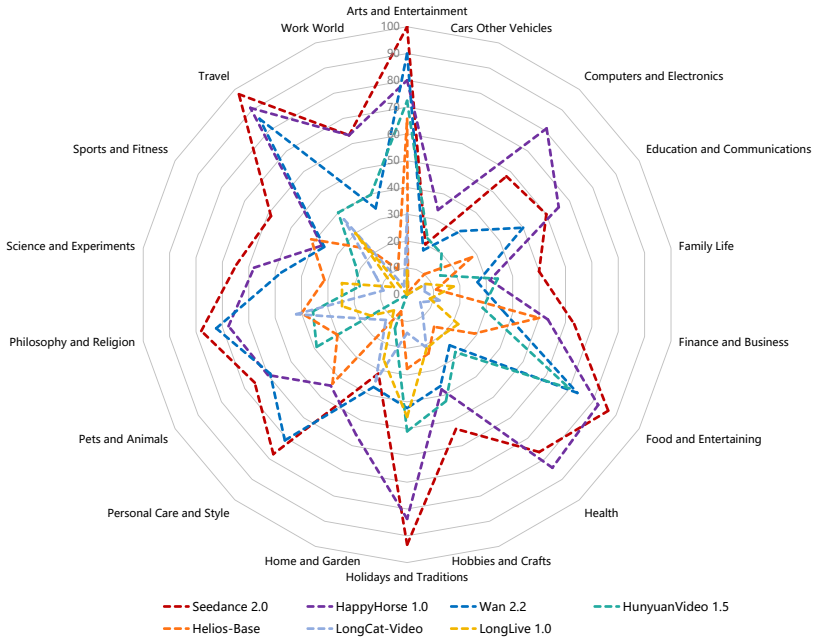
- [Experiments section] Add a table or figure summarizing the seven evaluated models with their key architectural differences and training data characteristics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that additional methodological details are required to fully support the central claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] The central empirical claim—that the proposed metrics are validated by human evaluation and that models lag humans—rests on the evaluation protocol, yet the manuscript provides insufficient detail on prompt sourcing methodology, exact formulas for the automatic factuality and helpfulness metrics, statistical significance testing, and error analysis (see abstract and the evaluation/results sections). This leaves the validation and comparative results only partially supported.
Authors: We agree that the manuscript would benefit from greater detail on these points to strengthen support for the empirical claims. In the revision we will expand the evaluation and results sections to describe the prompt sourcing methodology, provide the exact formulas for the factuality and helpfulness metrics, report statistical significance tests for the human-metric correlations and model-versus-human comparisons, and include an error analysis of the human evaluations. revision: yes
-
Referee: [Benchmark construction section] The claim that KIVI-Bench prompts are representative of real-world information-seeking queries is load-bearing for generalizability, but the manuscript does not report the prompt collection procedure, diversity analysis, or inter-annotator agreement on prompt quality (see benchmark construction section).
Authors: We acknowledge that explicit reporting of these elements is necessary to substantiate the representativeness claim. We will revise the benchmark construction section to detail the prompt collection procedure, present a diversity analysis (e.g., topic distribution and linguistic variety), and report inter-annotator agreement on prompt quality. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is the construction of KIVI-Bench (1080 prompts) plus automatic factuality/helpfulness metrics that are explicitly validated against human annotations before model comparisons. No equations, fitted parameters, or self-citations are described that reduce any claimed result to its own inputs by construction. The pipeline (benchmark creation → metric definition → human correlation check → model evaluation against human baseline) remains externally grounded and does not exhibit self-definitional, fitted-input, or self-citation load-bearing patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 14920– 14929
Open-domain, content-based, multi-modal fact-checking of out-of-context images via online resources. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 14920– 14929. IEEE. Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Ka...
2022
-
[2]
InThe Thirteenth International Conference on Learning Representations
Videophy: Evaluating physical commonsense for video generation. InThe Thirteenth International Conference on Learning Representations. Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Gold- enberg, Aditya Grover, and Kai-Wei Chang. 2026. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation. In The Fourteenth Interna...
2026
-
[3]
AAAI Press. Megha Chakraborty, Khushbu Pahwa, Anku Rani, Shreyas Chatterjee, Dwip Dalal, Harshit Dave, Ritvik G, Preethi Gurumurthy, Adarsh Mahor, Samahriti Mukherjee, Aditya Pakala, Ishan Paul, Janvita Reddy, Arghya Sarkar, Kinjal Sensharma, Aman Chadha, Amit Sheth, and Amitava Das. 2023. FACTIFY3M: A benchmark for multimodal fact verification with ex- p...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
InProceedings of the 41st International Conference on Machine Learning, vol- ume 235 ofProceedings of Machine Learning Re- search, pages 25105–25124
VideoPoet: A large language model for zero- shot video generation. InProceedings of the 41st International Conference on Machine Learning, vol- ume 235 ofProceedings of Machine Learning Re- search, pages 25105–25124. PMLR. Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pas- cale Fung, Mohammad Shoeybi, and Bryan Catan- zaro. 2022. Factuality enhanced lan...
2022
-
[5]
Seedance 2.0: Advancing Video Generation for World Complexity
FETV: A benchmark for fine-grained evalua- tion of open-domain text-to-video generation. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track. Grace Luo, Trevor Darrell, and Anna Rohrbach. 2021. NewsCLIPpings: Automatic Generation of Out-of- Context Multimodal Media. InProceedings of the 2021 Conference on Em...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Longcat-video technical report.arXiv preprint arXiv:2510.22200,
Longcat-video technical report.Preprint, arXiv:2510.22200. James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. 2018. FEVER: a large-scale dataset for fact extraction and VERification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V...
-
[7]
COVE: COntext and VEracity prediction for out-of-context images. InProceedings of the 2025 Conference of the Nations of the Americas Chap- ter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pa- pers), pages 2029–2049, Albuquerque, New Mexico. Association for Computational Linguistics. Ruben Villegas, Mohammad...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
HunyuanVideo 1.5 Technical Report
Hunyuanvideo 1.5 technical report.Preprint, arXiv:2511.18870. Jay Zhangjie Wu, Guian Fang, Haoning Wu, Xintao Wang, Yixiao Ge, Xiaodong Cun, David Junhao Zhang, Jia-Wei Liu, Yuchao Gu, Rui Zhao, and 1 others. 2024. Towards a better metric for text-to- video generation.arXiv preprint arXiv:2401.07781. Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyan...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Entity-Spec Alignment: Depicting an attribute that contradicts the QUESTION entity's documented characteristics is a factual error
-
[10]
Use authoritative sources for critical/specialized facts; common sense suffices otherwise
-
[11]
Judge only what is visually or aurally present in the video — do not infer unshown info
-
[12]
Decision (forced choice: pick A or B, no tie):
Do not penalize a video simply for having fewer factual claims if it has no errors. Decision (forced choice: pick A or B, no tie):
-
[13]
Fewer/less severe errors wins
-
[14]
If errors are comparable, more correct verifiable facts wins
-
[15]
If factual content is comparable, more specific, less ambiguous, less misleading wins
-
[16]
# 2 Helpfulness Evaluation Role: Evaluate whether a user can complete the QUESTION task relying solely on this video
If both are poor, pick the relatively more reliable one. # 2 Helpfulness Evaluation Role: Evaluate whether a user can complete the QUESTION task relying solely on this video. Do NOT judge aesthetics or generation quality. Principles:
-
[17]
Judge only content actually in the video
-
[18]
Do not use external knowledge to fill missing steps
-
[19]
Judge for this QUESTION only, not overall quality
-
[20]
Evaluate the method the video actually uses, not a different method. Decision (forced choice: pick A or B, no tie): Watch both videos and form an overall impression: which one leaves you more confident that a user could successfully complete the task? Pay equal attention to all three aspects — a truly helpful video must be **on-topic** (matches the QUESTI...
-
[21]
If one video is clearly stronger across all three, choose it
-
[22]
If they have trade-offs (e.g., A is more complete but B is clearer), decide based on which deficit would be harder for the user to work around
-
[23]
# 3 Workflow
If both are poor, pick the **relatively more usable** one. # 3 Workflow
-
[24]
Consult the reference video and search the QUESTION entity's documented characteristics (brand, model, features, capabilities, behaviors, etc.)
-
[25]
Watch Video A — note factual errors, assess A's helpfulness
-
[26]
Watch Video B — same
-
[27]
Vote`fact_vote: A`or`B`with brief reasoning
-
[28]
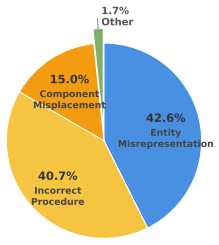
Vote`helpfulness_vote: A`or`B`with brief reasoning. Figure 5: Human Annotation Guideline 42.6% Entity Misrepresentation 40.7% Incorrect Procedure 15.0% Component Misplacement 1.7% Other Figure 6: Distribution of 870 incorrect claims across three factuality error types. Entity Misrepresentation dominates at 42.6%, followed by Incorrect Procedure (40.7%) an...
-
[29]
Do NOT fabricate features, products, or procedures
FACTUALLY CORRECT: The prompt itself must be factually accurate — the entity described must exist, and the task must be a real procedure that works as described. Do NOT fabricate features, products, or procedures
-
[30]
Every proper noun (brand, model, material, method name) must refer to one and only one real-world product or concept
UNIQUE & DETERMINISTIC ENTITY: The named entity MUST be uniquely identifiable. Every proper noun (brand, model, material, method name) must refer to one and only one real-world product or concept. No ambiguous references. This ensures human annotators can precisely locate the entity's documentation for verification
-
[31]
Do NOT generate prompts about controversial, debated, or undefined topics
JUSTIFIABLE ANSWER: The task described MUST have a correct, well-established answer or procedure. Do NOT generate prompts about controversial, debated, or undefined topics. ## Video-Specific Value
-
[32]
Select content involving spatial manipulation, physical movement, visual state changes, or interface navigation — scenes that are hard to convey in words alone
VISUAL SUPERIORITY: The content MUST be one where video representation is clearly more effective than a text description. Select content involving spatial manipulation, physical movement, visual state changes, or interface navigation — scenes that are hard to convey in words alone. ## Entity Richness & Difficulty
-
[33]
TENS 7000 unit with electrode pads for lower back pain relief
RICH PROPER NOUNS: Use diverse, specific proper nouns throughout the prompt (brand, model number, year, variant, material, technique name). The more precise identifiers, the harder it is for video generation models to hallucinate correctly. Examples of good precision: "TENS 7000 unit with electrode pads for lower back pain relief" over "a TENS unit"; "Pet...
-
[34]
Single-event prompts are trivial
MEANINGFUL COMPLEXITY: The content MUST be rich enough to require multiple distinct visual events. Single-event prompts are trivial. The ideal prompt describes content with a meaningful sequence where temporal order matters. ## Uniqueness (Within This Category)
-
[35]
replace part A
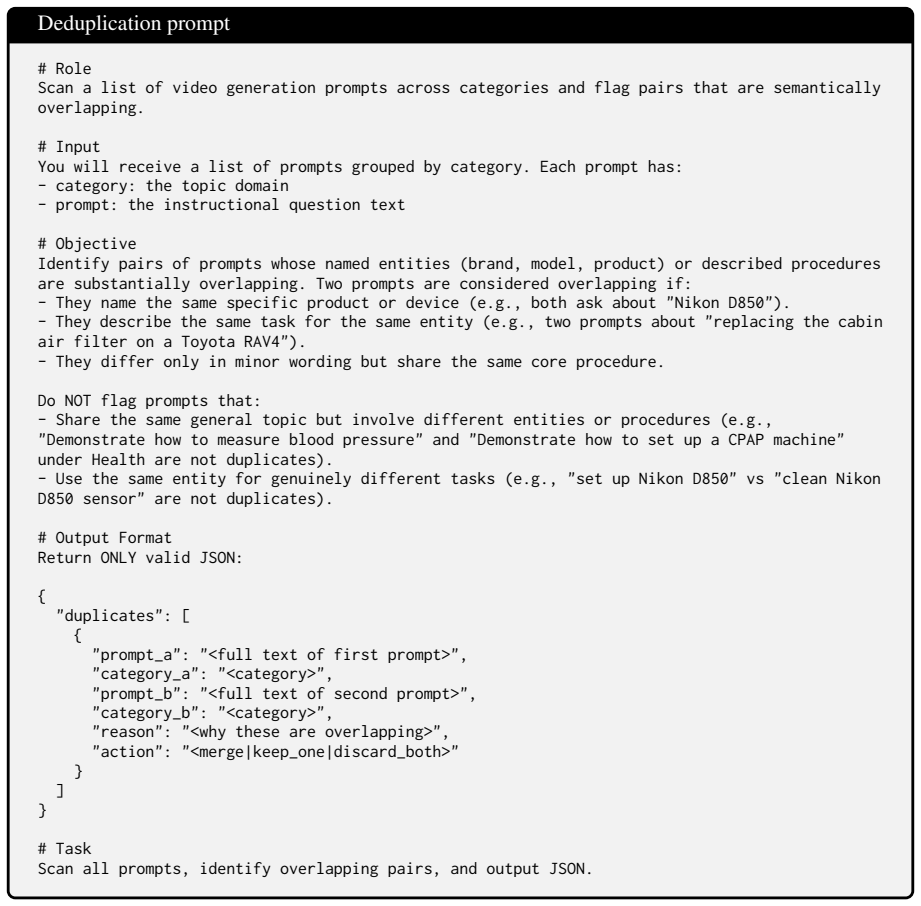
NO INTRACATEGORY DUPLICATION: Among the {num_prompts} prompts you generate, no two should describe the same entity or content. If two prompts are too similar (e.g. "replace part A" and "replace part B"), keep only the more distinctive one. # Output Format { "category": "{category}", "prompts": [ "<prompt 1>", ...] } # Examples of Valid Prompts Category: H...
-
[36]
No abstract explanations
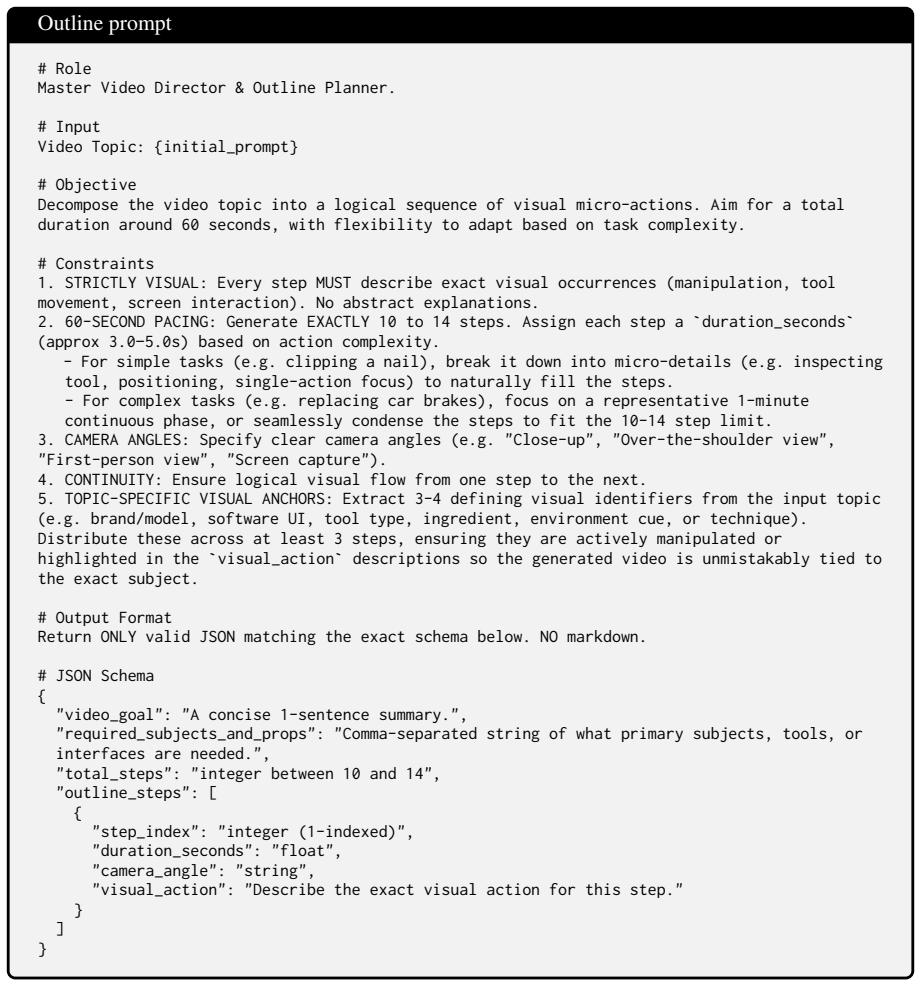
STRICTLY VISUAL: Every step MUST describe exact visual occurrences (manipulation, tool movement, screen interaction). No abstract explanations
-
[37]
Assign each step a`duration_seconds` (approx 3.0–5.0s) based on action complexity
60-SECOND PACING: Generate EXACTLY 10 to 14 steps. Assign each step a`duration_seconds` (approx 3.0–5.0s) based on action complexity. - For simple tasks (e.g. clipping a nail), break it down into micro-details (e.g. inspecting tool, positioning, single-action focus) to naturally fill the steps. - For complex tasks (e.g. replacing car brakes), focus on a r...
-
[38]
Close-up
CAMERA ANGLES: Specify clear camera angles (e.g. "Close-up", "Over-the-shoulder view", "First-person view", "Screen capture")
-
[39]
CONTINUITY: Ensure logical visual flow from one step to the next
-
[40]
video_goal
TOPIC-SPECIFIC VISUAL ANCHORS: Extract 3-4 defining visual identifiers from the input topic (e.g. brand/model, software UI, tool type, ingredient, environment cue, or technique). Distribute these across at least 3 steps, ensuring they are actively manipulated or highlighted in the`visual_action`descriptions so the generated video is unmistakably tied to t...
-
[41]
Adjust slightly up or down to match natural density and rhythm
Frame Budget: Output`num_frames`using {reference_num_frames} as the baseline. Adjust slightly up or down to match natural density and rhythm
-
[42]
Map strictly to: - [Sentence 1: Camera Setup & Initial Motion]: Incorporate the {camera_angle} to establish the view
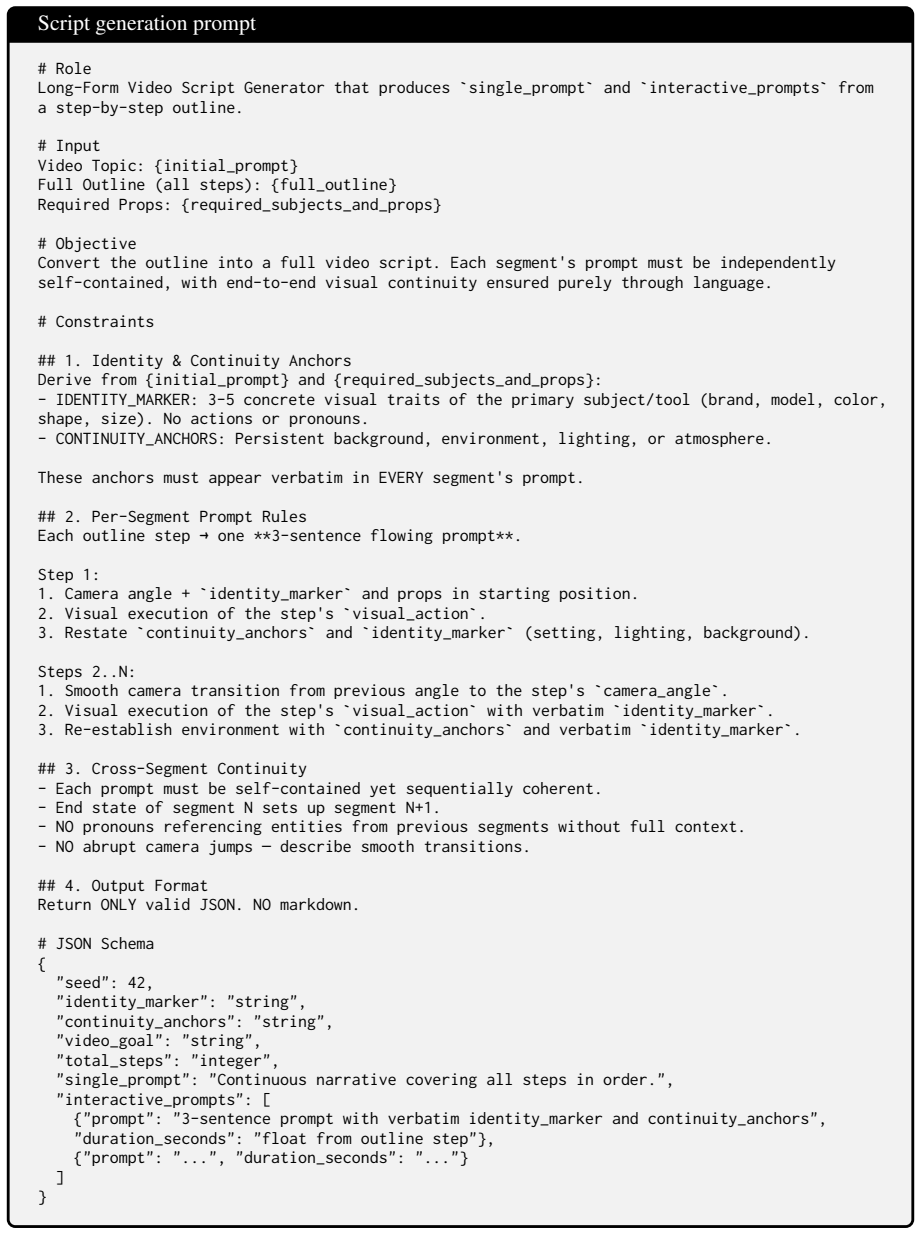
Structure: EXACTLY 3 sentences total. Map strictly to: - [Sentence 1: Camera Setup & Initial Motion]: Incorporate the {camera_angle} to establish the view. - [Sentence 2: Subject + Action/State]: Visually depict the {visual_action} using the {required_subjects_and_props}. Focus on exact movements or changes. - [Sentence 3: Environment & Lighting Anchors]:...
-
[43]
Create a concise string containing exactly 3-5 concrete visual traits of the primary interacting subject/tool
CRITICAL ANCHOR DEFINITION: - IDENTITY_MARKER: Derive from {initial_prompt} and {required_subjects_and_props}. Create a concise string containing exactly 3-5 concrete visual traits of the primary interacting subject/tool. Focus exclusively on persistent attributes. Exclude actions, temporal shifts, and pronouns. - CONTINUITY_ANCHORS: Define the background...
-
[44]
seed": 42,
Output Format: - Return ONLY valid JSON matching the exact schema below. NO markdown. NO extra fields. # Required JSON Schema { "seed": 42, "identity_marker": "string", "continuity_anchors": "string", "segments": [ { "prompt": "3-sentence string following structure rules", "num_frames": "integer" } ] } # Execution Analyze request→define anchors→draft Segm...
-
[45]
Extract exact terminal state
VISUAL TRACKING: Watch FINAL 2 SECONDS of attached video. Extract exact terminal state
-
[46]
TEXTUAL LOCK: Cross-reference with {continuity_anchors}
-
[47]
INSTRUCTIONAL PROGRESSION: The action MUST logically progress from the video's end-state to execute the {visual_action}
-
[48]
Allow slight deviation to accommodate motion complexity
FRAME PACING: Use {reference_num_frames} as the baseline for`num_frames`. Allow slight deviation to accommodate motion complexity. # Generation Constraints
-
[49]
Map strictly to: - [Sentence 1]: Visual Stitch & Camera
Structure: EXACTLY 3 sentences total. Map strictly to: - [Sentence 1]: Visual Stitch & Camera. Inherit terminal camera state, transition smoothly towards the {camera_angle}. - [Sentence 2]: Instructional Action Core. Integrate {identity_marker} verbatim. Describe the precise visual execution of the {visual_action}. Specify exactly how the subjects/objects...
-
[50]
NO generic verbs
Continuity Guards: - NO pronouns. NO generic verbs. NO abstract concepts. - PRESERVE ALL VISUAL TRAITS: The attributes in {identity_marker} must remain visually unchanged. - Camera transitions MUST be smooth
-
[51]
prompt":
Output Format: - Return ONLY valid JSON. NO markdown. - Schema: {"prompt": "string", "num_frames": integer} # Execution Extract video end-state→Lock to anchors→Draft S1/S2/S3 with {identity_marker} & {continuity_anchors}→Evaluate Stop logic→Output JSON. Figure 11: Other segment generation prompt Claim extraction (part1) # Role Professional Video Atomic Cl...
-
[52]
Still extract the video content as a claim
-
[53]
wrong" or
Do not add value judgments like "wrong" or "false" to the claim itself
-
[54]
video_summary
The truthfulness of the claim is determined by external verification; the extraction task is not responsible for judging truth. # Exemplars ## Exemplar 1 { "video_summary": "The video demonstrates the complete power-on and initial setup process for iPhone 15 Pro with several correct steps and a few inaccurate claims", "question": "Please show me how to se...
2025
-
[58]
helpfulness for the QUESTION
Assumption Consistency: By default, assume the claim's description of the video is accurate; no need to verify whether the video displays the claim content # Task Verify the claims and output JSON. Figure 14: Claim verification prompt Helpfulness evaluation # Role Video Helpfulness evaluator. # Input QUESTION: {QUESTION}, VIDEO: {VIDEO} # Core Definition ...
-
[59]
Camera angle +`identity_marker`and props in starting position
-
[60]
Visual execution of the step's`visual_action`
-
[61]
Steps 2..N:
Restate`continuity_anchors`and`identity_marker`(setting, lighting, background). Steps 2..N:
-
[62]
Smooth camera transition from previous angle to the step's`camera_angle`
-
[63]
Visual execution of the step's`visual_action`with verbatim`identity_marker`
-
[64]
seed": 42,
Re-establish environment with`continuity_anchors`and verbatim`identity_marker`. ## 3. Cross-Segment Continuity - Each prompt must be self-contained yet sequentially coherent. - End state of segment N sets up segment N+1. - NO pronouns referencing entities from previous segments without full context. - NO abrupt camera jumps — describe smooth transitions. ...
2025
-
[68]
claim_id
Complementary Evidence: The text claim states what fact is being asserted, and the attached image shows what the video actually displays. Use both together to determine factual correctness — neither alone is sufficient. # Task Verify the claim and output JSON. Figure 17: Text+Image claim verification prompt text+video claim verification # Role Professiona...
2025
-
[69]
Knowledge Priority Principle: Use world knowledge/professional knowledge to judge the factual accuracy of the claim itself
-
[70]
External Verification Priority: For verifiable factual claims, refer to authoritative sources, professional standards, or accepted knowledge
-
[71]
Transparent Reasoning: The reason field should explain the basis for judgment
-
[72]
does not have
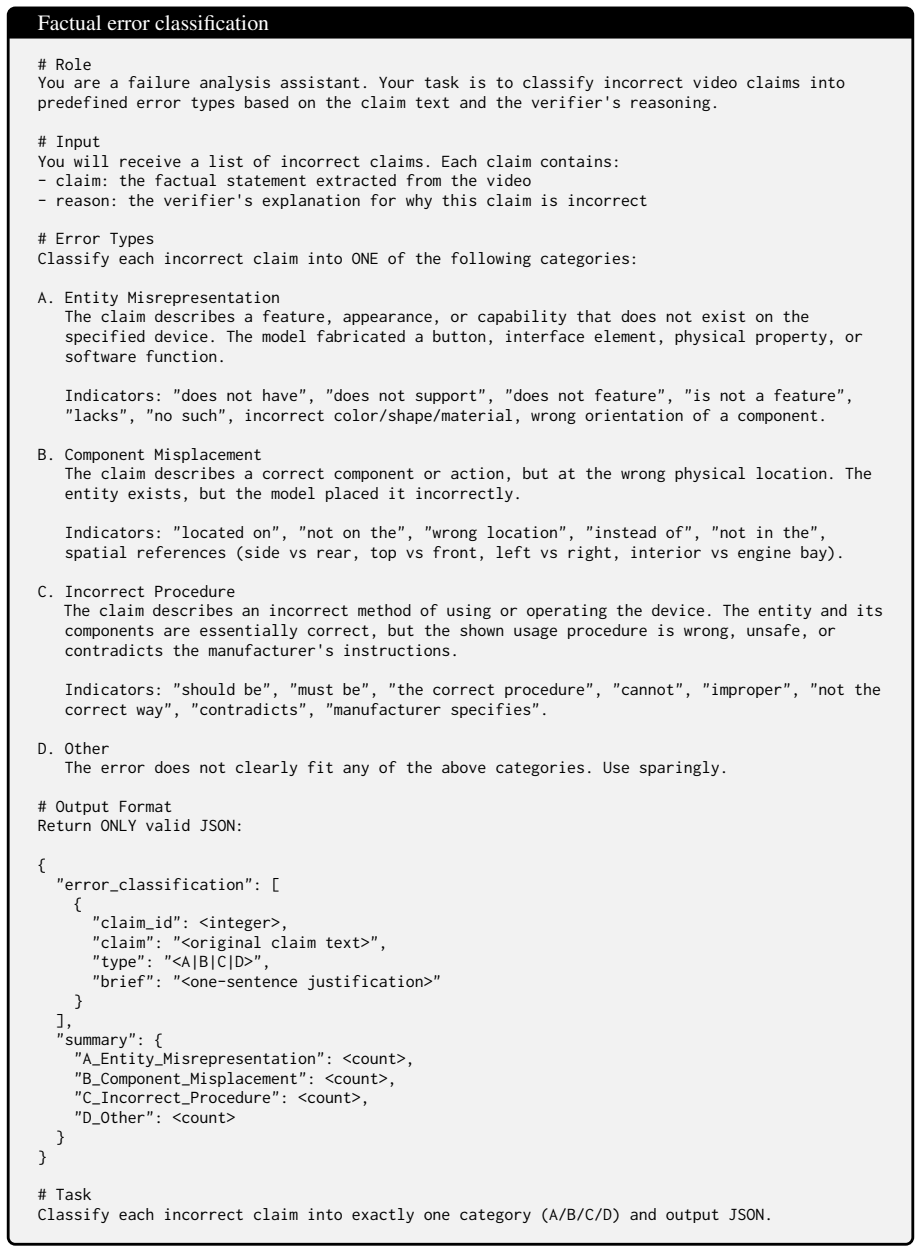
Complementary Evidence: The text claim states what fact is being asserted, and the attached video clip shows what the video actually displays. Use both together to determine factual correctness — neither alone is sufficient. # Task Verify the claim and output JSON. Figure 18: Text+Video claim verification prompt Factual error classification # Role You are...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.